






并查集的查找思想与代码实现
并查集是一种特殊的集合类型算法。它的本质是许多独立的树形结构。主要用于进行合并与查询的操作,特点是可以快速合并两个集合,以及快速查询某元素的根节点。这些特点有很多应用,例如可以极快地知道两个元素是否来自同一个集合,这是并查集最重要和典型的应用之一。
关于并查集的定义实在没什么好单独描述的。并查集的核心在于它优异的算法实现。我们在看代码实现之前先通过一个情境来理解并查集的思想。
废话有点多,不感兴趣直接跳
假设在很久很久以前,有这么一种家庭。家庭里的人只知道自己的爸爸是谁。一个人只有一个爸爸,一个爸爸可能有好多儿子。我们可以把这个家庭用集合描述出来,以小写字母 a a a~ z z z 来代表家庭中的成员。表示每个人的节点都用一条边连接向他的爸爸。
现在这里有很多这样的家庭。我们绘制出关系图象后如下:

可以看到每个家庭可以很自然地排成一个树形,这些家庭的图象形成了由树形结构组成的森林,我们从任意节点开始顺着边往上走,就能找到树结构的根,也就是这个家庭的祖先。
一切看起来都非常和谐。
但是现在人们遇到了一个问题:两个好奇的人 o o o和 k k k想知道他们是否来自同一个家庭。
这里的人们从前并没有想到过这个问题,但 他们是有脑子的 这个问题难不倒他们。人们首先想到,同一个家庭意味着祖先是相同的。而两人只需要向上面说的遍历树的方法那样一层层询问,最后就能找到自己的祖先。然后两人将祖先一对比,就知道自己是不是和对方来自同一家庭了。
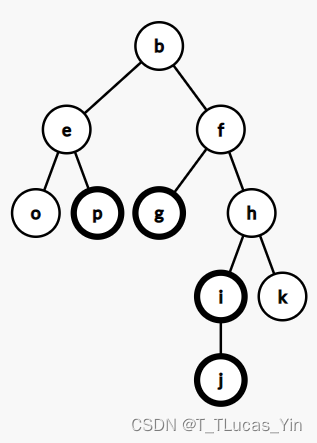
这个方法简单而好用,看起来没有什么问题。
但是一万年过去了,现在每个家庭都有数千万人。依旧按字母顺序顺次命名的两个小辈 j t p a l jtpal jtpal和 d p n k o dpnko dpnko想要知道他们是否来自同一家庭,于是他们——
像一万年前的先辈一样向自己的长辈询问。
紧接着他们就发现,一万年前的 o o o和 k k k总共询问了5次,而现在他们最少需要询问24次!于是问题就暴露出来了,原来这个方法在人数过多的时候效率会大大的降低,使问题无法得到高效的解答。
于是他们又重新审视了这个问题,并尝试获得新的解答方法,而我们
也终于步入了今天的正题
话说一群会使用计算机的高级人类研究起这个问题,他们用程序模拟了他们原先的思考方式。我们搞到了一段核心程序:
int f[100005];//这里存了每个人记忆中的father
void Find_root(int k){
if(f[k]==k) return k;//这人觉得他爸爸就是他自己,所以他是最老的祖先
else return Find_root(f[k]);//否则,就问问这人的爸爸再来回答
}
人们通过用树结构表示家庭的方法,结合这段程序,他们发现这样查找祖先,家庭树有几层,就要询问几次。
翻译:时间复杂度在 O ( l o g 2 n ) O(log2 \ n) O(log2 n)至 O ( n ) O(n) O(n)。
由于每次询问都需要花费一些时间,来回耽误的时间很多,效率就慢下来了。这就是古老的方法最大的缺点。
现在我们直接看人们研发的新方法。
void Find_root(int k){
if(f[k]==k) return k;
else return f[k]=Find_root(f[k]);
}
提示:变在这了
else return f[k]=Find_root(f[k]);
科学家们解释道,这个方法是:现在有两个人想要知道他们是否来自同一家庭,于是他们各自问他的爸爸,再问他的爷爷,再问他的曾爷爷(假设都能问到)……最终知道了自己的祖先,但是他们没有直接去比较,而是把祖先的名字告诉了他的曾爷爷,再告诉他的爷爷……最后自己带着答案去比较。等下次这个家庭中的其他人有同样的问题,问任何人就都能直接知道自己的祖先是谁了,大大节约了传递问题的时间。
现在让我们跳出这个故事。其实重构过之后的Find-root函数就是并查集查询算法部分的核心代码。查询算法的优化就在于查询后直接将存储信息指向祖先,从而节约掉了不必要的递归步骤。这种操作被称为路径压缩。这样一来,人数越来越多时,最新一层的人也始终相当于处在第二层,只需要一步查询就可以知道祖先是谁。
这个优化对于时间复杂度无疑是巨大的。更新后的查询函数时间复杂度为 O ( α ( n ) ) O(\alpha(n)) O(α(n))1。
并查集的合并思想与其代码实现
在我们所说的故事的世界里,时间又过去了10000年。人们逐渐淡忘了自己100辈之前的祖先,只记得50辈之前的祖先了。所以很多原本属于同一家庭的分支现在变成了许多家庭。
某个平静的一天,来自两个家庭的
f
j
e
o
w
p
a
fjeowpa
fjeowpa与
z
n
v
t
b
p
e
znvtbpe
znvtbpe突然脑子一炸,意识到他们在数万年前也许来自同一家庭。于是两人一拍即合,当即决定合并他们现在的家庭,恢复曾经的风光。
俩疯子
但是并不能直接在两人之间建立联系,因为这会导致关系混乱,出现一个人两个爹的状况,就不好了。
好在两人都是研究计算机的高手,他们共同努力,开发出了新算法:
int f[100005];
void Find_root(int k){
if(f[k]==k) return k;
else return f[k]=Find_root(f[k]);
}
void merge(int x,int y){//合并x和y所在的家庭
int a=Find_root(x),b=Find_root(y);//分别找到两人的祖先
if(a!=b) //注意判断,如果两人在同一家庭,合并就没有意义了
f[a]=b;
//x的祖先的爸爸改为y的祖先,实际上相当于x所在家庭的祖先改为y的祖先
}
家庭合并算法通过在两家庭祖先之间建立关系,从而达到合并家庭的目的。
让我们再次跳出故事,merge()函数其实就是并查集的合并思想,即将一棵并查集树的根节点归于另一棵并查集树上,使其所在树成为子树,以此合并并查集。由于并查集的查找算法是
O
(
1
)
O(1)
O(1)的,而合并中只用到了查找,因此合并算法也是
O
(
1
)
O(1)
O(1)的时间复杂度。可见并查集的速度十分惊人。
并查集的高级用法
在故事的最后,让我们来看一下并查集最后三种拓展用法——点带权并查集,边带权并查集与种类并查集。
点带权并查集
我们都知道树结构上点是可以带权的,因此就有了点带权并查集。
并查集的点权值可以存储点到叶子节点(底端)的距离。实现方法也很简单,只需要单独开一个数组,每位置对应一个点。初始时所有位置都为一,每经过一次合并操作就将操作中一个点的权值加到另一个点的权值上。
int f[100005],v[100005];
void merge(int x,int y){//合并x和y所在的集合
int a=Find_root(x),b=Find_root(y);
if(a!=b) f[a]=b,v[b]+=v[a];//合并操作时更新点权,注意b和a不要弄反
}
边带权并查集
我们都知道树结构上的边是可以带权的,因此就有了边带权并查集
并查集的边权值可以存储点到根节点(顶端)的距离。实现方法比点带权稍难一些,因为合并操作时被动集合所有节点到根节点的距离都会改变,所以需要在递归中进行更新。依旧建立一个新数组,初始时所有位置都为0,每经过一次合并操作,被动集合根节点的边权就变为另一集合的点权。进行查询操作时,每个点的边权都要加上它父亲的边权。
int f[100005],v[100005],d[100005];//v存点权,d存边权
void Find_root(int k){
if(f[k]==k) return k;
int root=Find_root(f[k]);//提前存储根节点
d[k]+=d[f[k]];//更新边权
return f[k]=root;
}
void merge(int x,int y){
int a=Find_root(x),b=Find_root(y);
if(a!=b) f[a]=b,d[a]=v[b],v[b]+=v[a];//与上文描述相同,注意顺序
}
种类并查集
我们知道并查集可以表示两人间的所属关系或并列同属关系,而在一些特殊情况中,我们需要表达两种或两种以上的关系,这时就不能用普通的并查集了。我们通常将一个并查集的空间开到两倍大, 1 1 1 ~ n n n 和 n + 1 n+1 n+1 ~ 2 n 2n 2n中每一个位置分别存储一元素的两种对立状态,如位置1存储a,位置n+1就存储a的敌人。合并时把表示同类的关系连接起来。
使用种类并查集的问题通常是要判断题目中是否存在非法关系,还要注意题目中给定关系的隐含条件。例如,敌人的敌人是朋友,每次给定两个人,表示两人是朋友。合并时除了连接这两人外,还要连接两人的敌人。如果漏掉了隐含条件,题目就会出错。
再例如更复杂的问题:三种生物循环残杀(a吃b,b吃c,c吃a),n只生物都属于三种生物中的一种,给定他们某两只之间的关系,表示x是y的朋友或
x是y的天敌,此时需要将数组开到3倍大,每一段分别表示本身、食物、天敌。连接的关系(表示同类)如下:
cin>>k>>x>>y;
if(k==1){//x和y是同类
else{
merge(x,y);//x和y
merge(x+n,y+n);//x的食物和y的食物
merge(x+2*n,y+2*n);//x的天敌和y的天敌
}
}
if(k==2){//x和y是天敌
else{
merge(y,x+n);//y和x的食物
merge(x,y+2*n);//x和y的天敌
merge(x+2*n,y+n);//x的天敌和y的食物
}
}
以上就是关于并查集的一些内容,感谢观看,手下留赞
只会营销号式结尾怎么办
α ( x ) \alpha(x) α(x)是 A c k e r m a n ( m , n ) Ackerman(m,n) Ackerman(m,n)的反函数。 A c k e r m a n Ackerman Ackerman函数的定义如下
A ( n , m ) = { n + 1 if m=0 A ( m − 1 , 1 ) if m>0 and n=0 A ( m − 1 , A ( m , n − 1 ) ) A(n,m) = \begin{cases} n+1 &\text{if m=0}\\ A(m-1,1) &\text{if m>0 and n=0}\\ A(m-1,A(m,n-1)) &\text{} \end{cases} A(n,m)=⎩ ⎨ ⎧n+1A(m−1,1)A(m−1,A(m,n−1))if m=0if m>0 and n=0
A c k e r m a n Ackerman Ackerman函数本身的增长是十分迅速地,例如
A ( 4 , 0 ) A(4,0) A(4,0)= 13 13 13;
A ( 4 , 2 ) A(4,2) A(4,2)= 2 65536 − 3 2^{65536}-3 265536−3。
而 α ( x ) \alpha(x) α(x)代表最大的整数 m m m使得 A ( m , m ) ⩽ x A(m,m)\leqslant x A(m,m)⩽x。可想而知它的增长缓慢得非常极端。在竞赛常用数据量下, α ( x ) \alpha(x) α(x)的值几乎是恒定的1。而时间复杂度等于此函数的并查集操作就可以看成是几乎不耗费时间的 O ( 1 ) O(1) O(1)算法,速度之快极其恐怖。 ↩︎















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









