







 本文介绍了如何在Android应用中使用jsoup库解析HTML网页,以获取博客列表的标题。首先分析网页结构,识别出博客标题的HTML标签,接着配置并引入jsoup库,最后编写代码提取数据并展示在ListView中。通过点击标题,可以在WebView中加载对应博客详情页。
本文介绍了如何在Android应用中使用jsoup库解析HTML网页,以获取博客列表的标题。首先分析网页结构,识别出博客标题的HTML标签,接着配置并引入jsoup库,最后编写代码提取数据并展示在ListView中。通过点击标题,可以在WebView中加载对应博客详情页。
本文主要记录通过网页解析得到自己想要的数据,也就是一个简单的爬虫。将使用第三方库jsoup实现,通过第三方库,能够快速方便的解析html。在开始之前,需要具备以下能力:
- 首先,需要对网页编程有一点了解,知道一个页面的结构,标签的含义,知道html网页其实是一种xml格式的文件。如果对这些都了解的话,就可以很方便的进行网页解析了,如果不太熟悉,建议先了解一下网页编程。
- 然后,在使用第三方库之前,最好是先看一下官方文档:Jsoup官方文档,Jsoup文档中文版
接下来就通过一个具体需求来实现。假设需求是一个Android端的博客浏览器,第一页是博客标题的列表,点击单个标题可以进入第二个页面,第二个页面是一个WebView,通过第一个页面传入的url加载指定博客的网页。以上这个简单的需求,两个页面实现,当然重点是在第一个页面,怎样获取博客标题的列表?
1.分析网页结构
在解析一个网页之前,需要先了解这个网页的结构,在PC端通过浏览器的开发者工具就能很方便的查看网页结构,比如在Chrome中,按F12就可以出现开发者工具。接下来就是分析博客列表页面的结构:
根据需求,我要得到博客标题的列表,于是,在Chrome中,打开指定页面,右键选择某个标题,选择“审查元素”在右边就能看到指定标题的代码:
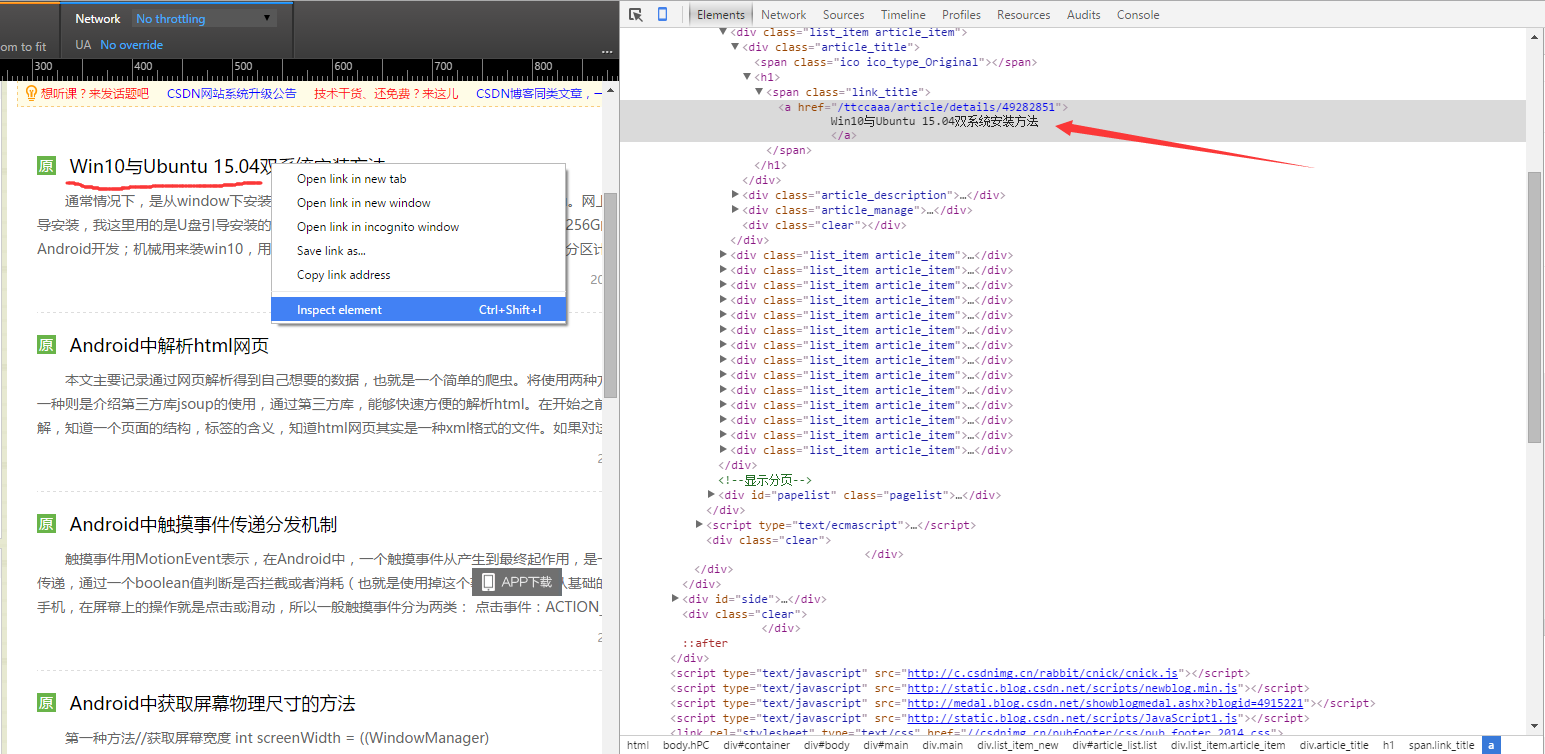
从网页源码中,需要的内容的结构:
<span class="link_title"><a href="/ttccaaa/article/details/49282851">
Win10与Ubuntu 15.04双系统安装方法
</a></span>一个< span >标签,里面有一个超链接标签< a >,链接指向博客内容的网页,到此,思路就比较清晰了,只需要提
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1748
1748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









