







机器学习-线性回归推导
机器学习就是找到目标函数,然后结合优化算法,得到我们的理想参数和训练器,最后进行预测或分类。
注重这个学习的过程,而不是直接求得值,所以优化算法必不可少。
1、线性回归方程和转化
1.1 线性回归方程
性回归的目的:求θ项,然后输入x项,预测输出。
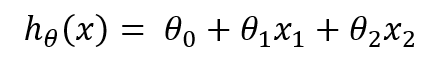
其中,x项是特征值,θ项是具体的权重;θ0是偏置项可以对值进行微调;θ1,θ2两个是核心的元素;
1.2 线性回归方程转化
因为ML都是进行矩阵运算,可以提高计算速率。
一般x:x1,x2都是默认列向量,而且没有x0,所以需要构造一列数据x0=1的值,所以上面的公式可以转换为矩阵形式:
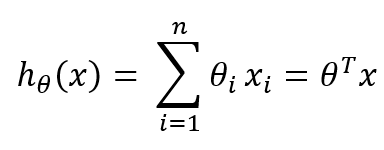
2、误差
机器学习驱动目标:由于需要求θ项,所以需要偏差项,所以这里用真实值和预测值之间的偏差来规定机器学习的行为,偏差越小越好,ε
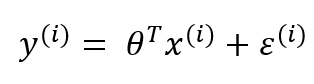
其中:y是真实值,
θ
T
θ^{T}
θTx是预测值。
机器学习的前提: ε(i)是独立且具有相同的分布,且服从均值为0方差为 θ 2 θ^{2} θ2的高斯分布
1、样本和样本之间是独立的,互不影响;
2、样本尽可能来自相同的分布;
3、服从高斯分布。
但是现实中,很多时候没有完全符合这些条件,但是可以进行机器学习的。
3、误差分析
3.1 预测值和误差
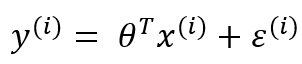
3.2 误差化简
由于误差服从均值为0的高斯分布:
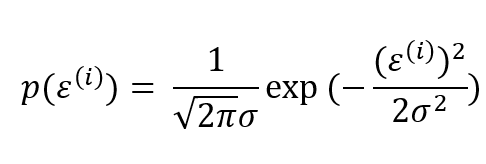
因为我们想要的是θ,所以要消去ε,将1代入2式子:
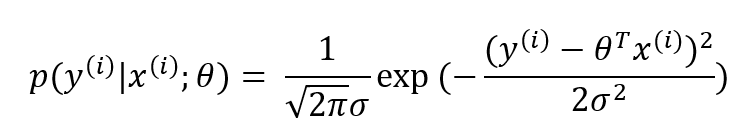
我们想要的目标:θ和x组合之后,成为y(真实值)的可能性越大越好。
3.3 误差转化为求最大似然函数
似然函数(找到θ,使得L(θ)最大):
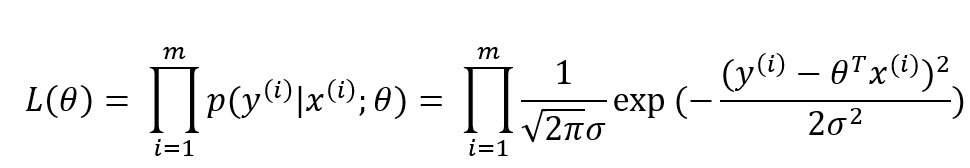
因为似然函数是一个类似-x2趋势的图形,有极大值,为了求解方便,这里取对数得到对数似然。
对数似然:
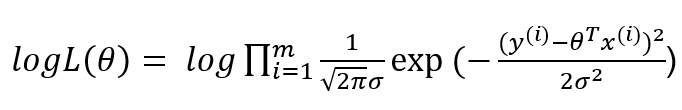
简化:
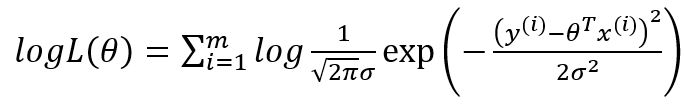
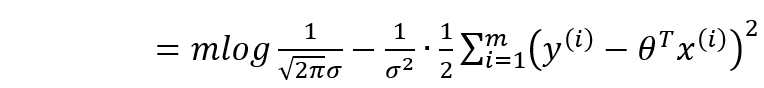
3.4 误差转化为求最小目标函数
目标:让似然函数(对数变换后也是越大越好),最后得到目标函数:
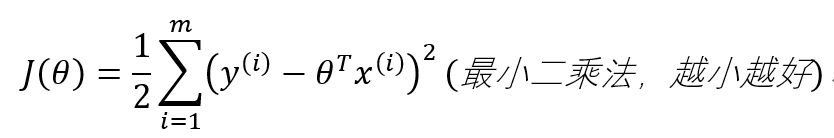
4、目标函数-通过偏导求极值
4.1 目标函数
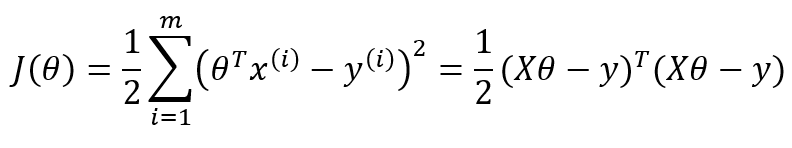
这里:
数据是m*n维,m个数据,n个特征
X:m*(n+1)这里多加入一个1的特征
θ:(n+1)*1的n+1维列向量
y:m*1的m维列向量
4.2 目标函数求偏导
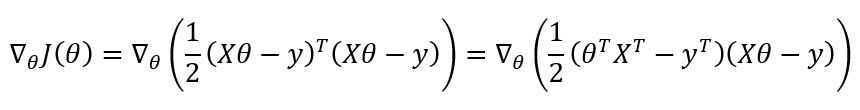
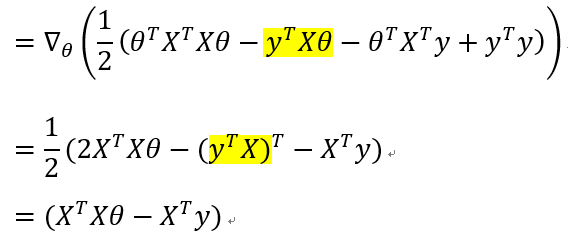
这里补充一些求偏导的知识:
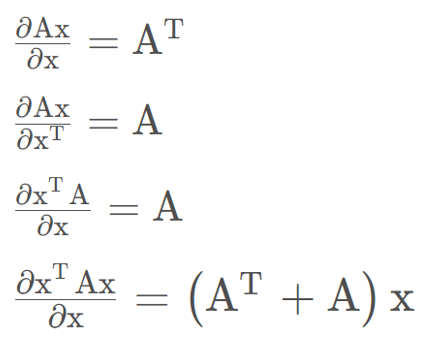
偏导等于0:
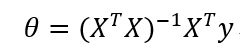
4.3 目标函数直接求偏导缺陷
上述方法缺陷:没有机器学习的过程,有数据直接得到一个结果;其次有逆矩阵,可能不存在值,导致方程无解。
需要新方法来得到最好的结果,于是引入机器学习方法。
5、目标函数求极值点-机器学习方法
5.1 目标函数
机器学习思想:每次步行一定距离,慢慢让结果变优,而不是一步到位。这里引入梯度下降优化算法。
目标函数:
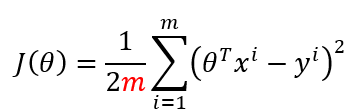
这里比之前的目标函数多了一个m,这里是除了总样本数目。对结果没有影响,我们需要求的是目标函数的最小值,对应的θ。
5.2 批量梯度下降
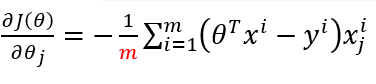
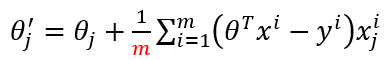
1是梯度方向,2是每一步的梯度下降,每次往梯度下降的方向走一步,这个容易得到最优解,但是考虑了所有样本,假如数据m样本多了的话,运算速度会很慢。
5.3 随机梯度下降
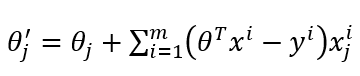
这里像比于批量梯度,少了m。每次只找一个样本,迭代速度快,但是不一定每次都是朝着收敛的方向。
5.4 小批量梯度下降
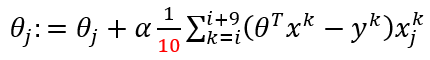
这里相比于批量梯度下降,把m变成10,并加入步长alpha。时间,内存的条件允许的条件下,这里可以选择大点的数据,比如64,128等等,不限制于10。alpha是学习步长,一般是0.01等等。
6、总结
对于线性回归方程,这个比较特殊,比较容易直接求出θ,但是里面有逆矩阵,可能求出来的值不对,而且很多情况下对于其他公式不能直接求出θ,所以需要机器学习的思想:引入优化算法,一步一步去逼近真实值,间接求出最优θ。














 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









