







多层感知机
隐藏层
线性模型的局限性
线性模型意味着任何特征的变化都会同步影响结果进行线性变化。但实际上很多事情并不是线性的,例如:收入增长和还款概率,当收入从 0 → 5 0\rightarrow5 0→5 时的还款提升概率比 100 → 105 100\rightarrow 105 100→105 时高的多,这时可以考虑以收入的对数作为特征,再使用线性模型。
但还存在一些例子不能经过简单处理就能使用线性模型的,当处理图像分类问题时,某一个像素点增强并不能同步增强对某一物体分类的概率,而是需要和周围像素点一起进行判断。
加入隐藏层
用一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层的输出都是下一层的输入,直到生成最后的输出。 我们可以把前
L
−
1
L-1
L−1 层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。 下面,我们以图的方式描述了多层感知机。
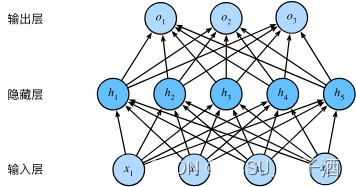
从线性到非线性(激活函数)
我们用 X X X 表示输入的小批量样本, H H H 表示隐藏层的输出, O O O 表示最终输出,那么上述模型可以表示为 H = X W 1 + b 1 H=XW_1+b_1 H=XW1+b1 O = H W 2 + b 2 O=HW_2+b_2 O=HW2+b2
但这两个函数本质上和之前并无不同,因为线性函数和线性函数简单叠加仍然是线性函数。这时我们就要加入激活函数(
σ
(
⋅
)
\sigma(\cdot)
σ(⋅))来改变其为非线性,简单来说就是将隐藏层的输出经过激活函数转换后再输入进下一层。
H
=
σ
(
X
W
1
+
b
1
)
H=\sigma(XW_1+b_1)
H=σ(XW1+b1)
O
=
H
W
2
+
b
2
O=HW_2+b_2
O=HW2+b2
可以堆叠多层的这样的带激活函数的隐藏层产生更有表达能力的模型。
激活函数
介绍一些常用的激活函数,设 x x x 为要经过激活函数的值
ReLU 函数
丢弃所有的负值
R
e
L
U
(
x
)
=
max
(
0
,
x
)
ReLU(x)=\max(0,x)
ReLU(x)=max(0,x)
sigmoid函数
sigmoid函数将输入变换为区间
(
0
,
1
)
(0, 1)
(0,1) 上的输出。 因此,sigmoid通常称为挤压函数(squashing function)
s
i
g
m
o
i
d
(
x
)
=
1
1
+
exp
(
−
x
)
sigmoid(x)=\frac1{1+\exp(-x)}
sigmoid(x)=1+exp(−x)1
tanh函数
tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。
t
a
n
h
(
x
)
=
1
−
exp
(
−
2
x
)
1
+
exp
(
−
2
x
)
tanh(x)=\frac{1-\exp(-2x)}{1+\exp(-2x)}
tanh(x)=1+exp(−2x)1−exp(−2x)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









