






前言
基于Flask+Echarts+Mysql制作分析新能源车辆数据可视化
一、配置Mysql
配置MySQL数据库:首先,确保您已经安装了MySQL,并创建了相应的数据库和数据表。您可以使用MySQL的命令行界面或可视化工具进行这些操作。创建表时,确保您包含了要在图表中使用的数据字段。
# 1.连接到mysql数据库
conn = pymysql.connect(host='xxx', user='root', password='xxx', db='qimozuoye', charset='utf8')
cursor = conn.cursor() # cursor当前的程序到数据之间连接管道
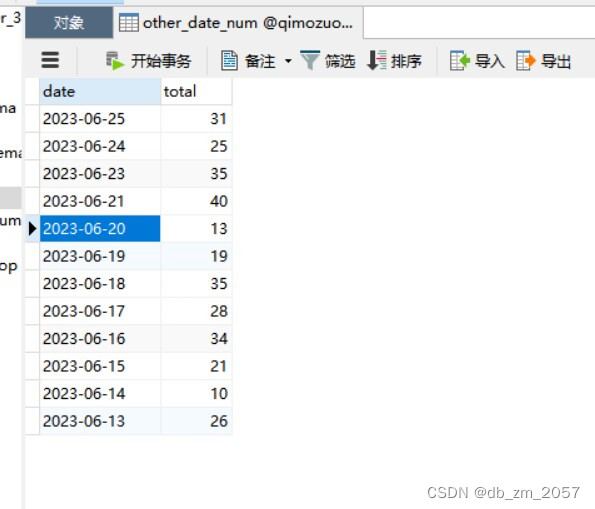
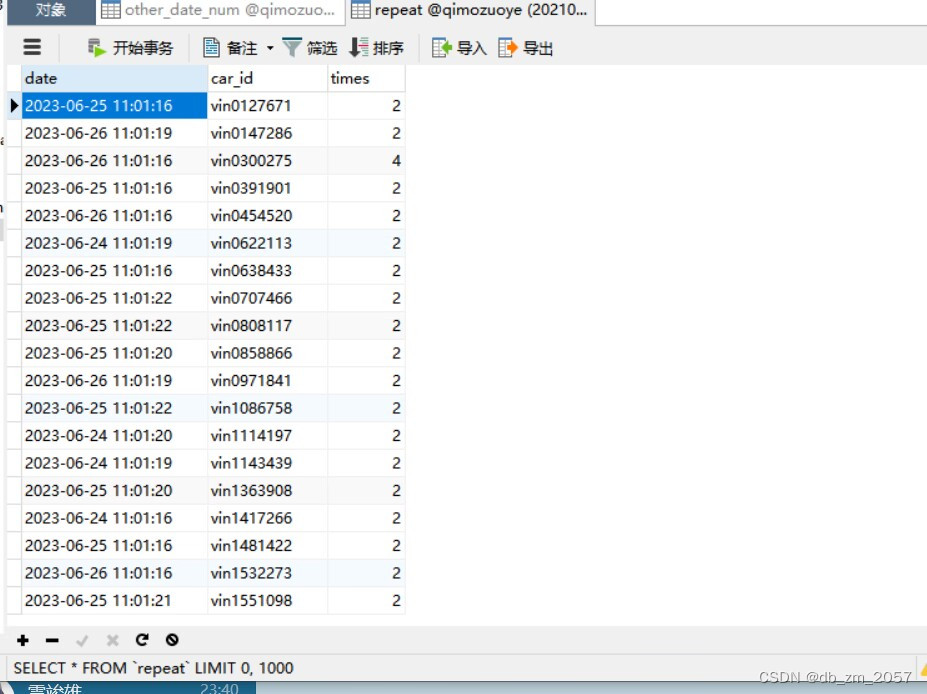
Mysql数据如下:
二、使用步骤
1.初始化Flask应用程序
创建一个Flask应用程序,并设置与MySQL数据库的连接。在应用程序的配置文件中,指定数据库的连接参数,例如数据库名称、用户名和密码。使用Flask的数据库扩展,如SQLAlchemy或MySQLdb,连接到MySQL数据库。
代码如下(示例):
# 导入所需的库和模块
from flask import Flask, render_template
import pymysql
import json
# 创建Flask应用程序
app = Flask(__name__)
# 运行Flask应用程序
if __name__ == '__main__':
app.run()
2.读入数据
查询MySQL数据:使用SQL语句编写查询,从MySQL数据库中检索您想要在图表中使用的数据。通过在Flask应用程序中定义适当的路由和视图函数,将查询结果传递给前端。
代码如下(示例):
# 饼图的数据
sql = 'select * from other_date_num'
cursor.execute(sql)
all_other_date_num = cursor.fetchall()
print(all_other_date_num)
3.创建ECharts图表
在前端使用ECharts库创建图表。您可以使用JavaScript编写代码,在HTML文件中嵌入ECharts的相关代码。定义一个具有合适配置的容器元素,以显示图表,并使用从Flask应用程序传递的数据填充图表。
代码如下(示例):
<div id="pie" style="width:900; height:350px;"></div>
<script src="./echarts/pie.js"></script>
4.渲染图表
在Flask应用程序中定义一个路由和视图函数,用于将图表页面渲染给用户。在视图函数中,将前端HTML文件与从MySQL数据库检索到的数据进行组合,并将其返回给用户。
@app.route('/data_other_date_num')
# 饼图
def other_date_num():
list_other_date_num = list(all_other_date_num)
print(list_other_date_num)
num = 0
data_other_date_num = []
for i in list_other_date_num:
a = list_other_date_num[num]
b = a[0]
c = a[1]
data_other_date_num.append({'value': c, 'name': b})
num += 1
return jsonify(data_other_date_num)
下面是结果图:
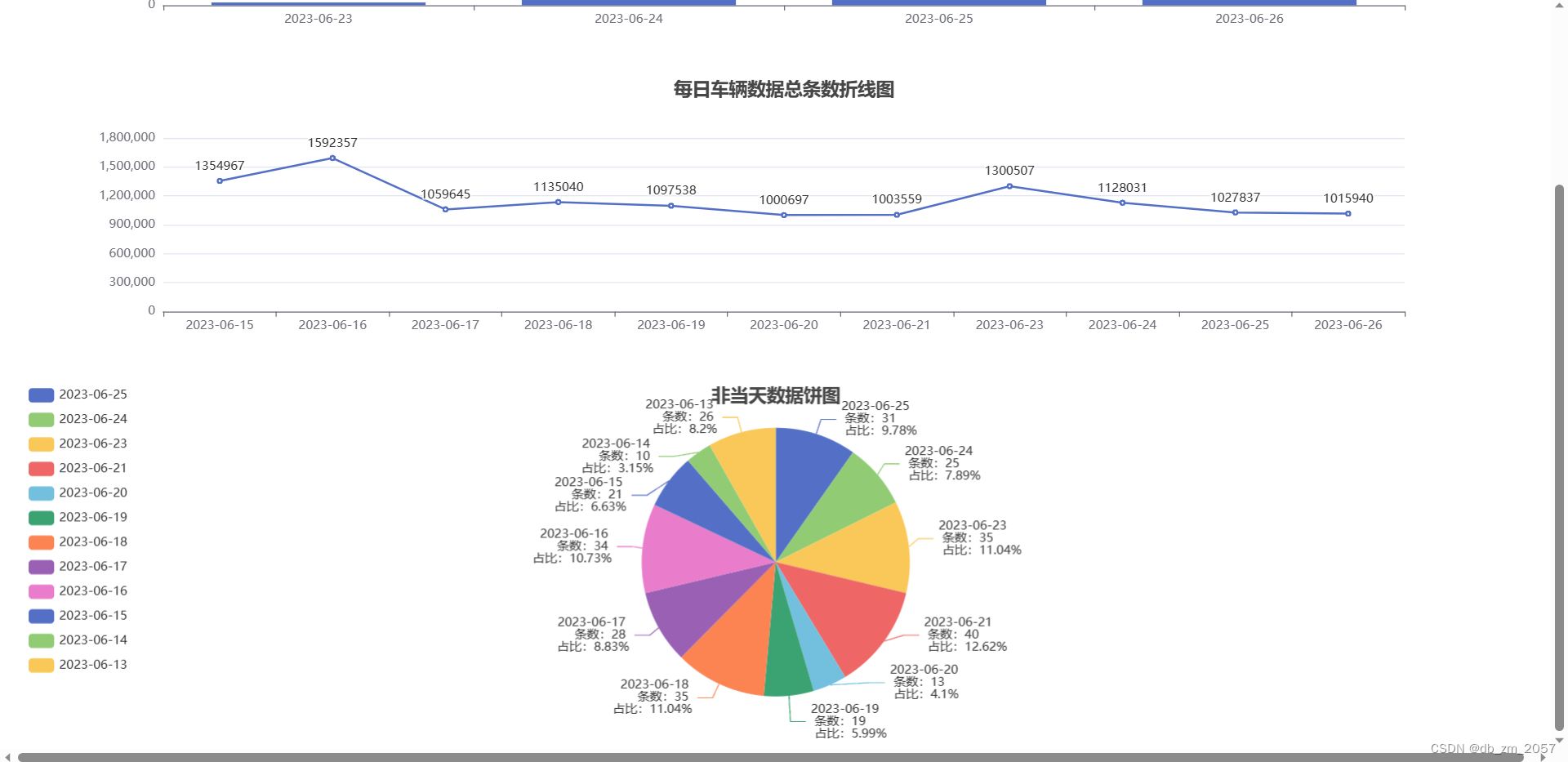
总结
这是一个基本的MySQL、Flask和ECharts结合的图表绘制过程。
学习总结
学习Hadoop是一个令人兴奋和富有挑战性的过程。在我的学习过程中,我掌握了一些关键的心得体会:
-
深入理解分布式计算原理:Hadoop是一个分布式计算框架,学习Hadoop需要深入理解分布式计算的基本原理和概念,如数据分片、数据复制、容错处理等。这对于充分发挥Hadoop的能力至关重要。
-
掌握Hadoop核心组件:Hadoop由多个核心组件组成,包括Hadoop分布式文件系统(HDFS)和Hadoop MapReduce。深入了解和掌握这些组件的工作原理和用法是学习Hadoop的关键。了解Hadoop生态系统中的其他组件,如Hbase、Hive等,也是非常有帮助的。
-
实践是提高的关键:学习Hadoop最好的方式是通过实践。建议使用Hadoop提供的示例数据集,尝试在本地环境或虚拟机上搭建Hadoop集群,并编写MapReduce程序来处理数据。通过实际动手操作,您将更好地理解Hadoop的工作原理和实际应用。
-
借助丰富的学习资源:Hadoop有广泛的学习资源可供利用。官方文档、教程、视频课程和在线论坛都是宝贵的学习资料。参加Hadoop相关的培训课程或社区活动,与其他Hadoop开发者交流经验也是一种有效的学习方式。
-
熟悉生态系统和工具:Hadoop生态系统提供了丰富的工具和框架,用于数据处理、数据仓库、数据可视化等各个方面。如Apache Spark、Apache Hbase、Apache Hive等,可以帮助更好地利用Hadoop进行大规模数据处理和分析。
-
持续学习和跟进最新发展:Hadoop是一个快速发展的领域,不断涌现出新的技术和工具。因此,持续学习和跟进最新的Hadoop发展非常重要。关注Hadoop社区、博客和相关的学术研究,保持对新技术和趋势的了解。
总的来说,学习Hadoop需要耐心和实践,但掌握Hadoop的技能将为您提供处理大规模数据和构建分布式系统的能力。无论是从事大数据工程师、数据科学家还是数据分析师等角色,掌握Hadoop都是非常有价值的技能。














 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









