







Redis核心技术与实战
实践篇
25 | 缓存异常(上):如何解决缓存和数据库的数据不一致问题?
缓存和数据库的数据不一致是如何发生的?
缓存和数据库的一致性包含了两种情况:
- 缓存中有数据,那么,缓存的数据值需要和数据库中的值相同;
- 缓存中本身没有数据,那么,数据库中的值必须是最新值。
对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略。 在业务应用中,要使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,就无法实现同步直写。
对于只读缓存来说,如果有数据新增,会直接写入数据库;而有数据删改时,就需要把只读缓存中的数据删除。 这样一来,应用后续再访问这些增删改的数据时,因为缓存中没有相应的数据,就会发生缓存缺失。此时,应用再从数据库中把数据读入缓存,这样后续再访问数据时,就直接从缓存中读取。
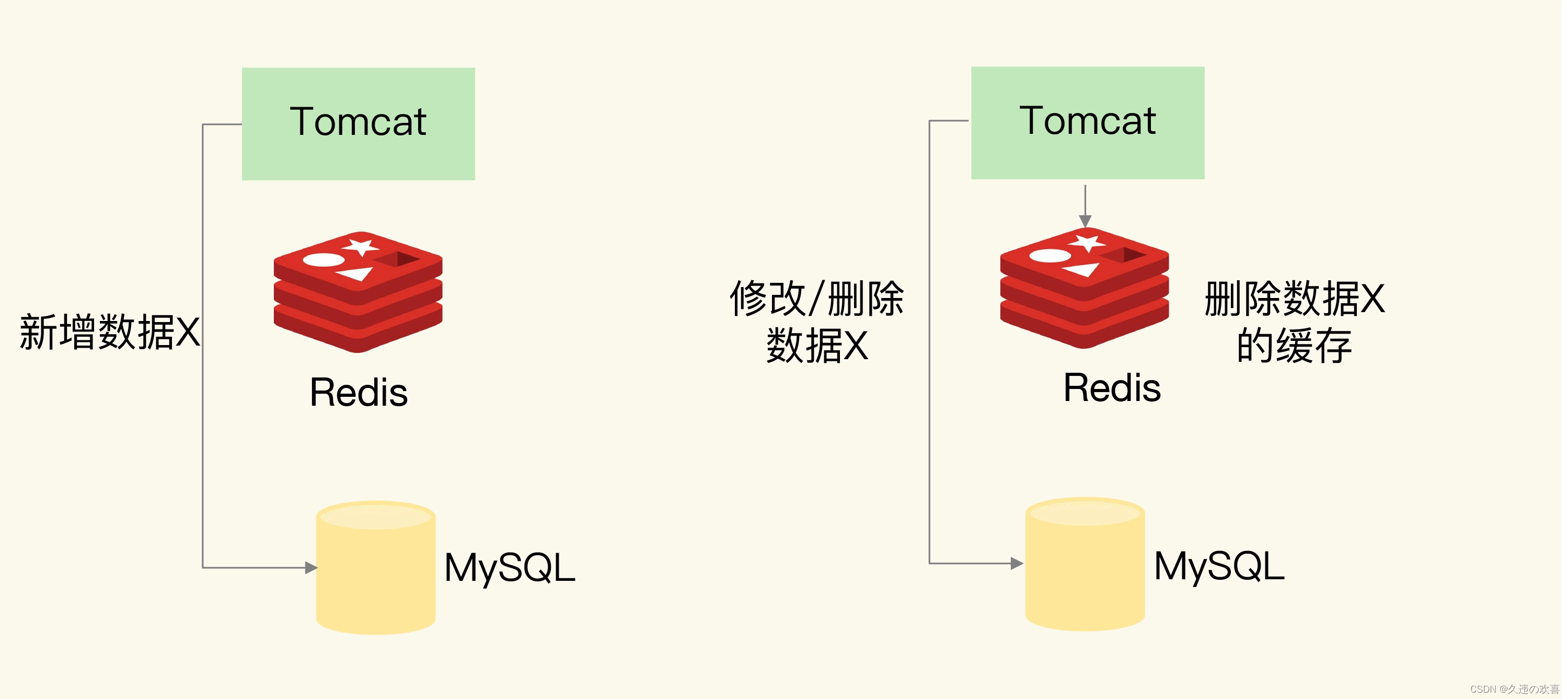
1. 新增数据
如果是新增数据,数据会直接写到数据库中,不用对缓存做任何操作,此时,缓存中本身就没有新增数据,而数据库中是最新值,这种情况符合上述所说的一致性的第 2 种情况,所以,此时,缓存和数据库的数据是一致的。
2. 删改数据
删改操作如果无法保证原子性,就会出现数据不一致问题。
假设应用先删除缓存,再更新数据库,如果缓存删除成功,但是数据库更新失败,那么,应用再访问数据时,缓存中没有数据,就会发生缓存缺失。然后,应用再访问数据库,但是数据库中的值为旧值,应用访问到的就是旧值。
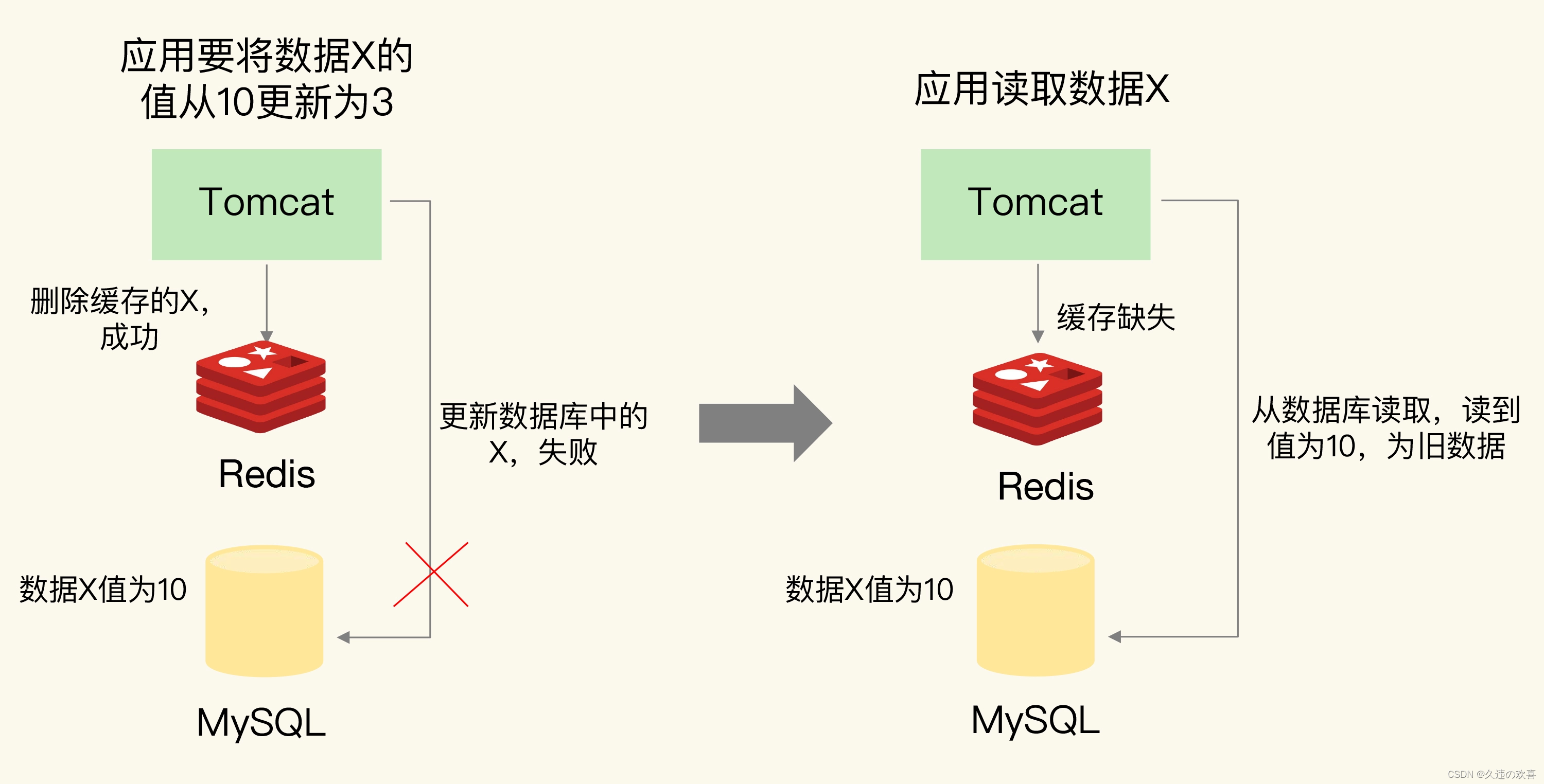
如果应用先完成了数据库的更新,但是,在删除缓存时失败了,那么,数据库中的值是新值,而缓存中的是旧值,这肯定是不一致的。这个时候,如果有其他的并发请求来访问数据,按照正常的缓存访问流程,就会先在缓存中查询,但此时,就会读到旧值。


如何解决数据不一致问题?
重试机制
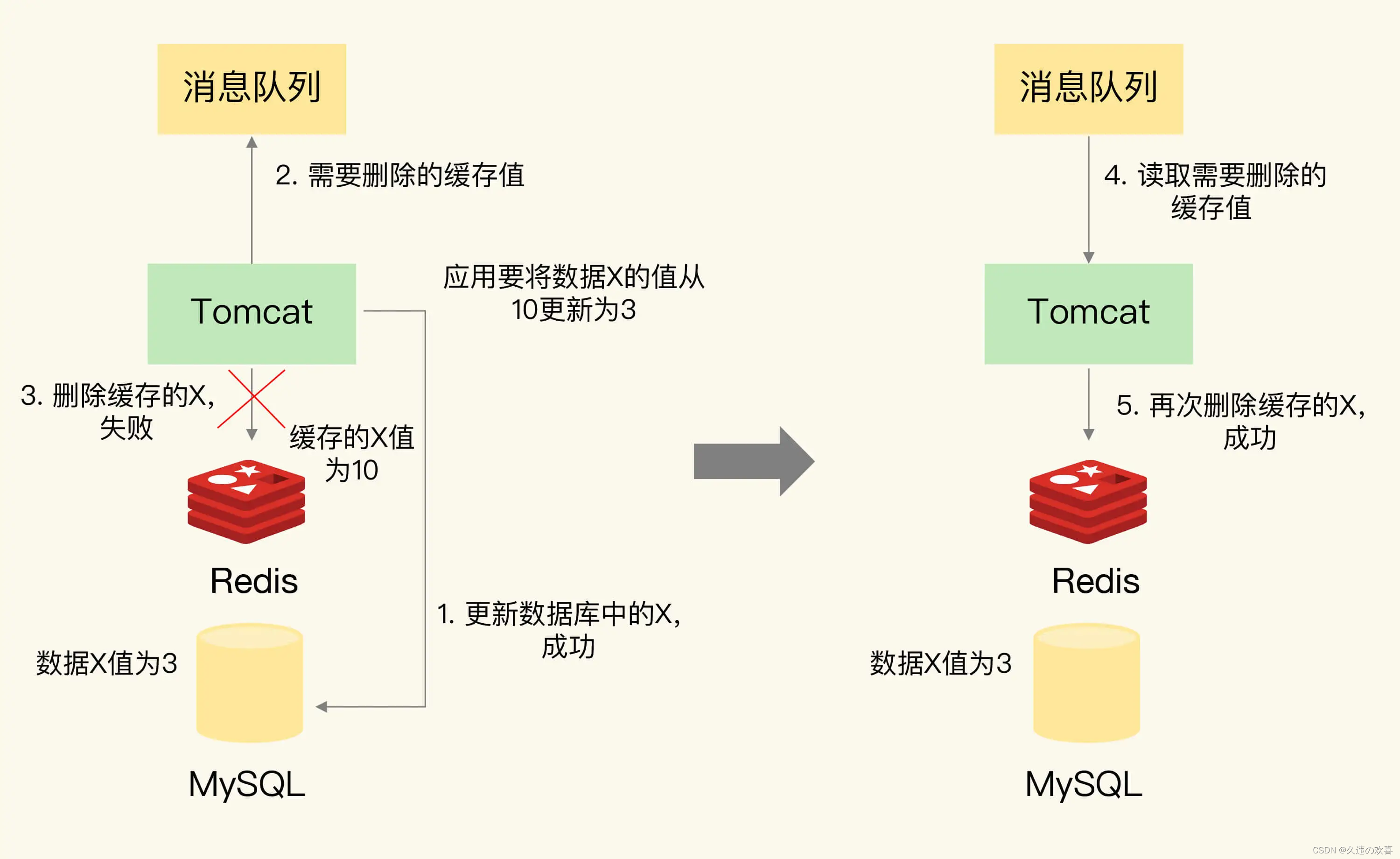
具体来说,可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用 Kafka 消息队列)。当应用没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
如果能够成功地删除或更新,就把这些值从消息队列中去除,以免重复操作,此时,就可以保证数据库和缓存的数据一致。否则的话,还需要再次进行重试,如果重试超过的一定次数,还是没有成功,就需要向业务层发送报错信息。
实际上,即使这两个操作第一次执行时都没有失败,当有大量并发请求时,应用还是有可能读到不一致的数据。
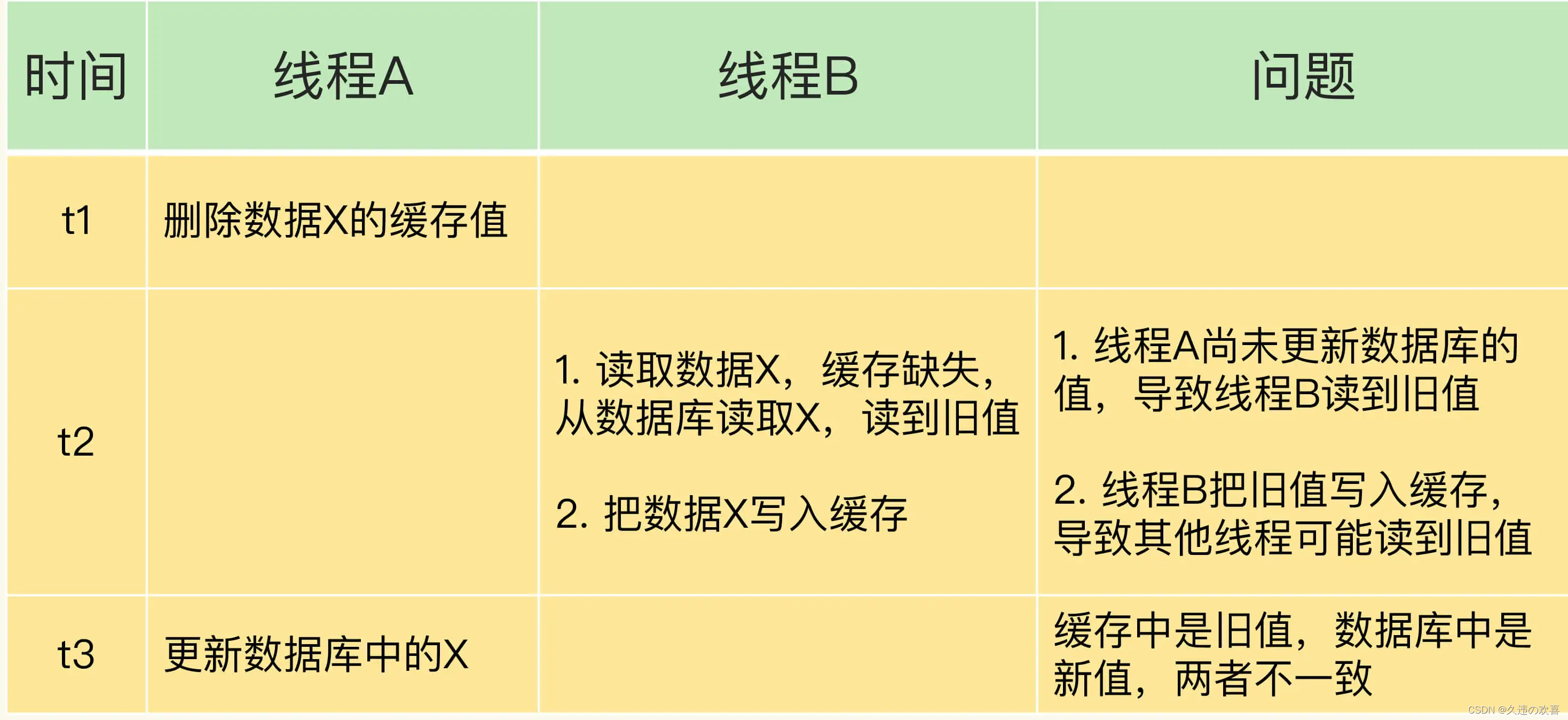
情况一:先删除缓存,再更新数据库。
假设线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,那么这个时候,线程 B 会发现缓存缺失,就只能去数据库读取。这会带来两个问题:
- 线程 B 读取到了旧值;
- 线程 B 是在缓存缺失的情况下读取的数据库,所以,它还会把旧值写入缓存,这可能会导致其他线程从缓存中读到旧值。
等到线程 B 从数据库读取完数据、更新了缓存后,线程 A 才开始更新数据库,此时,缓存中的数据是旧值,而数据库中的是最新值,两者就不一致了。
解决方案:
在线程 A 更新完数据库值以后,可以让它先 sleep 一小段时间,再进行一次缓存删除操作。 之所以要加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程 A 再进行删除。
这样一来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,所以也把它叫做 “延迟双删”。
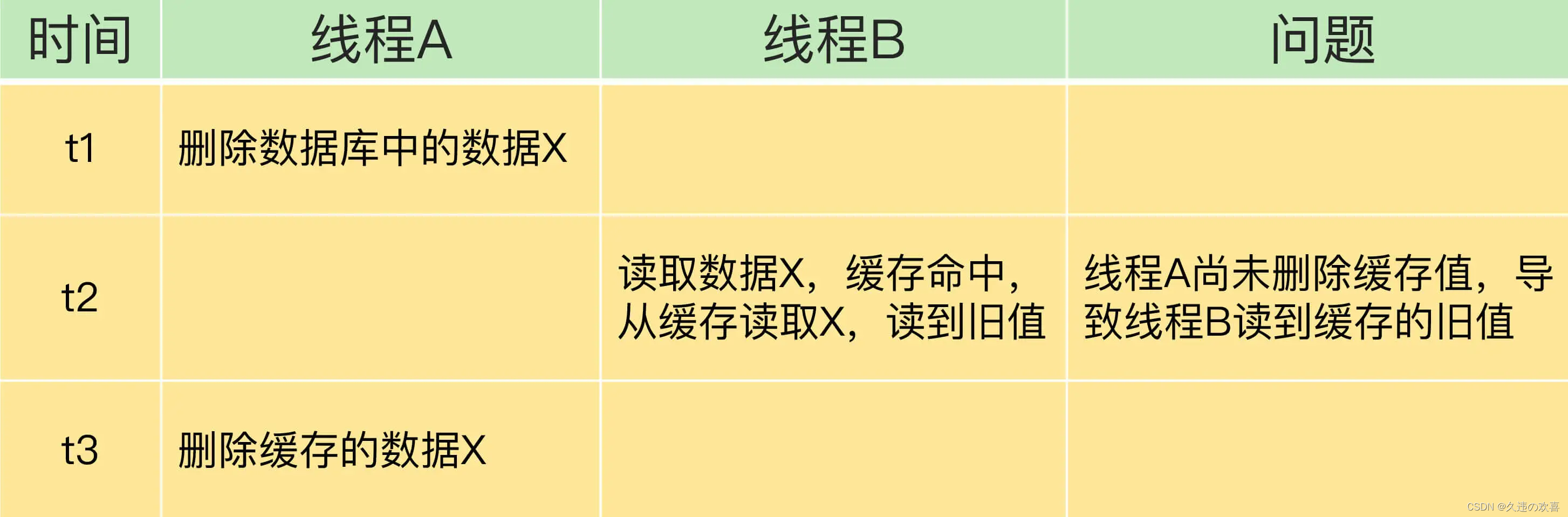
情况二:先更新数据库值,再删除缓存值。
如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。不过,在这种情况下,如果其他线程并发读缓存的请求不多,那么,就不会有很多请求读取到旧值。而且,线程 A 一般也会很快删除缓存值,这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。
















 2214
2214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











