







TSMaster信号映射模块可以将数据库变量映射为系统变量,经过映射后的系统变量就等同于数据库中的变量,该系统变量的读写操作就等同于读写数据库变量。其在系统软件中的位置如下图所示:
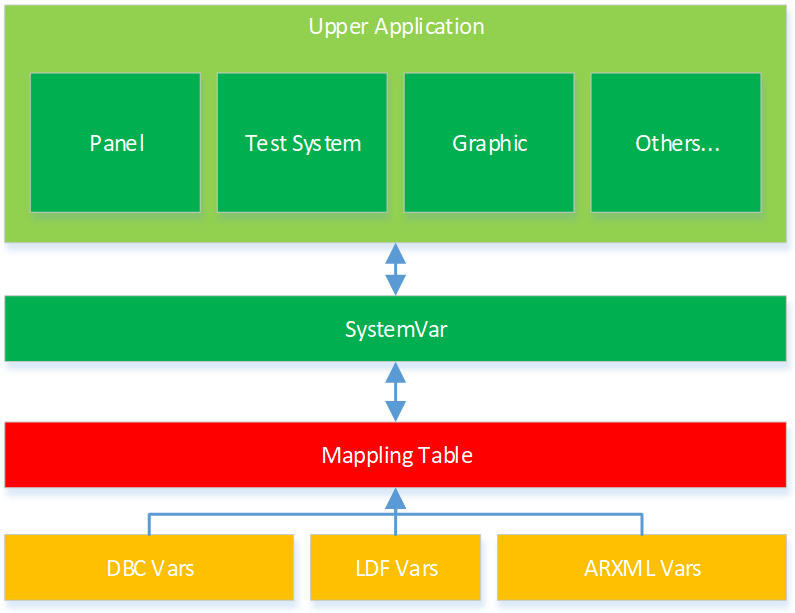
信号映射模块设计的目的,就是为了实现上层应用层逻辑和下层数据库变量的解耦合。如果上层应用层直接操作数据库中的变量,一旦数据库发生变动,介于这种强耦合关系,会造成上层开发,比如Panel,测试脚本等需要修改对应的数据库变量,对于大型工程项目来说,这种变动是不可接受的。采用信号映射模块,上层映射层不用直接操作数据库变量,直接使用映射后的系统变量,当下层数据库等发生变动时,只需重新将映射数据库变量到对应的系统变量即可,而不用修改上层的应用。本文将重点介绍TSMaster中添加信号映射的操作方法。
本文关键字:信号映射、系统变量、表达式映射
目录
Catalog
1. 直接映射的操作方法
2. 表达式映射的操作方法
3. 信号映射转换实例
一、直接映射的操作方法
1、信号映射模块路径:仿真-环境-信号映射
打开信号映射后,点击模块左上角激活按钮使能信号映射模块。如图1。
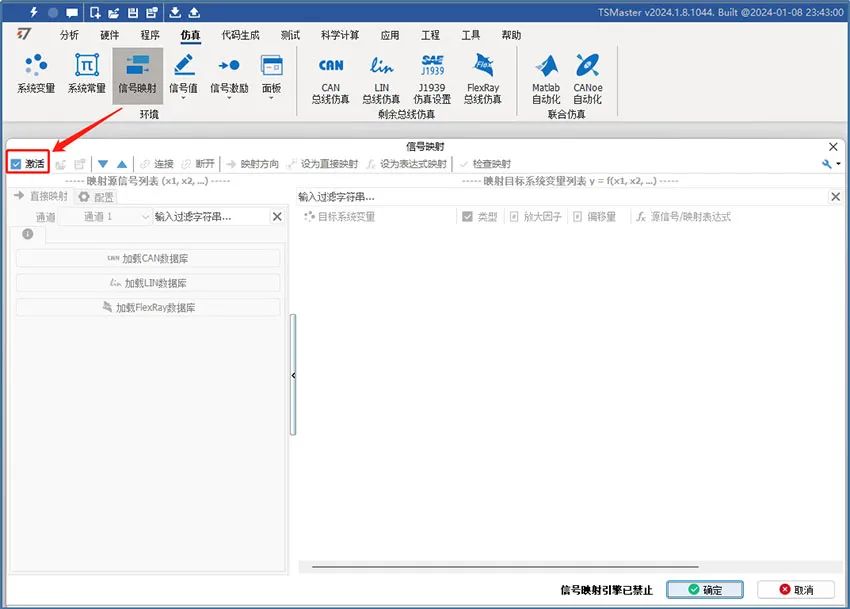
图1
选择数据库中的信号进行映射,以CAN数据库为例,如图2所示:
▲ Step1:选择【通道1】的数据库报文信号;
▲ Step2:选择需要映射的信号,比如“EngSpeed”信号;
▲ Step3: 鼠标右键,选择【自动创建映射】;
▲ Step4:在【映射目标系统变量列表】自动生成目标系统变量,默认为直接映射类型。
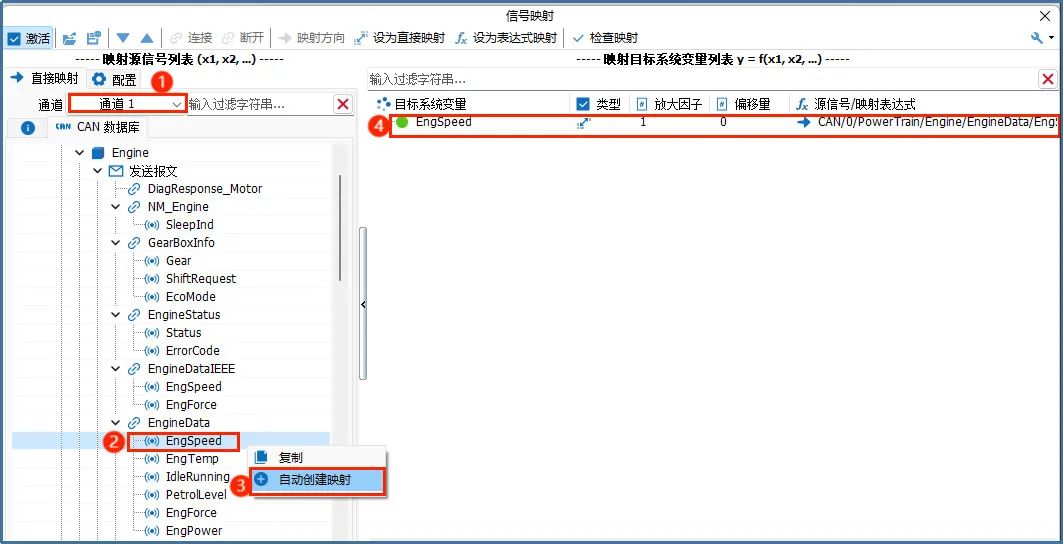
图2
▲ Step5: 当自动创建映射后,在【仿真-系统变量-用户变量列表】中会自动生成同名系统变量,如图3。

图3
2、映射方向的三种方式
直接映射方式可以理解为一对一的映射方式,可以选择信号映射的方向,TSMaster提供了三种方式:双向传递、仅从信号映射至系统变量、仅从系统变量映射至信号,以适配不同的映射需求,如图4。
1)双向传递:系统变量值的改变会同步到信号,信号值的改变会同步到系统变量。
2)仅从信号映射至系统变量:信号值的改变会同步到系统变量,系统变量值的改变不会同步到信号。
3)仅从系统变量映射至信号:系统变量值的改变会同步到信号,信号值的改变不会同步到系统变量。
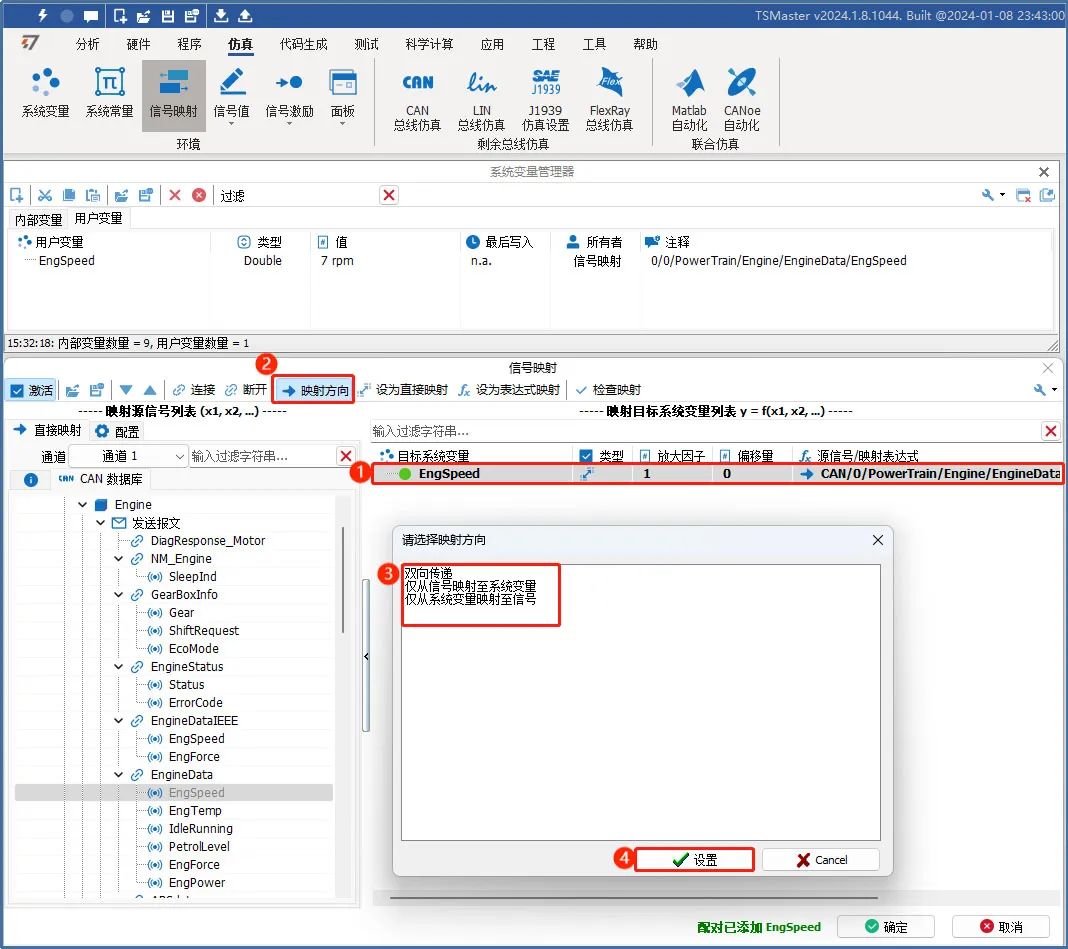
图4
操作步骤如下:
① 选择映射列表条目中目标系统变量;
② 点击【映射方向】弹出菜单;
③ 选择映射方向;
④ 点击【设置】完成选择。
二、表达式映射操作方法
1、表达式映射的说明
将所选表达式设置为表达式映射后可以编辑表达式,最终将自定义的算法表达式计算得到的结果映射到系统变量,自变量可以选择常量、系统变量、FlexRay信号、CAN信号、LIN信号。
TSMaster提供了一系列的数学函数列表及表达式,其中数学函数列表:
abs, acos, asin, atan, atan2, ceil, cos, cosh, e, exp, fac, floor, ln.
log, log10, max, min, ncr, npr, pi, pow, sign, sin, sinh, sqrt, tan, tanh
表达式示例:
[1] sqrt(x1n1.5 + x2n2.5)
[2] x1 * 3 + x2 / 1.2 - 11.9
[3] (1/(x1+1)+2/(x2+2)+3/(x3+3))
[4] (x1 > 50) & ((x2 <30) |(x3 = 1)
2、表达式映射的操作步骤
选择映射对后点击设置为表达式映射,在窗口右侧编辑计算方法,如图5。
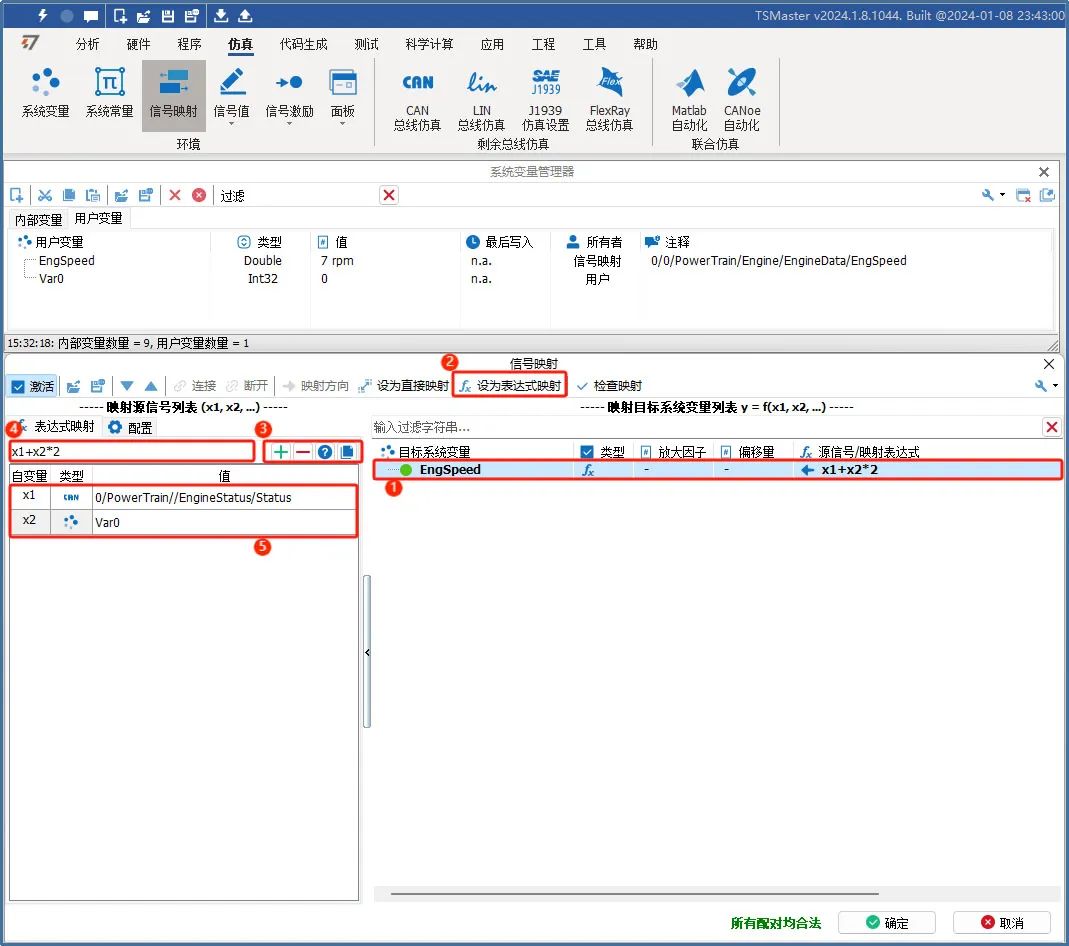
图5
① 选择映射目标系统变量
② 设置为表达式映射
③ 点击加号添加自变量
![]()
:添加自变量
![]()
:删除自变量
![]()
:查看任意表达式帮助
![]()
:复制当前表达式映射的C代码
④ 编辑计算方法表达式
⑤ 给计算表达式中的自变量赋值,自变量可以选择常量、系统变量、FlexRay信号、CAN信号、LIN信号
【检查映射】:完成信号映射列表的添加和配置后,可以选择检查当前映射,可以避免出现无效映射的情况。
【配置】:自动激活对应的RBS发送信号。勾选后映射列表中涉及的信号将会以RBS的方式仿真发送,如图6。
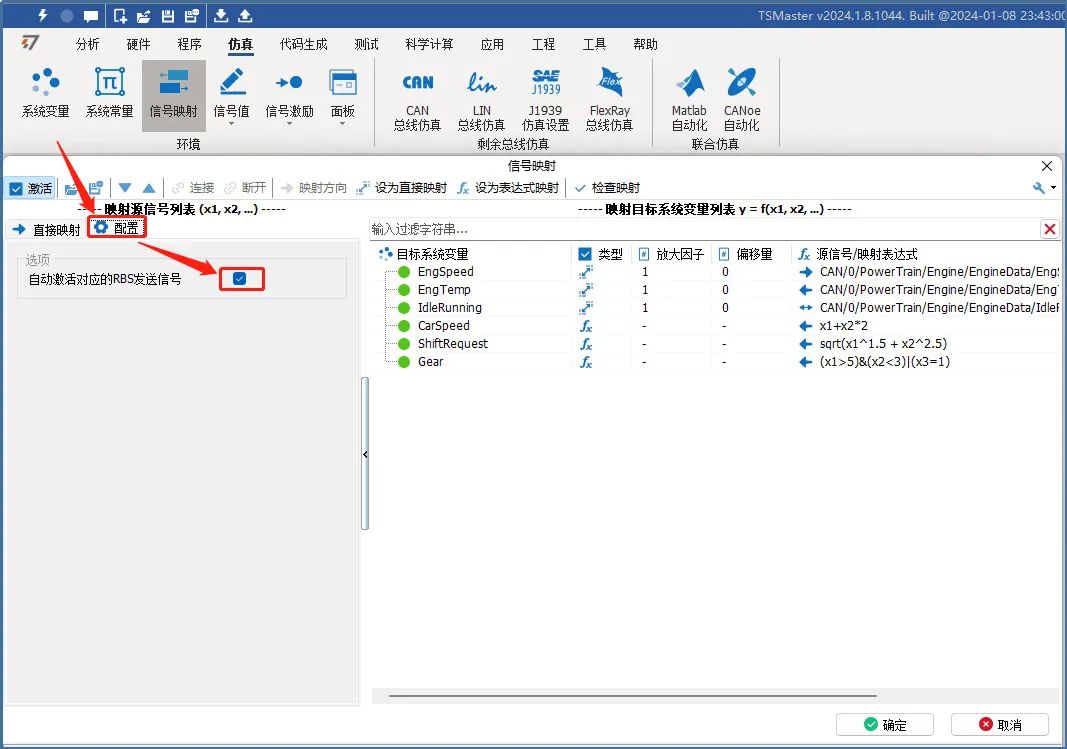
图6
配置好的映射信号列表,可以进行配置文件的保存与导入,如图7。
【配置文件保存】:信号映射对配置完成后可以将当前映射对配置导出到本地。
【配置文件导入】:可以将当前信号映射列表导出.ini文件。

图7
三、信号映射转换实例
汽车车速与发动机转速之间有一种常见的转换关系计算,车速(km/小时)=发动机转速x 60 x 3.14 x轮胎直径/(1000X主减速比x对应档位传动比)。通常轮胎直径、主减速比、对应档位传动比可以通过汽车手册查得,再通过已知的发动机转速,使用信号映射计算出汽车的车速,即:车速CarSpeed= 发动机转速*60*3.14*0.724/(1000*3.683*0.672)。
在TSMaster的信号映射里创建好目标系统变量“CarspeedMappingFromEngSpeed”,设置为表达式映射,x1绑定汽车发动机转速EngSpeed,如图8。
CarspeedMappingFromEngSpeed = x1*60*3.14*0.724/(1000*3.683*0.672)

图8
配置好信号映射表达式后,可以修改EngSpeed的发送值为1000 rpm,经过信号映射后可以自动计算车速为55.1 km/h, 如图9。
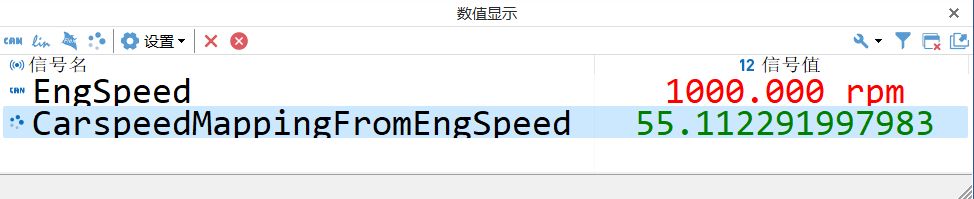
图9
同样,继续修改EngSpeed的发送值为2000 rpm,经过信号映射后可以自动计算车速约为110.2 km/h, 如图10。
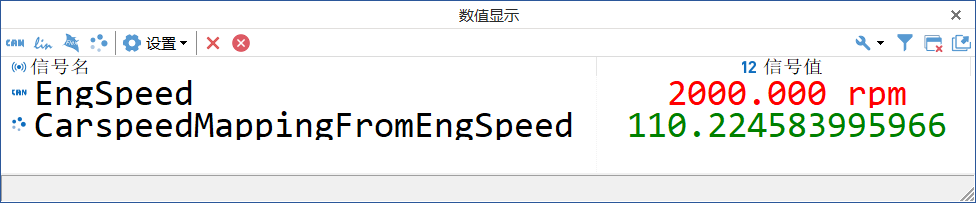
图10
以上是信号映射模块使用操作流程和示例,信号映射出来的系统变量可以直接被我们的panel模块、信号测试模块、信号比较模块、C小程序、图形模块等模块访问和使用,信号映射是我们TSMaster中实现模块互通的一员,合理使用信号映射模块可以有效提高基于TSMaster的工程开发效率。
















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











