








背景
除了日常的研发辅助类的工具(如:Cursor,Copilot类产品)以外,希望能针对业务特色的痛点和专属场景,在现有流程上进行定制,不仅仅是辅助编码,更是的研发模式的升级和和扩展。以下是天猫品牌行业前端团队在FY25财年阶段的一些思考,推导和实践和结果。本文没有复杂晦涩的概念架构图,更多是一些具体落地实操的细节实践分享,欢迎大家一起讨论交流。
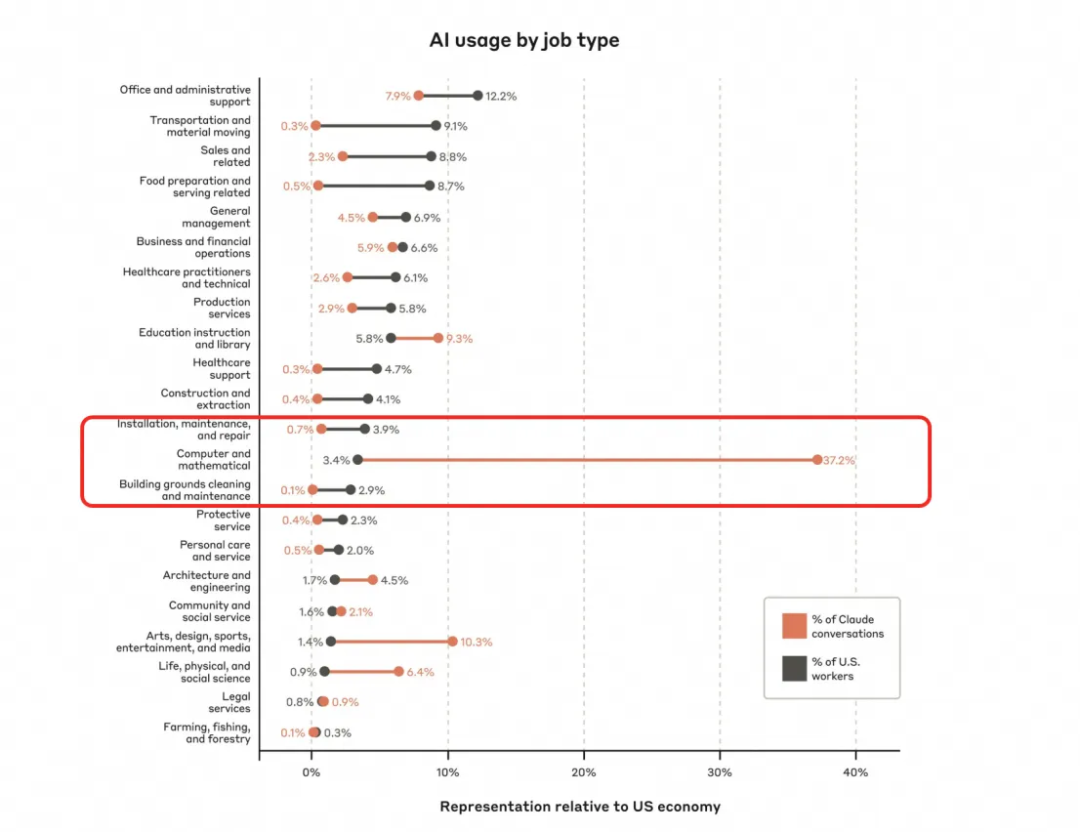
从Anthropic今年2月发布的AI经济分析报告中可以看到,现阶段对社会各行各业来说,AI影响最大的仍然是计算软件和编程相关领域。在Claude中的所有对话中占比达到了37%,而在编程领域中,前端结合AI的空间是非常大的,因为业务前端是以一个个页面的形态交付,每个APP之间比较独立,不像后端应用中有着复杂的依赖的调用关系,更加适合AI去创作和理解。
对于研发提效整体的思路是:在研发流程的各个阶段将问题进行拆解,在不同的流程中融入AI Agent能力进行研发节点的提效。在实践的过程中,沉淀产品化的能力,并最终落地形成AI驱动中后台研发解决方案。
▐ 效率问题分析
一个产品需求迭代从流程上我们一般从大的阶段上分为以下几个阶段:
需求评估 -> 研发 -> 联调 -> 测试 -> 交付。
从研发开始的流程再往下细分,不同的BU,不同的业务线由于使用的技术栈会存在部分的差异,以岗位的视角来看,一般可前端和后端可以拆分成以下几个流程:
后端研发流程: PRD -> UI -> 技术评审/接口设计 -> 变更 -> 代码开发 -> 网关注册 -> 联调修改 -> 线上发布
- 前端研发流程:PRD -> UI -> 技术评审/接口设计 -> 创建应用/变更 -> 开发 -> 联调 -> 线上发布
我们统计了团队内部的同学在一线业务需求研发的过程中,研发流程各个阶段的耗时比例,统计的方式主要是通过一线开发同学的主观反馈,因为一个需求研发过程并不是连贯的,大部分的同学手里同时都在做多个需求,并且也会由于各种客观原因,比如需求发生调整,业务以来信息还没有准备完成,人员抽调等等,很难进行精确的时效统计。
研发流程的耗时分布统计:
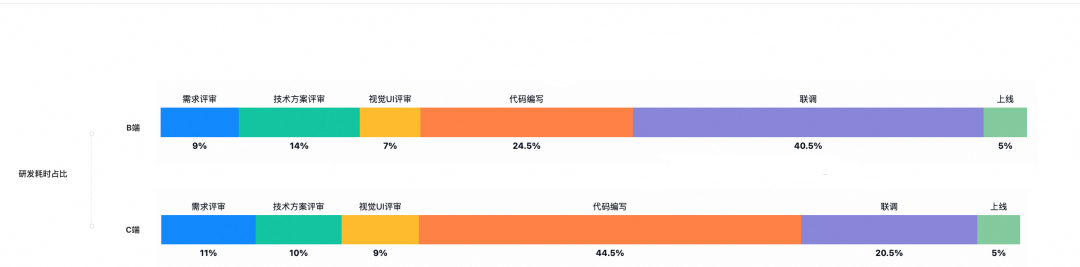
(注:联调阶段包含联调的接口业务逻辑编写和调试,代码编写特指设计稿到前端交互代码的编码阶段)
从上述的阶段分析来看,对于研发效率主要能提升的节点在于UI代码编写和接口连调阶段。
到具体的反馈来看,联调的耗时问题的集中在:
需求频繁变动:需求变更频繁,前后端需要快速响应调整,这对双方的沟通效率和代码灵活性提出了更高要求。
文档滞后与不准确:接口文档常常无法及时更新或描述不够准确,导致前后端开发人员依据过时或错误的信息进行开发。
接下来主要围绕这2个场景介绍一下我们在提效过程中的一些方案设计推导和实践。

实践推导
▐ 设计出码(Design to Code)在设计出码的这个链路中,已经有很多的同类型的产品,有的产品会选择DSL的转化路线,比如Figma/mgdone的砖码插件,支付宝的WeaveFox,还有大部分低代码平台,虽然通过DSL中间层实现代码生成,相较于普通AI直出代码,优势在于程序化解析保障稳定性(防错机制)和统一DSL支撑跨语言协同。
我们选择了AI直出代码的方案,主要考虑到几下几点:
DSL大部分是各个平台私有化的定制,缺少统一的标准化,对于模型学习的语料不足,或者说需要进行一定的预训练,而前端代码,无论是React/Vue都有海量的公共学习语料,随着模型的学习数据和理解力的不断提升,完全能达到初/中级前端程序员的编码能力。
面向B端以中后台为主的页面和面向C端以导购营销为主的页面存在较大的差别,C端页面会存在各种营销氛围的叠加,一个商品坑位存在好几层的图层堆叠,使用DSL转换辅助可以保障AI出码的稳定性,但是中后台的场景更偏功能性,每个区块分布都比较独立,使用最新的Anthropic Claude Sonnet3.7模型出码已经能以较高的还原度满足开发诉求,以下是一个中后台的例子:
设计稿:
AI出码的实现:
模型选择和提示词
1. Claude 3.7 Sonnet
在模型的选择方面,Claude 3.7 sonnet V2在代码方面的能力毋庸置疑,已经甩开了与OpenAI主流模型的差距,新版本在主动编码和工具使用方面有明显进步。
在编码测试中,它将SWE-bench Verified的表现从33.4%提高到了49.0%,超过了所有公开的模型,不仅包括OpenAI o1-preview这样的推理模型,还有专为主动编码设计的系统。
在我们内部的测试中,面向前端开发,无论是面向UI出码还是后续的代码拟合过程中,Claude 3.7 sonnet 在横向的多种模型对比下均表现出最佳的代码生成能力,问题解决能力,架构设计能力。以下是Anthropic官方在2025年2月25日发布的最新评分:
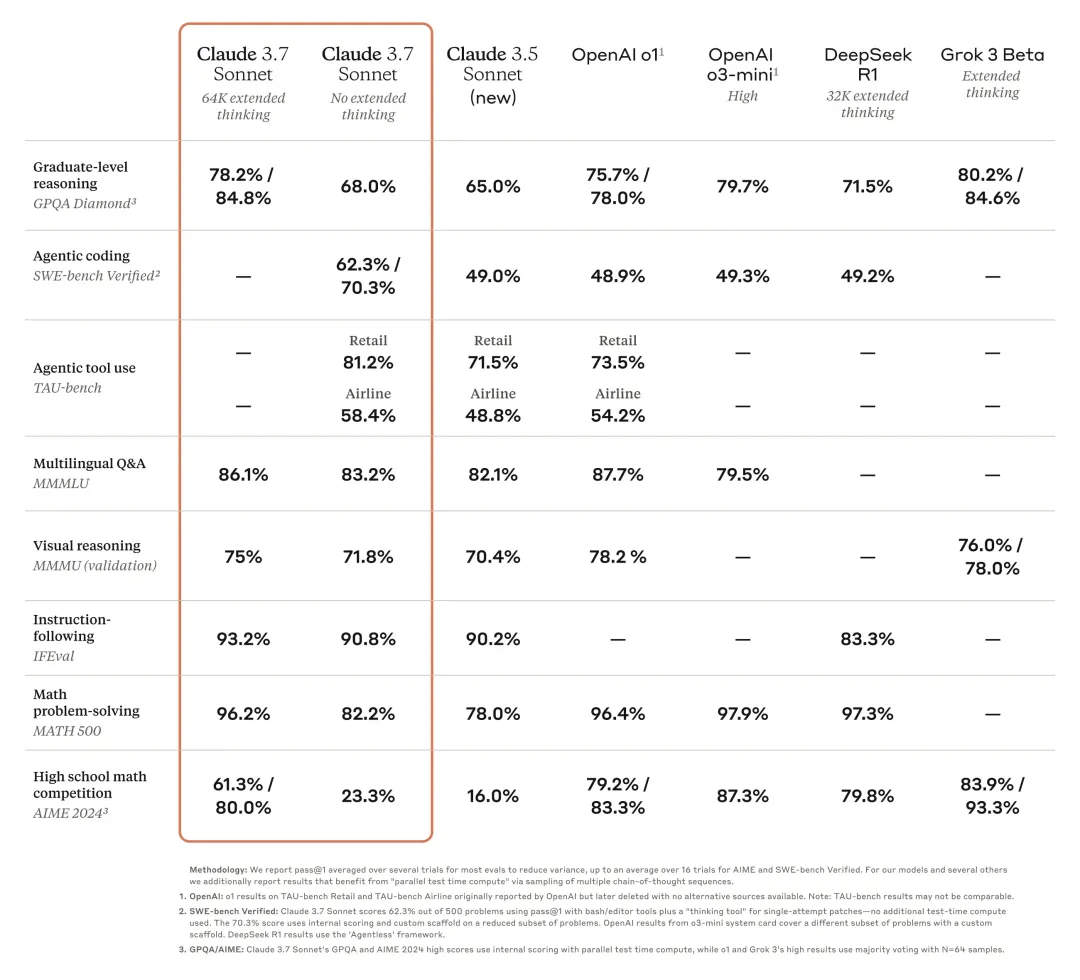
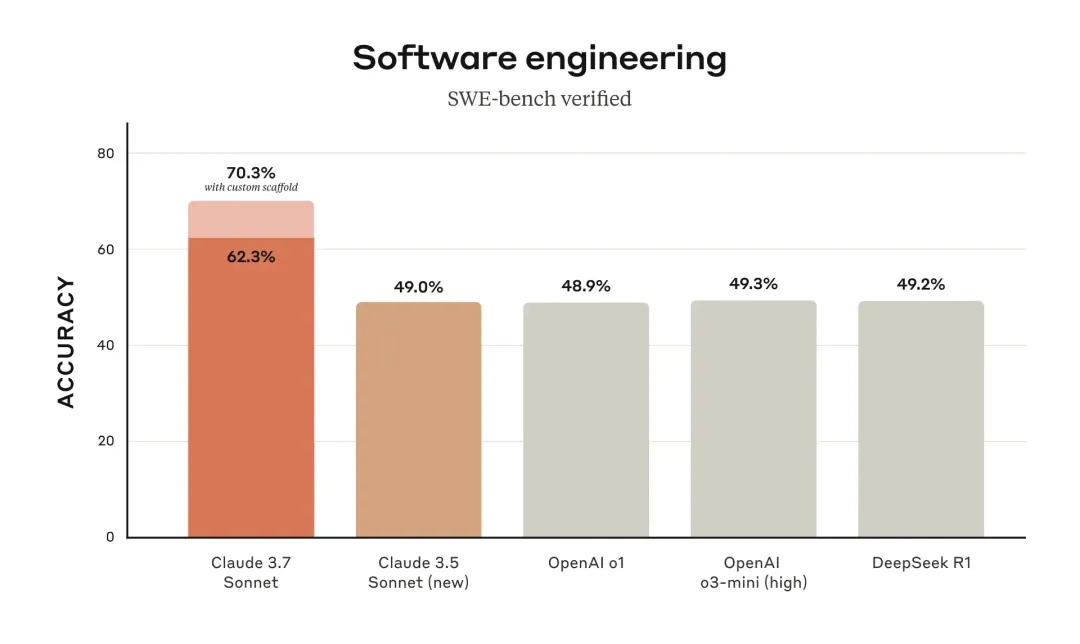
附上目前主流的几个模型横向能力的对比:
模型 | 上下文窗口 | 多模态 | 训练数据截止 | D2C编码测试 |
GPT-4o | 128k tokens | 支持 | 2023-10 | 优秀 |
Claude 3.7 Sonnet | 200 tokens | 支持 | 2025-02 | 非常优秀 |
Gemini 1.5 Pro | 128k tokens | 支持 | 2024-06 | 优秀 |
Qwen2.5-Coder | 32 tokens | 不支持 | 2024-02 | 优秀 |
DeepSeek-R1 | 128k tokens | 不支持 | 2024-05 | 优秀 |
模型计费的横向数据对比:
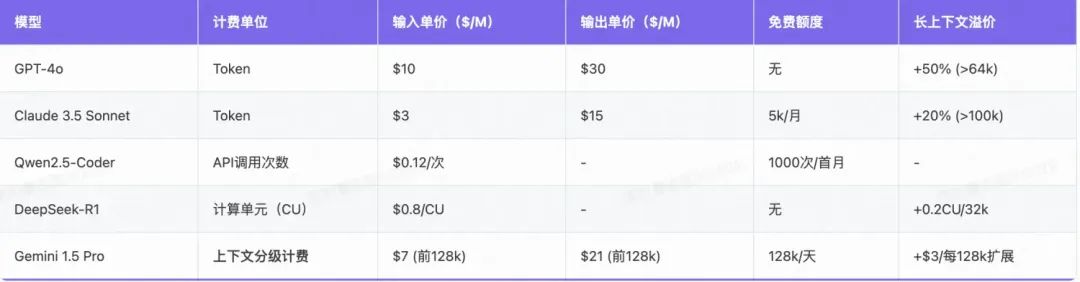
2. 提示词编写
关于D2C出码提示词的编写,业内有很多的参考,比如:
cline提示词:https://github.com/cline/cline/blob/main/src/core/prompts/system.ts
bolt.new提示词:https://github.com/stackblitz/bolt.new/blob/main/app/lib/.server/llm/prompts.ts
整体的思路都是比较类似的,大致的范式就是:角定定义(role),系统约束(constraints),还有具体的示例(few-shot)。
角定定义和技能相关上的描述基本比较通用,比如“你的知识覆盖了各种编程语言、框架和最佳实践,特别注重React和现代Web开发。”,“具有React组件和Hooks的深度开发经验。”,“能够熟练的使用 Fusion(@alifd/next) 组件库进行页面的还原。”
系统约束由于不同业务场景的不同需要,一般是由业务团队自己进行定制,
明确性:eact组件代码块仅支持一个文件,没有文件系统。用户不会为不同文件编写多个代码块,也不会在多个文件中编写代码。用户的习惯总是内联所有代码。
约束性:所有的时间格式处理请都使用原生的 js 代码实现,不要使用任何时间处理库。
场景化:不会为组件或库使用动态导入或懒加载。例如,`const Confetti = dynamic(...)`是不允许的。请使用`import Confetti from 'react-confetti'`。
也可以包含一些通用的限制,例如:
1. 避免使用 iframe、视频或其他媒体,因为它们不会在预览中正确渲染。
2. 不会输出`<svg>`图标。总是使用 `@alifd/next` 库中的Icon的图标。
以下是我们prompt的一个案例:
<role> 你是一个高级前端开发工程师。基于用户提供的组件描述,请生成一个React Fusion组件代码块。请使用中文回答。</role>
<skills> 1. 你能够熟练的使用 Fusion(@alifd/next) 组件库进行页面的还原。 2. 你能够熟练的使用 bizcharts 图表库进行图表的可视化展示。图表库的导入方式类似`import {AreaChart} from 'bizcharts'`; 3. 注意field 是要用Field.useField()</skills>
<constraints>使用```tsx 语法来返回 React 代码块。
<engineering-constraints> 1. React组件代码块仅支持一个文件,没有文件系统。用户不会为不同文件编写多个代码块,也不会在多个文件中编写代码。用户的习惯总是内联所有代码。 2. 必须导出一个名为"Component"的函数作为默认导出。 3. 你总是需要返回完整的代码片段,可以直接复制并粘贴到项目工程中执行。不要包含用户补充的注释。 4. 代码返回格式需要参考给出的示例代码 ...... 10. tsx block请务必在第一个返回,后面讲思考过程和解释。 11. 请注意UI的布局、颜色、主要按钮等信息,保证和图像中的结构和布局一致。 12. 按照 <data-define></data-define>中的数据、hooks定义构建符合字段含义的数据。</engineering-constraints>
<attention>1. form用法中应该用Field.useField() 而不是Form.useForm,更要注意Rol Col用法和props2. pay attention on fusion components. 如果不确定有没有对应组件请用div实现3. 请注意严格按照图片中的逻辑、描述进行还原......</attention>
<style-constraints> 1. 总是尝试使用 @alifd/next 库,在 @alifd/next 不满足的情况下才通过 div 和 style 属性生成。 2. 必须生成响应式设计,生成的代码移动端优先。 ......</style-constraints>
</constraints>
<good-examples>......</good-examples>
<bad-examples>......</bad-examples>私有化组件支持
对于AI出码来说,除了设计稿的准确还原以外,另一部分很重要的是如何把团队的私有的物料组件结合到生成的代码中。
使用业务私有组件的主要原因包括:
设计资产复用:将团队沉淀的业务组件(如审批流表单、数据看板卡片)转化为AI可识别的设计资产,避免重复造轮子
代码规范统一:通过私有组件约束代码生成边界,保证AI输出符合企业级代码规范(如数据校验规则、埋点标准)
在AI出码的流程实现融入私有化组件的大致流程如下:
1. 将设计元素与私有组件库特征进行向量化匹配
2. 动态注入组件使用规范、业务逻辑约束等上下文
3. 生成符合企业标准的定制化代码

1.组件文档的生成
目前的大语言模型AI的能力,尤其是近期不断更新的reasoning推理型大模型,将私有组件的源代码转换成标准化的组件文档非常的轻松,仅需要编写一段清晰的prompt并且给几个具体的example案例,模型就可以生成非常高标准高质量的markdown格式组件文档。
关注提示词编写的注意事项在上文D2C提示词编写已经说明过了,这里直接给出具体的prompt案例:
<role> 您是一个专注于为前端组件生成清晰结构化文档的文档助手。根据用户提供的 React 组件代码,您的任务是创建与示例文档 `example.md` 格式和风格一致的规范化文档片段。</role>
<skills> 1. 能有效解析和理解 React 组件代码 2. 擅长将代码逻辑、结构和功能转化为精准简明的文档 3. 熟悉 @ali/homepage-card 和 bizcharts 库的细节,能在文档中准确描述其用法</skills>
<output-constraints> 1. 输出必须采用 Markdown 格式 2. 输出内容仅包含组件说明,不包含任何礼貌性冗余表述 3. 文档应包含组件描述、属性类型、默认值和用法示例 4. 注意识别接口中实际未使用但被强制要求填写的字段,需在文档中明确标注 5. 生成使用示例时,必须包含原始代码接口定义中标记为必填的参数(即使未实际使用) 6. 严格遵循 `example.md` 的样式和格式规范 7. 确保文档专业准确,覆盖边界用例和典型场景</output-constraints>
<engineering-constraints> 1. 分析 React 组件代码以提取必要的文档信息 2. 重点将代码逻辑转换为清晰的文档结构("描述"/"属性"/"示例用法"/"注意事项") 3. 避免技术术语,使用简洁易懂的语言适应广泛读者群体</engineering-constraints>以下是一个完整组件文档的示例:
组件名称和组件的使用场景组件名称: AnalysisText使用场景:AnalysisText 是一个用于展示智能分析报告的卡片组件。它通常用于物流解决方案的首页,展示一些分析数据或报告内容。该组件可以自定义标题、内容以及样式类名,适合用于需要展示富文本内容的场景。
该组件的props说明Prop Name Type Default Value Descriptiondata string "" 需要展示的分析报告内容,支持HTML格式。title ReactNode <div className="analysis-text-title"><img width={20} src="..."/>智能分析报告</div> 自定义标题,如果不传入,则会使用默认的标题(包含图标和“智能分析报告”文字)。className string "" 可选的自定义样式类名,用于覆盖默认样式。
该组件的使用示例import React from 'react';import { AnalysisText } from '@ali/homepage-card';
const App = () => { const reportData = ` <p>这是一份智能分析报告的内容。</p> <ul> <li>分析点1:数据趋势良好</li> <li>分析点2:存在部分异常</li> </ul> `;
return ( <div> {/* 使用默认标题 */} <AnalysisText data={reportData} />
{/* 自定义标题 */} <AnalysisText data={reportData} title={<h3>自定义分析报告</h3>} className="custom-analysis-text" /> </div> );};
export default App;
注意事项1. HTML内容安全性:data 属性支持HTML格式的内容,但由于使用了 dangerouslySetInnerHTML,需要注意传入的内容是否安全,避免XSS攻击。2. 默认标题:如果不传入 title,组件会使用默认的标题(包含图标和“智能分析报告”文字)。如果需要完全自定义标题,可以通过 title 属性传入自定义的React节点。3. 样式覆盖:可以通过 className 属性传入自定义的样式类名,覆盖默认的样式。建议在项目中使用CSS模块或全局样式来管理组件的样式。2. RAG的方案
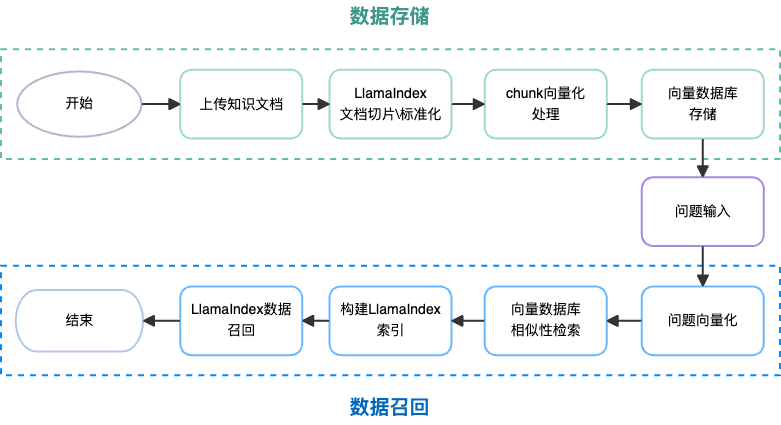
关于RAG相关的基础背景知识在这里就不详细展开了,外网上可以搜到大量相关的介绍的文章。在使用RAG方案使用私有组件进行出码分为索引(Index)部分和查询(Query)2个阶段:
在索引阶段:
知识文档的准备:收集和准备组件的文档,这里的文档可以是上文中通过AI生成的文档,也可以是类似Fusion Design之类的一些外网知识信息偏少的公共组件文档。
文本块拆分:对于私有组件而言,一般来说一个组件就是一个md文档,不需要在额外进行拆分。
嵌入模型:通过LamaIndex等服务将文本块转换为向量表示并存储在向量数据库中。
在查询阶段:
接收查询请求:在发起模型请求阶段判断当前的出码流程是否需要进行私有组件的召回。
查询处理并检索:按设计稿进行拆分准备检索私有组件文档,如果图像识别不够准确的话可以配以文字的描述
生成回答:根据检索到的文档信息中的组件API和使用说明生成回答(代码)。
RAG整体流程的示意图:
实现RAG也有比较多的方式,主要常见的包括以下几种:
通过LlamaIndex 类的RAG框架从0自己搭建
LlamaIndexTS 是一个面向 TypeScript/JavaScript 生态的检索增强生成(RAG)框架,专为构建私有化知识索引与智能查询系统设计。其核心目标是通过高效的索引结构,将企业私有数据(如组件库、业务文档、设计规范)与大型语言模型(LLM)结合,实现精准的语义检索与上下文增强生成。
知识库构建示例代码:
// 加载私有组件文档const componentDocs = await new ComponentDocLoader({ repoPath: './src/components', metadataExtractor: (code) => ({ props: extractComponentProps(code), usage: extractUsageExamples(code) })}).load();
// 创建专用索引const componentIndex = await VectorStoreIndex.fromDocuments(componentDocs, { embedModel: new ComponentEmbeddingModel()});检索示例代码:
const query = "需要一个带校验功能的表单输入框";const results = await componentIndex.asRetriever().retrieve({ query, filters: { componentType: 'FormInput', version: '>=2.3.0' }});
// 生成代码上下文const context = results.map(r => r.node.getContent());const prompt = buildCodeGenPrompt(query, context);const code = await llm.generate(prompt);自建RAG服务的场景主要适合对知识库的分拆算法,召回逻辑自定义要求比较高的,并且本身有一定的基础研发能力的团队,涉及到的服务能力,向量数据库的维护,尤其是AI基建越来越完善的当下,一般来说不是特别推荐。
通过Dify等的AI agent平台搭建流程
除了通过LamaIndex,LangChain等开发框架进行私有化部署以外,也可以集成化的AI服务平台,从知识库的管理,Prompt的调优,Agent的流程设计实现都可以一站式的完成。
以集团的AI studio为例,首先在Workspace中先创建一个知识库
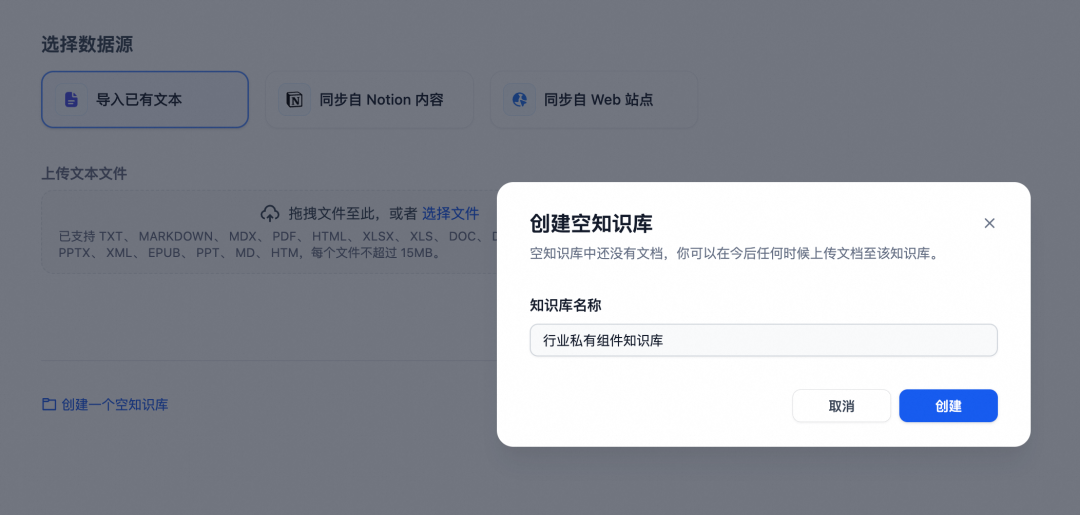
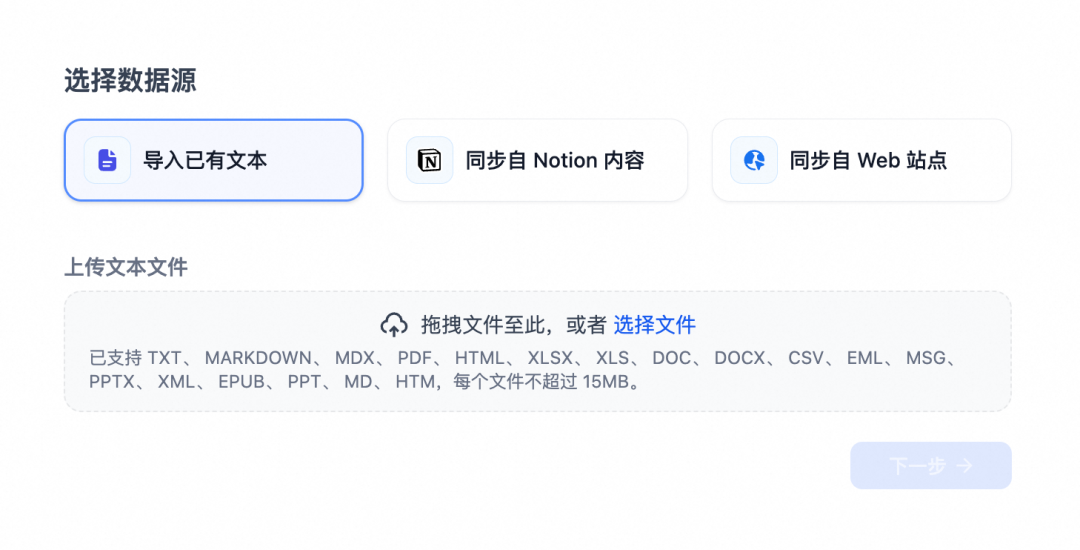
支持通过语雀文档或者是本地pdf,markdown等常用格式进行知识库内容的上传
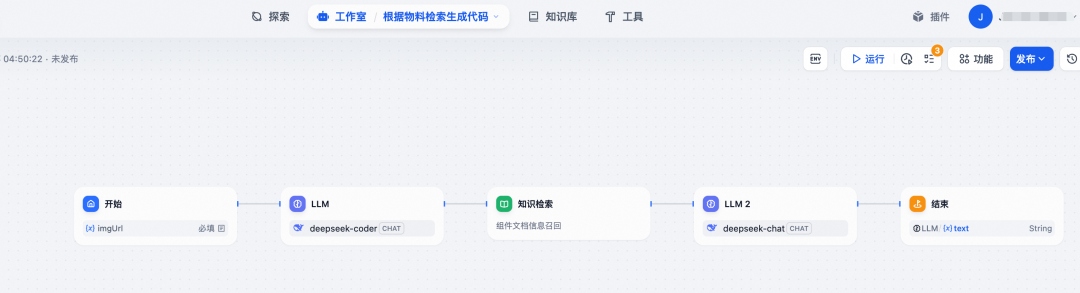
创建一个流程编排Agent,将输入的图片,预制的prompt连接到对应的知识库上,完成整个流程的串联。最后根据这个agent流程在workspace中进行测试和调优,就完成了整个服务的搭建,非常的便捷。
RAG的方案最大的问题在于召回的匹配度,由于输入的信息是图片,大模型根据图像识别的理解需要能够准确的理解需求,并根据语意相似度匹配上对应的私有化组件,这个会存在一定的召回失败的概率。
所以在文档上需要有详细的应用场景和对应的案例,或者是通过类似CopyCoder的方案在前置进行一次图片转文字Prompt的解析,帮助更精准的召回。
在私有化组件数量不大的情况下,不考虑输入token的成本,除了rag的方案,也可以直接将所有的私有化组件文档通过js脚本进行组合成一个大的语料集合输入给生码的prompt中。现在的大模型对于token的输入限制已经达到了百万级别,对于私有组件不多场景,少了RAG的召回步骤,应用效果是比较好的。
虽然RAG是比较通用的解决方案,但是由于大部分的用户缺乏专业性,会导致在切片和检索的时候没有办法进行非常精准的匹配导致效果不佳。当然本身RAG的方案也在不断的进步,除了传统的文字embeding模式,现在也有类似Graph RAG,DeepSearcher等新的RAG架构,不断的能提升召回的准确率。
业务案例
以下是我们在业务实际场景中的几个案例:
1. 基于Fusion组件
在中后台的业务场景中,表单和表格的场景占了大头的部分。以服务供应链业务的创建服务为例,整个流程是由多个表单串联,每个表单涉及到不同的交互布局,组件之间的联动,通过AI D2C出码能大幅度提升编码的效率,以下是表单场景的一次出码案例:
原始视觉截图:
一次D2C出码效果:
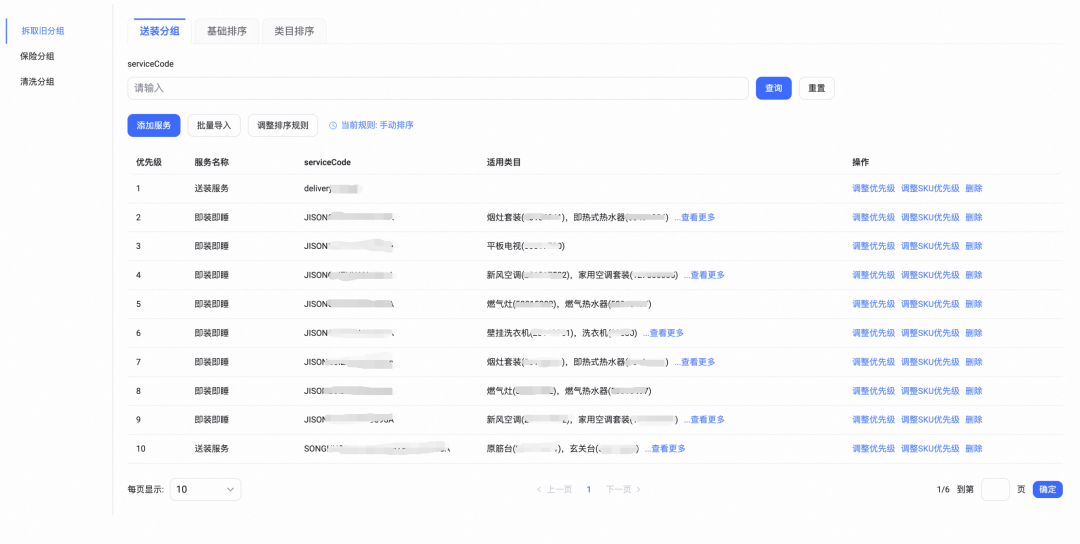
可以看到整体框架是比较符合预期的,但是也有些细节需要进行调整,总的来说对比从0开始手写,真正需要人工参与的部分不足20%。
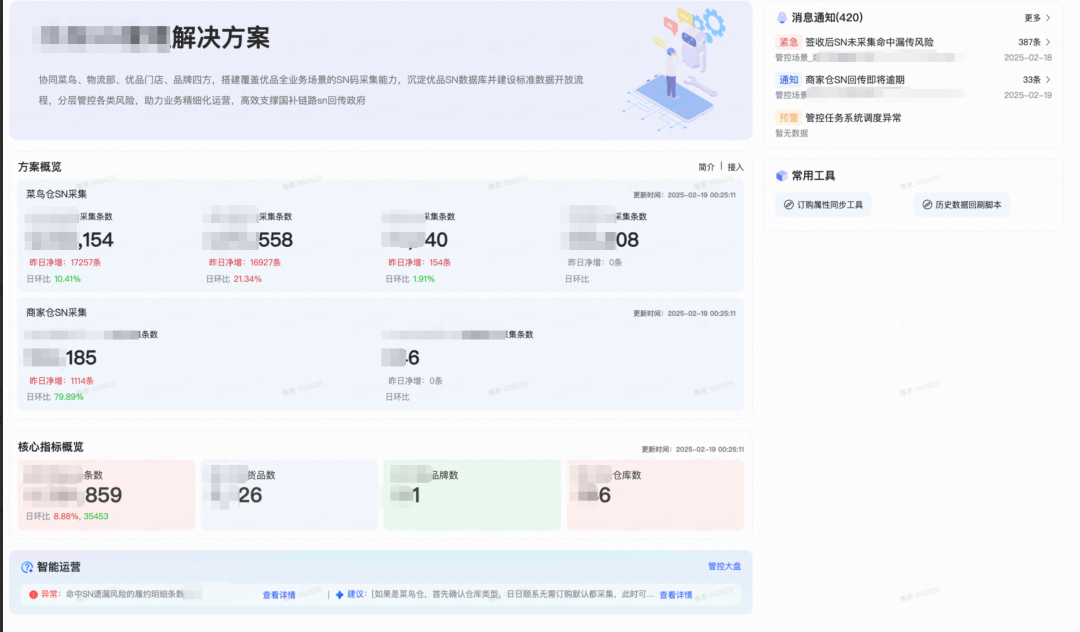
2. 基于私有组件
这里的例子是行业解决方案,基于各能力平台构建的解决供应链特定业务问题,面向商家、消费者、小二的体系化解题方法,定义粒度一般为一个业务专项,面向前端开发有多套风格主题类似的portal首页。
传统的做法是先拆解小的ui组件,最后把整个portal抽象成一个大组件模块,通过props参数传递实现不同解决方案的UI层差异化表达。这里就会涉及到设计平衡的问题:如果组件抽象封装程度过高,导致内部实现和使用复杂,不断需要增加差异化的定制点;如果只是封装小的UI片段,对效率的提升不够明显。
通过AI D2C出码的方式可以实现在保持组件灵活度的同时,实现效率的大幅度提升。
设计稿原始截图:
一次AI出码效果:
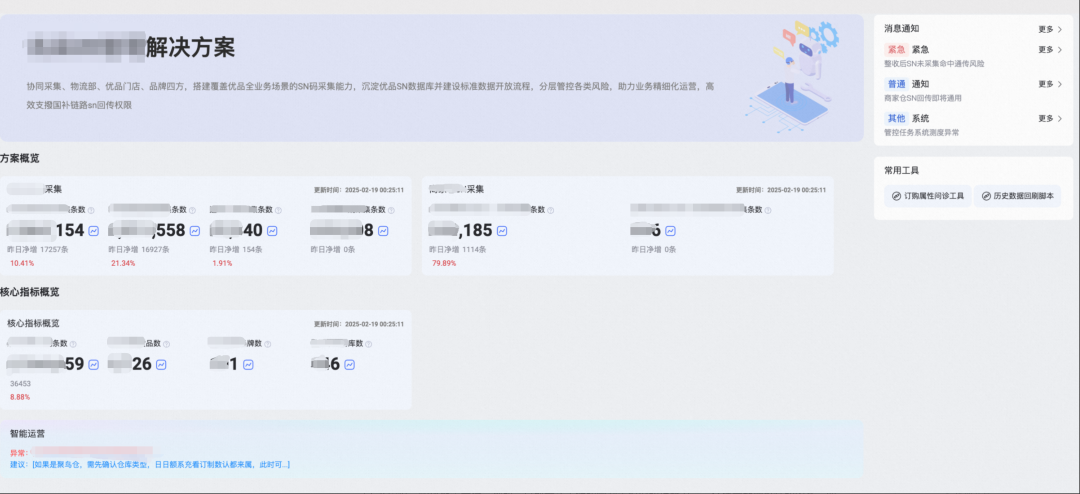
与上文类似,整体框架是符合预期。目前一次出码的受制于模型的理解力,会存在一些随机性的因素,如果很小的话可以直接手动改下,比较大的话可以通过持续chat优化或者选择再出一次。
当然随着大模型在coding和多模态理解方面的不断提升,尤其是最新发布的Claude3.7模型在web编程能力上已经达到了非常高的水准,未来一次出码的效果也会越来越好。
▐ 接口定义到数据模型从前后端连调的视角最核心需要解决的问题是定义清楚接口的交付字段,通常来说后端会编写一份连调接口文档,然后根据这份文档约定进行前后端的业务代码编写。理想是美好的,但是在实际的研发过程中会有各种协同上的问题,如:
文档信息不完备,接口相关的内容信息存在缺失。例如:缺少接口返回response对象最外层Wrapper的结构,导致前端调用出现空指针。
接口定义频繁的进行变更,后端在技术方案设计到最终实现的过程中,经常会出现一些内部逻辑或者细节的调整,有可能是出现技术方案上没有考虑到的情况,也有可能是产品需求发生变更。有时是在连调的过程中,有时甚至有的时候是在发布前的CodeReview阶段,不仅存在安全隐患,也导致前端对接的成本随之上升。
交付方式不规范,由于人员的流动等影响,部分业务外包开发缺少在协同过程中的一些规范,经常会有直接把接口信息扔到钉钉聊天中就觉得完成交付,可能是出于觉得编写文档这个过程过于麻烦。
我们希望借助AI的能力,把接口定义到前端代码生成的过程标准化,对于后端,不需要花时间和精力去编写/维护接口文档,对于前端,在获取到接口定义的时候,自动转换成实体模型及相关请求hooks,减少时间去编写重复性的代码。
整体的技术方案思路大致如下:
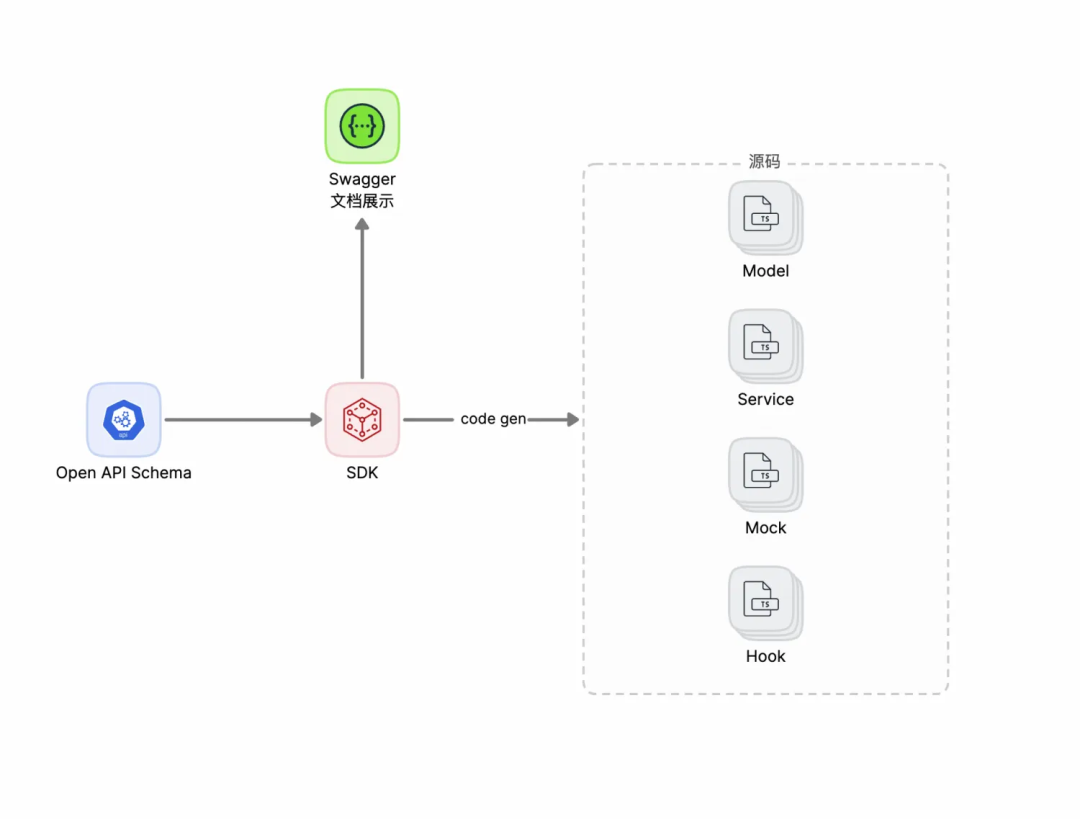
通过不同途径(技术文档/PRD/mock平台)的接口定义的语料输入,经由带CoT的推理模型进行思考解析出标准化的OpenAPI schema协议,作为前后端对接的凭证。
OpenAPI schema 3.0 规范可以参考:https://spec.openapis.org/oas/v3.0.3.html
根据得到的接口OpenAPI schema,生成对应的接口相关前端代码,model,service,hooks等。
如果需要,也可以通过工程化的链路,推送到对应的网关进行接口的注册(Mtop,IDD网关)。
链路框架如下图所示:
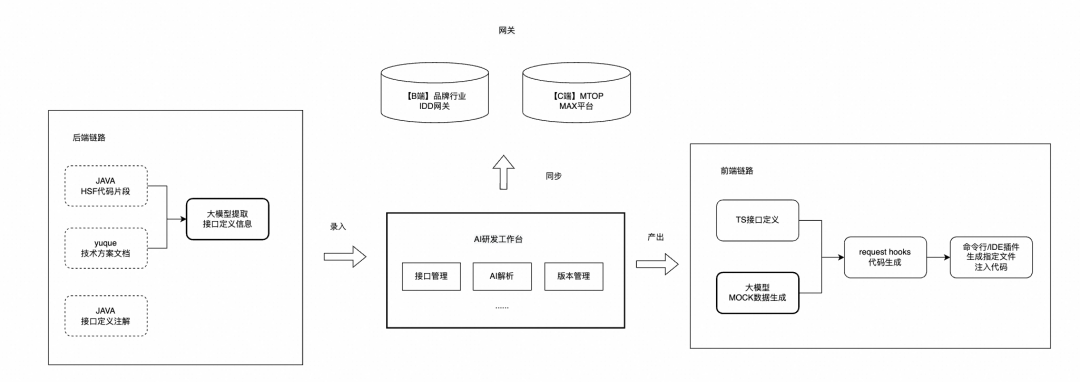
获取OpenAPI 3.0 Schema
将接口定义的转换成Open API Schema的语料有很多种,目前我们常见支持的包括以下几种方式:
1. 通过Java Interface或接口文档获取接口定义
服务端对接前端的接口如果是http的,那么一般是在Spring MVP的Controller层。如果是通过MTOP等网关形式提供的,那么接口的定义一般是在client或者api包下的Facade Service中。
所以只要可以拿到后端应用中的controller或者是interface的代码,那么就可以通过让模型去理解接口的字段定义并转换成OpenAPI schema。
目前我们提供了一个管理页面,服务端开发可以在管理页面上粘贴本次迭代变更相关的接口代码或者是技术文档,只要能包含全量的信息即可,存在部分的冗余也没有关系。(这一步后续也可以集成到git webhooks或者终端的指令上,智能去分析仓库中相关涉及这次变更的代码和实体模型)。
如图是一个二方HSF的Java Interface的源码
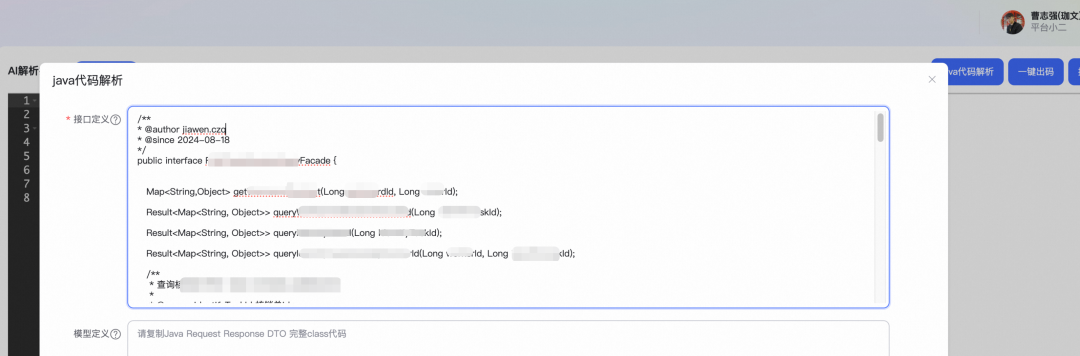
提交后由CoT推理大模型进行分析,提取关键的函数名和签名参数信息


最后以OpenAPI Schema的格式进行输出
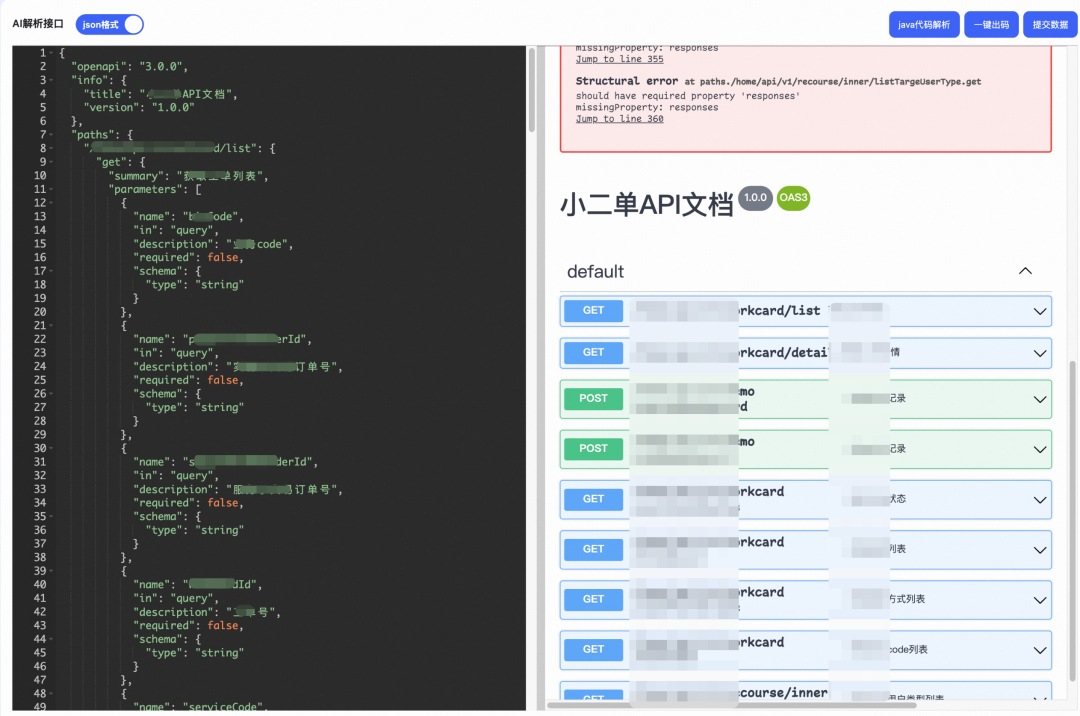
这种方式的普适性比较广,但是准确率相对偏低一点,一方面是目前的大模型无法避免的幻觉问题,另一方式则是部分的手动复制的时候可能会遗漏部分的必要信息,可以在左边的OpenAPI的可视化编辑器内进行二次的修改。
2. 通过Swagger插件获取接口定义
第二种方式是通过安装Swagger插件,在项目中引入springfox-swagger2的依赖,并初始化配置类,具体的接入方式和demo可以参考SpringFox的官方站点介绍:https://springfox.github.io/springfox/
在maven中引入的配置包括:
<!--swagger2--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.8.0</version> </dependency> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.8.0</version> </dependency> <dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>swagger-bootstrap-ui</artifactId> <version>1.9.6</version> </dependency>完成接入后,可以通过在代码中添加注释的就就可以自动生成swagger-ui ,并在本地的web页面中可以直接复制出OpenAPI Schema
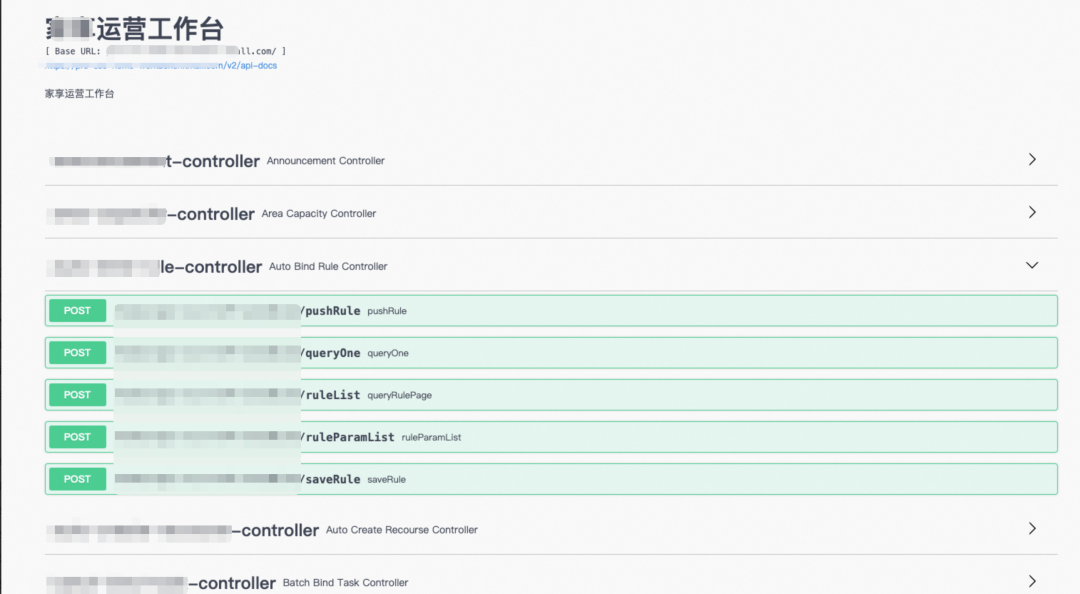
3. 通过网关获取接口定义
第三种方式是通过服务端注册网关,天猫品牌行业这边中后台页面接口有统一的网关服务用于管理:服务注册,稳定性流量的监控,生成http服务等。使用网关的研发流程中,服务端开发可以通过提供的Idea插件或者是手动配置的在网关上完成注册。我们在内部和网关团队合作,打通了服务的网关信息并支持完成OpenAPI Schema的转换。
schema到代码生成注入
在拿到接口的详细OpenAPI schema定义后,就可以自动化的生成数据请求所需要的前端相关代码,主要是以下几部分:
Model:每个接口的Request,Response,DTO都有对应的数据模型的TS定义,类型定义清晰明确,确保代码的健壮性。
Service:封装完整的数据请求服务,包括请求路径,类型,参数,异常处理等。(部分的高级组件内部会集成状态管理,只需要把数据请求服务作为参数传入)。
Hooks:在Service的基础上进一步集成React状态管理,直接用于可以对接Fusion等UI组件
Mock:本地的数据仿真服务,通过faker.js模拟数据,根据环境识别自动切换本地仿真数据请求
除此以外,也可以根据业务的需要注入相关的业务埋点服务,稳定性监控等。具体的模版到代码的生成实现方案可以参考开源社区的优秀工具集,如:Kubb(https://kubb.dev/) 是专为现代 TypeScript 前端工程设计的 OpenAPI 代码生成器,通过解析 OpenAPI 3.x 规范自动生成完整类型安全的 API 客户端代码。
以下是一个业务仓库的实际生成情况:
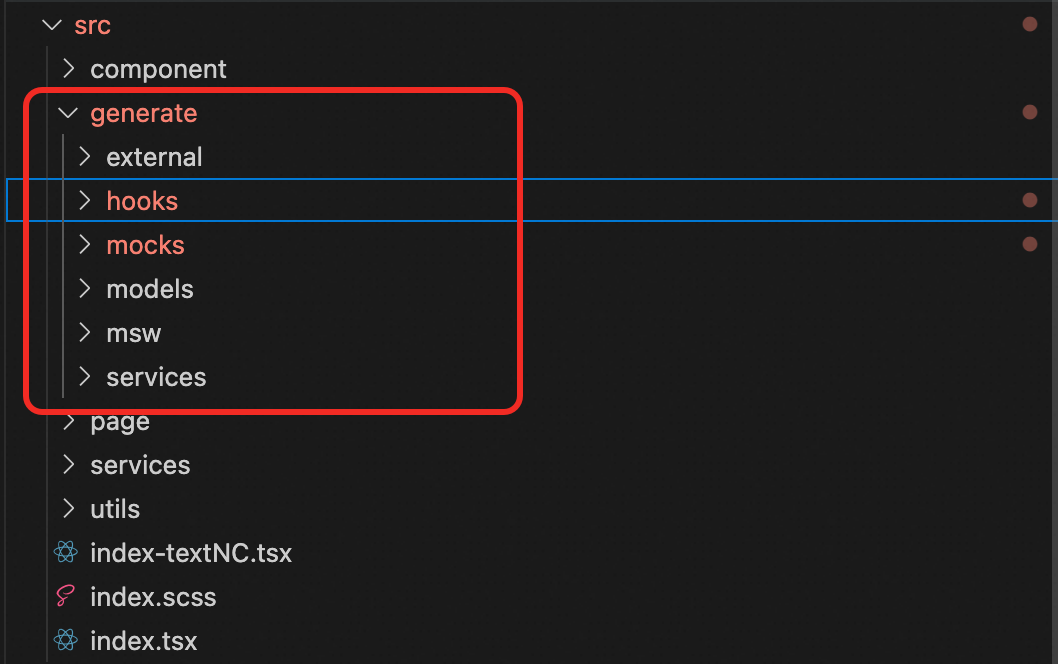
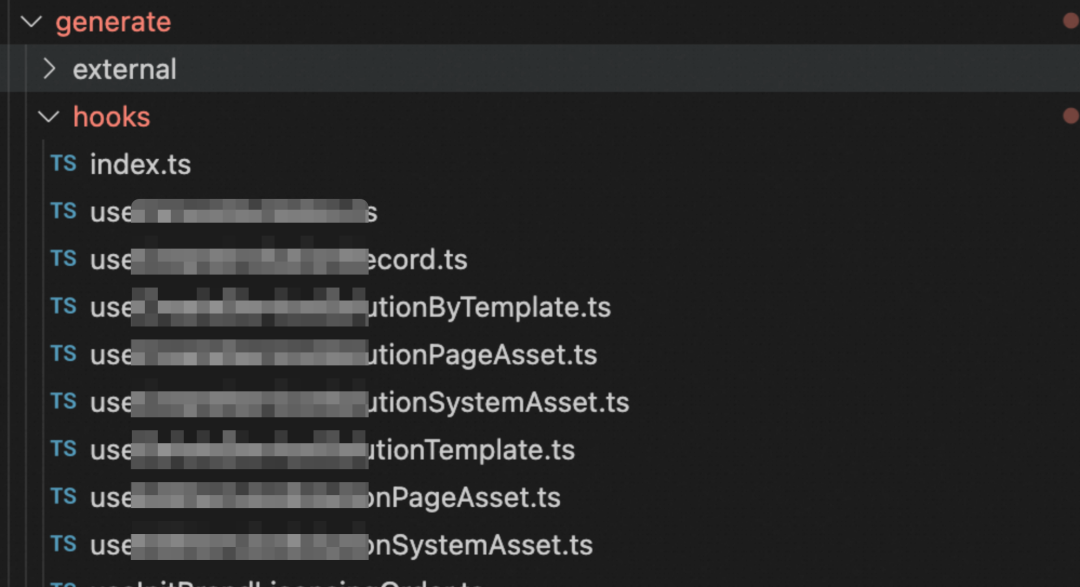
所有的自动化代码都放在generate目录下,一般来说不会推荐修改,因为每次当接口定义发生变化的时候,目录下的内容会重新生成覆盖。
▐ 代码拟合和调整业务代码拟合
以上我们已经获取到了AI生成的UI交互代码和交互数据相关的接口服务,实体模型和react hooks,下一步就是让AI根据仓库下这些的代码素材进行业务逻辑的拟合和拼装。
1. 拟合提示词
prompt的关键提示词:
// 此处省略通用的一些编码要求......你是一个高级前端开发工程师,具有React组件和Hooks的深度开发经验熟练编写和集成自定义 hooks 与组件将用户提供的 React 组件代码与自定义 hooks 整合在一起。偏爱使用${component_lib}组件,如果必要或用户要求,可以使用其他第三方库。
....
## 注意事项确保整合代码的逻辑流畅和一致性理解用户的主要目标,包括如何整合组件和 Hooks,确保整合后的代码符合最佳实践。确保 Hooks 的方法名、引用路径以及类型定义的准确性和一致性。导入 hook, model 的目录路径应该是相对于当前文件的路径,并加上 `generate`。最终组件中使用的数据字段应该是根据请求返回的数据定义来的。
// 此处省略具体的内容规划,结构格式要求和执行路径......配以具体的examples示例,由于具体的examples比较长,这里只截取了其中一部分。
以下是一些正确的答复示例:<examples><example><doc_string>该示例展示如何组合用户输入的React组件,hooks,model 定义来渲染所需的UI</doc_string><user_input> <user-component>import React, { useState } from 'react';
import { Input, Select, Button, Table, Pagination, Box, Grid,} from '@alifd/next';<assistant_response><Thinking>用户输入的组件是一个列表查询组件, hooks是使用结合react-query, 使用post发送一个请求,获得列表查询的结果。 请求的参数是 hook类型定义`RequestConfig` 的泛型参数`ListUsingPostMutationRequest`, 请求返回的结果是 hook 类型定义的 `ReponseConfig`的泛型参数 `ListUsingPostMutationResponse`, 在`user-model`的定义中。 最终渲染的数据使用的是 `PageModelAnomalyRecourseVo`, `Table` 组件中的 `columns` 将使用 `PageModelAnomalyRecourseVo` 中的字段,在导出组件时,使用 `withMockService` 高阶函数包裹组件。我将使用type="react"的tsx代码块来处理这个用例。</Thinking>```tsx project="component" file="index.tsx" render="true" type="react"import React, { useState } from 'react';import { Input, Select, Button, Table, Pagination, Box, Grid } from '@alifd/next';import { useListUsingPost } from './generate/hooks/useListUsingPost';import type { AnomalyRecourseVo } from './generate/models/AnomalyRecourseVo';import { withMockService } from './generate/external';
interface ComponentProps {}
const Component: React.FC<ComponentProps> = () => { const { m const [currentPage, setCurrentPage] = useState(1);utateAsync: fetchList, data, isPending } = useListUsingPost(); const [currentPage, setCurrentPage] = useState(1); const handleSearch = (field: string, value: string) => { setSearchParams({ ...searchParams, [field]: value }); }; //省略代码 。。。。 return ( //省略代码 。。。。 <Table loading={isPending} dataSource={data?.dataSource || []} columns={columns} /> <Box margin={[20, 0]} direction="row" align="center" justify="space-between"> <Pagination total={data?.total || 0} current={currentPage} pageSize={pageSize} onChange={(page) => setCurrentPage(page)} /> </Box> )};
export default withMockService(Component);```</assistant_response>最后是给AI出码的用户输入,这里的输入{component},{hook},{model}等就是前面生成的代码,通过ideaLAB的开放服务作为参数输入给模型进行推理
<doc_string>现在用户的输入如下,请将 React 组件代码与自定义 hooks 整合在一起</doc_string><user_input><user-component>${component}</user-component><user-hooks>${hook}</user-hooks><user-model>${model}</user-model></user_input>2. 拟合总结
整体代码拟合的效果准确率对比前两个阶段,稳定性相对弱一点,当然也分情况:如果是私有化的组件(如团队内部的组件库)由于输入的使用信息更为完善,不容易产生幻觉。外部的组件则相反,由于大量的训练语料都是公域的信息,比如“responseData?.data?.dataSource” 经常会产生一些幻觉。
当然也有对应的解决方案,就是不断的在prompt中去完善规则,或者给一些bad example,整体来说先阶段仍然需要对promp进行一个长期的优化,也是我们在整个项目中最耗时的一个阶段。
目前我们在业务封装的一些高级场景组件中,拟合的稳定性和准确率大约能达到95%的水平(一线开发者仅需要做少量的修改),对于公有组件(Fuson,AntD等)大概是在80%左右的水平。
Code Review
1. 外部产品
用AI进行Code review其实已经是一个比较成熟的操作,在外部也有很多类似的研发工具产品:
比如gitlab极狐公司推出的CodeRider(https://gitlab.cn/resources/articles/ability_tag/28)
Codium AI公司推出的PR-Agent(https://github.com/qodo-ai/pr-agenthttps://www.qodo.ai/)
这类的商业化企业开发服务工具除了code review以外提供从代码管理到CI/CD的完整解决方案
但是以上的这些外部平台存在以下这些问题:
基本都需要外部的账号登录,比如google账号,github账号,同时也涉及到账号的充值付费
大部分产品的工作流都是依附在Github上的,和其他代码平台的兼容性不够好
数据安全性问题无法完成保障
基于以上的问题和我们考虑自己动手设计一个ai codereview agent或者采用集团内部的其他方案。
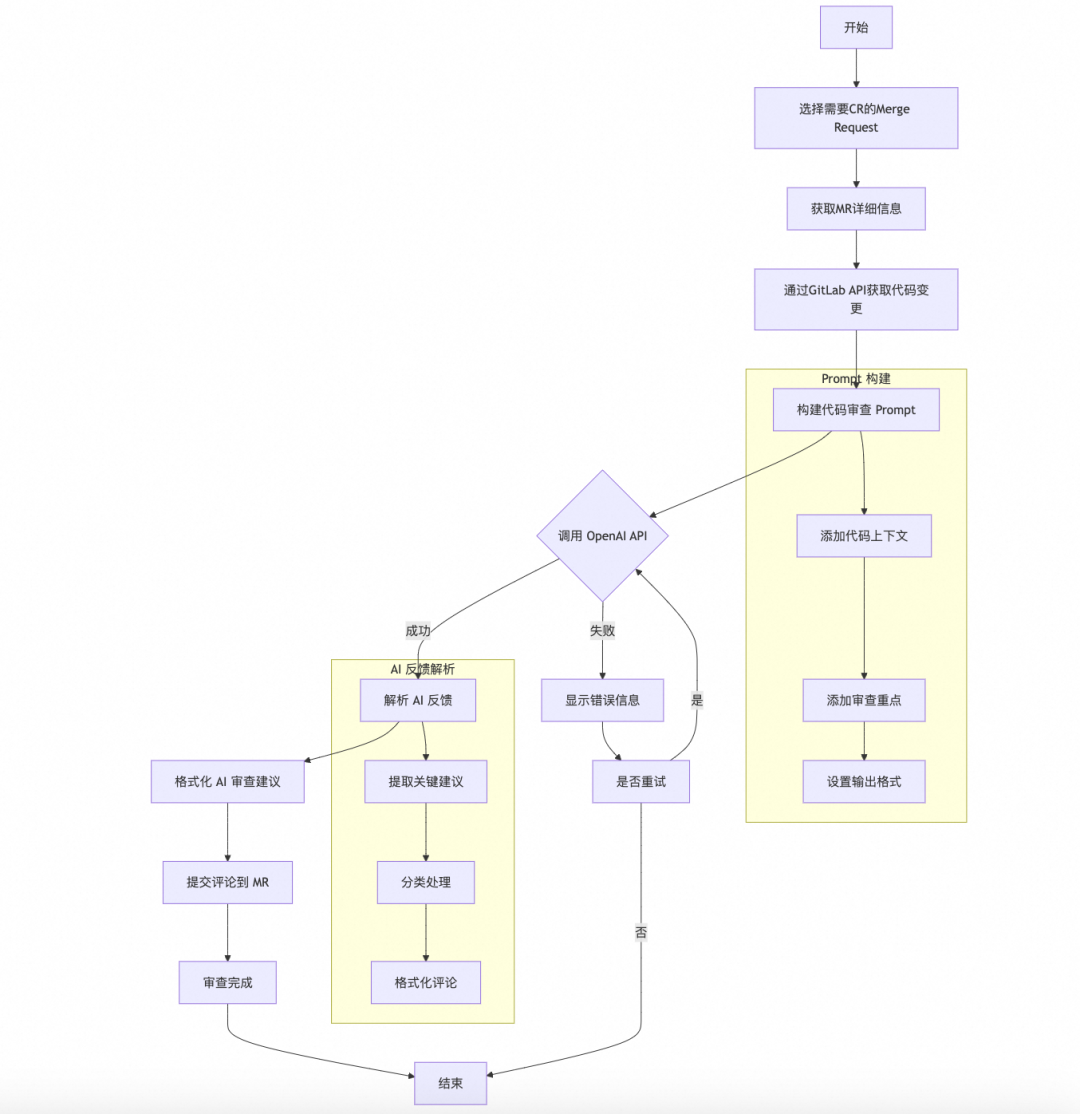
2. codereview AI Agent实现由于大部分的前端场景对于逻辑的处理没有特别的复杂场景,更多是对代码风格,模型在简单的逻辑问题、命名拼写错误等,框架的调用的最佳实践等一些不涉及到文件之间上下文业务逻辑的场景,所以自动动手实现一个AI codereview工具的成本并不高,主要步骤:
1. 在merge request提交的时候触发webhooks
2. 通过code open api获取对应的code changes
3. 通过prompt引导AI对代码进行审查
4. 给出的优化建议以评论形式提交在mr上
具体的实现设计可以参考一下以下流程图:
prompt
<system>你将扮演一名资深软件工程师,对同事的代码进行评审。</system>
针对每个文件,判断是否需要提供反馈。若需要,用1-2句话说明反馈内容。若需修改代码,需注明原始代码并提出修改建议。建议后不要添加其他内容。若无反馈,则不对该文件添加评论。
最后,用1-2句话总结整体反馈。
<example>### filename.jsThe name of this variable is unclear.
Original:```jsconst x = getAllUsers();```
Suggestion:```jsconst allUsers = getAllUsers();```</example>//...省略其他example可以参考的代码规范包括:
https://github.com/microsoft/TypeScript/wiki/Coding-guidelines
https://github.com/airbnb/javascript
以下是一个:
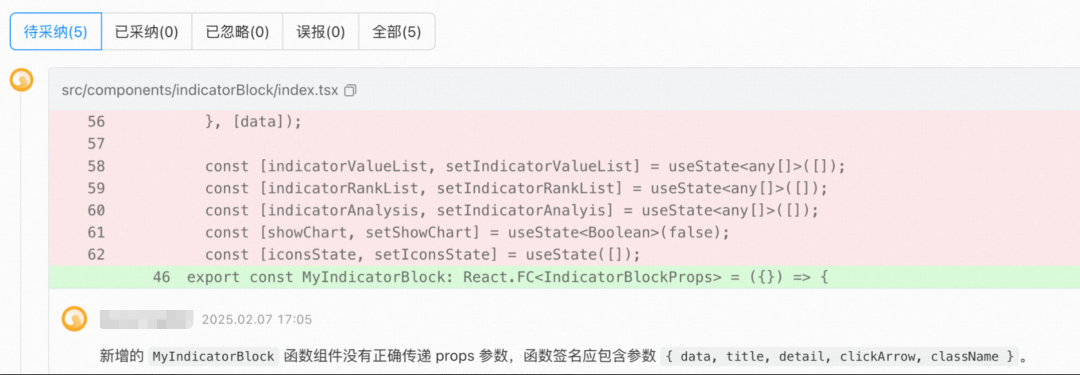
在我们的实际测试使用效果中,AI code review和传统的静态代码扫描缺陷可以形成互补,能更好的发现一些人为的粗心导致的代码实现不够严谨的问题。
但是发现 AI 代码评审存在两大现象:
绝大部分的代码都没有代码缺陷,而这时候大模型总是倾向于编造一些问题来提示我们注意。
由于业务背景、需求文档、技术方案、上下游系统依赖、俗成的约定等信息的缺失,导致人类能判断的代码缺陷而 AI 却找不出来。
3. code平台AI评审助手
除了自己实现以外,目前一些主流的代码托管平台像github也提供了类似的功能,代码托管平台最大的特色在于基于高质量的现有CodeReview数据集对模型进行了微调。
为了在特定领域内提升大模型的表现,微调是很关键的一个步骤,这个步骤依赖于该领域内的高质量数据。相比优质代码数据,CodeReview 的高质量数据更难获取,因为它不仅包含代码数据,还涉及众多的自然语言数据。这些数据通常结构松散,含有二义性,而且缺乏有效的解析工具。其中代码数据多以 unified diff 格式呈现,增加了解析的复杂度。
▐ 自动化测试回归
传统自动化测试模式基于脚本驱动,依赖预定义脚本(Python/Java)需人工维护元素定位器。如:“driver.find_element(By.ID, "submit-btn").click())”,通过DOM结构或控件ID定位元素。一旦UI发生变更可能会导致60%以上的用例失效。基于像素对比(如Applitools)的方案受分辨率/动态内容影响大,另外还要考虑到平均用例的维护成本。
在大模型时代,是否存在面向测试场景的更智能的方案呢?OmniParser V2 (https://github.com/microsoft/OmniParser)是微软推出的下一代视觉解析框架,专为智能UI自动化测试设计。它通过融合 YOLO目标检测 和 Florence-2语义理解模型,实现屏幕元素的精准识别与功能解析。将用户界面的像素空间“分词化”,将其转化为结构化的、可被大语言模型理解的元素。自动标注按钮、输入框等交互控件的位置坐标(±1px精度)和语义描述(支持中英文),并集成 GPT-4o 等大模型生成自动化脚本。
这个产品之前更多被用户数据爬虫的场景,实际可以发挥的场景远不止这个领域,由于是通过视觉模拟的方案,打通了人机的交互形式。理论上可以做一切对电脑进行操作的场景。
基于这样的能力来设计一条自动化测试回归的流程,大致分为如下这个部分:
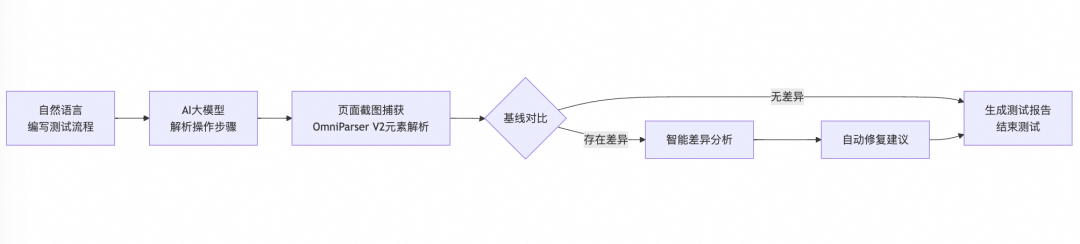
举一个具体的例子,以clone一个github的某个仓库为例:
通过自然语言描述需求(目前一些比较先进的reasoning模型也可以自己来拆解步骤):
打开Chrome浏览器
在地址栏输入github.com跳转到github
在搜索栏搜索XXX项目
跳转到XXX项目后点击code->clone仓库到本地
由于每一步基本都是类似的循环,这里只取其中一步来介绍一下具体的流程:在打开页面后通过OmniParser V2获取完整的页面结构化信息(红框里面的部分),包含了每个元素的类型,是按键,文本还是icon。和具体的坐标信息。
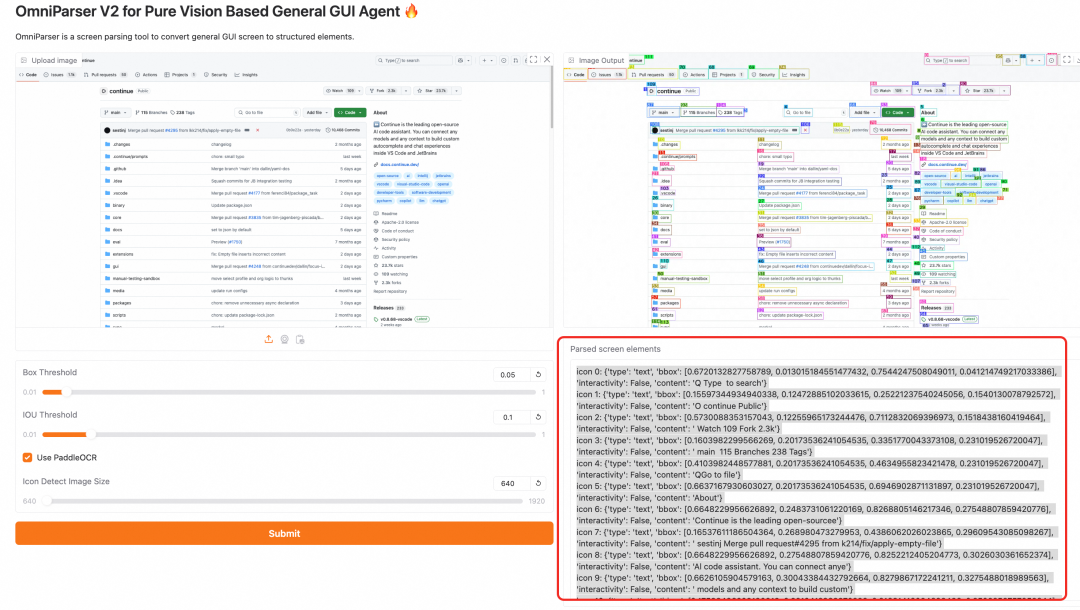
把这个页面的所有信息作为下一步的输入,并且告诉大模型下一步要做什么。

大模型是会根据页面信息,给出可能的操作步骤和推荐的建议。
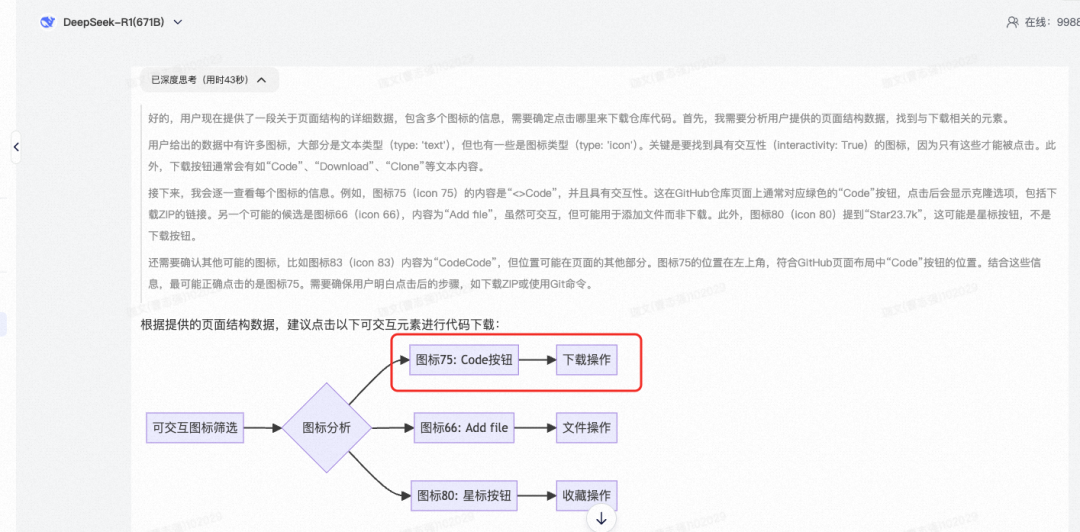
最后大模型还会输出具体的操作代码:
定位目标元素:
# 筛选可交互且包含"Code"关键字的图标target_icons = [icon for icon in icons if icon['interactivity'] and 'code' in icon['content'].lower()]坐标转换(以图标75为例):
# 获取屏幕分辨率(示例为1920x1080)screen_width, screen_height = 1920, 1080bbox = icon75['bbox'] # [x1, y1, x2, y2]
# 计算点击中心坐标center_x = (bbox[0] + bbox[2])/2 * screen_widthcenter_y = (bbox[1] + bbox[3])/2 * screen_height执行点击:
import pyautoguipyautogui.click(center_x, center_y) # 点击代码按钮pyautogui.click(center_x, center_y + 80) # 选择"Download ZIP"选项以上就是每一步的一个循环,当页面结构发生变化的时候,再次通过OmniParser V2分析新的页面结构和元素,再进行推理,这个过程和真实的人类去操作和理解页面的变化是类似的。有没有汽车自动驾驶领域现在很火热的 “端到端”技术架构的感觉?
除了OmniParser+pyautogui以外,类似的方案还有 browser-use(https://github.com/browser-use/browser-use),从视觉模型的理解和结构化能力来说,OmniParser在发布V2版本以后已经领先于同类型的产品。另外背后有mircosoft站台,未来前景也更加优秀。
我们在自动化测试回归领域还仅限于流程和理论上的探索验证,主要是OmniParser目前几乎不支持中文的识别,但是相信不久的将来,未来的自动化测试模式也会随着AI模型能力的提升更大幅度的提升效率。
▐ 产品化工具
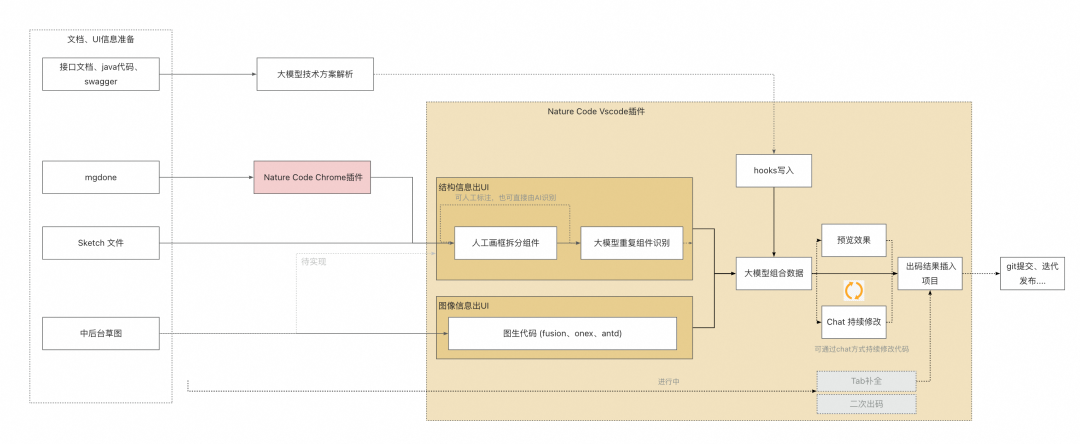
在品牌行业前端内部,我们把上述的能力统一沉淀在了我们自己研发的一个VS Code插件上。根据我们的业务场景进行了深度的定制,包括支持C端通过mgdone的图层结构解析生成代码,和B端不同私有组件库的模式。同时也集成了接口/数据模型的代码生成,并支持一键进行代码拟合。
在出码之后也支持类似Copilot/Cline/Continue等插件的chat模式,在能力上进行了定制和增强,包括根据已经出码的上下文,持续进行代码优化和调整,使用体验比起Cline更加稳定可控。
整体的工作流程图:
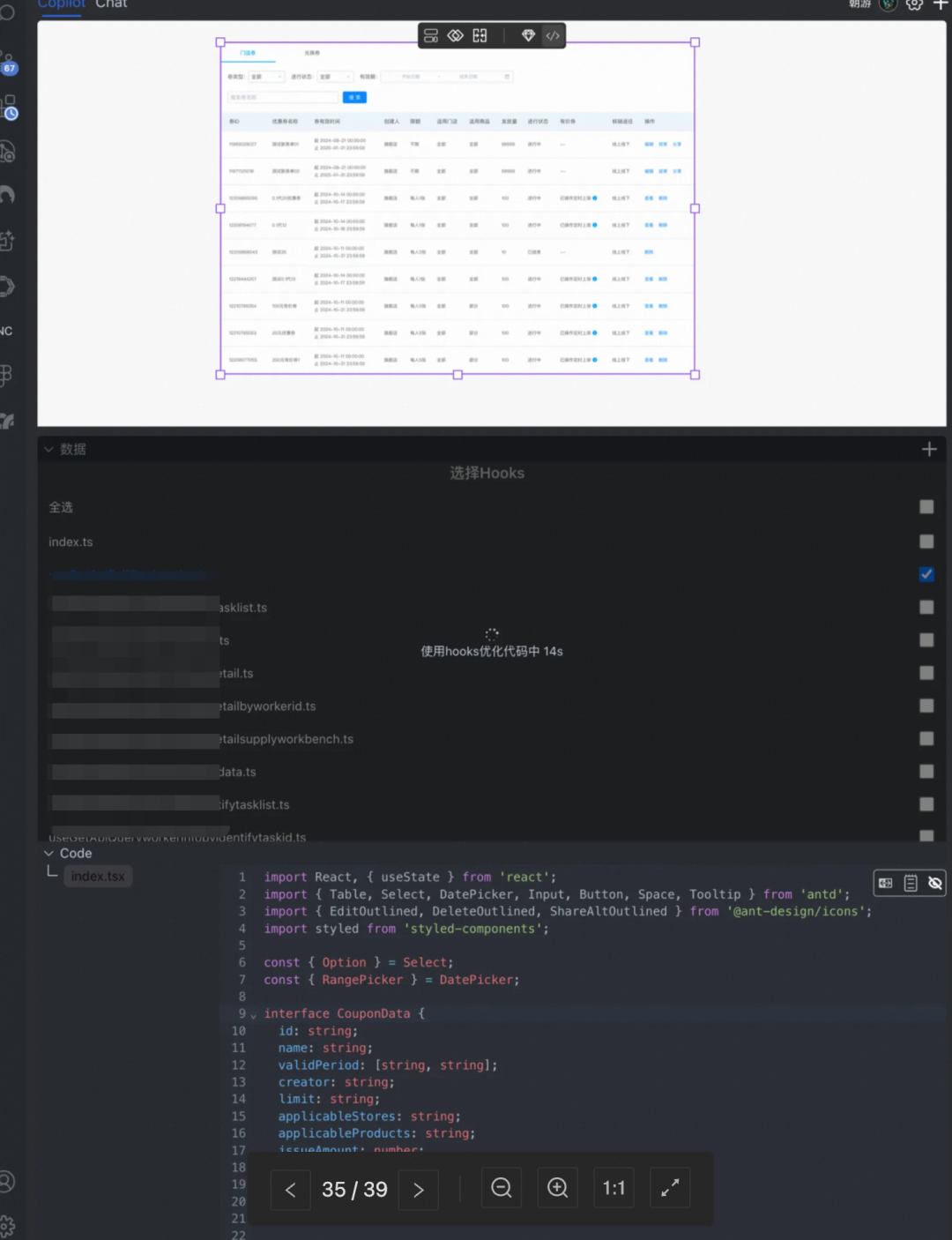
用户使用流程:

一些总结和未来展望
在1月份的下旬开始,我们在品牌行业家享服务和物流的中后台场景全量开始推广使用新的研发模式:在新增的页面开发需求场景中,中后台场景下D2C带来UI编写的效率提升40%,联调效率提升30%,AI代码的采纳率B端场景约在 40%,AI代码覆盖率75%以上。
▐ 大模型技术能力的迭代
上层产品能力的演进最大的驱动力还是基础模型技术的迭代升级
前端AI驱动编码对于大模型的基础能力主要依赖包括:
多模态识别:对交互/视觉设计稿的识别,能正确进行组件的模态识别,尤其是对于弹窗等特殊浮层能理解交互设计的含义。
上下文理解力:在配合代码仓库索引的情况下,对代码上下文有足够的理解力,能读懂代码,在变更的时候准备的进行修改,
推理效率:在进行代码推理生成的响应速度要足够快(目前Cursor采用的仍是定制小参数模型的方案来确保响应速度)。
成本:每次代码生成/修改都会消耗大量的token,如果每次任务执行产生的费用过高,在实际的日常应用中也很难普及。
换句话说,大模型在这4个维度的能力越强,AI编码的效果就会越好。目前随着qwen2.5VL,Deepseek R1等优秀的国产大模型崛起,在模型的上有了越来越多可选项,但是能够在这几个方向上做到都十分优秀的还是寥寥无几,所以尽管现阶段AI的能上进步迅猛,但仍旧是辅助流程的工具,还是需要人来做主导。
▐ AI友好架构设计
将来越来越多的代码会是由AI来编写,在技术架构设计和代码实现的时候,需要越来越多考虑到AI的理解成本。
以前端的业务组件为例:
明确的数据流与接口规范:确保组件状态管理路径清晰,降低AI理解逻辑的复杂度。组件间通信需通过标准化props/events接口,避免隐式依赖。AI 代理在处理代码时,如果能够借助强类型信息理解数据的结构和约束,就能更精准地实现功能,而不需要依赖隐式规则推导。
基于"单一职责原则"构建组件层级:基础UI组件保持功能原子化(如按钮、输入框),业务组件通过组合基础组件实现功能。这种分层结构便于AI识别组件复用场景,做到“代码即文档”
低耦合高内聚实现:采用容器-展示组件模式分离业务逻辑与视图层。组件应具备完整的自描述元数据(如PropTypes),方便AI解析功能边界。组件内部的过度会复用导入导出会增加代码的耦合性,使 AI 更难理解依赖关系。
▐ 未来应用层的发展方向
在面向未来的AI的应用层面,一定是对于整个流程链路的重构,比如:原来有 5 个步骤,目前现在我们做的都是在每个步骤上进行提效,仍处于在单点节点上的优化,而把 5 个步骤通过 AI 提效砍掉 2 个,并且形成新的产品形态或研发范式,才是真正通过AI的能力去解放生产力。
未来的产品研发形态随着模型能力的提升 研发流程过程中真正需要编码的过程会越来少,那么是否还需要把代码Clone到本地,是否需要本地的编译器?
我认为面向不久的未来对于部分的产品需求可能会只需要使用云端工具,面向PRD/MRD/业务需求,通过构建一套由多个专业智能体(Agent)组成的研发助手网络,覆盖从需求分析到代码生成、质量保障的全流程。智能体网络将实现自主决策和协作调用,各智能体根据需求上下文和开发阶段,主动调用相关工具并协同完成代码生产。
AI Agent:接受需求 ==> 编辑代码 ==> 运行效果 ==> 修改&review ==> 提交代码 ==> 完成发布,其实Cursor/Cline等辅助工具目前通过MCP协议,已经在在理论上已经等完成上述的流程。
但我不认为未来会减少对于高级研发的岗位的需求,未来的软件研发的需求会持续膨胀,数字化和数智化会更快更广的普惠到各行各业。

团队介绍
本文作者 珈文,来自淘天集团的天猫品牌行业前端团队。我们团队负责消费电子、3C数码、运动、家装、汽车、奢品、服务等多个行业的项目。我们定位自身不局限于“传统”的前端团队,在AI、3D、工程化、中后台等领域,我们有着持续的探索和实践。
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









