







用户数据仓库
赚跟多人的钱,用户分析,运营
当前赚了多少钱,业务报表,财务
一、项目背景
1、项目概述
根据业务系统中采集的用户行为日志数据,实现:
- 1)数据采集平台
- 2)数据仓库搭建,实现对平台层用户维度分析。
- 3)数据仓库的调度
分析平台层用户维度,对用户活跃、新增、留存、沉默、流失、回流等8个主题的分析。
- 0)活跃用户:
- 1)新增用户:今天活跃表 leftjoin 新增表(历史新增),活跃表存在但是新增表没有,证明是新增的
- 2)留存用户:今天活跃表 leftjoin 上周一新增用户, 两个表都存在的用户为留存用户。
留存率: 留存用户数/上周的新增用户数。 - 3)回流用户(本周的老用户上周没活跃,本周活跃的,上周没活跃,但上周以前活跃了 ):本周活跃-本周新增-上周活跃,- 为leftjoin
- 4)沉默用户:按照设备id,对日活跃表分组,登录次数为1,且是在一周前登录。
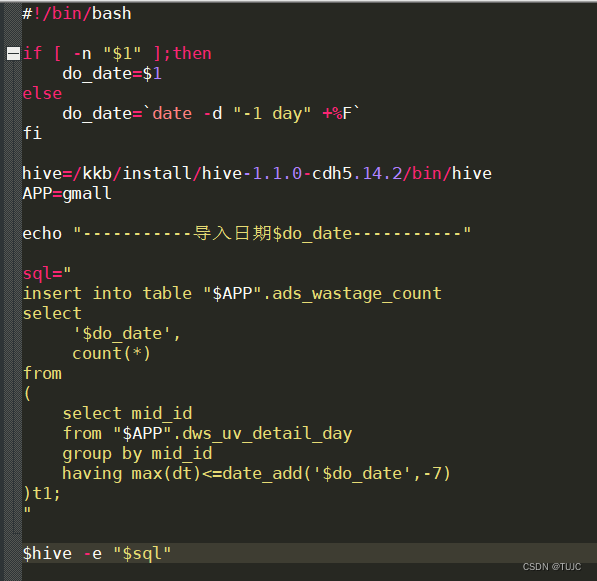
- 5)流失用户:按照设备id,对日活跃表分组,且七天内没有登录过。
- 6)最近连续3周活跃用户数:按照设备id,对周活进行分组,统计次数等于3次。
- 7)最近七天内,连续3天活跃用户数?
- 1)查询出最近7天的活跃用户,并对用户活跃,日期进行排名
- 2)计算用户活跃日期,及排名之间的差值
- 3)对同用户及差值分组,统计差值个数
- 4)将差值相同个数大于等于3的数据取出,然后去重,即为连续3天及以上活跃的用户
等差数列,
先将每个人都登录日期排名,
每个登录日期减去自己对应的排名值,
如果差值相同,说明日期是连续的。
因此,对差值进行分组,count值为3,说明这7天里有3天日期连续,符合,得到该用户。
2、hive分层
1)ods层
外部分区表,按照日期分区,LZO压缩
HDFS数据映射 ,两张表,启动日志表、用户行为表
2)dwd层
启动日志表,
- get_json_object,将ods中json每个字段解析出来
- insert into select
- 一个json,一行数据
事件日志基础表,
- 事件日志json包括,公共字段cm,value是一个json;还包括一个事件字段et,value是一个json数组包含多个事件。。
- 需要自定义hive解析函数,是因为,这个事件日志不是一个标准日志,事件日志json前面有一个服务器事件加竖线,因此不能像启动日志那样直接通过get_json_object来解析字段,
- udf,一进一出,像get_json_object一样,把公共字段解析出来
- udtf,一进多出,解析具体字段,输入一个事件日志,输出多个事件名与json,key为事件名,value为他的json,主要是在公共字段的基础上,增加了 event_name, event_json两个字段。
- 再使用lateral view侧写 + udtf,将一行多个事件数据拆成多行单独的事件数据
- 一个json,多行数据
事件明显表,
就是在基础表中(各种事件都在一张表),拿到自己的事件及其json解析后字段。
3)dws层:
- 通过dwd层的表来实现各种维度的统计:
- 用户活跃维度:统计当日、当周、当月活动的每个设备明细 。
- 方式:统计活跃设备明细:启动日志表:每个设备启动一次都会有一个启动日志表
4)ads层:
dws层 ==> 一些指标的汇总到ads层 ==> 使用脚本进行控制
5)调度时
shell文件,使用hive -e sql 执行特定sql
还有hive -f 文件
6)数据可视化:
可以通过sqoop将hive当中ads层的数据,导出到mysql做报表展示
直接连hive进行可是化展示吗不行的,hive查询比较慢
3、其他
1)数据源
日志分为两大类:
- 1、app启动日志,每启动一次app,都会打印一条启动日志
- 2、用户行为日志:基础数据,用户操作数据
启动日志和用户行为日志,都在一个日志文件中,日志名字按天区分
1)启动日志
{"action":"1","ar":"MX","ba":"Huawei","detail":"542",
"en":"start","entry":"3","extend1":"","g":"5666N0XK@gmail.com","hw":"1080*1920","l":"en","la":"19.5","ln":"-78.6","loading_time":"10","md":"Huawei-18",
"mid":"0","nw":"3G","open_ad_type":"2","os":"8.2.6","sr":"B","sv":"V2.5.4","t":"1660178510462",
"uid":"0","vc":"0","vn":"1.3.5"}
共有25个字段,
关键字段:
状态 action=1,可以算成前台活跃;
en = start,日志类型为启动日志;
2)用户行为日志
公共字段:基本所有安卓手机都包含的字段
业务字段:埋点上报的字段,有具体的业务类型
下面就是一个示例,表示业务字段的上传。
1574774962420|{"ap":"app",
"cm":{"ln":"-51.5","sv":"V2.5.7","os":"8.1.0","g":"Z0BN6732@gmail.com","mid":"995"...},
"et":[{"ett":"1574758387950","en":"display","kv":{"goodsid":"239","action":"1","extend1":"1","place":"5","category":"41"}},{"ett":"1574688967010","en":"newsdetail","kv":{"entry":"3","goodsid":"240","news_staytime":"3","loading_time":"12","action":"4","showtype":"5","category":"49","type1":"542"}}]}
-
① 公共字段:k:cm,value:json形式:包含客户端基本信息,如设备标识mid、用户标识uid、区域ar,表示那个用户。
-
② 业务字段: k:et,value:jsonArray形式,包含多个具体事件json,每个具体的事件json,具有不同的字段,对于hive中不同的原始表
- 事件k: 1)进入产品详情(loading)、2)商品点击(display)、3)评论(comment)、收藏(favorites)、4)点赞(praise)、5)商品页面详情(newsdetail)、6)点击广告(ad)
用户操作数据的一条数据包含两部分:
1、基本公共字段:cm对应的都是安卓手机公共字段
2、用户的行为事件字段:商品列表页,商品点击,商品详情,广告,消息通知
活跃,评论,收藏,点赞,错误日志
3)数据来源
用户行为数据:pc端使用的是JS埋点日志数据;移动端使用的是SDK内嵌的
业务数据(数据库的数据)
一部分是系统生成的样例数据,数据不够,又通过javabean造数据
模拟一个java程序去生成日志数据 => 使用flume进行采集 node01和node02都去采集 => 汇总到node03 => 通过node03的flume将数据保存到hdfs上面去了
2)有mid,不用uid
mid,设备id,因为我们系统通过公众号、视频号等一些手段,进行推广,可能一些用户没有进行注册,因此通过mid来标识,具体的是业务方面的同事处理,bs浏览器端是了浏览器的标识,微信小程序端是设备标识
数仓还有其他维度的开发
- 平台层的用户维度,统计平台中用户的数量
- 商品维度,
- 订单维度,
- 用户层,统计某个用户的点赞收藏评论,等用户画像。
开启hive本地模式以加快hive查询速度,yarn分配资源是很慢的
set hive.exec.mode.local.auto=true;
1、用户行为数据仓
使用flume采集node1、2日志数据 => node3的flume汇总,保存到hdfs
=> 创建hive表映射ods层,自定义hive的函数udf,udtf,解析启动日志以及事件的日志
=> 到了dwd层
=> dws层 1变11张表
=> ads层 统计各种指标结果
使用shell脚本来实现程序的自动化的运行
2、业务数据仓库如何实现:
sqoop导入数据到hdfs
=> ods层创建表映射hdfs的数据
=> dwd层进行数据的汇总(商品和分类表进行了汇总)
=> dws层 主要就是针对数据进行聚合操作 ==> ads层做数据报表
数据可视化:可以通过sqoop将hive当中ads层的数据,导出到mysql做报表展示
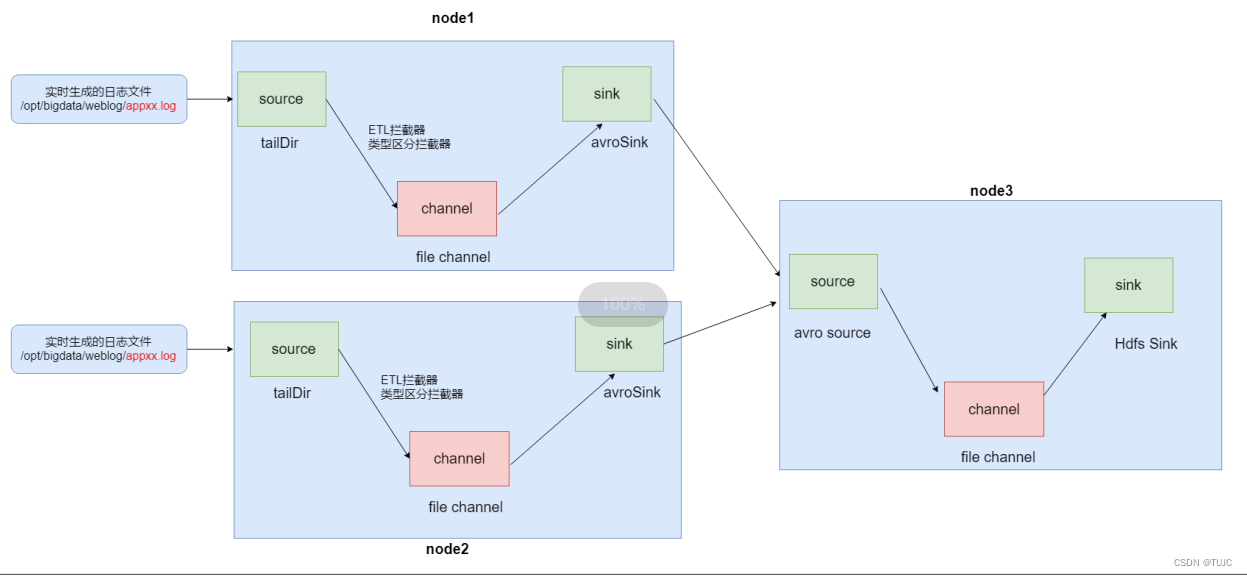
二、flume数据采集
flume作用
- 1)采集日志数据到hdfs
- node01与node02都生成了日志,日志数据会实时追加,通过flume中Taildir Source实时监测采集日志数据,使用file类型的Channel,把数据缓存在磁盘中。
- 2)日志类型区分,将启动日志与用户行为日志 分开,存在hdfs不同文件夹。
- 自定义类型区分拦截器 ,实现数据的区分,以及粗略的ETL的过滤,过滤脏数据
- 3)数据校验,校验日志格式是否为json ,
1、flume参数配置
node01与node02:收集日志
- source:tailDir source 支持事务处理
- channel: fileChannel(实际工作当中使用比较多)
- sink:avro sink
node03:汇总node01与node02数据,上传到hdfs,使用lzo的压缩方式了
- source:avro source
- channel: fileChannel
- sink: hdfsSink
1)在node01和node02主机上
/kkb/install/flume-1.6.0-cdh5.14.2/myconf目录下
创建flume-client.conf文件
#flume-client.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 配置source
a1.sources.r1.type = taildir
a1.sources.r1.positionFile = /kkb/bigdata/index/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /kkb/bigdata/weblog/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.bigdata.flume.interceptor.LogETLInterceptor Builder
a1.sources.r1.interceptors.i2.type =com.bigdata.flume.interceptor.LogTypeInterceptor$Builder#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/bigdata/flume_checkpoint
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/bigdata/flume_data#通道支持事务的最大大小
a1.channels.c1.transactionCapacity=1000000
#添加或者删除一个event的超时时间,单位为秒,默认是3
a1.channels.c1.keep-alive=60
#添加event,最多保存多少个event,默认是100
a1.channels.c1.capacity=1000000
#配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
#node3
a1.sinks.k1.hostname = 192.168.52.120
a1.sinks.k1.port = 4141
在文件配置如下内容
注意:
com.bigdata.flume.interceptor.LogETLInterceptor和com.bigdata.flume.interceptor.LogTypeInterceptor是自定义的拦截器的全类名。
需要根据用户自定义的拦截器做相应修改。
2)在node03主机上
/kkb/install/flume-1.6.0-cdh5.14.2/myconf目录下
创建flume-hdfs.conf文件
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1#配置source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port = 4141
a1.sources.r1.channels = c1#配置channel
a1.channels.c1.type = file
#检查点文件目录
a1.channels.c1.checkpointDir=/kkb/bigdata/flume_checkpoint
#缓存数据文件夹
a1.channels.c1.dataDirs=/kkb/bigdata/flume_data#配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/origin_data/gmall/log/%{topic}/%Y-%m-%da1.sinks.k1.hdfs.filePrefix = logevent-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second#不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount =1000
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
2、flume拦截器
实现Interceptor接口,重写intercept(Event event)方法,对event对象进行相关处理与返回;
拦截器打包之后,由于依赖包在flume的lib目录下面已经存在了,故只需要单独包,不需要将依赖的包上传。打包之后要放入三台服务器Flume的lib文件夹下面;
java编写flume的拦截器代码,maven打包上传到服务器,配置node01与node02的flume-client.conf时,source里添加拦截器的类型为刚刚打包的拦截器类型。
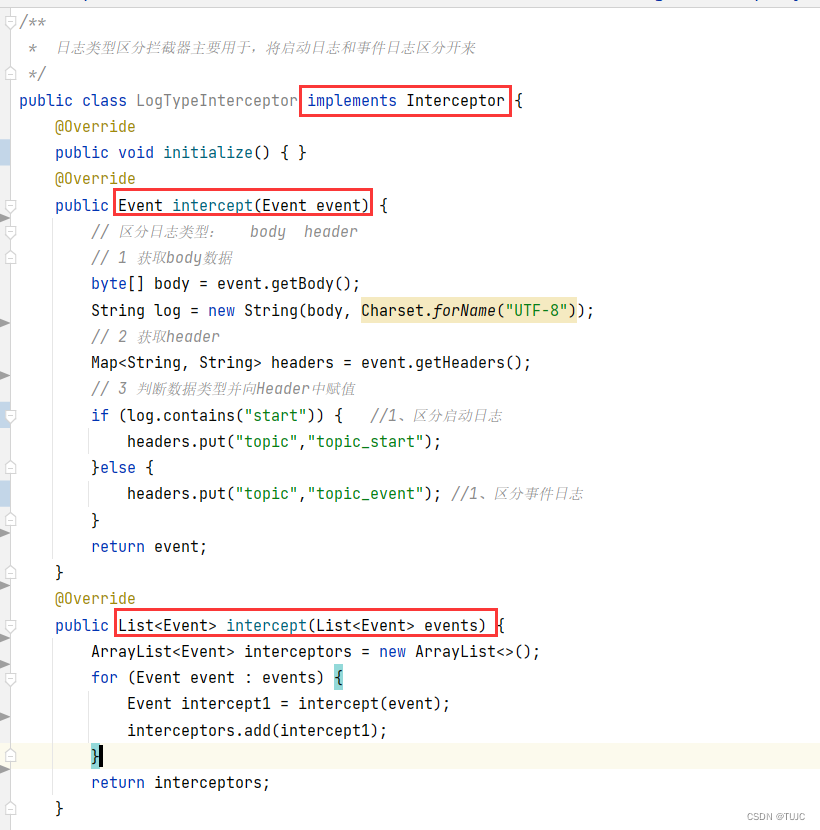
1)日志类型区分拦截器
主要用于,将启动日志和事件日志区分开来
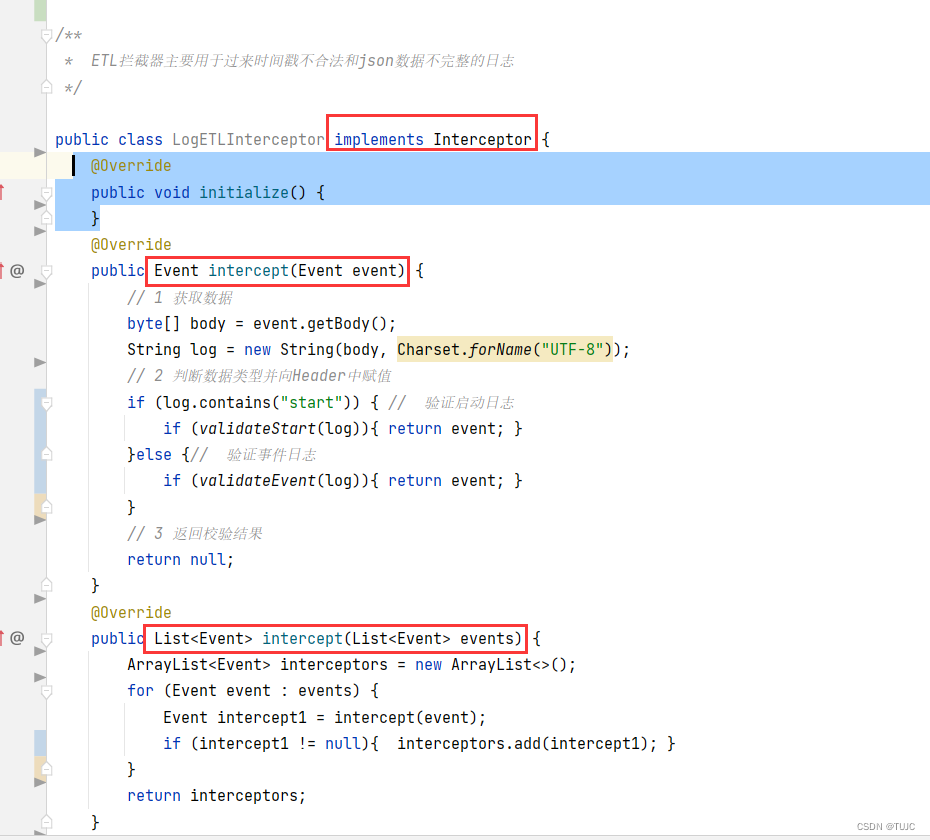
2)ETL拦截器
主要用于过来时间戳不合法,,和json数据不完整的日志
3、flume启动与停止
/bin/flume-ng agent
-n a1 agent名称
-c /kkb/myconf 置文件所在的目录
-f /kkb/myconf/flume-hdfs.conf 配置文件的路径名称
-Dflume.root.logger=info,console 定key=value键值对---启动的日志输出级别
ps -ef | grep flume | grep -v grep |awk '{print \$2}' | xargs kill
三、hive分层分析
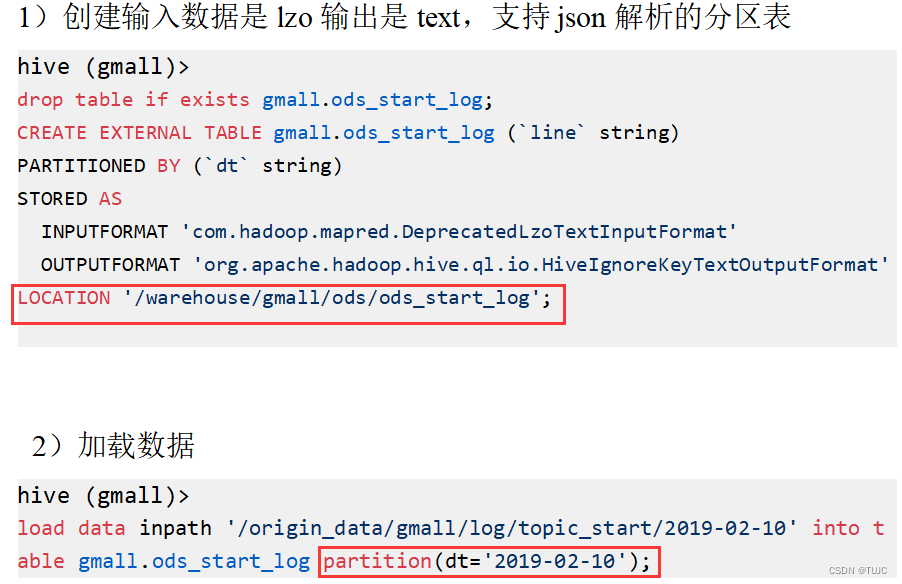
1、ODS,原始数据层
2个表,存放原始数据,保持原貌不做处理
1)ods_start_log 启动日志表
只有一个字段 line(保存着json),按照日期dt分区,表的格式:lzo
现在根据启动日志表,进行每日/周/月用户活跃、新增、留存、沉默、流失、回流,6个主题的分析。

2)ods_event_log 事件日志表(格式同启动日志表)
只有一个字段 line ,按照日期dt 分区,表的格式:lzo
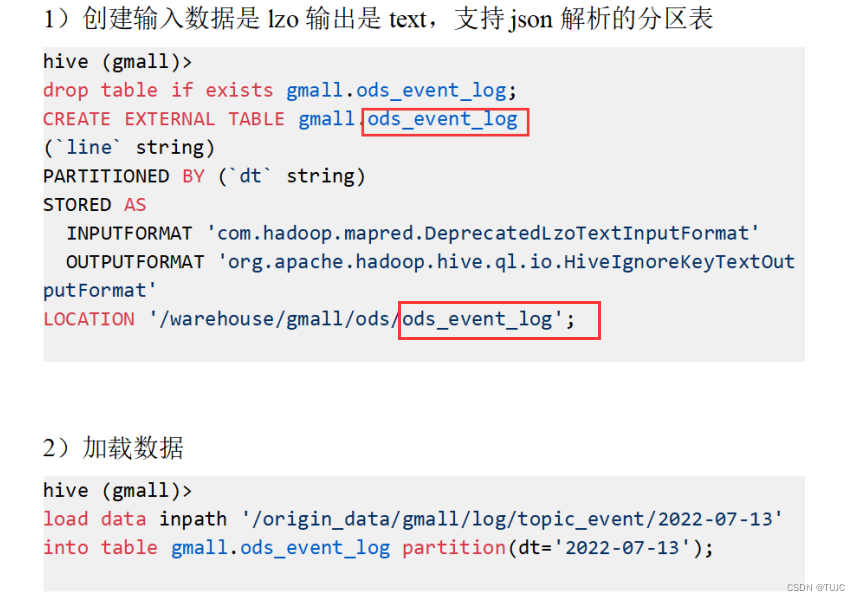

2、DWD,明细数据层:
10个表,对ods层数据清洗(去除空值,脏数据,超过极限范围的数据),
1)dwd_start_log 启动表,
- 关键字段:mid_id,user_id,dt(分区字段,按照日期分区) (其实这是启动表和事件表的公共字段);
- 从ods_start_log中的line,用get_json_object(line,’$.mid’) mid_id的方式获取字段。
2)dwd_base_event_log 事件日志基础明细表:
- 公共字段:mid_id、user_id、dt(分区字段),event_name、event_json、server_time
- 来源:
①从 ods_event_log的line 中用 UDF 获取 公共字段 和 server_time,
②用UDTF 获取 event_name , event_json。
1)dwd_start_log 启动表,
- 关键字段:mid_id,user_id,dt(分区字段,按照日期分区) (其实这是启动表和事件表的公共字段);
- 从ods_start_log中的line,用get_json_object(line,’$.mid’) mid_id的方式获取字段。

2)dwd_base_event_log 事件日志基础明细表:
- 公共字段:mid_id、user_id、dt(分区字段),event_name、event_json、server_time
- 来源:
①从 ods_event_log的line 中用 UDF 获取 公共字段 和 server_time,
②用UDTF 获取 event_name , event_json。
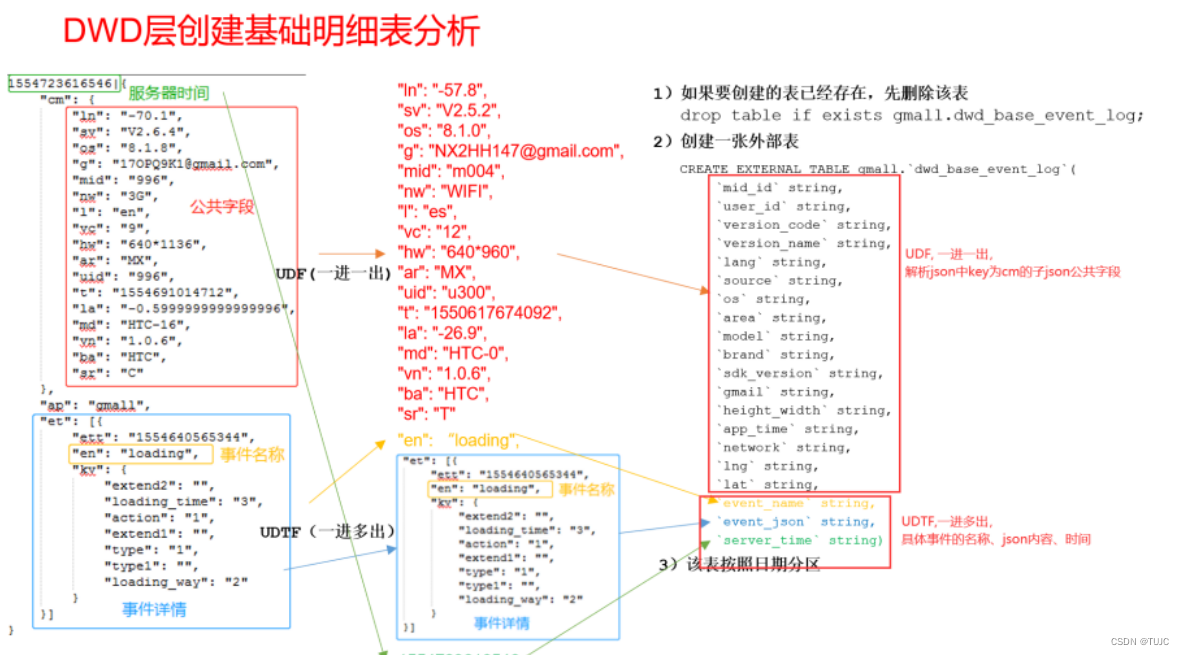
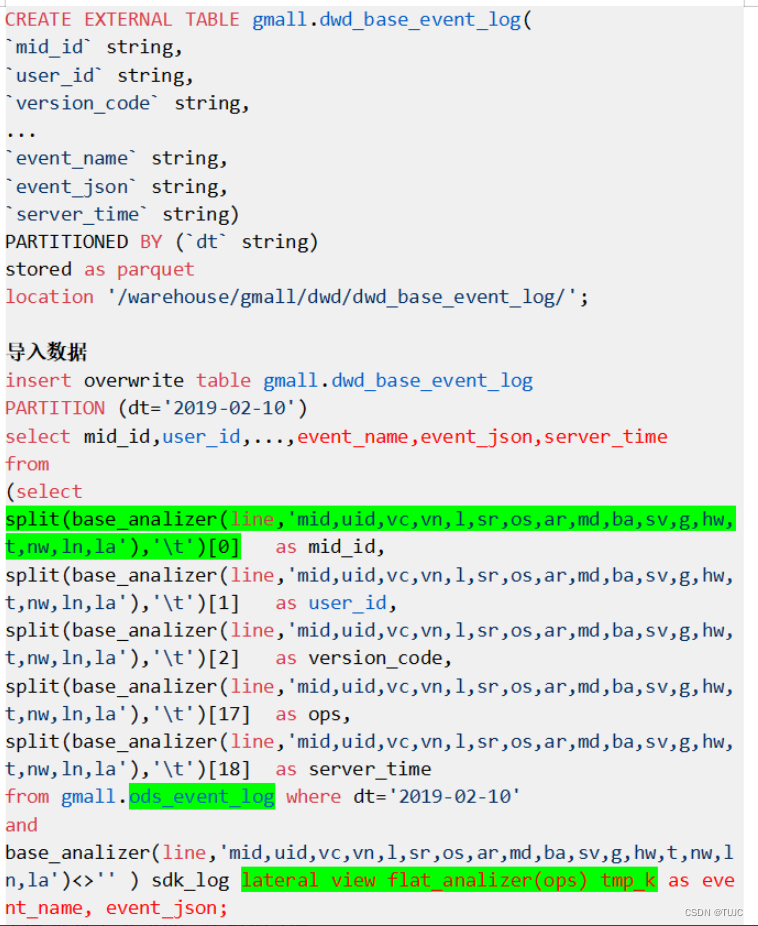
3)自定义UDF/UDTF
为什么要自定义UDF/UDTF,
因为自定义函数,可以自己埋点Log打印日志,出错或者数据异常,方便调试。
自定义UDF函数(解析公共字段,一进一出)
自定义UDTF函数(解析具体事件字段,一进多出)
-
自定义UDF:继承UDF,重写evaluate方法
-
自定义UDTF:继承自GenericUDTF,重写3个方法:initialize(自定义输出的列名和类型),process(将结果返回forward(result)),close
自定义UDF:继承UDF,重写evaluate方法
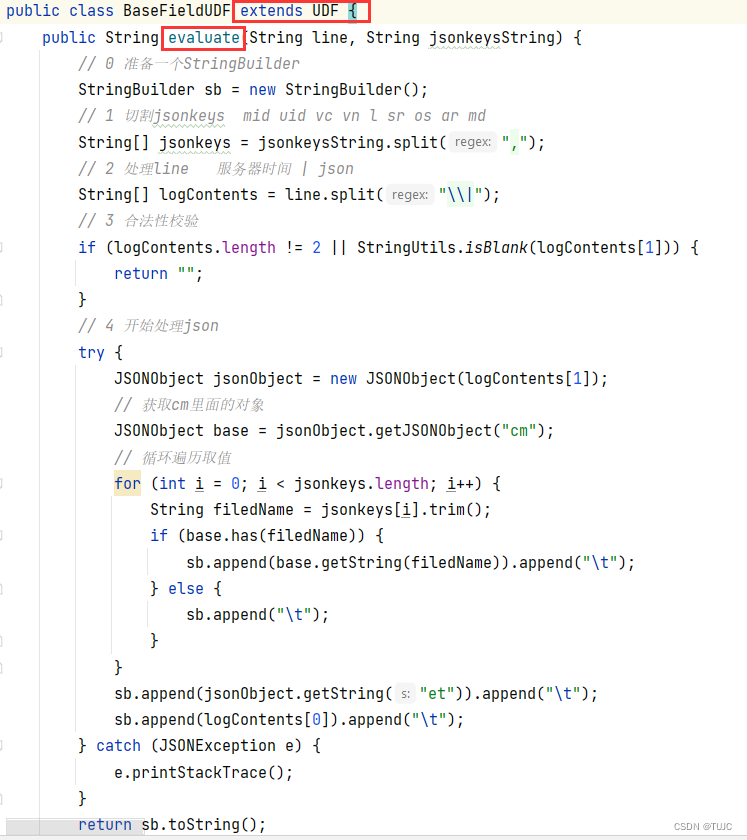
自定义UDTF:继承自GenericUDTF,
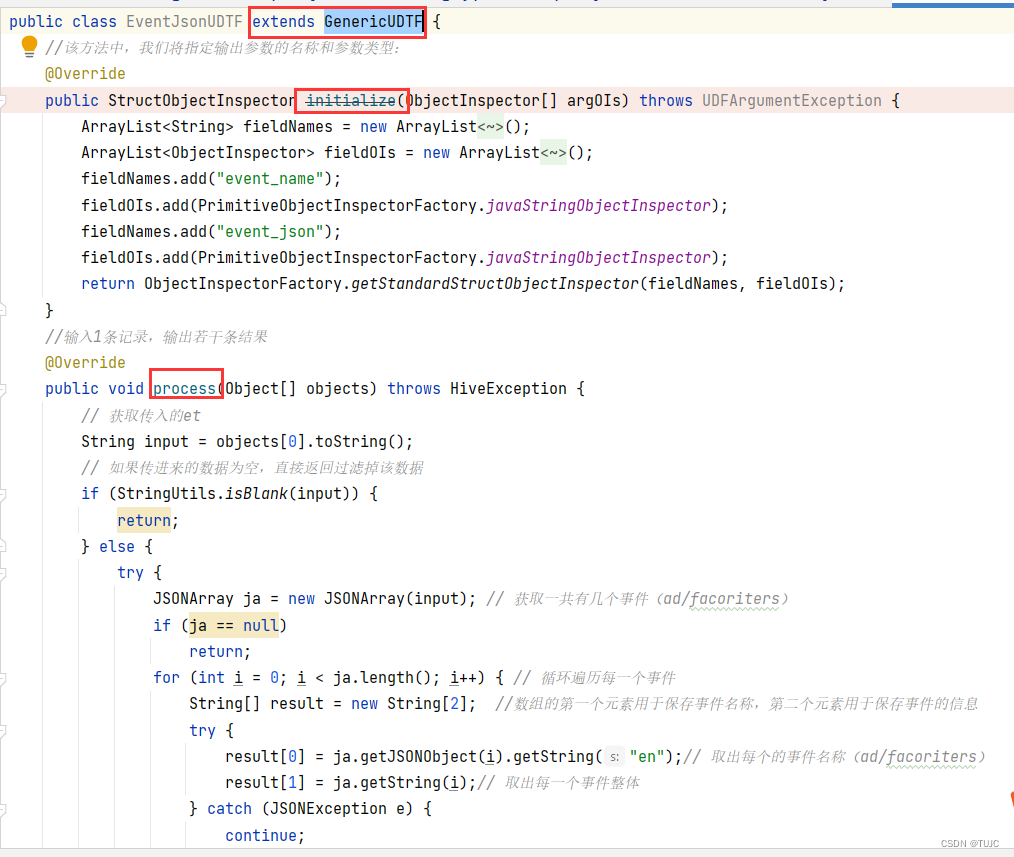
4)其他的具体事件明细表

8个具体事件表:
来源:
从刚才事件基础明显表中,直接获取公共字段和server_time,
从刚才事件基础明显表event_json中,获取特有字段,where event_name = “display”
从一张事件基础明细表,一共可以获得8张具体事件明细表
dwd_display_log 商品点击表
dwd_newsdetail_log 商品详情页表
dwd_loading_log 商品列表页表
dwd_ad_log 广告表
dwd_comment_log 评论表
dwd_favorites_log 收藏表
dwd_praise_log 点赞表
dwd_error_log 错误日志表
用于后续,用户画像分析,精准推销
3、DWS,服务数据层,轻度聚合;
1)设备活跃



2)新增设备

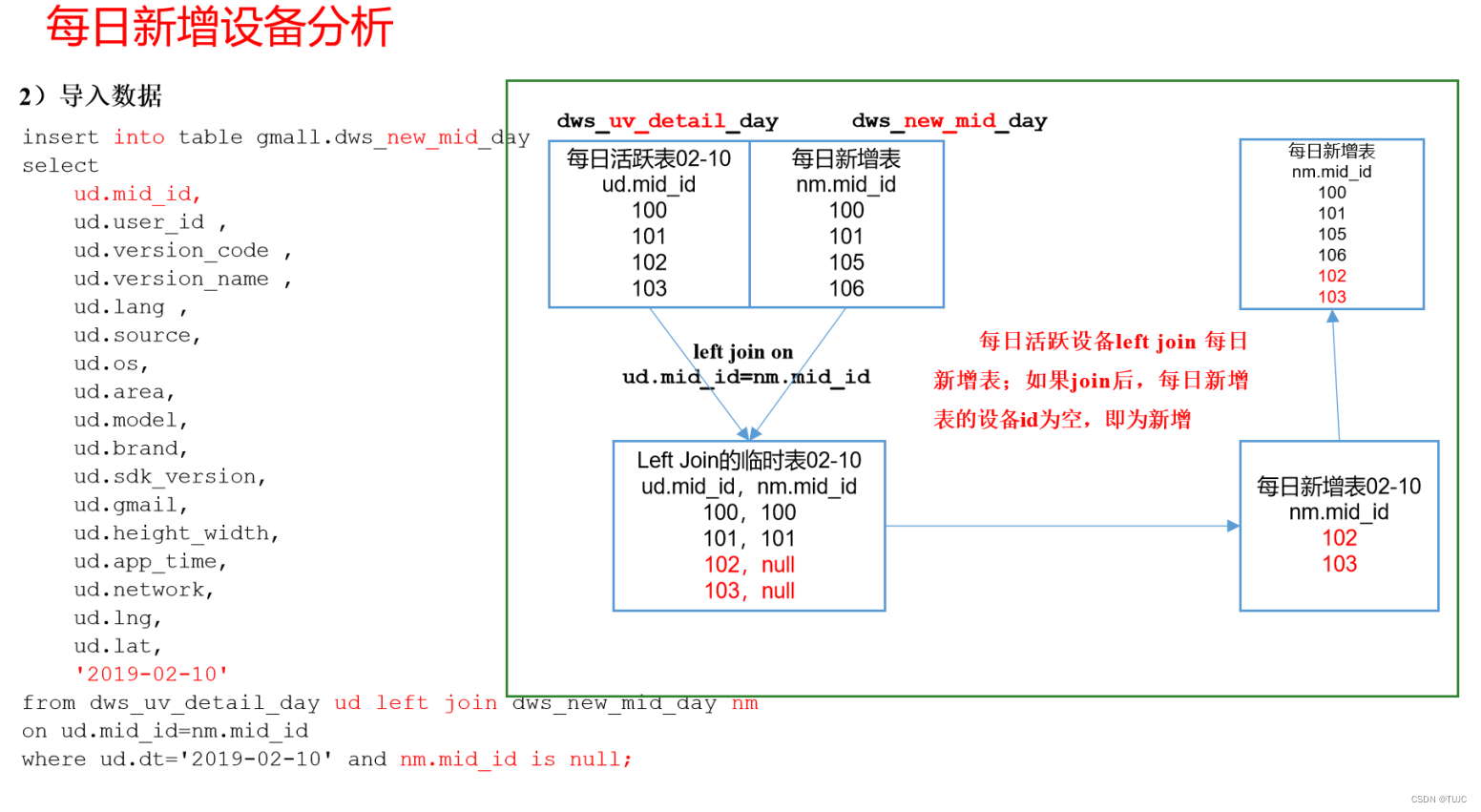
3)设备留存



2)新增设备
3)设备留存
4)沉默设备
使用日活明细表dws_uv_detail_day作为DWS层数据
5)本周回流用户
使用日活明细表dws_uv_detail_day作为DWS层数据
6)本周流失用户
使用日活明细表dws_uv_detail_day作为DWS层数据
7)最近连续三周活跃用户
使用周活明细表dws_uv_detail_wk作为DWS层数据
8)最近7天内连续3天活跃用户
使用日活明细表dws_uv_detail_day作为DWS层数据
4、ADS,应用数据层,具体需求
1)设备活跃

2)新增设备

3)设备留存
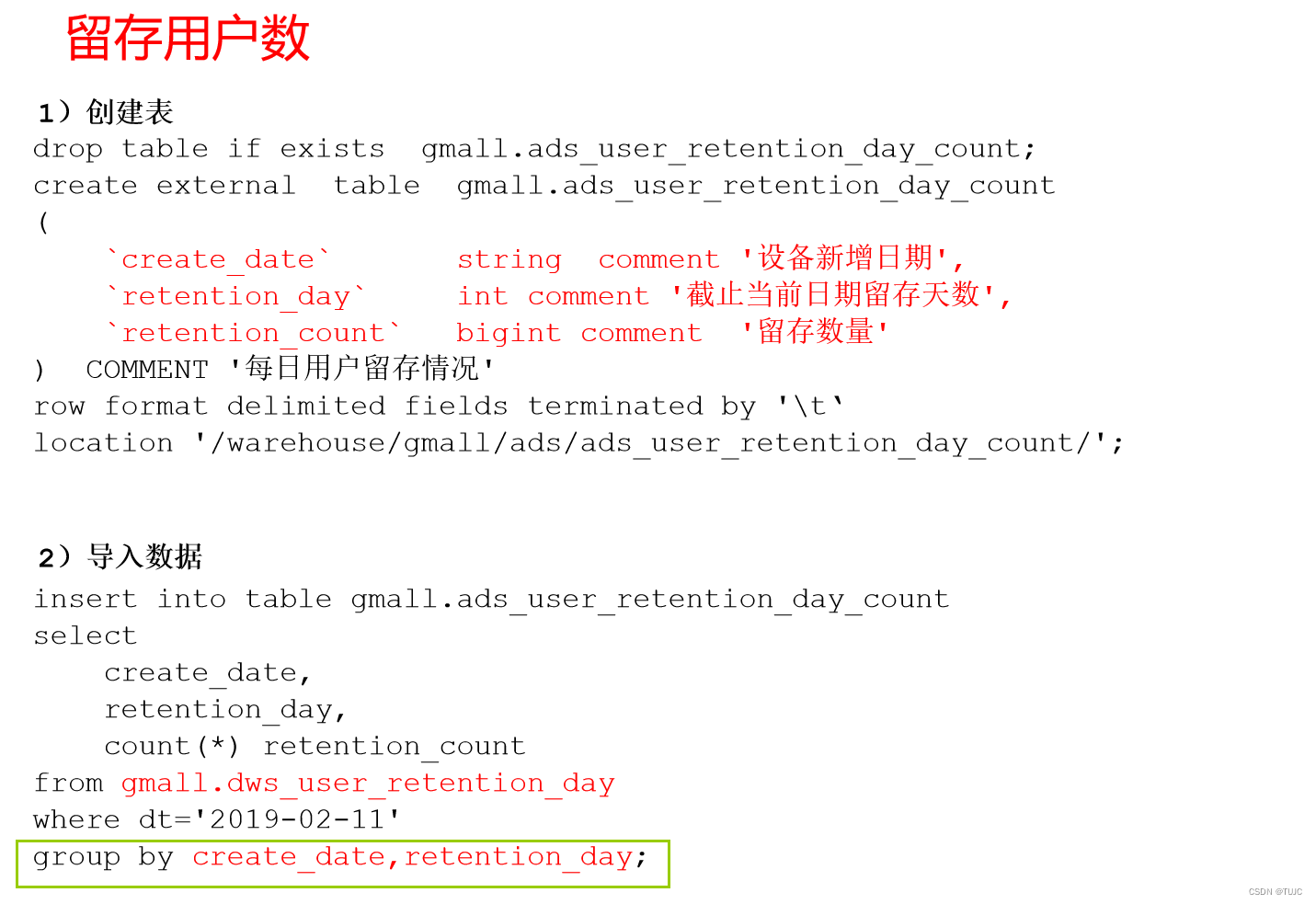

4)沉默设备

5)本周回流用户

6)本周流失用户

7)最近连续三周活跃用户

8)最近7天内连续3天活跃用户

四、shell脚本调度
如:流失客户用户,
1)在node03 的/home/hadoop/bin目录下创建脚本
[hadoop@node03 bin]$ vim ads_wastage_log.sh
2)增加脚本执行权限
[hadoop@node03 bin]$ chmod 777 ads_continuity_wk_log.sh
3)脚本使用
[hadoop@node03 bin]$ ./ads_continuity_wk_log.sh 2019-02-20
4)查询结果
hive (gmall)> select * from gmall.ads_continuity_wk_count;
5)脚本执行时间
企业开发中一般在每周一凌晨30分~1点
五、业务分析数仓
1、数据源:
业务库mysql中8张表:用户表、订单表、商品表、商品一二三级表、订单流水表、支付流水表。通过sqoop定时导入
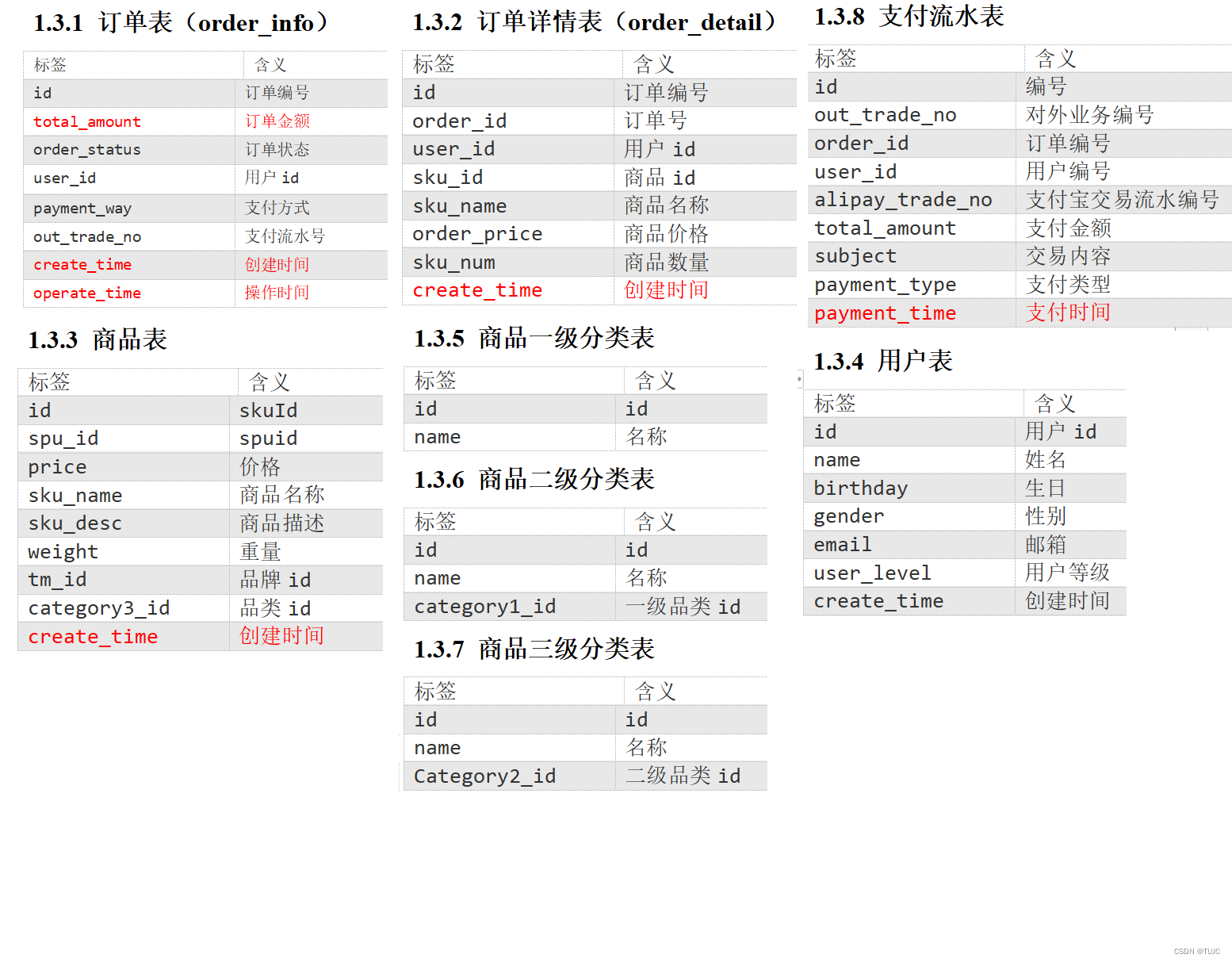
实体表:用户表、商品表,指一个现实存在的业务对象,全量同步;
维度表:商品一二三级表,业务对象的解释表,全量同步;
事务型事实表:订单流水表、支付流水表,指随着业务发生不断产生,一旦发生不会再变化的数据。 每日增量;
周期性事实表:订单表,指随着业务发生不断产生,会随着业务周期性的推进而变化的数据。 拉链表模型。
拉链表是一种数据模型, 所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。拉链表可以避免按每一天存储所有记录造成的海量存储问题,同时也是处理缓慢变化数据(SCD2)的一种常见方式。
拉链表通常会增加三个技术字段“开始日期starttime、结束日期endtime、状态标识mark”。通过主键(PK)与历史数据进行对比,判断当前数据与历史数据是否发生变化,如果发生变化或者新增则进行相应的开链、闭链操作。
2、sqoop数据采集
1)在/home/hadoop/bin目录下创建脚本sqoop_import.sh
[hadoop@node03 bin]$ vim sqoop_import.sh
在脚本中填写如下内容
#!/bin/bash
db_date=$2
echo $db_date
db_name=gmall
import_data() {
/kkb/install/sqoop-1.4.6-cdh5.14.2/bin/sqoop import \
--connect jdbc:mysql://node03:3306/$db_name?useSSL=false \
--username root \
--password 123456 \
--target-dir /origin_data/$db_name/db/$1/$db_date \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "$2"' and $CONDITIONS;'
}
import_sku_info(){
import_data "sku_info" "select
id, spu_id, price, sku_name, sku_desc, weight, tm_id,
category3_id, create_time
from sku_info where 1=1"
}
case $1 in
"sku_info")
import_sku_info
;;
"all")
import_sku_info
;;
esac
2)增加脚本执行权限
[hadoop@node03 bin]$ chmod 777 sqoop_import.sh
3)执行脚本导入数据
[hadoop@node03 bin]$ ./sqoop_import.sh all 2019-02-10
4)在SQLyog中生成2019年2月11日数据
CALL init_data('2019-02-11',1000,200,300,TRUE);
5)执行脚本导入数据
[hadoop@node03 bin]$ ./sqoop_import.sh all 2019-02-11
3、hive分层
1)ods层
(八张表,表名,字段跟mysql完全相同),从origin_data把数据导入到ods层,表名在原表名前加ods_。
hive (gmall)>
drop table if exists gmall.ods_order_info;
create external table gmall.ods_order_info (
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id',
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间'
) COMMENT '订单表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ods/ods_order_info/'
;
2) dwd层
对ODS层数据进行判空过滤。对商品分类表进行维度退化(降维)。创建商品表,增加分类,宽表。其他数据跟ods层一模一样;
1)维度退化要付出什么代价?
如果被退化的维度,还有其他业务表使用,退化后处理起来就麻烦些。
2)想想在实际业务中还有那些维度表可以退化
城市的三级分类(省、市、县)等

3)DWS层之用户行为宽表
为什么要建宽表
把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。


4)ADS层
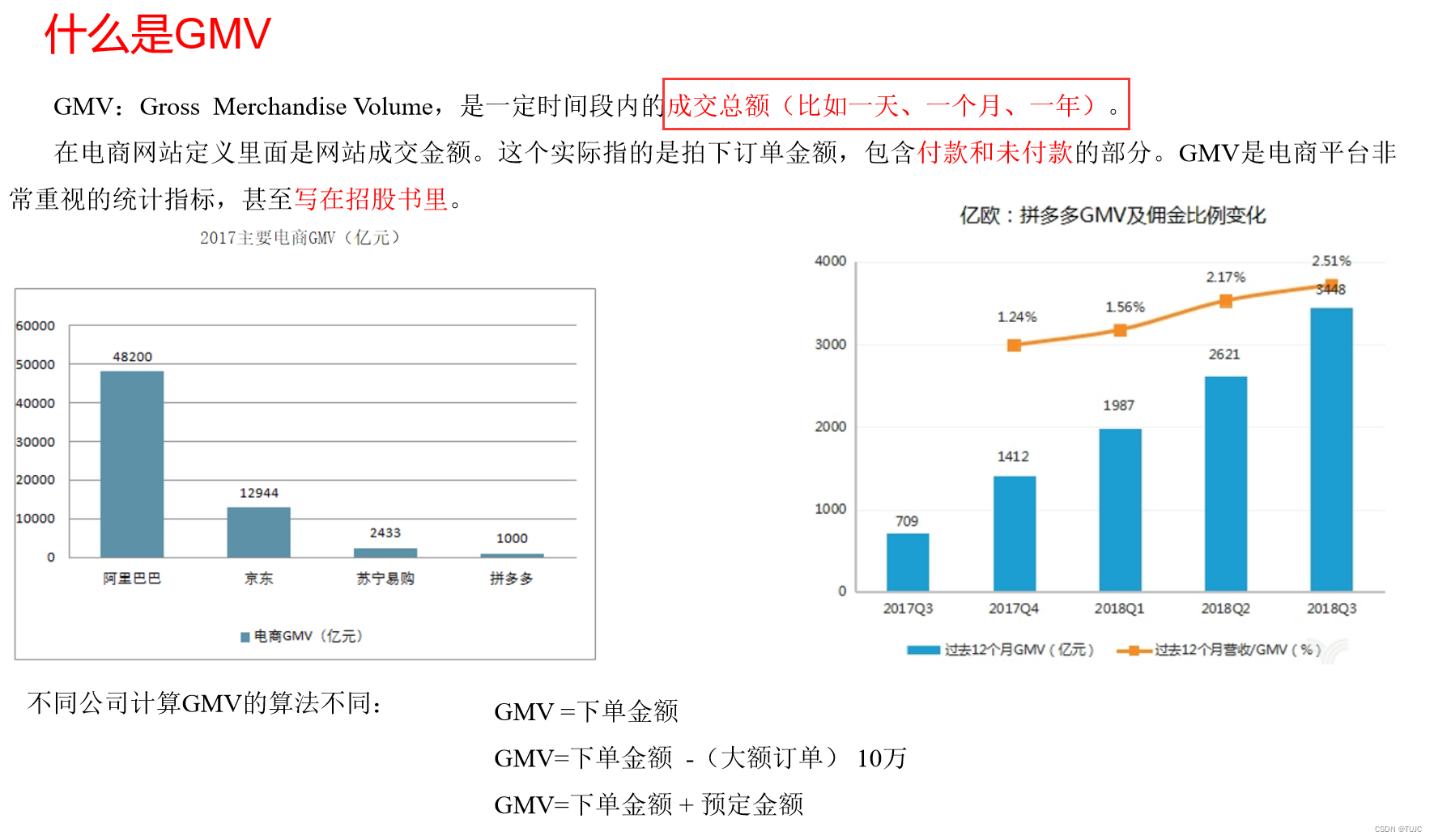
需求一:GMV成交总额
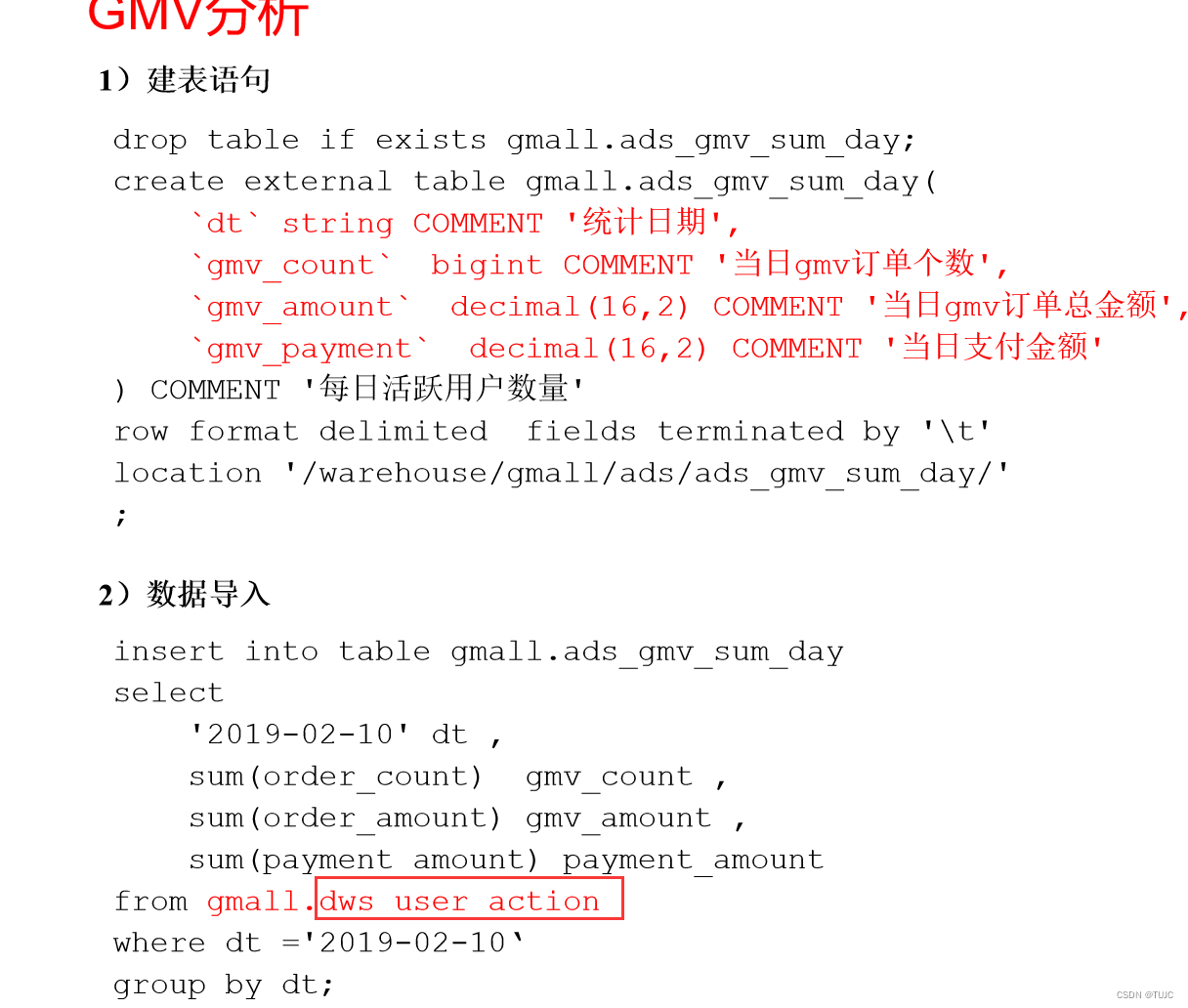
需求二:用户转化率



需求三:品牌复购率

六、业务术语
1.用户
用户以设备为判断标准,在移动统计中,每个独立设备认为是一个独立用户。Android系统根据IMEI号,IOS系统根据OpenUDID来标识一个独立用户,每部手机一个用户。
2.新增用户
首次联网使用应用的用户。如果一个用户首次打开某APP,那这个用户定义为新增用户;卸载再安装的设备,不会被算作一次新增。新增用户包括日新增用户、周新增用户、月新增用户。
3.活跃用户
打开应用的用户即为活跃用户,不考虑用户的使用情况。每天一台设备打开多次会被计为一个活跃用户。
4.周(月)活跃用户
某个自然周(月)内启动过应用的用户,该周(月)内的多次启动只记一个活跃用户。
5.月活跃率
月活跃用户与截止到该月累计的用户总和之间的比例。
6.沉默用户
用户仅在安装当天(次日)启动一次,后续时间无再启动行为。该指标可以反映新增用户质量和用户与APP的匹配程度。
7.版本分布
不同版本的周内各天新增用户数,活跃用户数和启动次数。利于判断APP各个版本之间的优劣和用户行为习惯。
8.本周回流用户
上周未启动过应用,本周启动了应用的用户。
9.连续n周活跃用户
连续n周,每周至少启动一次。
10.忠诚用户
连续活跃5周以上的用户
11.连续活跃用户
连续2周及以上活跃的用户
12.近期流失用户
连续n(2<= n <= 4)周没有启动应用的用户。(第n+1周没有启动过)
13.留存用户
某段时间内的新增用户,经过一段时间后,仍然使用应用的被认作是留存用户;这部分用户占当时新增用户的比例即是留存率。
例如,5月份新增用户200,这200人在6月份启动过应用的有100人,7月份启动过应用的有80人,8月份启动过应用的有50人;则5月份新增用户一个月后的留存率是50%,二个月后的留存率是40%,三个月后的留存率是25%。
14.用户新鲜度
每天启动应用的新老用户比例,即新增用户数占活跃用户数的比例。
15.单次使用时长
每次启动使用的时间长度。
16.日使用时长
累计一天内的使用时间长度。
17.启动次数计算标准
IOS平台应用退到后台就算一次独立的启动;Android平台我们规定,两次启动之间的间隔小于30秒,被计算一次启动。用户在使用过程中,若因收发短信或接电话等退出应用30秒又再次返回应用中,那这两次行为应该是延续而非独立的,所以可以被算作一次使用行为,即一次启动。业内大多使用30秒这个标准,但用户还是可以自定义此时间间隔。
















 1513
1513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









