







流程分析
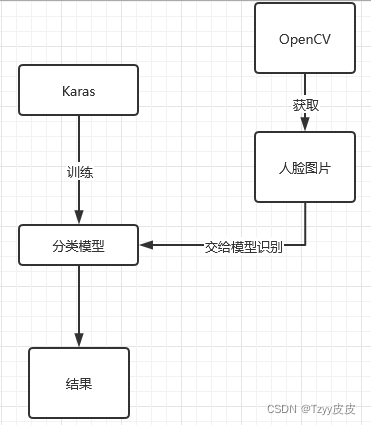
OpenCV为Keras提供数据
以摄像头截图人脸为Keras提供训练集测试集数据
带口罩的图片存放在 imgs/yes/
没带口罩的图片存放在 imgs/no/
每种准备400张
OpenCV摄像头截图
def CatchPICFromVideo(catch_num): # catch_num = 400
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') # haarcascade_frontalface_alt2
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
num = 0
while True:
ret, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
img_name = "imgs/yes/" + str(num) + ".jpg"
image = frame[y:y + h, x:x + w]
print(img_name)
# 将图片处理成固定大小
img_resize2 = cv2.resize(image, dsize=(200, 200))
cv2.imwrite(img_name, image)
num += 1
if num > catch_num:
break
# 画出矩形框圈出人脸
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示捕捉了多少张人脸
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, f'num:{str(num)}', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
if num > catch_num:
break
# 显示图像
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
Keras 卷积神经
使用Keras快速搭建神经网络
加载数据到内存
def load_data():
images = []
labels = []
for i in range(500):
img = cv2.imread("imgs/yes/" + str(i) + ".jpg")
images.append(img)
labels.append(1)
for i in range(500):
img = cv2.imread("imgs/no/" + str(i) + ".jpg")
images.append(img)
labels.append(0)
images = np.array(images)
labels = np.array(labels)
return images, labels
卷积神经网络构建以及训练保存
def cnn_train(images, labels):
# sklearn 划分数据集
x_train, x_test, y_train, y_test = train_test_split(images, labels, test_size=0.3, random_state=3)
# (400, 200, 200, 3) -> (400, 3, 200, 200) -- (图片数量,宽,高,通道数) -> (图片数量,通道数,宽,高)
x_train = x_train.reshape(x_train.shape[0], 3, 200, 200)
x_test = x_test.reshape(x_test.shape[0], 3, 200, 200)
# 目标值 转化为 One-Hot编码 : 2 -> [0, 0, 1]; 0 -> [1, 0, 0]
y_train = np_utils.to_categorical(y_train, num_classes=2)
y_test = np_utils.to_categorical(y_test, num_classes=2)
# 标准化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0
# Keras 模型构建
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=[3, 3], padding='same', input_shape=(3, 200, 200)))
model.add(Activation('relu'))
model.add(Convolution2D(filters=32, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(Convolution2D(filters=64, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.25))
model.add(Dense(2))
model.add(Activation('softmax'))
model.summary()
# 优化器
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练
model.fit(x_train, y_train, epochs=4, batch_size=100)
# 查看效果
loss, acc = model.evaluate(x_test, y_test)
print("最终loss\n", loss)
print("最终acc\n", acc)
# 模型保存
model.save("wearmask.h5")
结合模型进行识别
def mask_check():
# 加载模型
model = load_model("wearmask.h5")
# 人脸分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') # haarcascade_frontalface_alt2
# 调度摄像头
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
while True:
#读取一帧
ret, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
image = frame[y:y + h, x:x + w]
# 交给模型识别前的准备工作
img_resize = cv2.resize(image, dsize=(200, 200))
test_x = []
test_x.append(img_resize)
images_test = np.array(test_x)
images_test = images_test.reshape(images_test.shape[0], 3, 200, 200)
# 获取到识别结果
value = np.argmax(model.predict(images_test), axis=1)
# 画出矩形框圈出人脸
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示捕捉了多少张人脸
font = cv2.FONT_HERSHEY_SIMPLEX
print(value[0])
if value[0] == 0:
print('请带好口罩')
cv2.putText(frame, 'Please wear a mask!', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
else:
print('已带口罩')
cv2.putText(frame, 'Wearing a mask!', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 显示图像
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
最终完整代码
import numpy as np
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
import cv2
from keras.models import Sequential, load_model
from keras.layers import Convolution2D, Dense, Activation, Flatten, Dropout, MaxPooling2D
def CatchPICFromVideo(catch_num):
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') # haarcascade_frontalface_alt2
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
num = 0
while True:
ret, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
img_name = "imgs/other/" + str(num) + ".jpg"
image = frame[y:y + h, x:x + w]
print(img_name)
# 将图片处理成固定大小
img_resize2 = cv2.resize(image, dsize=(200, 200))
cv2.imwrite(img_name, img_resize2)
num += 1
if num > catch_num:
break
# 画出矩形框圈出人脸
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示捕捉了多少张人脸
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, f'num:{str(num)}', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
if num > catch_num:
break
# 显示图像
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
def load_data():
images = []
labels = []
for i in range(500):
img = cv2.imread("imgs/other/" + str(i) + ".jpg")
images.append(img)
labels.append(1)
for i in range(500):
img = cv2.imread("imgs/me/" + str(i) + ".jpg")
images.append(img)
labels.append(0)
images = np.array(images)
labels = np.array(labels)
return images, labels
def cnn_train(images, labels):
# sklearn 划分数据集
x_train, x_test, y_train, y_test = train_test_split(images, labels, test_size=0.3, random_state=3)
# (400, 200, 200, 3) -> (400, 3, 200, 200) -- (图片数量,宽,高,通道数) -> (图片数量,通道数,宽,高)
x_train = x_train.reshape(x_train.shape[0], 3, 200, 200)
x_test = x_test.reshape(x_test.shape[0], 3, 200, 200)
# 目标值 转化为 One-Hot编码 : 2 -> [0, 0, 1]; 0 -> [1, 0, 0]
y_train = np_utils.to_categorical(y_train, num_classes=2)
y_test = np_utils.to_categorical(y_test, num_classes=2)
# 标准化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0
# Keras 模型构建
model = Sequential()
model.add(Convolution2D(filters=32, kernel_size=[3, 3], padding='same', input_shape=(3, 200, 200)))
model.add(Activation('relu'))
model.add(Convolution2D(filters=32, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
model.add(Dropout(0.25))
model.add(Convolution2D(filters=64, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(Convolution2D(filters=64, kernel_size=[3, 3], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.25))
model.add(Dense(2))
model.add(Activation('softmax'))
model.summary()
# 优化器
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练
model.fit(x_train, y_train, epochs=4, batch_size=100)
# 查看效果
loss, acc = model.evaluate(x_test, y_test)
print("最终loss\n", loss)
print("最终acc\n", acc)
# 模型保存
model.save("wearmask.h5")
def mask_check():
# 加载模型
model = load_model("wearmask.h5")
# 人脸分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') # haarcascade_frontalface_alt2
# 调度摄像头
camera = cv2.VideoCapture(0, cv2.CAP_DSHOW)
while True:
#读取一帧
ret, frame = camera.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
image = frame[y:y + h, x:x + w]
# 交给模型识别前的准备工作
img_resize = cv2.resize(image, dsize=(200, 200))
test_x = []
test_x.append(img_resize)
images_test = np.array(test_x)
images_test = images_test.reshape(images_test.shape[0], 3, 200, 200)
# 获取到识别结果
value = np.argmax(model.predict(images_test), axis=1)
# 画出矩形框圈出人脸
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示捕捉了多少张人脸
font = cv2.FONT_HERSHEY_SIMPLEX
print(value[0])
if value[0] == 0:
print('请带好口罩')
cv2.putText(frame, 'Please wear a mask!', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
else:
print('已带口罩')
cv2.putText(frame, 'Wearing a mask!', (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 显示图像
cv2.imshow('camera', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# images, labels = load_data()
# cnn_train(images, labels)
mask_check()
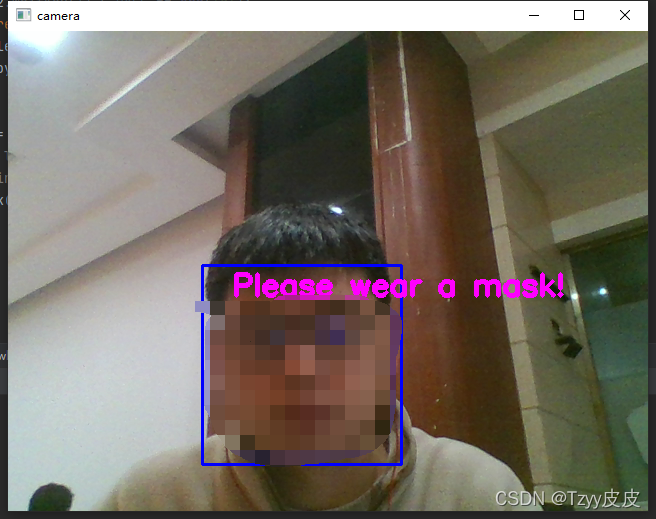
效果演示
为佩戴口罩
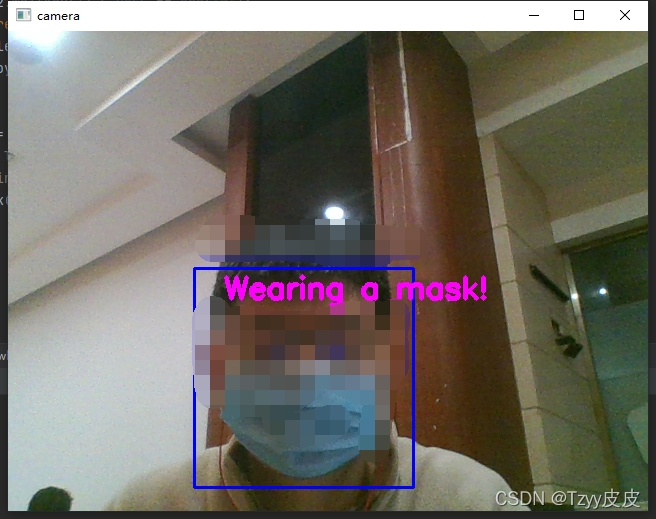
 > 已佩戴口罩
> 已佩戴口罩















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









