






本章节翻译by chenshusmail@163.com 原文:Kernel Launch (intel.com)
在 SYCL 中,通过将 kernel 排队到针对特定设备的队列中来执行工作。这些 kernel 由主机端提交给设备端, 由设备端执行并将结果发送回来。由主机端发起的 kernel 提交和实际开始执行并不立即发生 - 它们是异步的, 因此我们必须跟踪与 kernel 相关的以下时间。
-
Kernel 提交的开始时间
这是主机端开始提交 kernel 进程的时间。
-
Kernel 提交的结束时间
这是主机端完成提交 kernel 的时间。主机端执行多个任务,如排队参数, 在 runtime 为 kernel 在设备上开始执行分配资源。
-
Kernel 的启动时间
这是由主机端提交的 kernel 在设备端开始执行的时间。请注意,这并不完全相同于 kernel 提交结束时间。 在提交结束时间和 kernel 启动时间之间存在延迟,这取决于设备的可用性。 主机端可能会在实际启动执行之前将多个 kernel 排队等待执行。此外, 在实际 kernel 开始执行之前需要进行一些数据传输,这个时间通常不会与 kernel 的启动时间分开计算。
-
Kernel 的完成时间
这是 kernel 在设备端完成执行的时间。当前一代设备端是非抢占式的,这意味着一旦 kernel 启动, 它必须完成其执行。
像 Intel® VTuneTM Profiler (vtune), clIntercept, 和 onetrace 等工具为应用程序中每个 kernel 的上述每个时间提供了可视化时间线。
下面这个简单的例子展示了测量 kernel 执行的时间。这将涉及主机端的 kernel 提交时间、 设备端的 kernel 执行时间以及任何数据传输时间(由于没有 buffer 或 memory,所以这种情况下通常为零)。
void emptyKernel1(sycl::queue &q) {
Timer timer;
for (int i = 0; i < iters; ++i)
q.parallel_for(1, [=](auto) {
/* NOP */
}).wait();
std::cout << " emptyKernel1: Elapsed time: " << timer.Elapsed() / iters
<< " sec\n";
} // end emptyKernel1相同的代码,如果在 parallel_for 的末尾没有 wait(),那么它将测量主机端将 kernel 提交给 runtime 所需的时间。
void emptyKernel2(sycl::queue &q) {
Timer timer;
for (int i = 0; i < iters; ++i)
q.parallel_for(1, [=](auto) {
/* NOP */
});
std::cout << " emptyKernel2: Elapsed time: " << timer.Elapsed() / iters
<< " sec\n";这些开销高度依赖于所使用的后端 runtime 和主机端的处理能力。
一种测量设备端实际 kernel 执行时间的方法是使用 SYCL 内置的分析 API。 下面的代码演示了如何使用 SYCL 分析 API 来分析 kernel 执行时间。它还显示了 kernel 的提交时间。 由于它依赖于 runtime 和设备驱动程序,因此无法以编程方式测量 kernel 启动时间。分析工具可以提供这些信息。
#include <CL/sycl.hpp>
class Timer {
public:
Timer() : start_(std::chrono::steady_clock::now()) {}
double Elapsed() {
auto now = std::chrono::steady_clock::now();
return std::chrono::duration_cast<Duration>(now - start_).count();
}
private:
using Duration = std::chrono::duration<double>;
std::chrono::steady_clock::time_point start_;
};
int main() {
Timer timer;
sycl::queue q{sycl::property::queue::enable_profiling()};
auto evt = q.parallel_for(1000, [=](auto) {
/* kernel statements here */
});
double t1 = timer.Elapsed();
evt.wait();
double t2 = timer.Elapsed();
auto startK =
evt.get_profiling_info<sycl::info::event_profiling::command_start>();
auto endK =
evt.get_profiling_info<sycl::info::event_profiling::command_end>();
std::cout << "Kernel submission time: " << t1 << "secs\n";
std::cout << "Kernel submission + execution time: " << t2 << "secs\n";
std::cout << "Kernel execution time: "
<< ((double)(endK - startK)) / 1000000.0 << "secs\n";
return 0;
}下图显示了上述示例执行的时间线。这张图片是通过运行 clIntercept 生成跟踪文件并使用 Chrome* tracing 来生成可视化时间线的。在这个时间线中有两条轴线, 一个用于主机端,另一个用于设备端。注意, 在设备端唯一的活动是执行提交的 kernel。 在主机端完成了大量工作来准备 kernel 的执行。 在这种情况下,由于 kernel 非常小,总执行时间主要由 kernel 的 JIT 编译所占据, 即下图中标记为 clBuildProgram 的块。

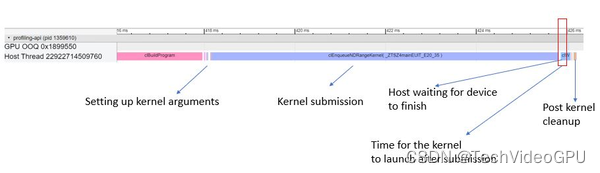
下图是放大版本,显示了主机端提交 kernel 时调用的函数的详细信息。 这里的时间主要由 clEnqueueNDRangeKernel 占据。另外请注意, 在主机上完成 kernel 提交和设备上实际启动 kernel 之间存在延迟。这是因为在主机上完成 kernel 提交后, 设备端需要一些时间来准备执行 kernel,这取决于设备的可用性和 runtime 的调度策略。

















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









