








这个mnist手写体数字识别的例子可以说是caffe中的 Hello World。mnist最初用于支票上的手写数字识别,针对mnist识别的专门模型是Lenet,这是由Yan LeCun大神搞出来的,可以说是最早的CNN实例。通过这个例子我们来看一下使用caffe大概是个什么流程
1、下载数据
第一步自然是要有数据了,没有数据怎么学习呢?
我们之前谈到数据一般是保存在caffe目录下data这个目录的
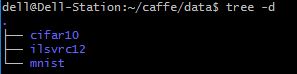
再进入mnist目录看一下:

这里只有1个file,即是get_mnist.sh脚本,我们就是运行它来下载mnist数据的,
来看一下此脚本里面写的什么
打开此脚本:vim get_mnist.sh
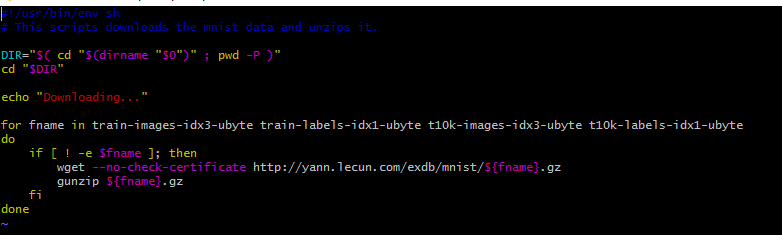
这里面的内容了解一下即可,主要是让大家看看稀奇,可见它用了一个for循环,下载了4个文件,并解压了它们。
这里可能和其他一些地方分别把四个文件的名字和网址都列出来不一样,可能是caffe版本的问题,但是所执行的任务是一样的,for循环大家总看得懂吧
废话有点多了,回到caffe根目录,输入下面的代码,
./data/mnist/get_mnist.sh

然后就显示以下内容
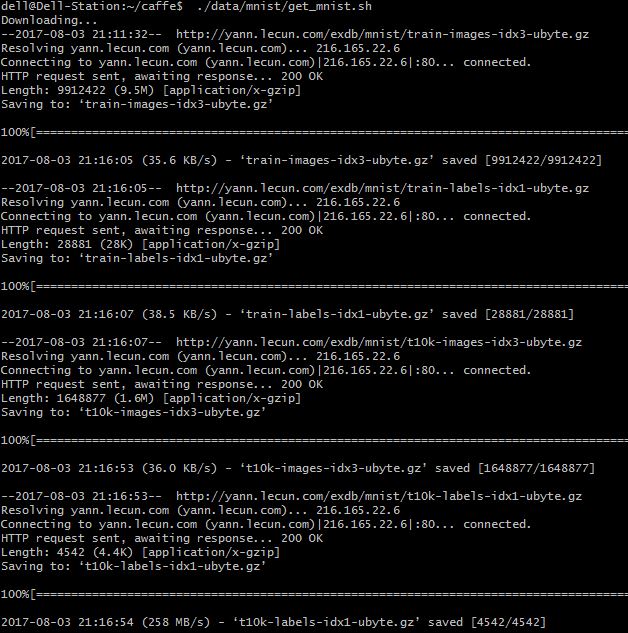
下载完毕,原来的文件夹里多了四个文件

2、转换数据格式
下载的数据为二进制文件,需要转换为LEVELDB或LMDB,
Mnist这个例程保存在我之前Caffe随记(一)中谈及的caffe目录下example这个目录,转到此目录可见如下,可以看到有个叫做mnist的文件夹,我们就要用到里面的东西
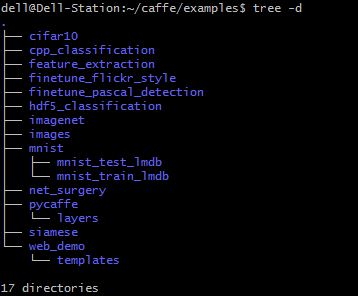
打开mnist目录

我们会用到create_mnist.sh这个脚本(然后我们还偶遇了上篇博文中提到的lenet_solver.prototxt这个脚本)
打开脚本看看里面的内容: vim create_mnist.sh
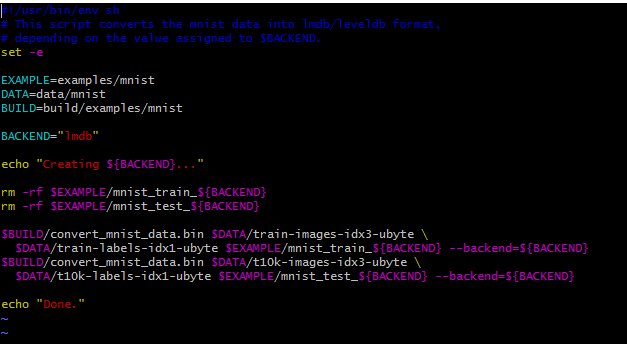
这里还是讲一下这个脚本中写的内容把,
首先,定义了几个路径变量:EXAMPLE、DATA、BUILD,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









