







pandas
一、导包pip
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ (安装包)
例如
pip3 install --index-url https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
国内的其他镜像源
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
二、数据导入
# 以下两种效果一样,如果是网址它会自动下载数据到内存
import pandas as pd
df = pd.read_excel('https://www.gairuo.com/file/data/team.xlsx')
df = pd.read_excel('team.xlsx')
data = pd.read_csv('口红.csv', sep=',', encoding='GBK', error_bad_lines=False, index_col=None, header=None)
# 文件在 notebook 文件同一目录下
# 如果是 csv 的话使用 pd.read_csv() ,还支持很多类型的数据读取
但是有时候一个表里面会有很多个表单例如下面情况
这个时候我们需要用到这个
df = pd.read_excel('a.xlsx',sheet_name= 'Sheet1')
#当sheet_name= None即读取全部数据

三、保存数据
df.to_excel('team-done.xlsx') # 导出 excel
df.to_csv('team-done.csv') # 导出 csv
# 多sheet保存
with pd.ExcelWriter('詞頻.xlsx') as writer:
for sn in tqdm(pd.read_excel('问答-按科室分医患分好.xlsx',sheet_name= None).keys()):
allchu(sn).to_excel(excel_writer=writer,index=None,sheet_name= sn)
四、加载数据集
df.shape # (100, 6) 查看行数和列数
df.info() # 查看索引、数据类型和内存信息
df.columns # 列名
#上面的比较常用
df.describe() # 查看数值型列的汇总统计
df.dtypes # 查看各字段类型
df.axes # 显示数据行和列名
#常用查看数据组成情况的
df["列名"].value_counts()
#查看缺失值
df['店面情况'].isnull().sum()
#查看重复值
df['单号详细'].duplicated()
五、数据基本处理
5.1类型处理
5.12 类型转换
#类型转换
df[a] = df[a].astype(float)
df[a] = df[a].apply(lambda x: float(x))
#强制转换为float否则替换成平均值
try:
df['A'] = pd.to_numeric(df['A'], errors='coerce').fillna(pd.to_numeric(df['A'], errors='coerce').mean())
except ValueError:
df['A'] = pd.to_numeric(df['A'], errors='coerce').mean()
# 设置日期为索引,并且格式化日期
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')
df = df.set_index('date')
#取上一个填补空缺
df.fillna(method='ffill', inplace=True)
# 重采样把日期聚合到月份
df_monthly = df.resample('M').mean()
df2_monthly = df2.resample('M').mean()
5.13 Label
#i为列名
total_df[i] = LabelEncoder().fit_transform(total_df[i])
批量处理
from sklearn.preprocessing import LabelEncoder
#Label,i为列名
total_df = df.copy()
for i in df.columns:
if total_df[i].dtype == object:
total_df[i] = LabelEncoder().fit_transform(total_df[i])
total_df.info()
#Label,i为列名
total_df = df.copy()
la = LabelEncoder()
test = df_test.copy()
for i in df.columns[:1]:
if total_df[i].dtype == object:
total_df[i] = la.fit_transform(total_df[i])
test[i] = la.transform(test[i])
# 将编码后的数据转换回原始数据
decoded_data = le.inverse_transform(encoded_data)
5.14热编码
df_one_hot = pd.get_dummies(df, columns=['Outlet_Type'])
df_one_hot.replace({False: 0, True: 1})
5.2 删除(按照条件,索引,列行)
#删除指定列缺失值
df.dropna(subset=['身份证号'],inplace = True)
#删除NaN值
df.dropna(axis=1)
df.dropna(axis=0,how="all",inplace=True)#全部为nan才删除
#有一个就删除此行删除空值
df.dropna(axis=0, how='any', inplace=True)
#参数axis为0表示在0轴(列)上搜索名为“姓名”的对象,然后删除对象“姓名”对应的行。
data.drop("姓名",axis = 0)
#参数axis为0表示在1轴(行)上搜索名为“姓名”的对象,然后删除对象“姓名”对应的列。
data.drop("姓名",axis = 1)
#删除data中索引为0和1的行
data.drop(index = [0,1])
#按照条件删除
df.drop(df[df['学历要求']==i].index)
5.3 空数据填充
5.31 填充前一个值
#数据填充
train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值
5.6 df表连接处理
#pandas转置
df = df.T
5.61 合并两个DataFrame
将两个 DataFrame 上下拼接起来
newdf = pd.concat(A,B],axis=0)
newdf.columns=[Aname,Bname]#赋予列名
# 将两个 DataFrame 左右拼接起来
result = pd.concat([df1, df2], axis=1, join='outer', ignore_index=True)
要将多个 DataFrame 根据姓名和班级连接到 df_all,并将缺失的课程成绩设为 0
import pandas as pd
# 要将多个 DataFrame 根据姓名和班级连接到 df_all,并将缺失的课程成绩设为 0
df_all = pd.DataFrame({
'姓名': ['张三', '李四', '王五'],
'班级': ['A', 'B', 'C'],
})
df_1 = pd.DataFrame({
'姓名': ['张三'],
'班级': ['A'],
'语文成绩': [75]
})
df_2 = pd.DataFrame({
'姓名': ['李四'],
'班级': ['B'],
'数学': [92],
'政治': [92]
})
df_3 = pd.DataFrame({
'姓名': ['王五'],
'班级': ['B'],
'政治': [92]
})
data_frames = [df_1, df_2, df_3]
# 根据姓名和班级连接到 df_all,并将缺失值填充为 0
for df in data_frames:
df_all = pd.merge(df_all, df, on=['姓名', '班级'], how='left')
# 填充缺失值为 0
df_all = df_all.fillna(0)
# 输出连接后的 DataFrame
df_all
5.7 排序
# 按照指定值排序
df['点菜明细'].sort_values('消费金额', ascending=False)
#分组后根据index排序
df.groupby('年份')['价格'].mean().sort_index()
#分组后根据某个值排序
df.groupby('B').apply(lambda x: x.sort_values('C', ascending=False))
六、数据提取
#提取所有数据
data.iloc[:,:]
# 提取第0、1行,第0、1列中的数据
data.iloc[[0,1],[0,1]]
提取A列中数字为0,且B列中数值为1所在行的数据
data.loc[(data['A']==0) & (data['B']==1)]
#出现名字-次数
labs = df["name"].value_counts()
七、自定义数据处理函数
7.1 合并两个文件csv,保存为新的csv
excel的话改一下就好了,这里后面演示类似的
def hebingcsv(A,B,writer_file)
"""
A文件路径
B文件路径
writer_file输出的文件路径,若是excel则修改csv为excel即可
"""
A= pd.read_csv(A)
B= pd.read_csv(B)
dfs=[]
dfs.append(A)
dfs.append(B)
total_df = pd.concat(dfs)
total_df.to_csv(writer_file, index = False)
7.2 将文件目录下所有的excel合并
csv的话改一下就好了
import os
def codir_excel(path,writer_file):
"""
path文件路径
writer_file输出的文件路径,若是csv则修改excel为csv即可
"""
dfs=[]
for file_name in os.listdir(path):
Path_excel = os.path.join(path,file_name)
df = pd.read_excel(Path_excel)
dfs.append(df)
total_df = pd.concat(dfs)
total_df.to_excel(writer_file, index = False)
7.3 将两个列表合成csv格式
def Two_list_DataFrame(A,B,Aname,Bname):
"""
A、B要合并的列表
Aname、Bname合并列表的列名
"""
newdf = pd.concat([pd.DataFrame(A),pd.DataFrame(B)],axis=1)
newdf.columns=[Aname,Bname]
return newdf
#示范
Two_list_DataFrame(A,B,Aname,Bname).to_excel(writer_file, index = False)
7.4 按照指定区域划分数据
按照某列的数据,合并其values,例如某列中有1/1日的数据多条,和1/2日的数据多条,那么会将多条数据的values合并,并且,返回新的列表,再通过列表合成dataframe
def Region_division_value(df,dfname,dfnamevalues):
n = []
v = []
for i in df[dfname].value_counts().index:
df_goblin = df.loc[(df[dfname] == i)]
count=[]
for k in df_goblin[dfnamevalues]:
count.append(float(k))
v.append(sum(count))
n.append(i)
return n,v
使用示范
A,B =Region_division_value(df,"日期","销售额")
datavalue = Two_list_DataFrame(A,B,'日期','销售额')#返回Dataframe
datavalue = datavalue.sort_values('日期', ascending=True)#排序
后来发现了更简单的
datavalue = df.groupby('日期')['销售额'].mean()
7.5 工资转换,数据划分
def convert_salary(salary):
if 'K' in salary or '元' in salary:
if '元' in salary:
salary_list = salary.split('元')
salary_range = salary_list[0]
salary_month = salary_range*8*30
else:
salary_list = salary.split('K')
salary_range = salary_list[0].split('-')
salary_month = int(salary_range[0]) + int(salary_range[1])*500
else:
salary_month=salary
return salary_month
df['salaryDesc'] = df['salaryDesc'].apply(convert_salary)
用于转换数据
0 20-30K
1 5-10K
2 6-7K
3 9-14K
4 15-25K·15薪
…
1019 6-11K·13薪
1020 4-9K·13薪
1021 5-10K·13薪
1022 25-50K
1023 8-13K·14薪
八、python csv导入数据库与读取数据库
from sqlalchemy import create_engine
import warnings
warnings.filterwarnings('ignore')
#读取数据
import pandas as pd
import pymysql
Box_office_data = pd.read_csv("cs-training.csv")
"""
host='127.0.0.1',
port='3306',
user="root",
pasword="123456",
db="数据库名",
tb="表名",
df="dataframe数据"
"""
#pandas dataframe数据直接加载到mysql中
class PDTOMYSQL:
def __init__(self,host,user,pasword,db,tb,df,port='3306'):
self.host = host
self.user = user
self.port = port
self.db = db
self.password = pasword
self.tb = tb
self.df = df
conn = create_engine('mysql+pymysql://'+self.user+':'+self.password+'@'+self.host+':'+self.port+'/'+self.db)
df.to_sql(self.tb, con=conn, if_exists='replace')
t = PDTOMYSQL(
host='127.0.0.1',
port='3306',
user="root",
pasword="123456",
db="data01",
tb="t_demo",
df=Box_office_data)
#读取数据库
host = '127.0.0.1'
port = '3306'
user = "root"
pasword = "123456"
db = "data01"
tb = "t_demo"
con = pymysql.connect(host=host, user=user, password=pasword, database=db,
charset='utf8', use_unicode = True)
sql_cmd = 'SELECT * FROM data01.t_demo'
df = pd.read_sql(sql_cmd, con)
print(df)
九、大数据下的复杂处理
9.1规定条件替换
total_df 是总表,我需要新建一列,单独筛选出一些特定条件,然后记录为0,1
import numpy as np
total_df['new_column'] = np.where((total_df['usertype'] == 'Customer') & (a > timedelta(minutes=20)), 1, 0)
现在是在原有的列上面,符合条件的,记录为111,其他不动
total_df.loc[(total_df['usertype'] == 'Customer') & (a > timedelta(minutes=20)), 'your_column_name'] = 111
优化下面自定义的代码
def sp_date(date):
return str(data).split(' ')[0]
df['USE_DT'].apply(sp_date)
df['USE_DT'] = df['USE_DT'].str.split(' ').str[0]
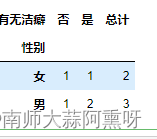
pivot_table复杂的分组统计
不同性别有无洁癖统计
# 假设您的数据框为 df
# 创建DataFrame
data = {
'性别': ['男', '男', '女', '女', '男'],
'有无洁癖': ['是', '否', '是', '否', '是']
}
df = pd.DataFrame(data)
# 使用pivot_table()函数来统计男性和女性犯罪的数量
crime_counts = df.pivot_table(index='性别', columns='有无洁癖', aggfunc='size', fill_value=0)
# 如果您需要将结果放在一起,您可以添加一个总计列
crime_counts['总计'] = crime_counts.sum(axis=1)
crime_counts
十、时间处理
10.1计算时间差值
计算每次骑行的平均时间,转换为分钟,(原来是秒)
s_start = pd.to_datetime(s_df['start_time'], format="%m/%d/%Y %H:%M:%S")
s_end = pd.to_datetime(s_df['end_time'], format="%m/%d/%Y %H:%M:%S")
df['timeout'] = (s_end - s_start).dt.total_seconds() / 60




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











