






简介
Intel这次的黑客松比赛要求利用OneAPI的MKL库,生成2048*2048的单精度数,然后利用内部库实现FFT变换,因为MKL内部整合了fftw3这个库,所以我分别用其内部的库跟自带的fftw3进行对比。最后是对比两种FFT的结果。
生成单精度实数
生成单精度数的代码如下,这里面全是MKL自带的函数,非常好用,建议各位阅读一下Intel的函数说明,会对这些函数有一个进一步的理解,我直接把这些函数的说明文档链接贴出来(就不当翻译了)
void generate_random_array(float* array, int N1, int N2)
{
MKL_UINT seed = 123;
VSLStreamStatePtr stream;
vslNewStream(&stream, VSL_BRNG_MT19937, seed);
vsRngUniform(VSL_RNG_METHOD_UNIFORM_STD, stream, N1 * N2, array, 0.0, 10.0);
vslDeleteStream(&stream);
}这里,注意图中我画框的地方,可以直接搜索需要了解的函数名字,很方面,很直接。
利用fftw3实现FFT
核心代码如下:
void fftw3(float* Datain, fftwf_complex* Dataout, int N1, int N2)
{
fftwf_plan stream = NULL;
stream = fftwf_plan_dft_r2c_2d(N1, N2, Datain, Dataout, FFTW_ESTIMATE);
fftwf_execute(stream);
fftwf_destroy_plan(stream);
}这里与后面直接调用MKL不同的是注意输出数据类型的定义,即这句代码
fftwf_complex* Dataout利用MKL实现FFT
核心代码如下:
void MKL_2Dfft(float* Datain, MKL_Complex8* Dataout, int N1, int N2)
{
MKL_LONG dims[2] = { N2, N1 };
MKL_LONG status = 0;
MKL_LONG rstrides[] = { 0, N1, 1 };
MKL_LONG cstrides[] = { 0, N1 / 2 + 1, 1 };
DFTI_DESCRIPTOR_HANDLE hand = NULL;
char version[DFTI_VERSION_LENGTH];
//Basic MLK functions
DftiGetValue(0, DFTI_VERSION, version);
status = DftiCreateDescriptor(&hand, DFTI_SINGLE, DFTI_REAL, 2, dims);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiSetValue(hand, DFTI_CONJUGATE_EVEN_STORAGE, DFTI_COMPLEX_COMPLEX);
status = DftiSetValue(hand, DFTI_INPUT_STRIDES, rstrides);
status = DftiSetValue(hand, DFTI_OUTPUT_STRIDES, cstrides);
status = DftiCommitDescriptor(hand);
status = DftiComputeForward(hand, Datain, Dataout);
DftiFreeDescriptor(&hand);
}这里我写了注释,那些status,请各位看一下Intel的函数说明,特别注意的是这些代码几乎是最简版本,当然由于本人学艺不精,所以还有会有更好的写法。另外注意这里输出的数据是这样的数据类型。
MKL_Complex8* Dataout调用及结果对比
主函数中,主要需要注意的就是,在定义FFTW和MKL的输入输出的数据类型时,其他的部分全是基础。
int main(int argc, char *argv[])
{
int rows = 2048, cols = 2048;
float* random_array = (float*)malloc(rows * cols * sizeof(float));
// Call the function to generate a random array
generate_random_array(random_array, rows, cols);
float* fftw3_input = (float*)fftwf_malloc(rows * cols * sizeof(float));
fftwf_complex* fftw3_output = (fftwf_complex*)fftwf_malloc((cols)*rows * sizeof(fftwf_complex));
float* mkl_input_real = (float*)mkl_malloc(rows * cols * sizeof(float), 64);
MKL_Complex8* mkl_output_cmplx = (MKL_Complex8*)mkl_malloc(rows * cols * sizeof(MKL_Complex8), 64);
for (int j = 0; j < rows * cols; j++)
{
mkl_input_real[j] = random_array[j];
fftw3_input[j] = random_array[j];
}
int times = atoi(argv[1]); // Set the number of iterations
printf("we will run %d times \n", times);
//Perform MKL FFT
clock_t start_time_mkl = clock();
for (int t=0;t<times;t++){
MKL_2Dfft(mkl_input_real, mkl_output_cmplx, rows, cols);
}
clock_t end_time_mkl = clock();
float total_time_mkl = (float)(end_time_mkl - start_time_mkl) / CLOCKS_PER_SEC;
printf("performFFT_oneMKL total time: %f s \n", total_time_mkl);
//Perform FFTW fft
clock_t start_time_FFTW = clock();
for (int t=0;t<times;t++){
fftw3(fftw3_input, fftw3_output, rows, cols);
}
clock_t end_time_FFTW = clock();
float total_time_FFTW = (float)(end_time_FFTW - start_time_FFTW) / CLOCKS_PER_SEC;
printf("performFFT_fftw total time: %f s \n", total_time_FFTW);
// test the rusults
float error_real = 0.0, error_imag = 0.0, maxerr = 0.001, total_error_real = 0.0, total_error_imag = 0.0;
for (int k = 0; k < rows*cols; k++)
{
error_real = fabsf(fftw3_output[k][0] - mkl_output_cmplx[k].real);
error_imag = fabsf(fftw3_output[k][1] - mkl_output_cmplx[k].imag);
if (error_real > maxerr || error_imag > maxerr)
{
printf("Result is inconsistan: ");
printf("%d\n", k);
}
total_error_real = total_error_real + error_real;
total_error_imag = total_error_imag + error_imag;
}
if (error_real < maxerr && error_imag < maxerr)
{
printf("Result is consistant\n");
printf("\n");
}
printf("Here are average errors: \n");
printf("Error of real part is:%f Error of image part is:%f%s\n", total_error_real / (rows * cols), total_error_imag / (rows * cols), "i");
printf("\n");
//Free memory
mkl_free(mkl_input_real);
mkl_free(mkl_output_cmplx);
free(random_array);
fftwf_free(fftw3_input);
fftwf_free(fftw3_output);
}最后输出的结果如下:
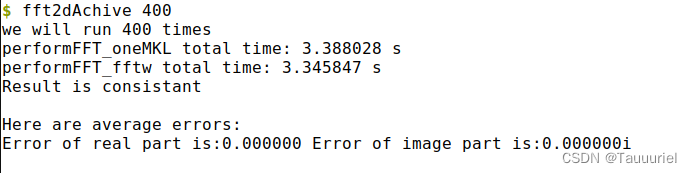
通过结果来看,在运行400次的时候,fftw还是比MKL要快,但是小于400次,MKL的速度是远远大于fftw的,但是一旦大于400次,fftw的速度就超过MKL了。















 4635
4635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









