







 本文介绍了PKU Paraphrase Bank,一个基于40部经典小说95个译本的句级中文文本复述语料库,规模达50w+句对。采用无监督方法生成,通过句对匹配模型和BERT语义相似度计算。语料库质量高,适合文本复述研究。
本文介绍了PKU Paraphrase Bank,一个基于40部经典小说95个译本的句级中文文本复述语料库,规模达50w+句对。采用无监督方法生成,通过句对匹配模型和BERT语义相似度计算。语料库质量高,适合文本复述研究。
前两天查文本复述的资料的时候发现9月30号北大release了一批中文文本复述语料,就去看了一下,发现这篇文章用的方法都比较经典,易于理解,在这里做一个总结。
文章目录
文本复述定义
文本复述研究的主要对象是‘词语以上,句子以下’的语言单元,不涉及到段落级的改写问题。与文本相似相比,还需要考虑语义的相似性。比如:
S1: 我吃了晚饭
S2: 我吃了早饭
这两句话很像(文本相似),但意义却不一样,不能互为文本复述。
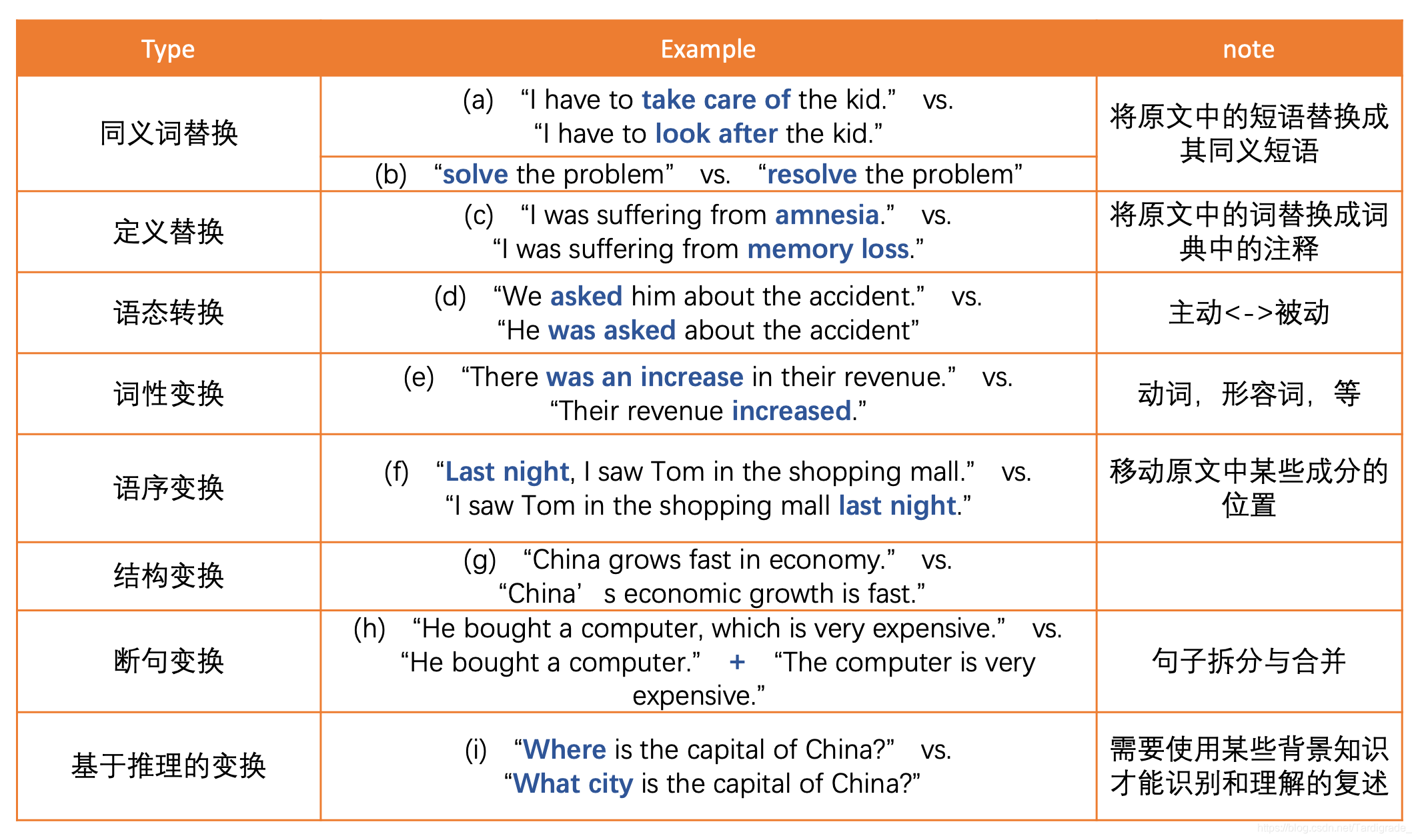
常见的文本复述类型有(来源某篇论文,不记得哪篇了):
语料库概况
PKU Paraphrase Bank: A Sentence-Level Paraphrase Corpus for Chinese
论文地址
语料库地址
数据来源
40部经典小说的95个译本,小说包括《基督山伯爵》《飘》《大卫科波菲尔》等。即每部小说选取2-3个译本。译本来源于网络。
这是很经典的枢轴(pivot)方法:采用同一文本(枢轴)的不同翻译作为文本复述模板的资源获取方法。
“由于每次翻译过程均要求源语言和目标语言中文本的语义保持一致,因此可以预期最后得到的文本在语义上能跟输入文本保持一致。”
举个文章中的例子(上面两句互为文本复述,下面两句互为文本复述):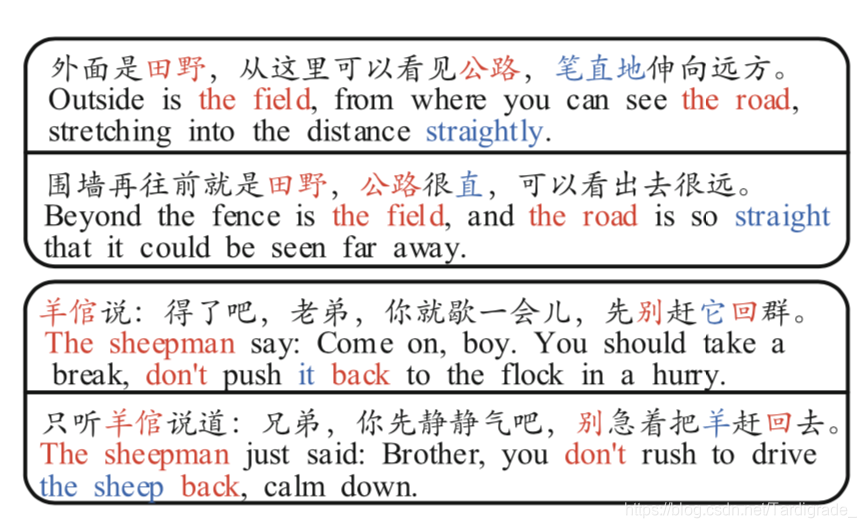
数据规模
509,832 (50w+) 组句对,大约是常见语料库(例如:Twitter News URL Corpus) 的10倍以上。平均每句23.05个词。
无监督语料库生成方法
流程概览

数据预处理
要点已经总结在上图中了。
首先,通过OCR工具将下载的pdf文件转换为plain text.
在格式清理的步骤中,需要将匹配用不到的头注,脚注,页码和注释等手动规则移除。
然后,通过。?!进行句子分割。少于6个单词的句子并入前句。
最后一步,利用Sun等人2011年提出的无监督方法Enhancing Chinese word segmentation using unlabeled data进行中文分词。
分数模型
这个语料库选取的数据来源有一个好处:由于原始翻译是按照句到句的方式进行的,所以理想情况下每一句都能够对应上。在这个前提下,我们就把问题转化成了两个文本T1和T2 中句子的对齐/匹配问题。
整体模型
对于T1中的每一个句子Ti1 和T2 中的每一个句子Tj2, 定义对齐矩阵C:
C i j = { 1 i f T i 1 a n d T j 2 m a t c h 0 o t h e r w i s e C_{ij}=\left\{ \begin{array}{rcl} 1 & & {if\ T_i^1\ and\ T_j^2\ match}\\ 0 & & {otherwise} \end{array} \right. Cij={
10if Ti1 and Tj2 matchotherwise
我们优化的目标是:
max. ∑ i = 1 N 1 ∑ j = 1 N 2 C i j × SCORE ( T i 1 , T j 2 ) \textup{max.} \sum_{i=1}^{N^1}\sum_{j=1}^{N^2}C_{ij}\times \textup{SCORE}(T_i^1, T_j^2) max.i=1∑N1j=1∑N2Cij×SCORE(Ti1,Tj2)
其中,N1为文本T1中的句子数目,N1为文本T2中的句子数目。即,我们优化的目标是尽量使分(SCORE)高的句对Ti1 和Tj2得到Cij=1.
同时,我们有约束条件:
∑ i = 1 N 1 C i j = 1 f o r a l l 1 ≤ i ≤ N 1 \sum_{i=1}^{N^1}C_{ij}=1\ for\ all\ 1 \leq i \leq N^1 i=1∑N1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









