






0. 前言
本次笔记是对于实习初期,初次接触到LLM大模型的一些记录。内容主要集中在对于环境的配置的模型的运行。
本人的硬软件配置如下:
GPU: RTX3060 6GB显存
内存: 32GB
系统: Windows 111. Anaconda3 + Pycharm 的环境搭建
我使用的是Anaconda3 + PyCharm 的环境搭建。
首先下载去anaconda官网下载最新版的anaconda.
安装时注意选择Add Anaconda3 to PATH, 这样可以直接在Pycharm的终端上运行。
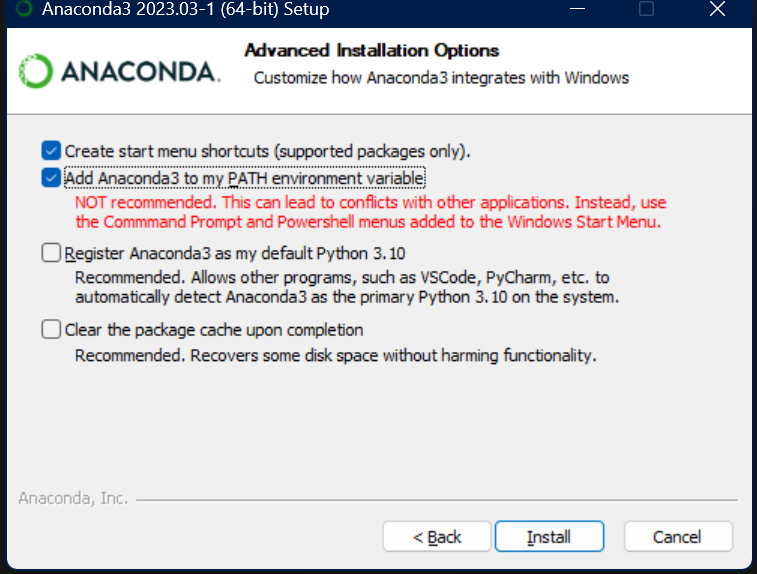
等待安装完毕后,进入Pycharm官网安装IDE
直接下载Community版本,然后安装过程中全部点击通过即可。
安装Pycharm完毕之后,需要创建一个新的anaconda的虚拟环境。方便运行包的管理
进入cmd 命令提示符,输入:conda activate
激活conda,随后创建新的虚拟环境:conda create --name ChatGLM-6B python=3.10
这里的ChatGLM-6B是自定义名字,python的版本可以自行修改
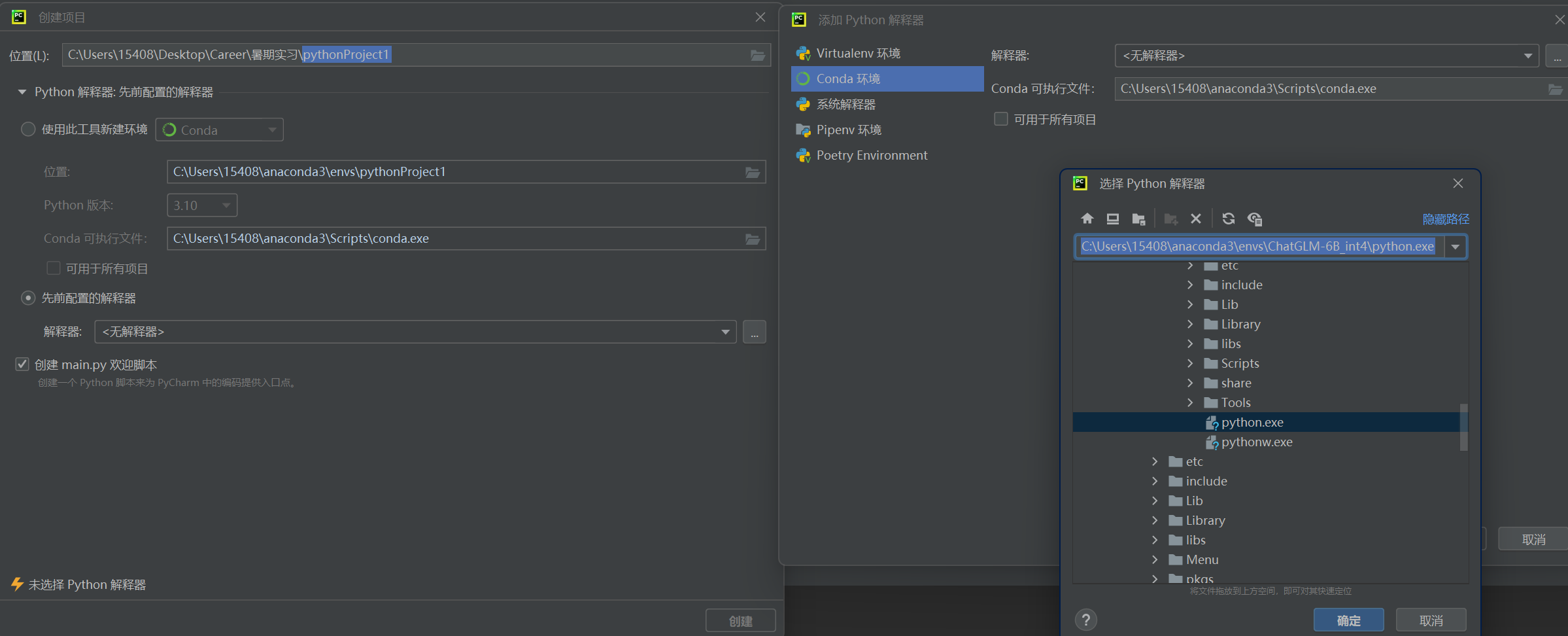
随后进入Pycharm,点击文件>新建项目>先前配置好的解释器, 如下图选择, 选择预先配置好的解释器,点击···,选择conda环境。 然后在可执行文件那里选择··· 选择到你刚刚创建的虚拟环境目录下(也就是envs\环境名称)找到python.exe)
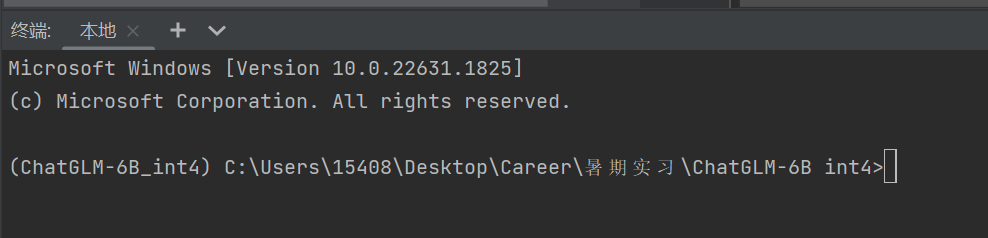
配置完毕后,打开Pycharm的终端,如果出现类似与这样,环境名称在括号中,说明配置虚拟环境成功。
2. Pytorch的安装
在anaconda环境配置完毕之后,需要安装模型所需要最重要的包,Pytorch。
先点击Pytorch官网 看到如下界面:

根据自己显卡的Cuda版本来进行选择,随后在Pycharm的终端输入命令下载Pytorch
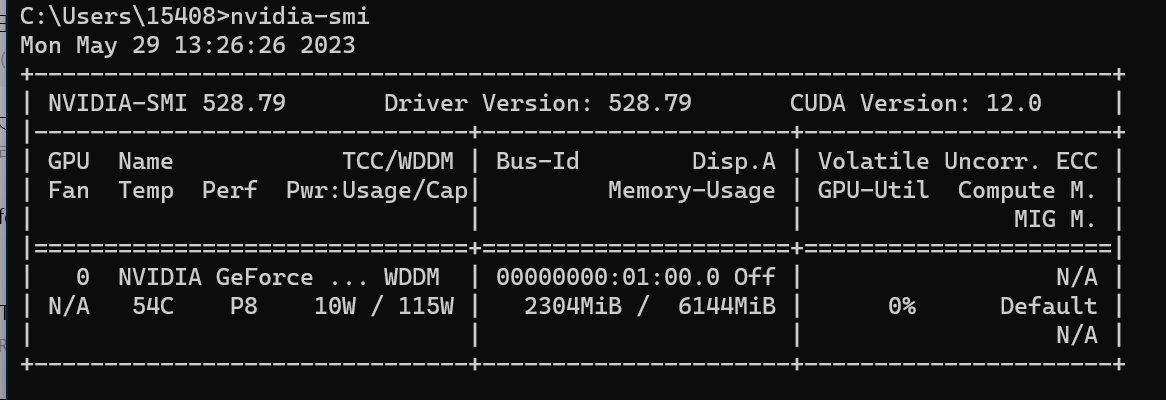
如果不知道Cuda是多少,可以运行cmd,输入nvidia-smi 查看Cuda版本:
安装完毕后,输入
import torch
torch.cuda.is_available()如果输出True,说明Pytorch配置完毕!

3. 安装ChatGLM-6B 代码
目前为止所有准备工作就绪,可以安装ChatGLM-6B的代码了。
进入存有ChatGLM-6B的Github 在确保计算机安装Git的情况下,在Pycharm的终端下git clone repo到项目文件夹下。当然如果电脑没有配置Git环境就需要下载下来解压到目录即可。
目录路径如下: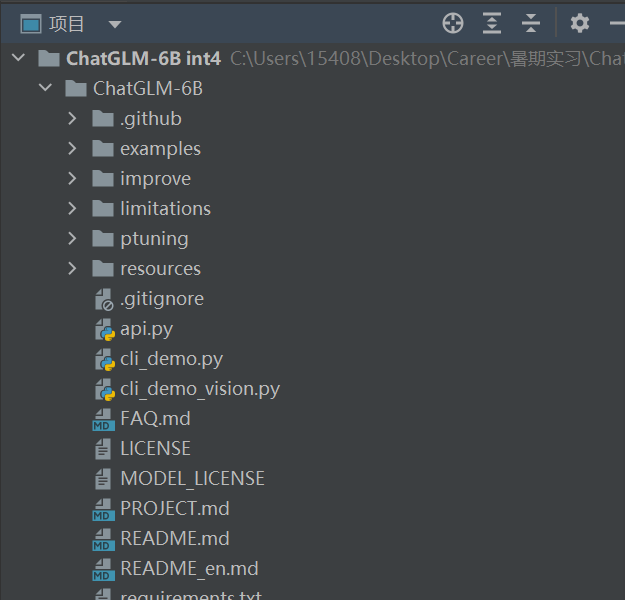
然后继续在终端输入命令,cd到requirement.txt的目录下,然后用pip命令安装ChatGLM-6B所需要的所有软件包:
pip install -r requirements.txt
等待安装完毕后,ChatGLM-6B的环境就配置完成了。
4. 预训练的下载与测试
在安装完CharGLM-6B的代码之后,我们依然需要下载预训练的模型。进入预训练模型下载网址 将里面全部的文件下载到一个文件夹下,注意这个文件夹可以不在Pycharm的项目之内,例如我下在D:\\data\\llm\\chatglm-6b-int4中。
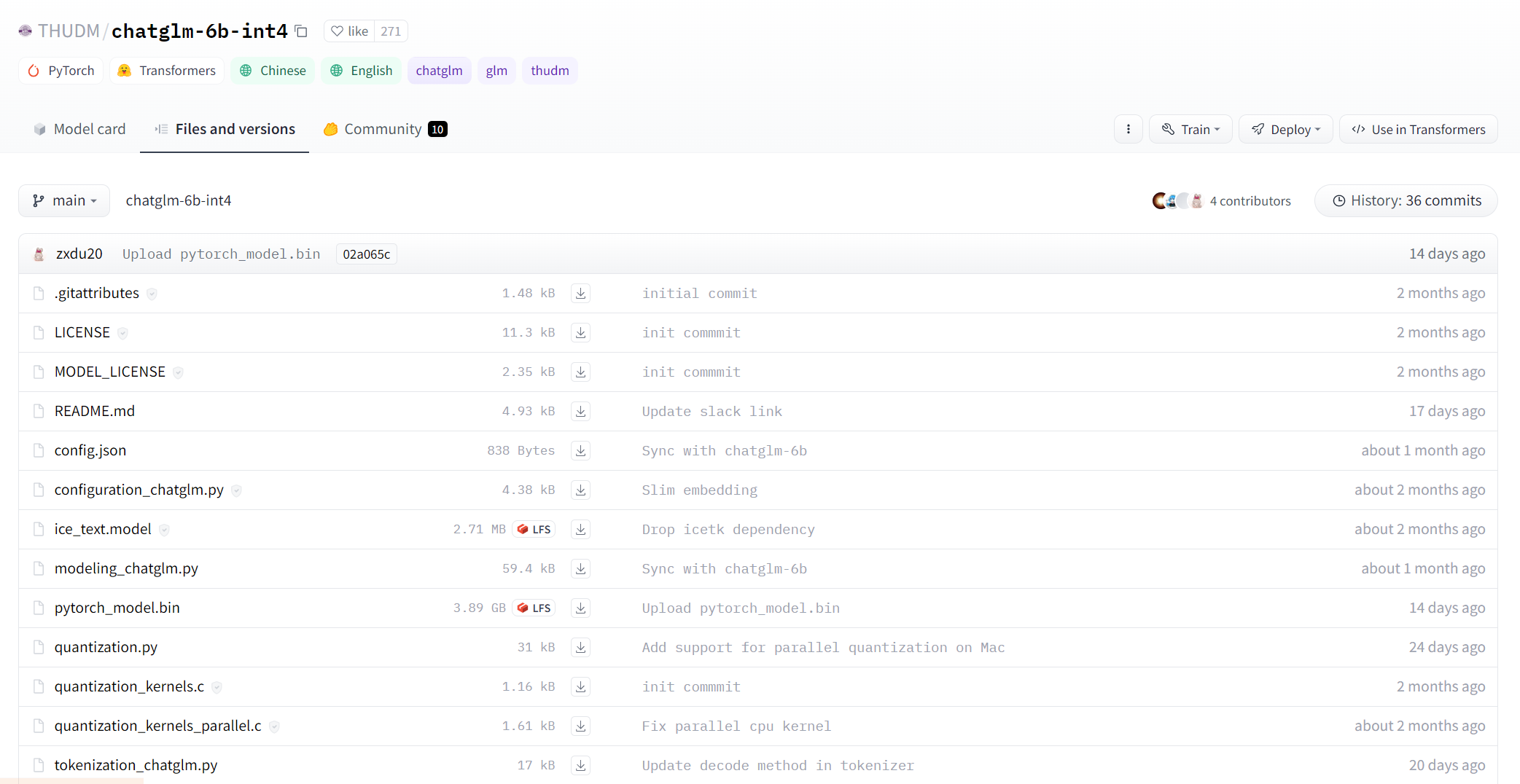
因为要下载数个GB的模型,所以下载时间可能会比较长,需要耐心等待~
下载完毕之后,就可以在Pycharm项目中创建可运行文件,我的叫做test.py 然后输入一下代码加载模型并开始测试:
import torch.cuda
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="")
model = AutoModel.from_pretrained("D:\\data\\llm\\chatglm-6b-int4", trust_remote_code=True, revision="").half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "介绍一下你自己", history=[])
print(response)
response, history = model.chat(tokenizer, "请问你能再重复一遍吗?谢谢!", history=history)
print(response)如下,如果一开始报错,请耐心等待,在30s左右模型会给出结果:
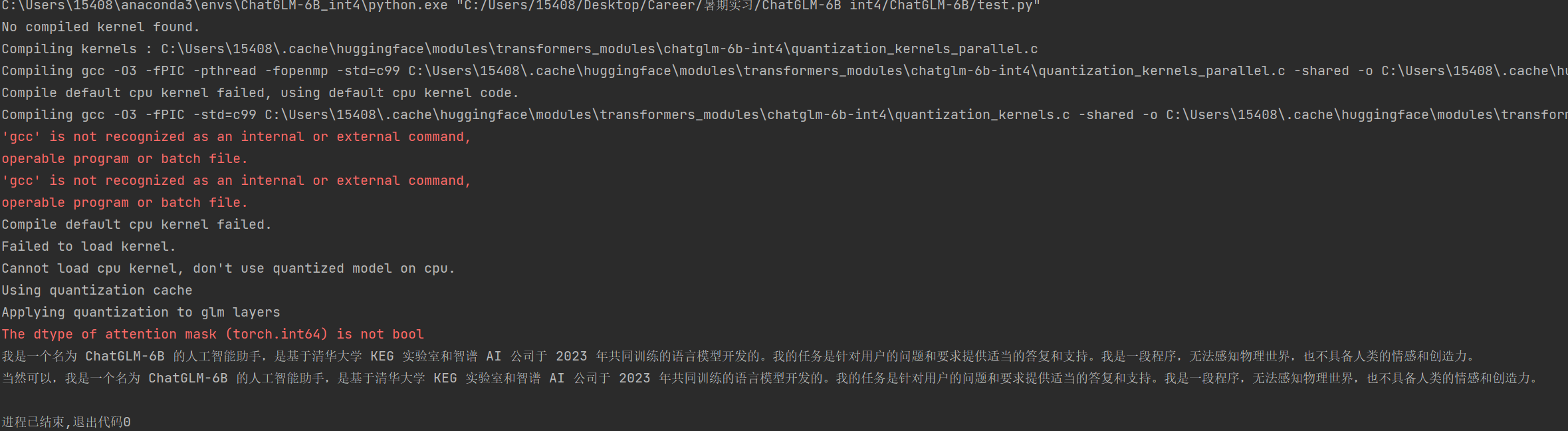
如果程序遇到如下报错
Kernel not compiled with GPU support
可能是显卡没有安装Cuda,进入NVIDIA官网 下载GPU所对应版本的CUDA Toolkit后重启即可。
5. 网页Demo的使用
一直用Python和模型对话还是会有些不太方便,因此官网也给出了网页式对话。
在Pycharm的终端gradio:
pip install gradio
然后打开程序web_demo.py 将里面原本的路径改为你自己预训练模型的存储位置,然后运行即可。
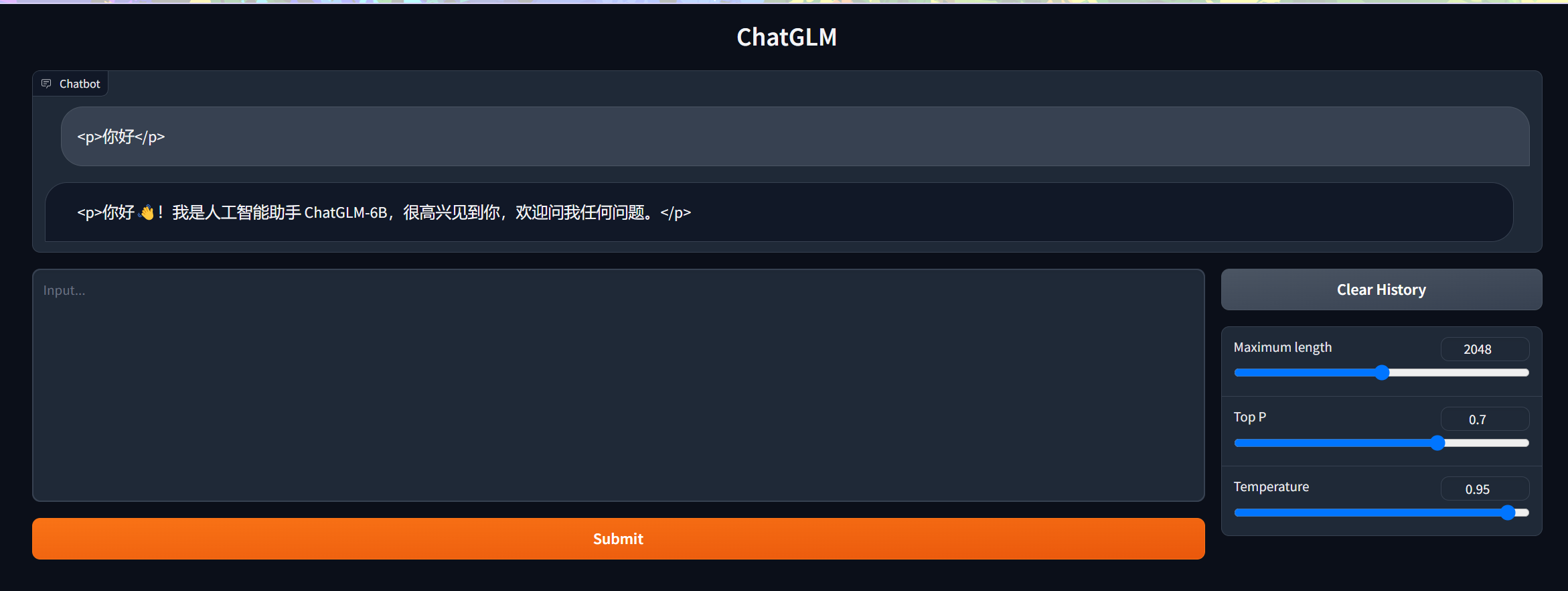
以上,就可以在本地安装并且使用ChatGLM了。















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









