







TensorFlow 2.x 要点函数用法与经验
此笔记为学习 tf 过程中遇到的部分函数用法解释与经验,不属于基础学习教程,阅读需要一定基础。
1. tf.keras搭建神经网络
1.1 六步法
(1) import相关模块,如 import tensorflow as tf
(2) 指定输入网络的训练集、验证集和测试集,如指定训练集的输入 x_train 和标签y_train,验证集的输入 x_validation 和标签 y_validation,测试集的输入 x_test 和标签 y_test。
(3) 逐层搭建网络结构,model = tf.keras.Sequential()。
(4) 在 model.compile()中配置训练方法,选择训练时使用的优化器、损失函数和最终评价指标。
(5) 在 model.fit()中执行训练过程,告知训练集和验证集的输入值和标签、每个 batch 的大小(batch_size)和数据集的迭代次数(epoch)。
(6) 使用 model.summary()打印网络结构,统计参数数目。
1. 2 函数用法介绍
— — tf.keras.Sequential()
Sequential 函数是一个容器,描述了神经网络的网络结构,在 Sequential函数的输入参数中描述从输入层到输出层的网络结构。
如:
拉直层:tf.keras.layers.Flatten()
拉直层可以变换张量的尺寸,把输入特征拉直为一维数组,是不含计算参数的层。如 model = tf.keras.layers.Flatten(input_shape=(28, 28))
全连接层:tf.keras.layers.Dense( 神经元个数,activation=”激活函数”,kernel_regularizer=”正则化方式”)
其中:
activation可选 relu、softmax、sigmoid、tanh 等
kernel_regularizer 可选 tf.keras.regularizers.l1()、tf.keras.regularizers.l2()
卷积层:tf.keras.layers.Conv2D( filter = 卷积核个数,kernel_size = 卷积核尺寸,
strides = 卷积步长, padding = “valid” or “same”)
循环神经网络层:LSTM 层:tf.keras.layers.LSTM()
— — Model.compile ( optimizer = 优化器, loss = 损失函数, metrics = [“准确率”])
Compile 用于配置神经网络的训练方法,告知训练时使用的优化器、损失函数和准确率评测标准。
其中:
optimizer 可以是字符串形式给出的优化器名字,也可以是函数形式,使用函数形式可以设置学习率、动量和超参数。
可选项包括:
‘sgd’ or tf.optimizers.SGD( lr=学习率,decay=学习率衰减率,momentum=动量参数)
‘adagrad’ or tf.keras.optimizers.Adagrad(lr=学习率,decay=学习率衰减率)
‘adadelta’ or tf.keras.optimizers.Adadelta(lr=学习率,decay=学习率衰减率)
‘adam’ or tf.keras.optimizers.Adam (lr=学习率, decay=学习率衰减率)
Loss 可以是字符串形式给出的损失函数的名字,也可以是函数形式。
可选项包括:
‘mse’ or tf.keras.losses.MeanSquaredError()
‘sparse_categorical_crossentropy’或‘categorical_crossentropy’(one-hot编码时)
or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
损失函数常需要经过 softmax 等函数将输出转化为概率分布的形式。from_logits 则用来标注该损失函数是否需要转换为概率的形式,取 False 时表示转化为概率分布,取 True 时表示没有转化为概率分布,直接输出。
Metrics 标注网络评测指标。
可选项包括:
‘accuracy’:标签值和 预测值都是数值。
‘categorical_accuracy’:标签值和 预测值都是以独热码和概率分布表示。
如 y_=[0, 1, 0], y=[0.256, 0.695, 0.048]。
‘sparse_ categorical_accuracy’:标签值是以数值形式给出,预测值 是以独热码形式给出。 如 y_=[1],y=[0.256, 0.695, 0.048]。
例:
one-hot编码时
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
...
model.compile(optimizer='adam',
loss=tf.keras.losses.categorical_crossentropy,
metrics=tf.keras.metrics.categorical_accuracy)
没有one-hot编码时
self.d2 = Dense(10, activation='softmax')
...
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=tf.keras.metrics.sparse_categorical_accuracy)
— — model.fit (训练集的输入特征, 训练集的标签, batch_size, epochs, validation_data = (验证集的输入特征,验证集的标签), validataion_split = 从测试集划分多少比例给验证集, validation_freq = 验证的 epoch 间隔次数)
fit 函数用于执行训练过程。
— — model.summary()
summary 函数用于打印网络结构和参数统计
2. 打乱数据集
用于训练、验证和测试的所有数据应随机打乱,但要注意数据与标签的匹配正确。
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
此处有问题,加上这段代码后,十分类准确率大概只有0.1,改正后再使用。
3. class类声明网络结构
使用 Sequential 可以快速搭建网络结构,但是如果网络包含跳连等其他复杂网络结构,Sequential 就无法表示了。这就需要使用 class 来声明网络结构。
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras.layers import Dense, Flatten, Conv2D
class MyModel(Model):
def __init__(self):
super(MyModel, self).__init__()
//初始化网络结构
def call(self, x):
y = self.d1(x)
return y
使用 class 类封装网络结构,如上所示是一个 class 模板,MyModel 表示声明的神经网络的名字,括号中的 Model 表示创建的类需要继承 tensorflow 库中的 Model 类。类中需要定义两个函数,init()函数为类的构造函数用于初始化类的参数,spuer(MyModel,self).init()这行表示初始化父类的参数。之后便可初始化网络结构,搭建出神经网络所需的各种网络结构块。call()函数中调用__init__()函数中完成初始化的网络块,实现前向传播并返回推理值。使用 class 方式搭建MNIST网络结构的代码如下所示。
class MNISTModel(Model):
def __init__(self):
super(MNISTModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
model = MNISTModel()
对比使用 Sequential()方法和 class 方法,有两点区别:
①import 中添加了 Model 模块和 Dense 层、Flatten 层。
②使用 class 声明网络结构,model = MyModel()初始化模型对象。
4. 功能扩展
按照以上三条基本可以实现对已有数据集,如Mnist,Fashion Mnist,IMDB等,实现分类。但是要解决自己领域的问题,一般需要自制数据集,以及模型的保存,训练参数的保存和可视化。本段主要讨论这些。
4.1 自制数据集
仿照Mnist,北京大学软件与微电子学院曹建老师自制了手写数字数据集。我们以此数据集为例说明自制数据集的过程。
数据集名称为mnist_image_label,里面包括4个文件,如图。

中间打码的是我写的.py文件,原文件中没有这个。
训练集特征:mnist_train_jpg_60000
训练集标签:mnist_train_jpg_60000.txt
测试集特征:mnist_test_jpg_10000
测试集标签:mnist_train_jpg_10000.txt
部分训练集图片

部分测试集标签

文件夹链接:https://pan.baidu.com/s/1tO73f1dxDLxfeY7RRybTbQ
提取码:ojp6
观察数据集后可知,训练集特征有60000个,测试集10000个,标签分行逐个列出,且标签有两部分组成:文件名 + 标签值,中间用空格隔开。
按照顺序,先准备数据集。
为此,先定一个函数用于读取文件,生成训练集、测试集,代码如下:
def generateds(path, txt):
f = open(txt, 'r') # 以只读格式打开txt文件
contents = f.readlines() # 读取文件中所有行
f.close() # 关闭文件
x, y_ = [], [] # 空列表
for content in contents: # 逐行取出
value = content.split() # 以空格分开,图片路径value[0], 标签value[1]
img_path = path + value[0] # 路径+图片名
img = Image.open(img_path) # 读入图片
img = np.array(img.convert('L')) # 图片转为灰度图
img = img / 255.0 # 归一化
x.append(img) # 图片逐个贴入列表
y_.append(value[1]) # 标签贴入列表
print('loading: ' + content) # 打印当前读取行号
x = np.array(x) # 转为数组
y_ = np.array(y_)
y_ = y_.astype(np.int64) # 转为64位整型
return x, y_ # 返回特征x, 标签y_
可根据训练集(特征+标签)路径、测试集(特征+标签)路径生成训练集和测试集,如下:
x_train, y_train = generateds(train_data_path, train_label_txt)
x_test, y_test = generateds(test_data_path, test_label_txt)
从读取数据到构建模型的全部代码如下:
# 自制数据集
# 导入所需模块
import tensorflow as tf
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import os
# 数据集路径
train_data_path = './mnist_image_label/mnist_train_jpg_60000/'
train_label_txt = './mnist_image_label/mnist_train_jpg_60000.txt'
x_train_savepath = './mnist_image_label/mnist_x_train.npy'
y_train_savepath = './mnist_image_label/mnist_y_train.npy'
test_data_path = './mnist_image_label/mnist_test_jpg_10000/'
test_label_txt = './mnist_image_label/mnist_test_jpg_10000.txt'
x_test_savepath = './mnist_image_label/mnist_x_test.npy'
y_test_savepath = './mnist_image_label/mnist_y_test.npy'
def generateds(path, txt):
f = open(txt, 'r') # 以只读格式打开txt文件
contents = f.readlines() # 读取文件中所有行
f.close() # 关闭文件
x, y_ = [], [] # 空列表
for content in contents: # 逐行取出
value = content.split() # 以空格分开,图片路径value[0], 标签value[1]
img_path = path + value[0] # 路径+图片名
img = Image.open(img_path) # 读入图片
img = np.array(img.convert('L')) # 图片转为灰度图
img = img / 255.0 # 归一化
x.append(img) # 图片逐个贴入列表
y_.append(value[1]) # 标签贴入列表
print('loading: ' + content) # 打印当前读取行号
x = np.array(x) # 转为数组
y_ = np.array(y_)
y_ = y_.astype(np.int64) # 转为64位整型
return x, y_ # 返回特征x, 标签y_
if os.path.exists(x_train_savepath) and os.path.exists(
y_train_savepath) and os.path.exists(
x_test_savepath) and os.path.exists(y_test_savepath):
print('-----------------Load Datasets-----------------')
x_train_save = np.load(x_train_savepath)
y_train = np.load(y_train_savepath)
x_test_save = np.load(x_test_savepath)
y_test = np.load(y_test_savepath)
x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28)) # 转为28*28的len个数组
x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))
else:
print('-----------------Generate Datasets-----------------')
x_train, y_train = generateds(train_data_path, train_label_txt)
x_test, y_test = generateds(test_data_path, test_label_txt)
print('-----------------Save Datasets-----------------')
x_train_save = np.reshape(x_train, (len(x_train), -1)) # 转为1维数组
x_test_save = np.reshape(x_test, (len(x_test), -1))
np.save(x_train_savepath, x_train_save)
np.save(y_train_savepath, y_train)
np.save(x_test_savepath, x_test_save)
np.save(y_test_savepath, y_test)
'''plt.subplot(1, 2, 1)
plt.imshow(x_train[0], cmap='binary')
plt.xlabel('x_train[0]')
plt.xticks([])
plt.yticks([])
plt.subplot(1, 2, 2)
plt.imshow(x_test[0], cmap='binary')
plt.xlabel('x_test[0]')
plt.xticks([])
plt.yticks([])
plt.show()'''
# 构建模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=tf.keras.metrics.sparse_categorical_accuracy)
model.fit(x_train, y_train, batch_size=32, epochs=10,
validation_data=(x_test, y_test))
model.summary()
4.2 数据增强
数据增强的作用自不用多说,直接看用法。
img_gen=tf.keras.preprocessing.image.ImageDataGenerator(增强方法)
img_gen.fit(x_train)
常用增强方法:
缩放系数:rescale=所有数据将乘以提供的值
随机旋转:rotation_range=随机旋转角度数范围
宽度偏移:width_shift_range=随机宽度偏移量
高度偏移:height_shift_range=随机高度偏移量
水平翻转:horizontal_flip=是否水平随机翻转
随机缩放:zoom_range=随机缩放的范围 [1-n,1+n]
fit参数:
img_gen.fit(x, augment=Flase,rounds=1,seed=None)
- x:样本数据,4维,即(batch, width, height, channel)的格式。灰度图,channel=1; RGB图,channel=3;
- augment:布尔值(默认False),是否使用随机样本扩张;
- rounds:整数(默认为1)。数据增强次数;
- seed:随机种子。
注:
尝试过rounds=2,想着把一张图片增强两张,然而效果并不是这样,rounds应该是增强几次,一张图片进行了rounds次增强循环,每次增强具有随机性。比如第一次没有水平翻转,第二次可能会水平翻转,增加更多的随机性,其结果还是输出一张图片。
例:
img_gan = ImageDataGenerator(rescale=1.0 / 1.0, # 原像素值0~255归一化到0~1
rotation_range=45, # 随机旋转45度
width_shift_range=0.15, # 随机宽度偏移[-.015,0.15)
height_shift_range=0.15, # 随机高度偏移[-0.15, 0.15)
horizontal_flip=True, # 随机水平翻转
zoom_range=0.5) # 随机缩放[1-0.5,1+0.5]
img_gan.fit(x_train)
注:
1、数据增强函数的输入要求是4维,可用reshape调整
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
2、model.fit(x_train,y_train,batch_size=32,……)变为
model.fit(image_gen_train.flow(x_train, y_train,batch_size=32), ……)
3、如果报错:缺少scipy 库
更多关于图像增强的方法可参考:https://blog.csdn.net/qq_27825451/article/details/90056896
但个人认为,以上方法基本可以解决问题了。
对MNIST数据集应用数据增强代码如下:
# 数据增强
import numpy as np
import matplotlib.pyplot as plt
from keras_preprocessing.image import ImageDataGenerator
import tensorflow as tf
# 加载数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) # 数据增强需要4维
y_train = tf.keras.utils.to_categorical(y_train) # one-hot编码
y_test = tf.keras.utils.to_categorical(y_test)
print('\nx_train.shape:', x_train.shape) # (60000,28,28,1)
print('\nx_test.shape:', x_test.shape) # (10000,28,28)
print('\ny_train.shape:', y_train.shape) # (60000,10)
print('\ny_test.shape:', y_test.shape) # (10000,10)
print('----------------------------------------')
# 增强参数
img_gen = ImageDataGenerator(rescale=1.0 / 1.0, # 归一化
featurewise_center=True,
featurewise_std_normalization=True, # 标准化
rotation_range=45, # 随机旋转45
height_shift_range=0.15, # 宽度随机偏移[-0.15,0.15)
width_shift_range=0.15, # 高度随机偏移[-0.15,0.15)
horizontal_flip=True) # 随机水平翻转
img_gen.fit(x_train, rounds=2)
# 此处的rounds未知用途,原意是想验证=2,是否是一张增强后存两张。
# 然而测试结果不是这样,猜测是原图经过rounds次ImageDataGenerator,从而增加随机性
# 另一个问题,特征增强后可以另存一个路径,那标签呢,难道是手动添加吗
# 估计是了,按顺序对所有训练数据增强后,其标签还是原来顺序的标签
# 可以复制原来的标签另存一个txt文档
# 组合新数据集
# 初始特征 + 随机打乱的增强特征, 两者合并后,再打乱一次
# 初始标签 + 同样顺序打乱初始标签,两者合并后,再同样顺序打乱一次
img_iter = img_gen.flow(x_train, y_train, batch_size=12,
shuffle=False, save_to_dir='save_data')
print(type(img_iter))
'''for x_batch, y_batch in img_iter:
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(np.squeeze(x_batch[i]), cmap='binary')
plt.xticks([])
plt.yticks([])
plt.show()
break'''
'''for x_batch, y_batch in img_iter:
for j in range(0, rounds):
for i in range(8):
plt.figure(j)
plt.subplot(2, 4, i+1)
plt.imshow(np.squeeze(x_batch[i]), cmap='binary')
plt.xticks([])
plt.yticks([])
plt.show()
break'''
'''for j in range(0, rounds):
for x_batch, y_batch in img_iter:
for i in range(8):
plt.figure(j)
plt.subplot(2, 4, i+1)
plt.imshow(np.squeeze(x_batch[i]), cmap='binary')
plt.xticks([])
plt.yticks([])
plt.show()
break注释部分是验证是否存了多张图
'''
x_train_subset1 = np.squeeze(x_train[:12]) # 原始特征, (12,28,28)
x_train_subset2 = x_train[:12] # 增强后特征(12,28,28,1)
print('x_train_subset1', x_train_subset1.shape)
print('x_train_subset2', x_train_subset2.shape)
# 显示图片
plt.figure(figsize=(10, 2))
for i in range(len(x_train_subset1)):
plt.subplot(1, 12, i+1)
plt.imshow(x_train_subset1[i], cmap='binary')
plt.xticks([])
plt.yticks([])
plt.suptitle('Original Training Image', fontsize=10)
plt.show()
plt.figure(figsize=(10, 2))
for x_batch, y_batch in img_iter:
for i in range(0, 12):
plt.subplot(1, 12, i+1)
plt.imshow(np.squeeze(x_batch[i]), cmap='binary')
plt.xticks([])
plt.yticks([])
plt.suptitle('Generator Image', fontsize=10)
plt.show()
break
#此处必须有break,否则,一试便知。。。
效果如下:


对MNIST应用数据增强完整代码如下:
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 数据增强必须四维
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
img_gan = ImageDataGenerator(rescale=1.0 / 1.0, # 原像素值0~255归一化到0~1
rotation_range=45, # 随机旋转45度
width_shift_range=0.15, # 随机宽度偏移[-.015,0.15)
height_shift_range=0.15, # 随机高度偏移[-0.15, 0.15)
horizontal_flip=True, # 随机水平翻转
zoom_range=0.5) # 随机缩放[1-0.5,1+0.5]
img_gan.fit(x_train)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28, 1)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=tf.keras.metrics.sparse_categorical_accuracy)
# 优化函数用SGD,学习率0.03效果更好
# batch_nomalization应更好
model.fit(img_gan.flow(x_train, y_train, batch_size=32), epochs=10,
validation_data=(x_test, y_test))
model.summary()
结果如下:

识别准确率较差,只有0.8左右。优化函数改为SGD,学习率0.03~0.04,可以提高一些准确率,已尝试。另外,采用Batch-Nomalization应该会有效果。此问题先放着,后续再解决。
4.3 断点续训
4.4 提取参数
4.5 可视化
4.6 给图识物
问题与思考
问题1:为什么要有拉直层?
搭建神经网络结构时,一般会有一步拉直层
tf.keras.layers.Flatten()。为什么?为什么不是直接输入原始特征?
试答:以MNIST为例,28*28的形式我们可以清楚它表示的数字,拉直后为一维数组,我们不知道它代表着数字几。只是它的维度需要等于输入层神经元个数。
事实上,神经网络的输入层的神经元个数就是输入特征的维数,先有的此事实,后有的拉直变换。将输入特征拉直后,就可以一维对应一个神经元喂入到神经网络中了。另一点,对所有的输入特征,进行同样的拉直变换或其他什么变换,训练得到的网络模型应该是等效于全部输入特征都不变换直接喂入输入层的网络结构,因为我们是对每一个输入特征都进行了相同的拉直变换。但是,会不会有这样的情况,原始特征属于不同的数字,经过拉直变换后得到的一维特征相似,这样是不是就存在错误分类的可能。猜测:只有本身特征就很相似的数据,经拉直后,才会出现相似的一维特征,而本身就相似的初始特征被分为一类是可以允许的,除非模型特别准确,100%。
3月29日早,补充:
如图所示。

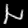
左为数字5,右为数字2.两者是图像增强后的结果。如果再把数字逆时针转动90度,5和2就分不清了,拉直后同样也分不清。但是,不旋转的话,一般的分类模型都是可以正确识别的。
问题2:为什么要卷积?
都是全连接不可以吗,为什么网络结构要有卷积层?卷积的意义作用是什么?














 2663
2663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









