








春晚互动的新期待
从前端视角出发,深度解析2025年春节主互动的技术实现,揭秘春晚互动背后复杂的前端方案如何应对高并发与跨端协同的技术挑战,并通过万字长文全面解读春节主互动前端技术的演进与升级。
▐ 背景
时隔五年,我们再次成为央视春晚电商互动的独家合作伙伴。今年手淘主互动页面以“许愿”为核心,新增了“接福禄”、“打年兽”多样化的互动、游戏内容,用户在感受到浓浓春节氛围的同时,又收获轻松愉快的游戏体验。
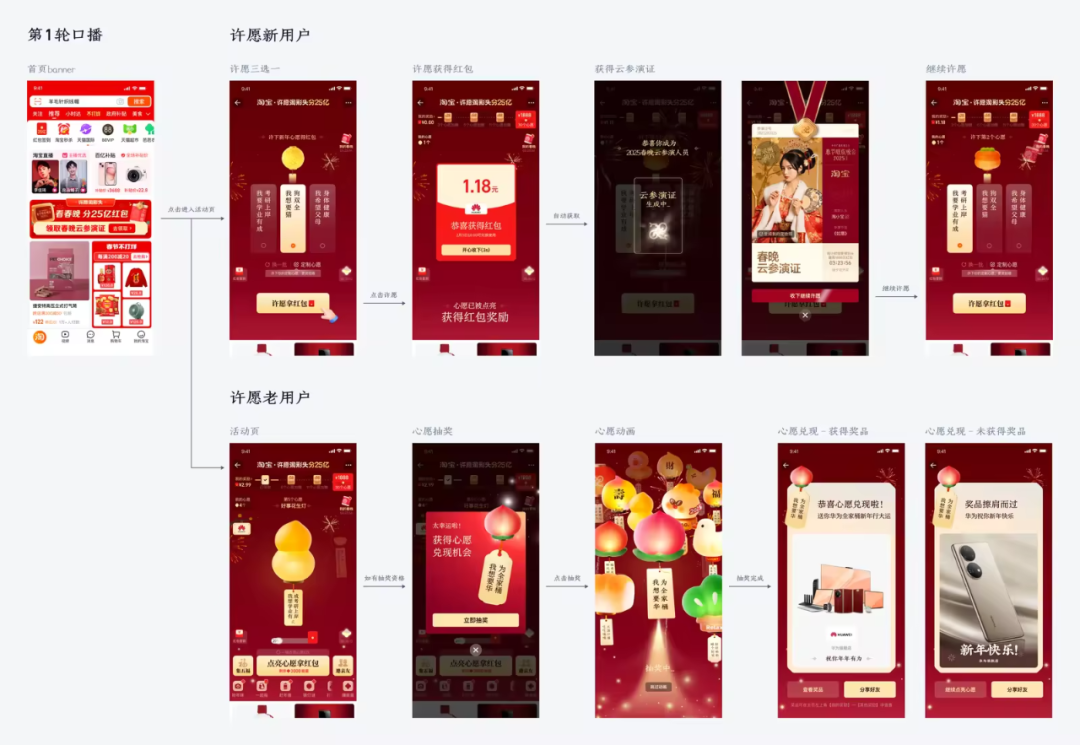
主互动

小游戏
随着春晚主玩法的升级,我们引入了更多渲染场景。然而,高帧率和高清晰度的要求也给我们带来了不小的挑战。那么,如何在有限的时间内既确保顺利上线,又提供流畅的用户体验呢?答案是:提升渲染性能至关重要。
▐ 为什么“丝滑”和“高刷”如此重要?
想象一下,你正在抢春晚的互动红包,屏幕上的红包雨飞快落下,可画面却卡得像老式幻灯片,一点就跳不动,最后眼睁睁看着机会溜走——这得多糟心!再比如,你想跟着AR特效一起跳舞,可动画一顿一顿,像机器人卡壳,哪还有沉浸感可言?对用户来说,“丝滑”意味着操作顺畅、不掉链子,红包抢得爽快,特效玩得尽兴;而“高刷”就像把电视从30帧升级到120帧,画面细腻得仿佛能摸到,连手指滑动都感觉轻快无比。尤其在春晚这种亿万人同时在线的场景,谁不想要一个不卡顿、不模糊的体验?“丝滑”和“高刷”,早已不是锦上添花,而是让每个人都能真正“玩起来”的关键。
“就像从老式电视升级到4K智能屏,画面从模糊卡顿变成清晰流畅,用户体验简直是天壤之别。”
▐ 技术目标
提供更丝滑流畅的交互体验,针对高端机型,支持120帧的刷新率,同时确保不超过用户设备的性能承载。通过提升20%渲染效率和流畅度,减少卡顿与发热问题,进一步优化整体用户体验。

技术核心:升级到Eva.js 2.0与WebGL 2
▐ 什么是Eva.js 2.0?
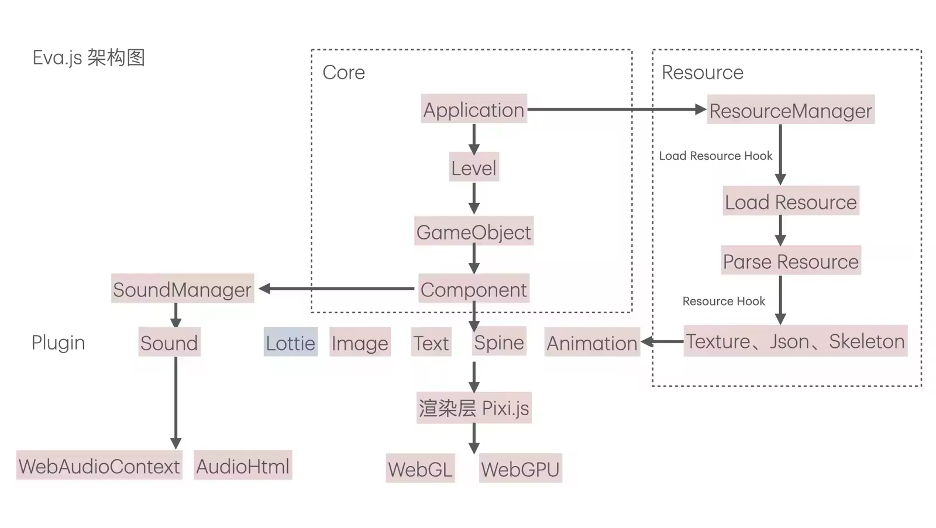
这个是Eva.js的框架设计图,它主要分为三层:核心层(包括Application初始化、关卡管理、Ticker循环控制、GameObject管理等功能)、Resource层(负责素材加载和解析),以及以插件形式集成的渲染能力。
我们对Eva.js进行了全面升级:
1.底层渲染引擎从 Pixi.js v4 直接升级至 Pixi.js v8。
2.优化渲染次序,提高渲染效率。
3.拓展插件能力升级,包括声音插件、Spine 插件、素材管理等功能优化。
4.合并Ticker,降低CPU占用。
Eva.js 2.0相对于v1整个渲染层改动还是挺大的,但是尽可能保证了API的不改动,最大程度的减少升级成本。
▐ WebGL 2的优势
我们日常使用的 Pixi.js v4.8.9 版本并不支持 WebGL2,而当前市场上的移动设备中,高达 97% 的机型已支持 WebGL2。这意味着,我们在技术升级后可以充分利用 WebGL2 带来的性能优化,如更高效的渲染管线、更低的 CPU 开销以及更丰富的视觉效果,从而显著提升互动体验和运行效率。这也是我们从 Pixi.js v4 升级至 Pixi.js v8 的重要原因之一,使技术栈更契合当前硬件发展趋势,为更复杂、更高质量的渲染需求提供更强大的支持。
WebGL2 | 97.05% |
WebGL | 2.93% |
Canvas2D | 0.02% |
再来看下WebGL2和WebGL的对比
特性 | WebGL 1.0 | WebGL 2.0 |
GLSL 版本 | GLSL ES 1.00 | GLSL ES 3.00 |
多重渲染目标 (MRT) | ❌ | ✅ |
多重采样 (MSAA) | 仅 Framebuffer | 纹理也支持 |
3D 纹理 & 2D 数组纹理 | ❌ | ✅ |
Transform Feedback | ❌ | ✅ |
Uniform Buffer Object (UBO) | ❌ | ✅ |
顶点数组对象 (VAO) | 需要扩展 | 内置支持 |
更好的帧缓冲控制 | 部分支持 | ✅ |
支持 OpenGL ES 3.0 功能 | ❌ | ✅ |
借助 WebGL2,我们可以利用更高级的着色器功能、更高效的缓冲区管理以及多目标渲染等特性,使渲染流程更加流畅,提升整体视觉效果和交互体验。这对于需要高性能图形计算的 Web 应用而言,无疑是一次重要的技术飞跃。
▐ 性能提升
通过对Eva.js进行了全面升级,底层渲染引擎从Pixi.js v4升级至Pixi.js v8,带来了显著的性能提升:
框架版本 | 滑动时最低FPS | 平均FPS | CPU占用 |
Eva.js v1 + Pixi.js v4 | 15 | 35 | 17.8% |
Eva.js v2 + Pixi.js v8 | 20 | 50 | 9% |
▐ 低成本迁移Eva.js 2.0
为了降低项目开发中的风险,必须尽可能确保 Eva.js 2.0 的无损降级,以保障顺利交付。为实现这一目标,需要做到以下两点:
1.兼容旧版本,确保平稳过渡;
2.通过 CDN 加载实现无感切换,提升用户体验。

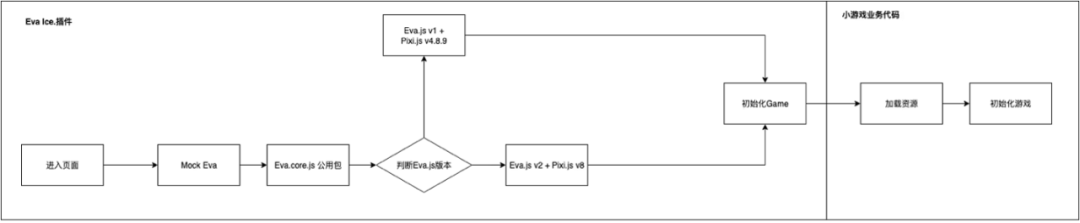
在Eva.js版本判断和CDN加载逻辑方面,我们通过插件层进行处理,确保游戏初始化流程的顺畅衔接。业务开发同学只需专注于业务逻辑,无需关心Eva.js的打包优化、加载方式或初始化细节,从而实现真正的无感知切换。此外,Eva.js的API在新旧版本间保持一致,开发环节不受影响,进一步降低了版本升级或降级的适配成本。这种设计不仅提高了开发效率,也保证了项目的稳定性,使业务方能够更专注于互动内容,而不必担心底层引擎的技术变动。
针对V1和V2中没有变化的Core层,我将其单独提取为EVA.core.js,以便业务代码仓库中自定义System或Component的继承使用。其他插件、资源加载器以及渲染引擎Pixi.js都采用异步加载。在代码加载完成后,将调用初始化游戏区的方法,开始游戏区的初始化操作。整个异步加载过程支持降级处理,确保在不同环境下都能平稳运行。

小游戏技术方案: 用户点赞的背后
▐ 小游戏开发提效
为了让游戏开发变得更加高效,保障春节游戏顺利上线,我们在开发伊始就进行了多个模块的抽象设计。

在通用层中,封装了音效管理,关卡管理(配置关卡/自动生成关卡),游戏配置管理(调节难度),游戏资源管理(资源预取、按需加载),弹窗队列管理
小游戏生命周期抽象。包括:游戏初始化 → 资源获取 → 教学引导 → 游戏开始 → 游戏暂停/恢复 → 游戏结束 → 结算发奖。
通用业务层,封装了通用的UI层/通用功能,包含接口、结算态、错误态、数据处理、积分态、教学态、引导态。
在完成上面的设计工作后,各业务开发同学只需专注于游戏本身功能的实现,而通用部分则可以通过调用公用API,快速实现大部分核心能力。本次沉淀的这些通用层能力,在未来的游戏开发中也将具有很高的复用价值。
▐ 伪3D场景
框架这层已顺利完成,接下来就是如何将业务需求落地。今年的主互动玩法相比往年有了很大变化,技术细节上也面临不少挑战,尤其是大量伪 3D 场景的引入,给实现带来了新的难题。
接下来,我将逐步揭秘这些伪 3D 场景的技术方案,包括如何通过 2D 渲染模拟 3D 效果、如何优化性能以适配大规模用户互动场景,以及如何确保不同设备上的一致性表现。让我们一起来看看,如何用技术打造更具沉浸感的互动体验!
灯笼飘条
在本次项目中,灯笼动画是通过 Spine 实现的,而其中的飘条动画则依靠 Spine 的伪 3D特性来完成。同时,Spine 也提供了 插槽(Slot) 功能,可以用于替换骨骼上的素材。
然而,Spine 与 Lottie 不同——Spine 插槽只能替换图片(纹理),不支持直接插入动态文本。这就带来了一个核心问题:如何在 Spine 动画中插入可修改的文字,并且让它精准贴合动画效果?
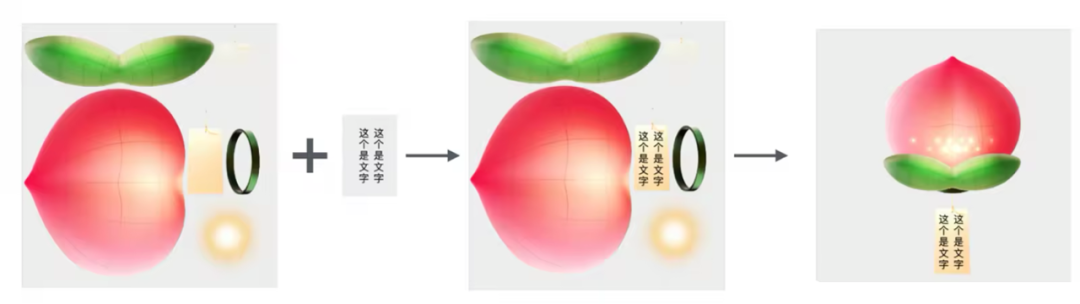
比较可行的方案是,在骨骼中获取飘条的世界坐标,然后将文字贴附到对应的飘条上。然而,这种方法存在一个问题:文字与灯笼的Spine动画是分离的,导致文字显得生硬,无法与飘条融为一体。此外,灯笼的Spine动画还包含飞行动效,管理文字的定位也会增加额外的复杂逻辑。
最佳方案是直接将文字绘制到图片纹理上。上图展示了Spine素材的雪碧图,通过Spine的atlas文件,我们可以定位Spine图集中的飘条位置,并在其上绘制文字,从而生成一张带有心愿文案的Spine贴图。这样一来,生成Spine时,文字就能与飘条自然融合,不会出现破绽,同时文字也能随着飘条一起呈现3D翻转效果。
优化素材加载流程
Eva.js v1.0 版本中提供了用于处理素材的 Hook,但存在一个问题:素材加载完成时触发的 Hook 运行时机不正确,此时的素材尚未被解析。
比如,在加载 Spine 的 atlas 文件时,Hook 返回的仍然是图集的字符串描述文件,这对后续处理并不友好。因此,在 v2 版本中,我调整了 Hook 的触发时机,确保素材在解析后再进行处理,从而提高了使用的便捷性。

将加载完成后的 Hook 修改为在素材解析后触发后,获取到的 atlas 文件便是可直接处理的格式,提高了处理效率和便利性。
3D卡片翻牌
Shader方案
在社区 Cocos 中,已经有基于 Shader 的 2D 实现方案用于模拟 3D 翻牌效果。通过AI 工具,将 Cocos Effects 转换为标准的 GLSL Shader,并成功实现了 3D 旋转效果,大大提升了开发效率。
CCEffect %{ in vec3 a_position; in vec2 a_texCoord; out vec3 p; out vec2 o; float Pi = 3.14159; vec4 vert () { vec4 pos = vec4(a_position, 1); vec2 uv0 = a_texCoord; // #if SAMPLE_FROM_RT // CC_HANDLE_RT_SAMPLE_FLIP(uv0); // #endif float sin_b = sin(y_rot / 180.0 * Pi); float cos_b = cos(y_rot / 180.0 * Pi); float sin_c = sin(x_rot / 180.0 * Pi); float cos_c = cos(x_rot / 180.0 * Pi); mat3 inv_rot_mat; inv_rot_mat[0][0] = cos_b; inv_rot_mat[0][1] = 0.0; inv_rot_mat[0][2] = -sin_b; inv_rot_mat[1][0] = sin_b * sin_c; inv_rot_mat[1][1] = cos_c; inv_rot_mat[1][2] = cos_b * sin_c; inv_rot_mat[2][0] = sin_b * cos_c; inv_rot_mat[2][1] = -sin_c; inv_rot_mat[2][2] = cos_b * cos_c; vec2 uv1 = uv0; #if SAMPLE_FROM_RT uv1 = vec2(uv0.x, 1.0 - uv0.y); #endif float t = tan(fov / 360.0 * Pi); p = inv_rot_mat * vec3((uv1 - 0.5), 0.5 / t); float v = (0.5 / t) + 0.5; p.xy *= v * inv_rot_mat[2].z; o = v * inv_rot_mat[2].xy; pos.x += (uv1.x - 0.5) / (1.0 / textureSize.x) * t * (1.0 - inset); #if SAMPLE_FROM_RT pos.y += (uv1.y - 0.5) / (1.0 / textureSize.y) * t * (1.0 - inset); #else pos.y -= (uv1.y - 0.5) / (1.0 / textureSize.y) * t * (1.0 - inset); #endif return cc_matViewProj * pos; }}%CCProgram perspective-fs %{ precision highp float; #include <builtin/internal/embedded-alpha> #include <builtin/uniforms/cc-global> #if SAMPLE_FROM_RT #include <common/common-define> #endif #if USE_TEXTURE #pragma builtin(local) layout(set = 2, binding = 12) uniform sampler2D cc_spriteTexture; #endif in vec3 p; in vec2 o; vec4 frag () { #if CULL_BACK if (p.z <= 0.0) discard; #endifconst vertex = `uniform float iRotation;const float Pi = 3.14159;void main() { mat3 mvp = uProjectionMatrix * uWorldTransformMatrix * uTransformMatrix; float fov = 27.7; float y_rot = iRotation; float x_rot = 0.0; float inset = 0.0; vec2 textureSize = vec2(100.0, 100.0); // 位置和UV计算 vec4 pos = vec4(aPosition, 0.0, 1.0); vec2 uv1 = aUV; // 三角函数计算 float sin_b = sin(y_rot / 180.0 * Pi); float cos_b = cos(y_rot / 180.0 * Pi); float sin_c = sin(x_rot / 180.0 * Pi); float cos_c = cos(x_rot / 180.0 * Pi); // 旋转矩阵构建 mat3 inv_rot_mat = mat3( cos_b, 0.0, -sin_b, sin_b * sin_c, cos_c, cos_b * sin_c, sin_b * cos_c, -sin_c, cos_b * cos_c ); // 透视计算 float t = tan(fov / 360.0 * Pi); p = inv_rot_mat * vec3(uv1 - 0.5, 0.5 / t); float v = (0.5 / t) + 0.5; p.xy *= v * inv_rot_mat[2].z; o = v * inv_rot_mat[2].xy; // 位置偏移计算 pos.x += (uv1.x - 0.5) * textureSize.x * t * (1.0 - inset); pos.y -= (uv1.y - 0.5) * textureSize.y * t * (1.0 - inset); // 最终位置计算 gl_Position = vec4(mvp * vec3(pos.xy, 1.0), 1.0); vUV = aUV;}`; const fragment = ` precision highp float;// Uniformsuniform sampler2D uTexture;uniform int iFlip;// Varyingsvarying vec3 p;varying vec2 o;void main() { vec2 uv = (p.xy / p.z).xy - o; vec2 uv2 = uv + 0.5; if (iFlip != 0) { uv2.x = 1.0 - uv2.x; } vec4 col = texture2D(uTexture, uv2); col.a *= step(max(abs(uv.x), abs(uv.y)), 0.5); gl_FragColor = col;}`;我修改了 iRotation 的实现。iRotation 作为传入 Shader 的数据,可以通过 JS 脚本动态调整,从而实现图片的水平翻转。
其原理是利用矩阵透视算法计算图片的 3D 投影点位,并据此进行渲染。然而,在功能开发完成后,我发现该方案在性能上存在问题。经过性能分析后,我发现每次绘制牌时都会触发 Shader 上下文的切换,导致渲染效率较低。由于每张牌的渲染都需要进行一次 Shader 切换,最终导致 drawCall 次数急剧增加,影响了整体性能。
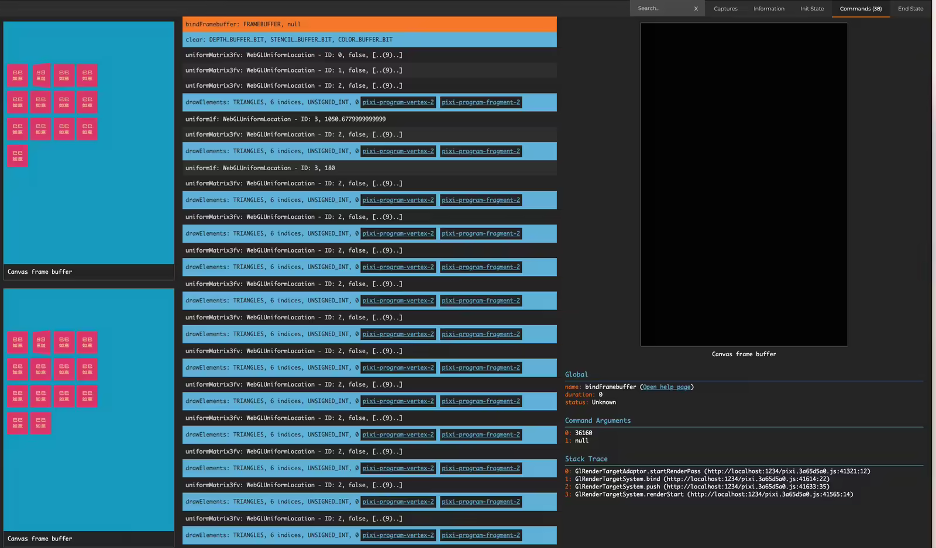
这个方案虽然实现了基本功能,但在性能方面不够完美。在我们追求极致性能和体验的场景中,仍需探索更优的解决方案。
Mesh形变
由于 CPU 和 GPU 之间的交互是异步的,并且 GPU 更擅长批量处理数据,因此更优的方案是:在 CPU 端预先计算好每张卡片经过 3D 透视转换后的关键点位(如 A、B、C、D),然后将这些点一次性传递给 GPU,GPU 直接完成所有卡片的批量渲染。
如下图所示,我们只需在 CPU 端计算出 A、B、C、D 四个顶点在 3D 透视变换后的坐标,并将其传递给 GPU,Shader 便可以高效地渲染出 3D 透视效果,从而避免频繁的 Shader 切换,降低 drawCall,提升整体渲染性能。
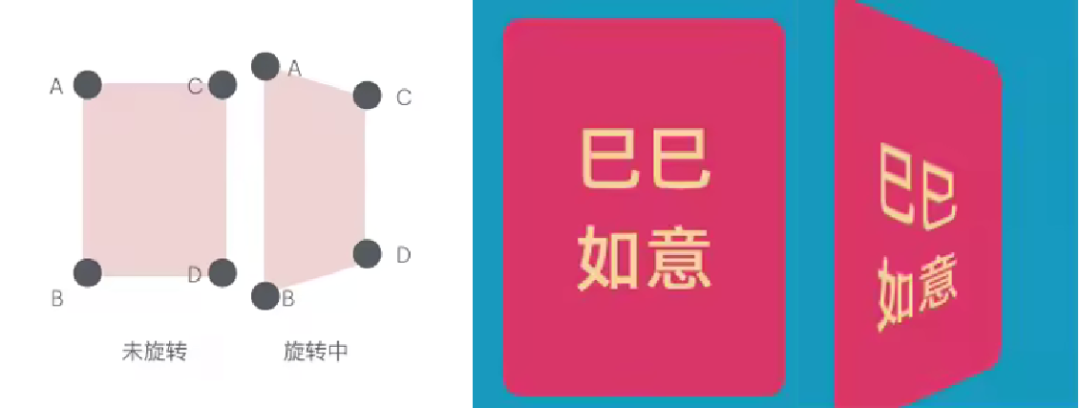
此时,我们已经能够获得外边框呈现 3D 效果的图片,但图片内部的内容却出现了扭曲和错乱。要解决这个问题,我们需要分析内部扭曲的原因。
主要问题在于,图 1 内部的点在经过 3D 透视变换后投影到图 2 的位置时,精度不足,导致像素映射不准确,使得图片看起来错乱。
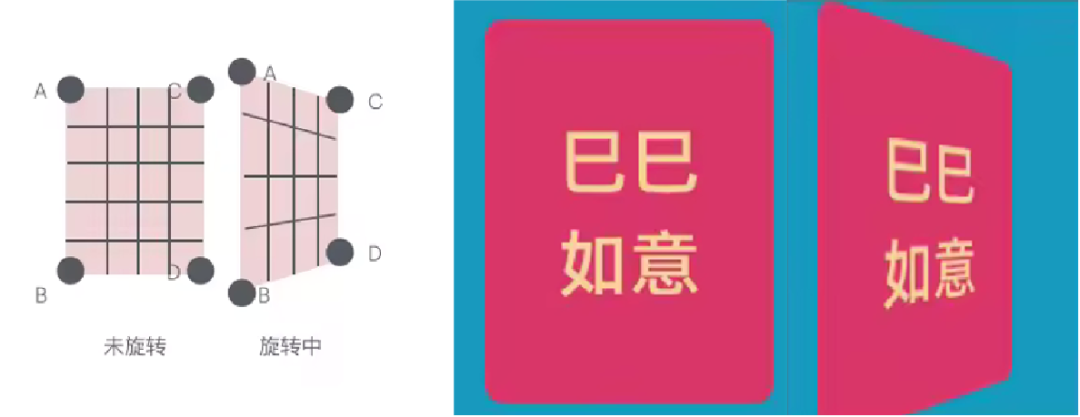
为了解决图片内部的扭曲问题,我们可以在原始图片的基础上增加一个网格,将整个图片划分为多个小区域。然后,对网格中的每个顶点进行 3D 透视变换计算,并映射到最终投影位置。这样,整个图片的透视效果会更加精准,避免扭曲错乱。
关键点:
网格数量的影响:网格划分得越细,3D 透视的效果越精细、平滑,但计算量也会增加,可能影响 CPU 端的性能。
平衡性能与效果:合理选择网格密度,确保 3D 视觉效果的同时,减少不必要的计算开销。
再来分析一下 drawCall
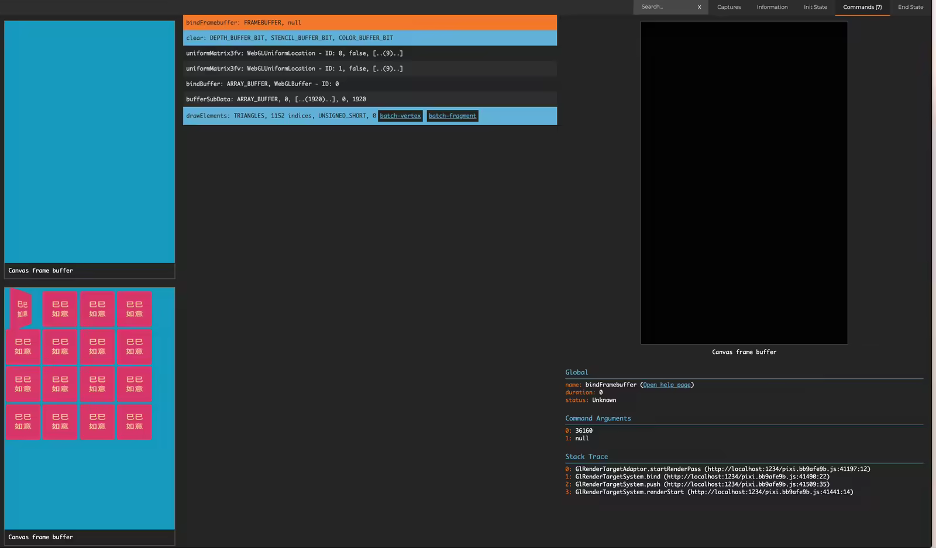
通过在 CPU 端预计算网格顶点的 3D 透视坐标,并将所有数据一次性提交给 GPU 进行渲染,我们成功将所有卡片的绘制优化为 一次 drawCall,完美符合预期。这不仅避免了频繁的 Shader 切换,还大幅提升了渲染效率,使得 3D 透视效果流畅且高效。
▐ 物理碰撞
在游戏中,物理碰撞是非常常见的功能,Eva.js也提供了2D的物理引擎,但是由于本次场景中,碰撞的场景不多,并且我们追求极致性能和体验,所以我们本次小游戏的实现中没有使用物理引擎,而是采用更轻量的方案实现,每帧计算碰撞情况。
// 检查火箭是否飞出屏幕或者击中年兽 gameBody.transform.update = (params) => { if (this.paused) { return; } const monsterPos = monster.gameObject.transform.position; fireLauncher.flyingFireCracker = fireLauncher.flyingFireCracker.filter((fireCracker) => { const pos = fireCracker.gameObject.transform.position; // 世界坐标转换 const globalPos = toGlobal(fireCracker.gameObject, { x: 0, y: -NianMonsterConfig.firecracker.collisionOffset }); const collisionPos = toLocal(fireCracker.gameObject.parent, globalPos); // 撞到年兽时爆炸 if (distance(collisionPos, monsterPos) <= NianMonsterConfig.nianmonster.collisionRadius) { this.addScore(1); this.fireLauncher.canRotate = true; monster.hit(this.scoreProgress.getStarAmount(), isFirst); isFirst = false; // 爆炸动画 fireCracker.explode(); return false; } // 飞出屏幕时销毁 if (pos.x < borderLeft || pos.x > borderRight || pos.y > borderBottom || pos.y < borderTop) { if (monster.state === MonsterState.MOVE) { monster.miss(); mx.event.emit(GameEvent.showDialog, { pointLeft: () => monster.faceLeft, text: NianMonsterConfig.nianmonster.dialogs.miss, duration: 1000, }); } fireCracker.gameObject.destroy(); return false; } return true; }); };这个是打年兽的碰撞检测代码,由于年兽和火箭不是在同一坐标系下,他们的层级不同,相对坐标无法直接计算,所以第一步先把年兽所在的位置和火箭所在的位置转到同一坐标系下(世界坐标),然后再开始计算是否有交叉,从而实现碰撞逻辑。
▐ 压缩纹理
压缩纹理技术是通过对纹理数据进行特定的编码方式压缩,减少其占用的存储空间和内存带宽,从而提高渲染性能并降低存储需求。其基本原理是通过丢失一些图像信息或应用特定的算法,压缩纹理的大小,同时尽量保持视觉效果的质量。
常见的压缩纹理格式包括:
DXT(S3TC):这是微软定义的纹理压缩格式,广泛应用于PC和Xbox平台。它通过将纹理分为4x4像素的块,并用更少的比特数表示每个块的颜色,来减少纹理的存储需求。常见的DXT格式包括DXT1(用于1bit透明图像)、DXT3(带有可变透明度)和DXT5(带有平滑的透明度过渡)。
ETC(Ericsson Texture Compression):ETC是由爱立信提出的纹理压缩技术,主要用于移动设备,特别是Android平台。ETC1支持RGB纹理压缩,而ETC2支持RGBA纹理压缩。它的特点是硬件支持广泛,能够在低功耗设备上高效运行。
ASTC(Adaptive Scalable Texture Compression):ASTC是一种高效的压缩算法,能够提供比DXT和ETC更高的压缩比和图像质量。它的最大优势是可以动态调整压缩率(通过选择不同的块大小),从而在图像质量和压缩比之间找到平衡。ASTC广泛支持在新一代的移动设备、游戏主机和PC上。
PVRTC(PowerVR Texture Compression):PVRTC是Imagination Technologies开发的纹理压缩格式,主要用于PowerVR架构的图形处理单元(GPU),例如Apple设备上的GPU。它支持2D和3D纹理的压缩,适用于移动设备,特别是在iOS平台上有着广泛的应用。
压缩纹理的工作原理
压缩纹理的过程通常涉及以下步骤:
1.分块:将大纹理图像分割成较小的块,通常是4x4或8x8像素的块。
2.量化:对每个小块的颜色进行量化,减少颜色信息的精度,从而减小数据量。
3.编码:对量化后的颜色数据进行编码,常见的方法有位图编码和哈夫曼编码等。
4.存储:将压缩后的数据存储为文件格式,并在图形处理时解压缩。
压缩纹理的优缺点
优点:
减少内存占用:大幅度降低了纹理在显存中的占用。
提高性能:减少了GPU在渲染纹理时所需的内存带宽,有助于提高渲染性能。
减小存储空间:减小了游戏或应用的安装包大小,尤其适合存储空间有限的移动设备。
缺点:
质量损失:由于压缩过程中丢失了部分信息,纹理的视觉效果可能有所下降,尤其是在低比特率的压缩中更加明显。
硬件依赖:不同平台对压缩纹理的支持程度不同,可能需要使用不同的压缩格式或解压缩算法。
压缩时间:压缩过程可能需要一定的时间,尤其是对于高分辨率和复杂纹理。
压缩纹理技术在现代图形应用中至关重要,尤其是在游戏开发、移动应用和虚拟现实(VR)等领域,有助于提升性能、节省资源并提供更流畅的用户体验。总之,压缩纹理不仅能够节省内存和存储空间,还能优化性能和提升加载速度,是现代图形应用中非常重要的一项技术。
格式 | 体积(相对) | 质量 | 适用场景 | 体积 |
JPEG | 小(有损压缩) | 可能出现明显的块状失真 | UI 图片、普通贴图 | 100~500KB |
ASTC | 小(可调节压缩率) | 质量较好(可调节压缩率,损失较小) | 移动设备高端游戏、3D 纹理 | 256KB |
ETC1 | 小(固定 4bpp,无透明度) | 质量一般(有损) | 旧版 Android 纹理(无透明) | 512KB |
ETC2 | 中等(支持透明,固定 4bpp/8bpp) | 质量较 ETC1 好(但仍有损) | Android 纹理,支持透明 | 1MB |
Eva.js v2支持了ktx2压缩纹理。
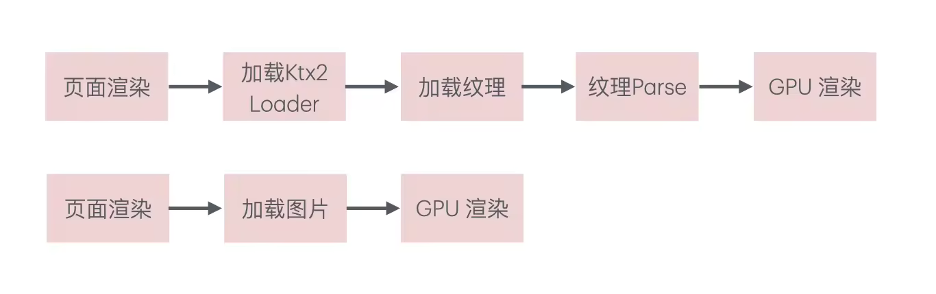
在使用压缩纹理时,我们需要先加载ktx2格式的加载和解析库,这个库是基于WASM实现的,体积大约为1MB。而我们的纹理素材是通过CDN进行加载的。相比JPEG或PNG等压缩格式,压缩纹理的文件尺寸通常更大,这导致使用压缩纹理反而会增加首屏加载时间。因此,在春晚的场景中,压缩纹理仅在接福禄场景中有所应用,并未广泛使用。
▐ 性能优化
引擎提前预热
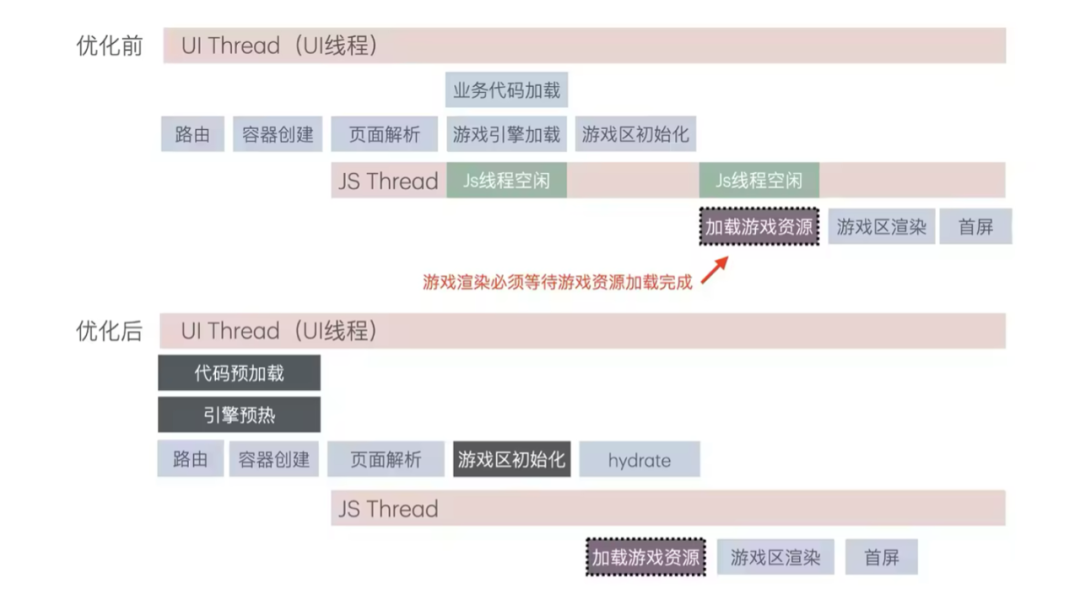
为了提升小游戏页面的加载速度,我们在小游戏资源包及首屏所需素材中增加了 Cache 包缓存,同时在主互动页面对小游戏进行了 Cache 预取,并进行了游戏引擎的预热处理。最大程度的利用了CPU资源。
首屏优化
Loading态骨架屏
由于小游戏整体主要依赖 Canvas 绘制,无法使用 SSR,因此我们采用了纯 CSR 方案。针对 CSR,我们同样可以优化首屏体验。首先,我们引入了静态化的骨架屏,并将其集成到 HTML 中,同时将 HTML 存入 Cache,从而大幅提升小游戏的打开速度。

3.5.2.2 容器背景色
即使 HTML 加载速度再快,依然会存在从容器打开时的白屏,到出现背景颜色,再到渲染游戏的这个过程。由于整个页面从纯白到有颜色的剧烈变化,可能会导致闪屏现象。
为了解决这一问题,我们采用了容器背景色方案。Themis 容器在打开时支持传入一个背景颜色,我们利用这一特性设置了合适的容器背景色,接下来让我们看看优化后的效果。
最终我们的全链路可交互时间为:均值1.74s P95 3.74s
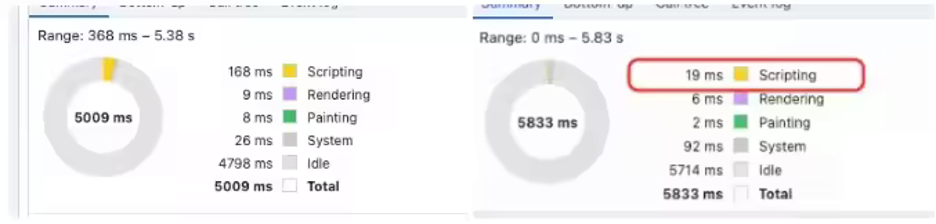
CPU优化
在游戏区静止态下,优化前,5秒内的脚本执行时长约为168ms;优化后,脚本时长降低至19ms,几乎达到了零消耗。
为了进一步优化 CPU 性能,我们在某些业务逻辑(如弹出窗口时)暂停游戏区的渲染。然而,在暂停游戏后,我们仍然观察到移动端大约 10% 的 CPU 占用。经过分析,我们发现,即使游戏暂停,游戏区的渲染循环依然在运行,导致了额外的 CPU 开销。
深入分析 pixi.js
在 pixi.js 源码中,我们发现其设计层面存在 多个计时器 (Ticker),因为 pixi.js 允许同一页面中运行多个渲染实例。因此,它提供了两种 Ticker:
sharedTicker(共享 Ticker)——默认情况下,多个实例共享该 Ticker。
systemTicker(系统 Ticker)——用于管理 pixi.js 内部的系统更新逻辑。
然而,在我们的场景下,并不需要多个 Ticker,因此,我们的优化方案是:合并 Ticker,减少不必要的计算开销。
优化效果
合并 Ticker 之后,我们可以观察到:
暂停游戏后,CPU 占用几乎降为 0%,显著提升性能。
避免了多个 Ticker 运行造成的冗余计算,减少了对移动端设备的资源消耗。
这一优化确保了在非必要场景下,CPU 负载降到最低,从而提升整体流畅度和电池续航能力。

挑战与突围
在上线过程中我们也遇到了一些挑战。1.灯不见了 2.小游戏页面重复刷新,经过我们的深度排查后,我们发现这两个问题都和WebGLContextLost有关。
WebGLContextLost 是 WebGL 开发中常见的问题,可能由多种原因引起,例如:
GPU 进程无响应——浏览器或系统层面的 GPU 进程崩溃,导致 WebGL 上下文丢失。
显存不足——场景中的纹理、缓冲区占用过多,导致 GPU 资源溢出。
WebGL 实例数量达到上限——不同浏览器对 WebGL 上下文的数量有限制,创建过多 WebGL 实例可能导致 WebGL 上下文丢失。
▐ 内存不足导致的灯不见了
由于移动端架构中,内存与显存是共享的,因此在下文中,我们统一将其称为“内存不足”。
当页面的内存不够的情况出现,浏览器会强制回收WebGLContext,这会导致我们的游戏区WebGL渲染会被中断,从而出现灯不见的情况,并且我们本次春晚为了保障灯笼的清晰度,使用的灯的素材也是高画质,尺寸非常大,尽可能没有压缩,所以在渲染灯时,会更容易出现内存不足情况。
针对手淘的高中低端机型,我们已实施画质降级策略。其中,高端机型与 Pad 设备会渲染 1.5 倍尺寸的画面,这意味着其内存占用比原来增加 2.25 倍。
测试结果 vs 线上环境 在测试过程中,我们未曾遇到因内存不足导致 WebGLContextLost 的问题。然而,在线上环境中,用户的使用场景更为复杂:
可能同时运行多个应用(如微信、微博、支付宝、小红书等);
本次春晚活动与支付宝存在联动唤端逻辑,而支付宝的“五福”活动本身也是一个重度依赖 WebGL 的应用,进一步加剧了设备的内存压力;
目前,我们的设备监控粒度较为粗略,仅能区分高中低端机型,无法精准监控具体的内存情况。
高端机型的意外问题 由于高端机型具备更高的渲染清晰度和帧率,因此相较于低端机型,反而更容易触发 WebGL Context 被回收的问题。
未来优化方向 我们需要提升内存监控能力,实时评估设备的内存压力,从而实现更精准的动态降级策略。例如:
当检测到设备内存不足时,自动降低画质或减少动画复杂度,以提升用户体验;
针对本次春晚活动,我们的临时方案是 降低高端机型的画质,以缓解该问题。
未来,我们希望能在保证流畅体验的前提下,实现更智能的资源分配策略。
▐ WebGLContext上限导致的页面重复刷新
当时考虑到的问题是,WebGLContextLost 大概率是由于内存不足或 GPU 无响应导致的。这种情况下,游戏区域会受到损坏,且无法恢复,因此我们选择刷新页面。事实上,在历年的大促场景和日常农场场景中,这种做法确实能够解决问题。
canvas.addEventListener('webglcontextlost', (event) => { setTimeout(() => { try { customReport(ErrorLogType.WebGLLostContext, 'webglcontextlost'); window.location.reload(); } catch (e) {} }, 0);});经过排查,我们才发现,原来是命中了以下情况:

当用户的主互动页面存在套娃逻辑时,可能会导致后台页面栈中最老的 WebGL Context 实例被暂时回收(可恢复)。此时,后台会触发页面的 reload 逻辑,从而创建一个新的 WebGL Context。紧接着,倒数第二个页面的 WebGL Context 变成最老的,随之被暂时回收,再次触发 reload 逻辑,创建新的 WebGL Context。此时,用户当前页面的 WebGL Context 又变成最老的,触发 WebGLContextLost,导致页面刷新。如果用户未返回上一页面,这一刷新逻辑便会陷入循环。
临时解决方案:我们调整策略,改为弹窗提示,要求用户手动点击刷新页面,从而缓解该问题。

技术结果
运行时体验 春晚小游戏中,低端机的帧数提升至30帧,中端机为60帧,高端机则为120帧,高于双十一时低端机限制为18帧、中端机为30帧、高端机为60帧。
小游戏首屏性能互动FSP:均值1.74s P95 3.74s 符合预期
稳定性 整体 0 故障,0 资损,无技术类导致重大舆情。

展望未来
手淘毕竟是一个以营销为核心的平台,过去在游戏与渲染相关领域的投入相对有限。面对日益增长的互动需求,未来 互动引擎 仍有很长的路要走,尤其是在 WebGLContext 管理、内存管理、内存监控 等方面,需要更深入的优化与探索。
随着互动场景的复杂度不断提升,我们不仅要提升 WebGL 资源的管理能力,还需要在高并发、高负载的环境下,确保稳定性和流畅性。这意味着,我们必须:
优化 WebGLContext 的生命周期管理,减少不必要的创建与销毁,降低性能开销;
加强内存管理机制,针对不同机型和设备情况,灵活调整渲染策略;
精细化内存监控能力,实时评估设备的资源占用情况,实现动态优化。
多种动效统一渲染引擎,目前动画效果除了使用 WebGL 渲染外,还包含 Lottie 动画。未来,我们可以通过 Eva.js 来实现 Lottie 动画,从而统一渲染引擎,这不仅有助于提升渲染效率,还能优化整体性能。
真3D实现,支持真实的 3D 场景渲染,并实现 2D 与 3D 的混合场景渲染,以提升视觉表现力和交互体验。
未来,我们希望构建一个更智能、适应性更强的互动引擎,为用户带来更流畅的体验,同时确保系统的稳定性和高效性。

用户的正向舆情
今年的春晚已经圆满结束,尽管过程中遇到了一些挑战,但依然收获了大量用户的积极反馈。今年春晚的落幕,既是一个阶段的结束,也是新的起点。
我们将继续反思问题、优化方案,持续提升用户体验。从每一次活动中总结经验,不断迭代升级,让未来的互动玩法更加流畅、稳定、有趣。只有不断进步,才能真正为用户带来更优质的体验,期待下一次的精彩呈现!

团队介绍
本文作者 识羽,来自淘天集团用户终端技术互动场景前端团队,我们团队负责“淘金币”、“芭芭农场”、“红包签到” 等手淘内千万级的互动产品,以及丰富的游戏产品,重点打造双11、春节、市场PR等S/A级营销互动。同时它也是一只拥有战友情、兄弟义,能自嘲、能自嗨,不敷衍工作、不耽误生活的充满活力和想象力的团队。
加入我们,你不仅可以依托淘系丰富的业务形态和海量的用户数据,与我们共同探索和衍生颠覆型互联网新技术,持续以技术驱动产品和商业创新,更可以与在用户增长、机器学习、图形图像、视觉算法、音视频通信、数字媒体、端侧智能等领域的全球顶尖专业人才共同引领面向未来的商业创新和进步。
期待对技术充满热情的你!
¤ 拓展阅读 ¤


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









