







 本文深入探讨随机森林模型,解释其算法原理,包括Bagging思想和特征随机选择。通过实例展示了如何使用Python实现随机森林,并对比了自定义实现与sklearn库的效果。总结了随机森林的优缺点及其在实际应用中的调参影响。
本文深入探讨随机森林模型,解释其算法原理,包括Bagging思想和特征随机选择。通过实例展示了如何使用Python实现随机森林,并对比了自定义实现与sklearn库的效果。总结了随机森林的优缺点及其在实际应用中的调参影响。
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是机器学习专题的第26篇文章,我们一起聊聊另外一个集成学习模型,它就是大名鼎鼎的随机森林。
随机森林在业内名气和使用范围都很广,曾经在许多算法比赛当中拔得头筹。另外,它也是一个通过组合多个弱分类器构建强分类器的经典模型,因此它在业内广受欢迎。
本文基于决策树相关的文章,没有阅读过的同学可以从最上方的专辑查看过往决策树相关的文章。
算法原理
上一篇文章介绍AdaBoost的时候把集成学习的几种思路大概介绍了一遍,集成学习主要是三种方法,Bagging、Boosting和Stacking。AdaBoost属于Boosting,而随机森林则属于Bagging。
Bagging最大的特点就是"民主",其中的思路很容易理解,针对同一份训练数据我们会训练出多个弱分类器来。当面临一个新的样本的时候,由这些分类器聚集在一起进行民主投票,每一个分类器都是平等的,它们的权重一样。最后,根据所有这些弱分类器的结果整合出最后的结果来。比如说我们一共训练了50个弱分类器,在面对一个样本的时候,其中的35个给出类别1,15个给出类别0,那么整个模型的结果就是类别1。
另外一点是,Bagging在训练每一个分类器的时候所使用的数据并不是固定的,而是通过有放回抽样选择出来的。所以样本在训练集中出现的分布也是各不相同的,有些样本可能在同一个分类器中出现了多次,同样也有一些样本没有出现过。单单有样本随机性还是不够的,因为训练样本的分布大体上是差不多的,虽然我们随机采样,也不会使得每一份训练样本会有很大的差距。所以为了保证每个分类器的侧重点不同,拥有更强的随机性,我们还可以从特征入手,限制每个分类器只能随机使用部分特征。这样得到的分类器每一个的特征都各不相同,侧重点也就不同,可以尽可能地增强随机的效果,让模型专注于数据。
随机森林这个模型的名字当中隐藏了两个关键点,分别是随机和森林。随机我们已经解释过了,一方面是每一个分类器样本的随机,另外一个是分类器可以使用的特征的随机。而森林也很好理解,因为我们使用的分类器是决策树,所以多棵决策“树”组成的模型,自然就是森林了。
抓住这两个特征,随机森林很好理解,也很好实现,毕竟决策树模型我们之前已经实现过好几次了。
代码实现
我们选择决策树当中最经典的CART算法来实现决策树,数据我们依然沿用上次AdaBoost模型当中乳腺癌预测的数据。
首先,我们还是一样,先读入数据:
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
breast = load_breast_cancer()
X, y = breast.data, breast.target
# reshape,将一维向量转成二维
y = y.reshape((-1, 1))
之后我们利用sklearn库中的train_test_split工具将数据拆分成训练数据和测试数据。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=23)
随机森林的核心结构依然是决策树,我们可以直接沿用之前CART决策树的代码,只需要稍稍做一些小小的改动即可。首先是计算GIni指数和根据所选的特征拆分数据的函数,这两个函数不需要做任何改动,我们从之前的文章当中复制过来。
from collections import Counter
def gini_index(dataset):
dataset = np.array(dataset)
n = dataset.shape[0]
if n == 0:
return 0
counter = Counter(dataset[:, -1])
ret = 1.0
for k, v in counter.items():
ret -= (v / n) ** 2
return ret
def split_gini(dataset, idx, threshold):
left, right = [], []
n = dataset.shape[0]
# 根据阈值拆分,拆分之后计算新的Gini指数
for data in dataset:
if data[idx] <= threshold:
left.append(data)
else:
right.append(data)
left, right = np.array(left), np.array(right)
# 拆分成两半之后,乘上所占的比例
return left.shape[0] / n * gini_index(left) + right.shape[0] / n * gini_index(right)
然后是拆分数据集,我们根据特征和阈值将数据集拆分成两个部分。和上面的split_gini函数类似,只是split_gini函数计算的是拆分之后的Gini指数,而我们现在开发的是将数据集拆分的功能。
from collections import defaultdict
def split_dataset(dataset, idx, thread):
splitData = defaultdict(list)
# 否则根据阈值划分,分成两类大于和小于
for data in dataset:
splitData[data[idx] <= thread].append(np.delete(data, idx))
return list(splitData.values()), list(splitData.keys())
再然后是获取所有阈值以及选择最佳的特征和拆分阈值的函数,这两个函数的逻辑和之前也完全一样,我们也复制过来。
def get_thresholds(X, idx):
# numpy多维索引用法
new_data = X[:, [idx, -1]].tolist()
# 根据特征值排序
new_data = sorted(new_data, key=lambda x: x[0], reverse=True)
base = new_data[0][1]
threads = []
for i in range(1, len(new_data)):
f, l = new_data[i]
# 如果label变化则记录
if l != base:
base = l
threads.append(f)
return threads
def choose_feature_to_split(dataset):
n = len(dataset[0])-1
m = len(dataset)
# 记录最佳Gini,特征和阈值
bestGini = float('inf')
feature = -1
thred = None
for i in range(n):
threds = get_thresholds(dataset, i)
for t in threds:
# 遍历所有的阈值,计算每个阈值的Gini
gini = split_gini(dataset, i, t)
if gini < bestGini:
bestGini, feature, thred = gini, i, t
return feature, thred
再然后就是建树的部分了,这里我们做了一点小小的调整。因为我们只使用了一部分训练数据以及一部分特征训练的决策树,所以一般不会出现过拟合的情况,所以我去掉了防止过拟合的预剪枝逻辑。另外一个变动是加上了backup的设置,因为特征和数据的稀疏,可能会出现某个节点只有一个分支的情况。为了防止这种情况,我在每个节点都存储了一个backup,它代表的当前节点的数据中出现次数最多的那个类别。
def create_decision_tree(dataset):
dataset = np.array(dataset)
# 如果都是一类,那么直接返回类别
counter = Counter(dataset[:, -1])
if len(counter) == 1:
return dataset[0, -1]
# 如果已经用完了所有特征
if dataset.shape[1] == 1:
return counter.most_common(1)[0][0]
# 记录最佳拆分的特征和阈值
fidx, th = choose_feature_to_split(dataset)
node = {'threshold': th, 'feature': fidx, 'backup': counter.most_common(1)[0][0]}
split_data, vals = split_dataset(dataset, fidx, th)
for data, val in zip(split_data, vals):
node[val <= th] = create_decision_tree(data)
return node
再然后是两个工具函数,第一个是单棵子树对于单个样本的预测函数,第二个是单个子树对于批量样本的预测函数。整体的逻辑和之前大同小异,我们直接看代码即可:
def subtree_classify(node, data):
key = node['feature']
pred = None
thred = node['threshold']
# 如果当前的分支没有出现过,那么返回backup
if (data[key] < thred) not in node:
return node['backup']
if isinstance(node[data[key] < thred], dict):
pred = subtree_classify(node[data[key] < thred], data)
else:
pred = node[data[key] < thred]
# 防止pred为空,挑选一个叶子节点作为替补
if pred is None:
for key in node:
if not isinstance(node[key], dict):
pred = node[key]
break
return pred
def subtree_predict(node, X):
y_pred = []
# 遍历数据,批量预测
for x in X:
y = subtree_classify(node, x)
y_pred.append(y)
return np.array(y_pred)
到这里其实都是决策树的部分,决策树实现了之后,构建森林的部分非常简单。只做了一件事,就是随机样本和特征,然后用随机出的样本和特征创建新的决策树并进行记录。
首先我们来看随机样本和特征的函数:
def get_random_sample(X, y):
rnd_idx = np.random.choice(range(X.shape[0]), 350, replace=True)
ft_idx = np.random.choice(range(X.shape[1]), 15, replace=False)
x_ret = X[rnd_idx][:, ft_idx]
# 将类别拼接到X当中
x_ret = np.hstack((x_ret, y[rnd_idx]))
# 对特征的下标进行排序
ft_idx.sort()
return x_ret, np.array(ft_idx)
在这个函数当中,我们设定了每次训练新的决策树的时候,使用的样本数量是350条,特征数量是15个。通过这种方式保证构建的决策树的随机性。
随机样本搞定了之后,构建森林的代码就很简单了,通过一重循环创建树并记录即可:
trees_num = 20
subtrees = []
for i in range(trees_num):
X_rnd, features = get_random_sample(X_train, y_train)
node = create_decision_tree(X_rnd)
# 记录下创建出来的决策树与用到的特征
subtrees.append((node, features))
我们在创建树的时候随机使用了一些特征,我们在后续预测的时候需要用同样的特征去预测。所以我们需要记录下每一棵树用到了哪些特征值,并且决策树当中记录的只是特征的下标,所以我们在记录之前需要先对这些特征进行排序。
这些函数都实现之后就是predict方法了,根据Bagging的定义,对于每一个样本,我们都需要获取每一棵决策树的分类。然后选择其中数量最多的那个作为最终的预测结果,这段逻辑也不复杂,相信大家观看代码都能想明白。
def predict(X, trees):
y_pred = []
for x in X:
ret = []
for tree, features in trees:
ret.append(subtree_classify(tree, x[features]))
ret = Counter(ret)
y_pred.append(ret.most_common(1)[0][0])
return np.array(y_pred)
最后,我们在测试集上验证一下模型的效果:

准确率65.7%,看起来并不高,和我们预想中有些差距,我们来看下森林当中单棵树的效果:
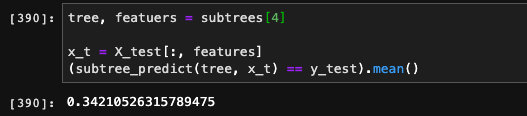
会发现有些树的准确率只有30%多,都没有达到50%的理论值。这当中的原因很多,一方面是我们选择特征的随机性,导致了我们可能选出来一些效果比较差的特征。另外一方面和我们训练的样本数量也有关系,在这个例子当中,我们可以使用的样本数量太少了,所以随机性很大,偏差自然也不小。
另外我们可以看下我们调用sklearn当中的随机森林的效果,我们同样设置森林中决策树的数量是40,并且选择Gini指数作为划分样本的依据。
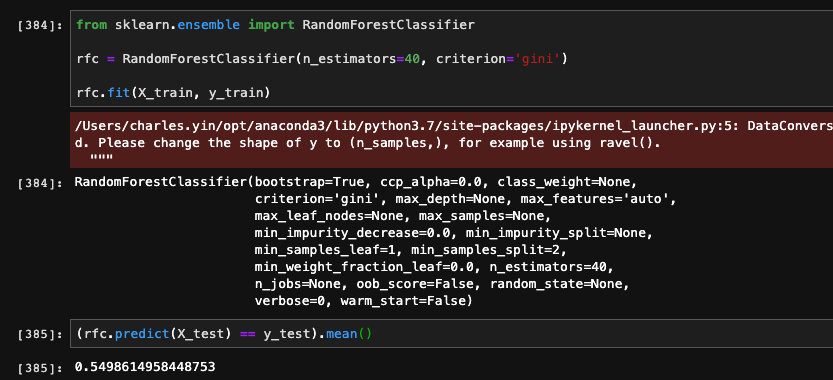
我们可以看到它的准确率甚至比我们自己开发的还要低,这也是很正常的,毕竟模型不是普适的,会存在一些场景下不太适用或者是效果不好的情况,这是非常正常的。
总结
随机森林模型最大的特点是随机,其实其中的原理和AdaBoost非常接近,我们通过随机样本和特征来保证模型的随机性,以及保证这样训练得到的模型是一个弱分类器。弱分类器除了效果弱之外,还有很大的一个特点就是不能过拟合,也就是说它们都是欠拟合的模型,自然不可能过拟合。我们通过整合大量弱分类器获得强大的分类效果。
和AdaBoost比起来,随机森林的随机性更强,并且对于参数的依赖更高,森林中决策树的数量,每一棵决策树需要使用的特征数量,以及剪枝的策略等等。这些因素都会影响到最终模型的效果,但它也有AdaBoost没有的优势,因为随机性,使得我们可能会发掘一些常规方法无法发现的特征组合或者是样本当中独特的数据分布。这也是为什么经过合适的调参之后,随机森林往往能够获得非常好的效果。
关于随机森林的介绍到这里就结束了,如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









