






目录
Postgres数据库部署
1、编写docker-compose.yml文件
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
2、执行安装命令
在上述文件所在目录执行如下命令:
docker-compose up -d
3、查看Postgres的进程是否启动
docker ps

4、登录客户端
psql -h localhost -p 5432 -U postgres -d postgres

navicate 客户端连接
Postgres的日志介绍
日志分类
PostgresSQL的日志分为3类:pg_log(数据库运行日志),pg_xlog(WAL日志, 即重做日志), pg_clog(事务提交日志,记录的是事务的元数据)
1、pg_log(数据库运行日志)
这个日志记录的是数据库运行时,服务器,数据库的各种状态信息,比如报错信息,定位慢查询SQL, 数据库的启动停止信息,发生checkpoint频繁的告警信息等等。
2、pg_xlog(WAL日志, 即重做日志)
这个日志记录的是Postgres的WAL信息,写前日志,也叫预写日志。默认单个大小事16M, 这些日志会在定时回滚恢复,流复制以及归档时被用到,这个FlinkCDC底层所用的debezium也是针对WAL来做日志解析,获取对相应的DDL,DML的操作,记录着数据库的各种事务信息,不得随意删除或者移动这类日志文件。
3、pg_clog(事务提交日志,记录的是事务的元数据)
pg_clog这个文件也是事务日志文件,但与pg_xlog不同的是它记录的是事务的元数据(metadata),这个日志告诉我们哪些事务完成了,哪些没有完成。这个日志文件一般非常小,但是重要性也是相当高,不得随意删除或者对其更改信息。
Note:
这里的pg_xlog (WAL日志),即重做日志,和Oracle 的redo log, Mysql的binlog的功能是一样的。
pg_log默认是关闭的,需要设置参数启用此日志。pg_xlog和pg_clog都是强制打开的,无法关闭。所以,针对Postgres CDC是不需要开启相关配置的。
WAL日志
WAL日志的位置
PGSQL中的重做日志在数据库的数据目录是pg_wal, 在服务器搜索可知:
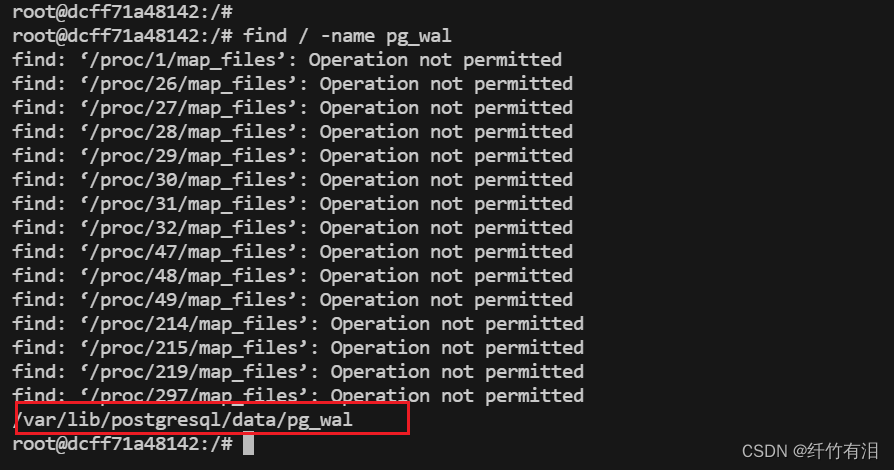
查看WAL日志文件

WAL日志算法
Q: 同样是写磁盘,为什么Postgresql在用户提交数据时,没有将数据直接写入到数据表磁盘上,而是写入到了WAL日志中?
我们知道磁盘IO一直是操作数据效率的一大瓶颈,而写WAL日志时,数据库采用了一种叫做重做日志算法的一种磁盘写入算法,在相同的数据量下,采用这种算法写入磁盘文件比普通的文件写入效率要提高一倍以上,所以Postresql或者其它数据库都是采用的这种,先更新内存数据和重写日志,最终将脏块同步到磁盘的方式,保证数据的安全性和持久性。
WAL文件的文件名解析
从上面的信息可以看到,WAL文件的文件名是由24位16进制的数字组成的,那么可以执行下面的命令来查看数据库当前正在使用的WAL文件,并以此文件名为例来说明下WAL文件名的含义:
postgres=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
000000010000000000000002
整个文件名00000001 00000000 00000002,其实分成了三个部分。在解释每个部分的含义之前,我们还必须引入另外一个概念——LSN。LSN,全称是Log Sequence Number 翻译过来就是日志序列号,是一个Postgresql全局的不断增长的8子节长度的数字,它会随着WAL日志的不断增加而不断地增长。
现在,我们回过头来,再看下WAL日志三个组成部分:
第一部分,叫做时间线,是从1开始递增地数字,很显然,当第二、三部分数字达到最大值之后,第一位会递增1。
第二部分,叫做LogId,实际上是LSN的高32位。
第三部分,叫做LogSeg,是LSN的低32位除以WAL文件的大小。WAL文件的大小默认是16M,但是可以在initdb时指定修改。
WAL文件的循环复用原理
如果单单从pg_wal目录下各个文件名称来看,WAL日志文件一直是在滚动更新的,旧文件不断地在删除、新文件不断地增加。我们又了解到,磁盘IO实际上效率是非常低的,那如果在WAL更新的过程中一方面要创建新文件,另一方面要删除旧文件,那岂不是会很耗时?其实是,当checkout命令执行后,旧的WAL文件也就没用了,当需要产生新的WAL文件时,并不是真正生成了新的文件,而是将最老的一个WAL文件进行了重命名。而且重命名也并不是我们传统意义上的rename,而是为旧文件创建了一个硬链接,然后再删除旧文件。
FlinkCDC的实时采集数据的演示
| 名称 | 版本 |
|---|---|
| Flink | 1.16.1 |
| FlinkCDC | 2.3.0 |
Flink CDC演示Demo的maven的项目依赖
<properties>
<flink.version>1.16.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--flink 依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-postgres-cdc</artifactId>
<version>2.3.0</version>
</dependency>
<!-- web UI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志加载 -->
<!-- logback必备依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
Postgres CDC的Table API
public class FlinkSqlCDCPostgresSourceExample {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE shipments (\n" +
" shipment_id INT,\n" +
" order_id INT,\n" +
" origin STRING,\n" +
" destination STRING,\n" +
" is_arrived BOOLEAN\n" +
") WITH (\n" +
" 'connector' = 'postgres-cdc',\n" +
" 'hostname' = 's171',\n" +
" 'port' = '5432',\n" +
" 'username' = 'postgres',\n" +
" 'password' = 'postgres',\n" +
" 'database-name' = 'postgres',\n" +
" 'schema-name' = 'public',\n" +
" 'table-name' = 'shipments',\n" +
" 'debezium.snapshot.mode' = 'initial'\n" +
")");
Table table = tableEnv.sqlQuery("select * from shipments");
tableEnv.toChangelogStream(table).print("Postgres cdc: ").setParallelism(2);
env.execute("Flink CDC: Postgres -> Print");
}
}
Flink CDC 任务WEB UI
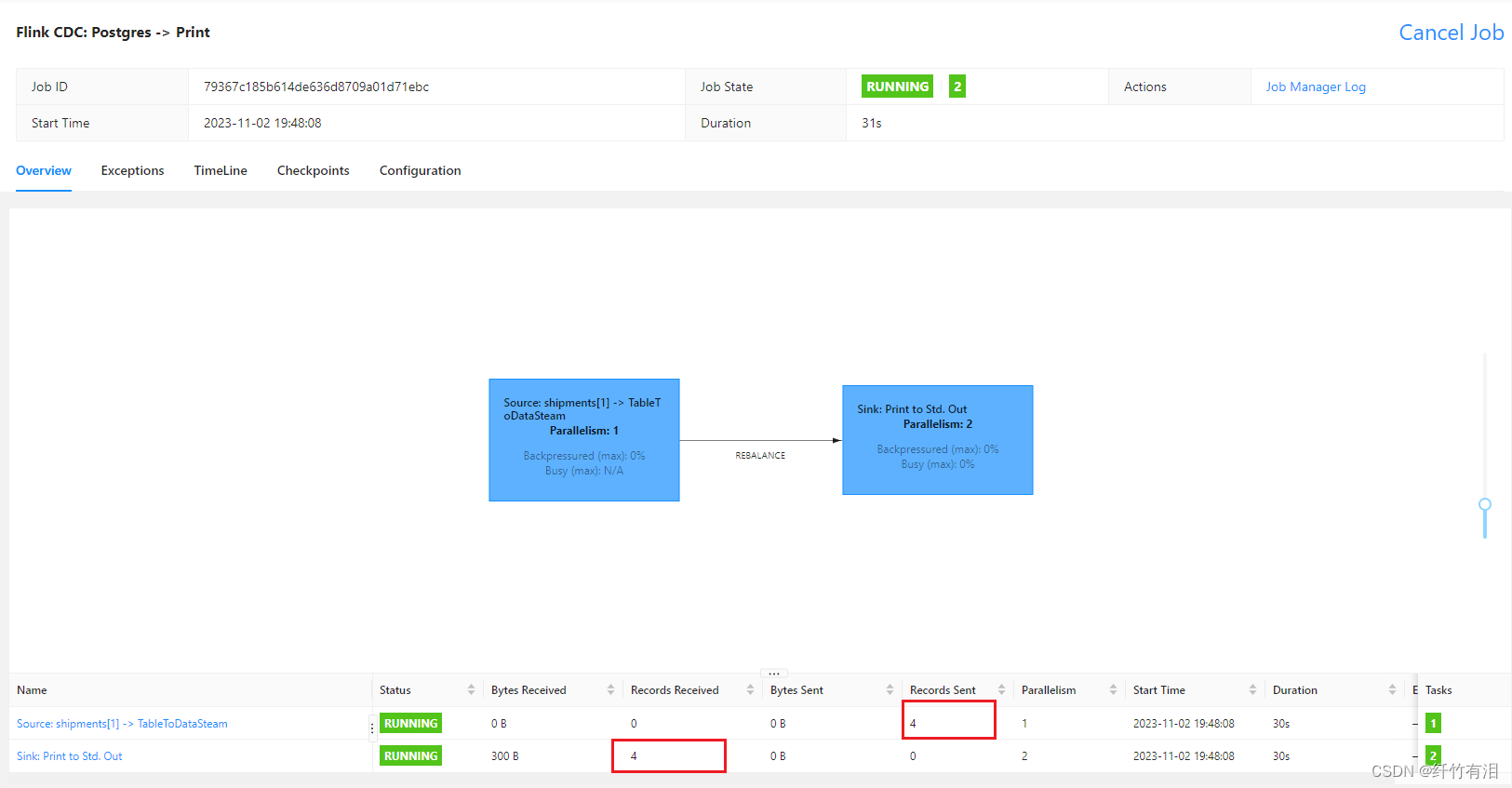

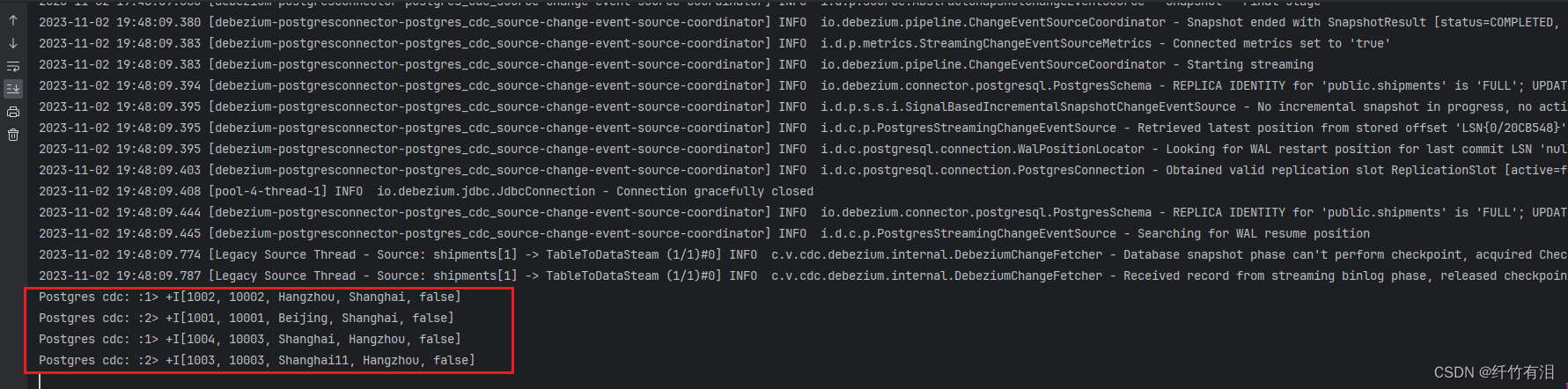















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









