








把数据库分析的Clustering加到这里来吧-为完成哦
内容一览
1.动机
2.k-means聚类(经典聚类)
3.多级聚类
4.COBWEB(Begriffliche Balungen)和概念聚类
5.前景
动机
动机
1.训练集的收集和分类相当费力
2.另外训练时那么多量要计算也是相当麻烦的
(Engineering z.B:Merkmalsberechnung der Daten kann sehr aufwendig sein)
3.可以运用于数据挖掘(Data Mining)
4.(Sich verändernde Charakteristika von Mustern) //这个理解不能???
5.寻找新的属性(Finden von neuen Eigenschaften)//同样理解不能???
6.对数据结构的初步认识(Erste Erkenntnisse über Struktur von Daten)
//还是理解不能??????????
Clustering
Clustering的一般问题描述
已知N个具有d维属性的数据的集合
目的是:
把这个集合中的数据分成k个不同的簇和一个噪音(有办法区分出噪音吗,对此暂时表示怀疑???)并且这些簇应该根据下列两个条件进行选择:
1.同一个簇中的数据应该相似
(Intra-cluster Similarity wird maximiert)
2.不同簇之间的数据应该不相同
(inter-cluster Similarity wird minimiert)
Criterion Function
在这里我们引入Criterion Function:
并用他来描述同一个簇内的数据的相似度。那么相应的Clustering的目的就可以改变为,优化这个Criterion Function。
//好像忽略了簇间的情况。
值的注意的是上式中的d并不一定表示的是x和m之间的距离。实际上函数d表达的是输入点x和该簇的参数点m之间的相识程度。举个例子,比如簇内数据分布符合正太分布,那么m就可以是指这个正太分布的均值和方差,而d函数对应的结果就是输入点属于该分布的概率。而在这里我们用这个概率来表达这种相似度。
参数的选择
那么现在问题就来了,这个式子里有两个参数m和k,我们应该怎么对这两个参数进行选择呢??
参数m
一般情况下m得选择是很难的,因为他要求对数据的分布具有一定的了解。正如上面的例子,如果不知道这些数据符合正太分布,那么对于这些参数将无从下手。
参数k
另一个起决定性作用而且很重要的的参数就是k
k表示的是聚类最终要生成的簇的数目。很明显根据要求的生成簇的数量的不同,他最终生成的结果也会相差很大。
在没有确定具体k的数目的情况下,我们一般采用的是下面这种方法:
把k从2到n-1的情况都给试一遍,从结果集中选出最好的聚类。
Clustering的评价标准
那么应该如何评价一个聚类的质量呢??
在介绍具体的方法之前,我们先说一下这种测量方法应该满足的一些条件:
1.数组不能随着k增长呈单调增长。n个数据分成n个簇的话,那是绝对满足簇内相识最小得条件的。但很明显这并不是一个好得聚类的方法
(Maß hierfür darf nicht einfach mit k monoton wachsen)
2.测量紧凑性的到的数值同样也不能随着k的减少单调下降。
(Kompaktheitsmaß für Clustering fällt monoton mit k)
下面要介绍到的Sihouette系数就是一种值不会随着k的增大而单调递增的聚类的质量的测量。
Silhouette系数(Silhouette-Koeffizient)
设计的目的以及其基本思想
1.同一个簇内的对象应该和这个簇的代表尽量的相似,
在这里我们用簇内对象到簇内代表的平均距离表示。
(Objekte in Cluster sollten Repräsentanten des Clusters möglichst ähneln-durchschnittlicher Abstand der Objekte zum Repräsentanten ihres Clusters)
2.不同簇中的对象应该长得相差尽量的远一点,在这里我们用不同簇内对象之间的平均距离表示。
(Objekte in unterschiedlichen Clustering sollten möglichst unähnlich sein -durchschnittlicher Abstand von Objekt zu Objekt in anderen Clustern: hier:zweinächster Cluster)
//不理解这后写得两个最近的簇表示的是神马意思
Silhouette-Koeffizient
a(o):
指簇内点o到簇内其他点得平均距离
b(o):
指簇内点o到离o第二近的簇内的点得平均距离
//为什么说是第二近呢??估计是把o所在的簇也算进去了吗
(Durchschnittliche Distanz zwischen o und Objekten in ‘zweitnächstem’ Cluster)
前面提到的距离函数dist(p,q)主要是针对单个数据对象的,现在把针对Cluster的距离函数补上:
single Link:
Complete Link:
Average Link:
Silhouette:
Silhouette的值域是:[-1,1]
当a(o)为0时效果最优,s(o)为1.反之当b(o)为0时,是最不受待见的这时s(o)=-1.当a(o)=b(o)时对应的s(o)为0,虽然他站在正中间,但这结果相信也是挺难接受的。
上面这个是针对对象o的Silhoutte值,下面来看一下针对簇的Silhoutte值: C‘=(C1,C2,...,Ck)
同样的这个Silhoutte的值域也是[-1,1]
根据S值的不同对聚类进行评价,一般情况下我们认为:
1. 0.7 < s < 1.0,结构化得很好
2. 0.5 < s < 0.7, 一般般
3. 0.25 < s < 0.5,有点弱啊
4. s < 0.25,完全没有感觉
对聚类算法的要求
必须是有效的而且是高效的并且能过处理含有比较大得噪音的高维的大型数据的聚类算法,而且这个算法应该在下面三方面具有很好的伸缩性:
1. 数据点得数量
2. 数据的维度
3. 噪音
/*
Effektive und effiziente Clustering Algorithmen für große hochdimensionale Datenbestände mit hohem Noise-Annteil erfordern Skalierbarkeit hinsichtlich Anzahl der Datenpunkte(N), Anzahl der Dimensionen(d),Noise-Anteil
*/
k-means聚类
把数据集划分为事先给定的数量的聚类
他的基本思想是:
1.为每一个类定义一个中点(Medoid)
//在Clustering中一般称为Medoid,但也就是均值的意思。他的官方解释是用作替代簇中重点得点。其实直接使用中点的话,可能照成误导,以为他是簇中的一个存在的一个点,其实不是,是通过计算后加进去的。
2.迭代循环调整这个中点//用新的代替旧的,旧的删了
3.优化的准则是使类内各点到其中点的距离的总和最小。
已知:
1.未分类的训练数据集X(这就是被说成是未监督的原因吧???),其中每个训练例子都含有d个属性:
x1=<attr11,..,attrdi>
2.想要分成的聚类的数量k
寻找的目标:
把训练数据分配到k个类中,并使得下式最小:
其中 cj 为各个类的中点
上式中直接用距离进行表述,比较正确的做法应该是用距离函数 d(cj,xji) 表示。但其实误差拉。
算法:
1.在d维空间中加入k个点 cj 作为k个类初始的中点。
2.直到 cj 不再改变或优化效率低时(这是循环条件),进行下面的操作:
重新把空间中的点分配到k个类中,分配方法如下:
3.计算求出新的中点,然后把旧的中点扔了:
评价:
1. 初始点所在的位置对结果有很大得影响
应对方法是相同的k下使用不同的初始,进行多次操作,
另外在选择初始的medoid的时候,应该尽量满足下面的条件,把不满足的点用其他Medoid代替:
*尽量的覆盖整个空间
*在进行下一个Medoid的选择的时候,应使其与前面选好得Medoids的距离足够远
*在选中的Medoid旁边应该有足够的数据点存在,一般我们认为,如果一个Medoid旁边的点得数量少于N/K*minDev时,那么这个Medoid就是挺糟糕的,最好把他换了。其中minDev是一个常数。
2. 结构依赖于度量 |x−cj| 。在高维的情况下会很难聚类。//???
3. 结果依赖于聚类的数量k
并没有标准的求k的方法,只能靠多次测试,寻找满足条件的结果了。但这也容易导致过拟合//??为什么呢???
CLARANS
用图表的方式描述上述的问题:每个节点表示一个Medoid的集合。直接相邻的两个节点表示的集合之中仅存在一个对象是不同的。
以下关于CLARANS的内容来自于百度百科,加上上面那句话,理解起来感觉还可以:
CLARANS是分割方法中基于随机搜索的大型应用聚类算法,他是在CLARA算法的基础上提出来的。与CLARA不同,CLARANS没有在任一给定的时间局限与任一样本。而是在搜索的每一步都带一定随机性的选取一个样本。CLARANS的时间复杂度是
O(n2)
。其中n是对象的数目。
此方法的优点是一方面改进了CLARA的聚类质量。另一方面拓展了数据处理两的伸缩范围,具有较好的聚类效果
他的缺点也比较明显,他的计算的效率较低,且对数据输入的顺序敏感,只能聚类凸状或球形边界
CLARANS的步骤
- 输入参数numlocal和maxneighbor。 其中numlocal表示抽样的次数, maxneighbor表示一个节点可以与任意特定邻居进行比较的数目。令i=1,i用来表示已经选样的次数,mincost为最小代价,初始时设为最大数
- 设置当前节点current为Gn中的任意一个节点
- 令j=1。j用来表示已经与current进行比较的邻居的个数
- 考虑当前的一个随机邻居S,并计算两个节点的代价差
- 如果S的代价较低,则current=S,转到步骤三
- 否则,令j++。如果j<=maxneighbor,则跳转到4
- 否则,当j>=maxneighbor, 当前节点为本次选样最小代价节点,如果其代价小于mincost,令mincost为当前节点的代价,bestnode为当前的节点
- 令i++,如果i>numlocal输出bestnode,运算终止。否则,转到步骤2
上面的终止判断有点机械,可以加上其他的终止判断准则。
Fuzzy-k-means-Clustering
在一般的k-means聚类中每个训练数据点都被唯一分配到一个类之中。在Fuzzy-k-means聚类中,并不把数据点精确的分给某一个点,而是用概率表示这个点和各个类之间的关系:
p(Xj|xi)
就表示i点属于j类的概率。当他为0的时候表示他们距离彼此很远,当概率为1时,就这个点刚好就在这个聚类的中点的旁边。
这个方法存在一个很大的问题就是,他每个周期的运行时间是O(kn)。
数据点i属于聚类j的概率可以由下式求得:
其中有:
//不理解为什么会长这样,另外b是啥??
另外有:
中心点得新的调整方法如下:
参数b控制,随之距离的变大点的影响的减弱速度
插一张自己也没看明白的图:
层次聚类
根据一个给定的相似度判断标准在多个层次对数据进行划分,并且使得低层生成的簇嵌套在高层的里面。
(Hierarchische Zerlegung des Datenbestands(unter Verwendung eines gegebenen Ähnlichkeitsmaßes)in Menge geschachtelter Cluster)
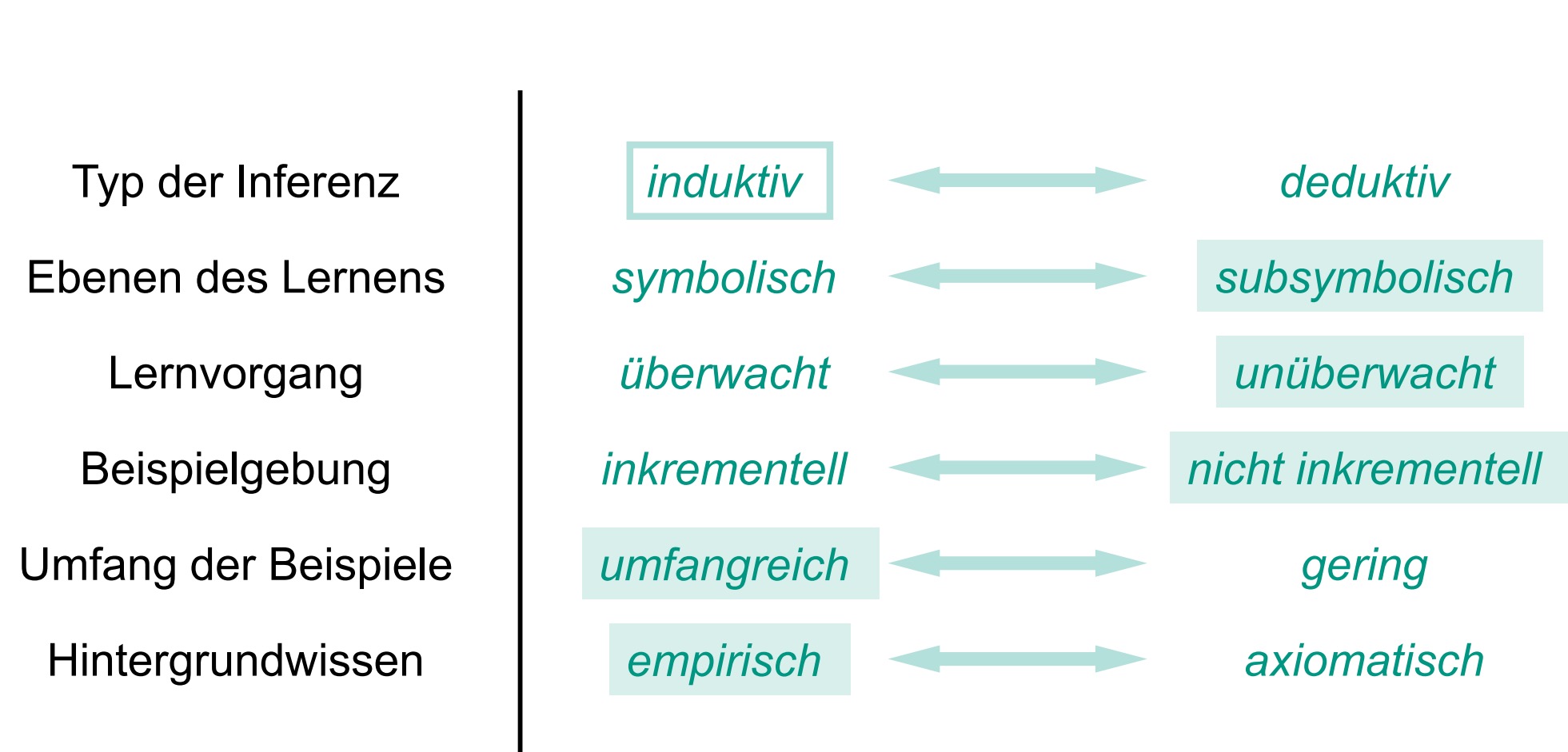
一般情况下我们可以用树状图(Dendrograms)对层次聚类的结果进行表示,其中每个节点表示一个可能的簇
我们可以使用从下往上的方法(bottom-up,agglomerative Ansätze),也可以使用从上往下(top-down, divisive Ansätze)的方法来构建这么一颗树。
针对层次聚类问题的主要思想是:
迭代合并低层聚类生成高一层的聚类
右边刻尺表示相似尺度。
根节点表示整个数据库,而相应的叶子节点表示单个数据点,每个内部节点表示他所对应的子树的数据的集合。
Agglomeration hierarchical Clustering
c=k//k为事先给定得
c'=n,D_i={x_i},i=1...n
DO
c'=c'-1;
Find nearest Clusters D_i,D_j;
Merge D_i and D_j
UNTIL [c==c' || d(D_i,D_j)>t]问题是:O(
n3
)!!!
文字解释:
1. 每一个对象都作为一个含有单个元素的簇
2. 计算任意两个簇之间的距离
3. 找出其中距离最小的两个簇A,B,并进行合并。把新的簇C加入簇的集合中,然后把旧的两个簇从这个集合中删了
4. 单C为集合中唯一的簇时,运算结束
5. 否则,计算C到集合内所有其他簇的距离。然后回到步骤三。
文字和程序的表述存在两个差异
1. 在终结判断上存在一点差异,程序上的方法是比较合理的。文字解释上得那个,就是本着让它能够停下来的想法去的。
2. 程序的时间复杂度是
O(n3),而文字说明的时间复杂度是
O(n^2),具体的是:$n^2+\sum^n_{i=1}(n-1)。造成区别的主要原因在于,程序中的方法,每个循环都要重新计算所有的距离。
虽然程序和文字解释在细节上存在区别,但是他们表达的意思是相同的。
(程序是机器学习的老师教得,文字部分是数据库分析的老师教的)
AHC距离
AHC距离:最邻近
//了解一下,真要用感觉还是前面提到的那个方法比较好
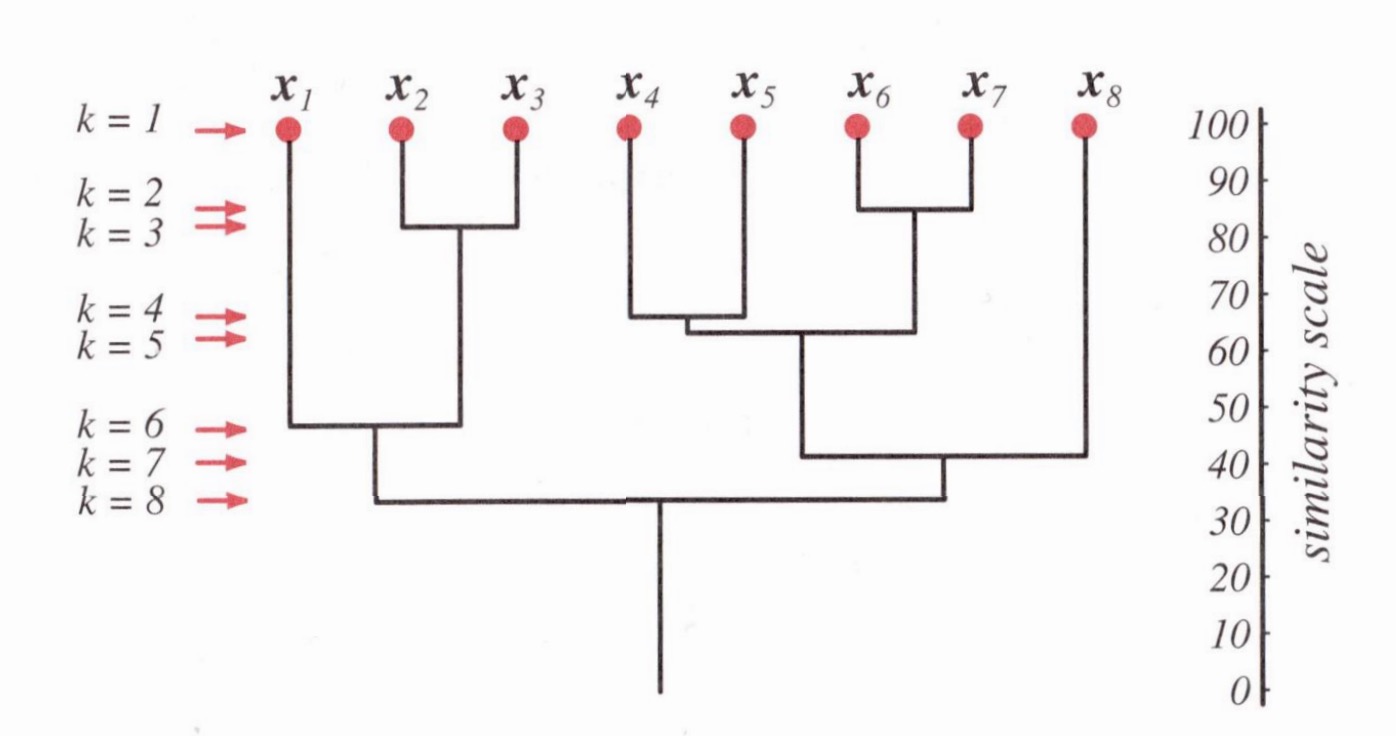
存在问题:
左边的分类基本正确,但是右边的因为一个噪音导致把两类合一了。
AHC距离:最远邻居
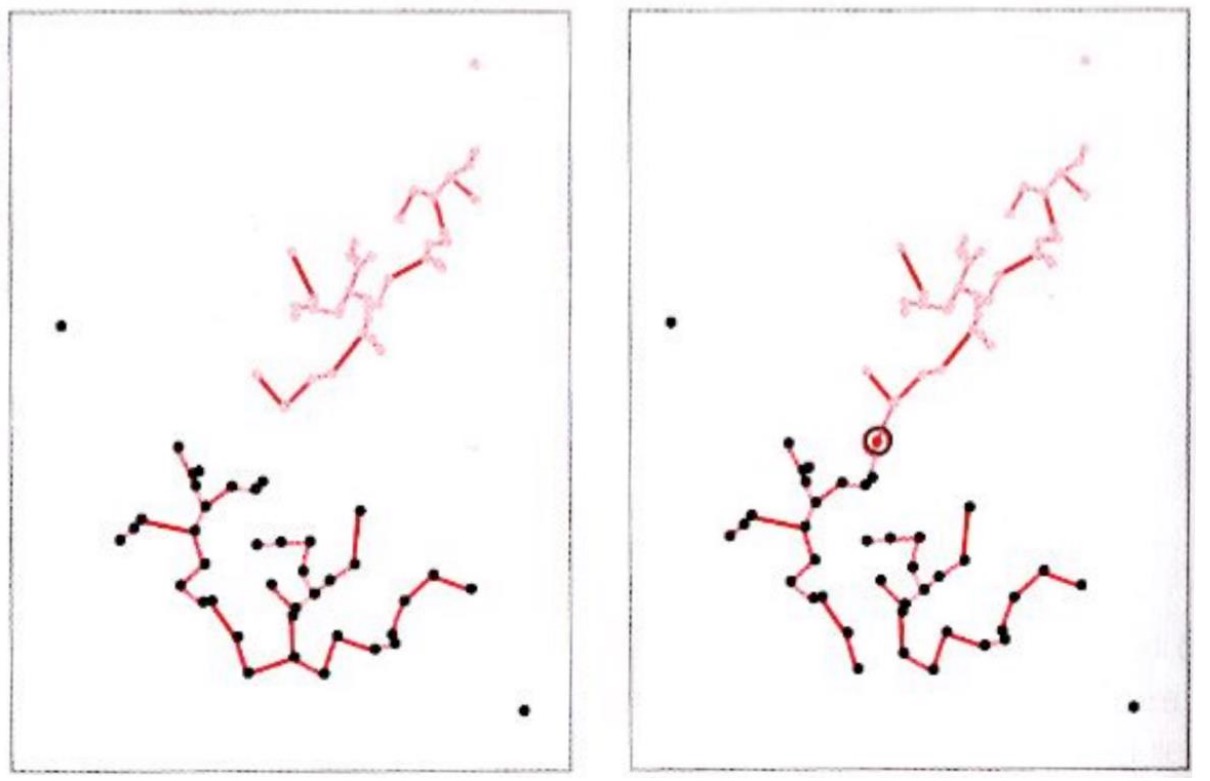
存在问题:
左边的阀值过大,右边的阀值过小
//其实没看明白是怎么错得????
对AHC的评价:
1.操作简单
2.当k未知时,效果比k-means好
(Besser geeignet als k-means Clustering, wenn k nicht bekannt, aber gewisse Aussagen über die Form der Cluster getroffen werden können(d,t))//不懂这句????
3.与初始值无关
4.需要找到正确的属性(Finden der richtigen Parameter nötig)//不是很有感??
5.对噪音比较敏感。
//然后又是一张关于AHC的没看懂的图:
Divisives hierarchisches Clustering
一般性的算法描述
1. 初始拥有一个由所有数据对象组成的簇
2. 重复下面的步骤,知道每个数据对象都对应一个单独的簇
*选择一个要分离的簇
*用分离后的子簇来代替前面选中的簇
那么现在有两个问题来了,首先进行分离的簇的选择的标准是神马(有差吗,不是单元簇不是都要进行分离吗??)。其次,就是要怎么进行分离
具体实现分离的方法有很多,下面介绍其中的一种方法:DIANA
DIANA
- 首先选择具有最大半径(Durchmesser)的簇C进行分离
- 然后从C中选出其中最偏僻的数据点o(通过比较簇内一点到其他所有点的平均距离来获得)
*SplinterGroup:={o}
*重复把所有满足下面条件的点o’加入到SplinterGroup中:
o’属于簇C但不属于SplinterGroup;
D(o’)>0;
其中:
D(o′)=∑oj∈C\SplinterGroupd(o′,oj)|C\SplinterGroup|−∑oi∈SplinterGroupd(o′,oi)|SplinterGroup|
讨论
//讨论的内容总是会保持原文的
Sowohl agglomeratives als auch divisives hierarchisches Clustering benötigen n-1 Schritte
Agglomeratives Clustering betrachtet im ersten Schritt n(n-1)/2 Kombinationen
*Divisives Clustering:
2n−1−2
Möglichkeiten, den Datenbestand zu splitten, im ersten Schritt.(DIANA betrachtet nicht alle Möglichkeiten explizit)//不该是
2n
-2吗??为什么是n-1次方???
Divisives Clustering ist konzeptionell anspruchsvoller, weil Vorgehen beim Split nicht offensichtlich.
Agglomeratives Clustering berücksichtigt lokale Muster.
Separierendes Clustering berücksichtigt die globale Datenverteilung. Dadurch eventuell bessere Resultate. //神马鬼
Birch算法
BIRCH表示:Balanced Iterative Reducing and Clustering using Hierarchies
//看这名字都比较像是层次聚类了,不知道为什么老师把他划分为划分聚类???
Birch的特殊点
在具体说它之前,先看一下他有哪些特殊之处:
1. 他需要构建模型,其实就是CF树,用来描述数据的分布
2. 他比划分聚类更加系统化//抽象啊,可以理解为效果更好吗??
3. 他对存储空间的需求比较少
BIRCH的属性
另外再看一下BIRCH算法的一些属性:
1. (I/O-Kosten wachsen linear mit der Größe des Datenbestands, wenn CF-Tree in Hauptspeicher passt.)这句理解不能????
2. 每次迭代都能够输出一个Clustering(不是Cluster)
3. 之所以不断迭代,是为了获得更优的Clustering(zusätzliche(optionale)Schritte liefern lesseres Clustering)
同样的希望的Cluster的数量也属于算法的一个参数(Anzahl k der gewünschten Cluster ist Parameter des Algorithmus)//是指作为结束的标志吗???
一些定义
在看具体的算法之前,还需要很多的准备,首先先认识一下下面的定义吧//里面有些就是换了个名字!!!
已知Cluster{
Xi−→
}
质心(Centroid)
半径(Radius)//感觉更像是标准差
直径(Durchmesser)//要怎么解释这个半径和直径的关系呢??这像是簇内两点的平均标准差
上面是一个簇内的情况,现在来看一下簇与簇之间的情况。
先约定有索引为1,…, N1 的点在簇1内, N1+1,...,N1+N2 的点在簇2内
//感觉老是换参考书了以前的话,果断就是用一个 ∈ 符号搞定,编课件的时候真得就不能再走点心吗??这看起来真心累啊
那么就有簇1和簇2之间的平均距离为:
D2 越小说明两个簇挨得越近,当他很小时两个簇也可能产生相交
CF树中的CF
CF代表Clustering Feature。在BIRCH中每个簇都用三个属性进行描述,也就是所谓的CF,他们是(N,LS,SS)。他们是目标簇的聚合信息(aggregierte Information)。
先看一下他们分别代表了什么内容:
*N代表着簇内点的数量
*LS为linear sum
*SS是square sum的意思:
那么为什么是这三个属性呢,他们有什么优势呢??
首先,通过这三个属性可以比较方便的计算前面提到的质心啊,半径啊,直径啊这些东西。具体方法自己琢磨。
其次,两个不想交的簇合并成一个簇时,新的簇的属性可以通过两个旧的簇的属性,很方便的计算出来。直接相加就是了。
CF树
CF树的属性
在研究怎么生成这颗树之前,先了解一下他的属性吧:
1. CF树是一颗高度平衡树
2. CF树的每个节点都代表一个簇
3. 如果节点B包含有节点A那么对应的簇A也就包含在簇B里面
4. 叶节点代表的是基本簇(Elementar-Cluster)。//注不是指只含有一个点的簇。他只含有CF数据(Blatt-Menge von Clustering Features.’Elementar-Cluster’)
5. 内部节点的数据结构和叶子节点的不同,他的存储形式是[
CFi,childi
],其中
CFi
代表
childi
的CF值,也就是说一个内部节点,他包含了指向儿子节点的指针,以及对应儿子节点的CF值。
CF树的参数
一颗CF树主要含有三个参数,他们分别是:
B - 指Fan-Out(针对内部节点)
B’ - 指叶子节点的容量(Kapazität eines Blatts)//这个不是很了??感觉没必要吧???
T - 指直径或半径的阀值。一个基本簇的直径或半径必须小于T
假设没有T会怎么样呢??
Ansonsten würden nur Füllgrad der Knoten Struktur des Baums ‘steuern’
Entfernte Punkte so stets in unterschiedlichen Blattknoten.Besseres Modell.
往CF树中增加节点
- 这些节点会被分配到理他最近的节点上(通过计算该节点到对应节点质心的距离)(就像B+树一样//对此表示不懂??)//所以这是只看叶子节点对吧??
- 假如找不到适合的叶子节点(由于阀值T的原因),那么该新加入的点将自己组成新的叶子节点,加入到树中。
- 当一个簇太大时(比如他含有太多的子簇),他将进行分裂。
另外加入节点的时候,应该从根部出发逐个节点的比较,当找到适合的时候,就把他加入这个节点,然后继续向下看,直到比完叶子节点。感觉有点怪,好像只比较叶子节点,加入后一路往上修改CF,感觉更方便。估计是我上课听错了吧???还有如果新加入的点到两个节点的距离相等,而且小于T呢???
另外新加入的点的信息并不会存储到节点中,只是对原节点中的CF值进行修改。(Kapazität der Blätter erschöpft sich kaum???所以前面的B‘参数究竟是干嘛用的??)
分裂节点
1.把相互距离最远的两个点作为新的节点的质心
(Die am weitesten voneinander entfernten Punkte sind die Seeds)
//按道理内部节点记录的应该是子节点的信息,也就是说上面所谓的节点指的其实是各个子节点的质心了???那如果是叶子节点内部满员了怎么办???
2.把其余的点分配到离得比较近的节点
3.Sobald Knoten, der einem Seed entspricht, voll wird anderer Knoten einfach aufgefüllt.这句话表示不理解???
从上面也可以看出在分裂节点的时候,我们并不需要具体的点的信息,而只是使用了CF属性。这也使得他可以处理比较大得数据
(BIRCH arbeitet nur mit aggregierten Werten, damit möglichst viel im Hauptspeicher ablaufen kann.)
节点分裂对应存在的问题
问题是,节点分裂与否只和它是否满员了有关,而与具体的当时的聚类的质量无关。
比如下面这张图中的情况,他分裂后能长得很丑
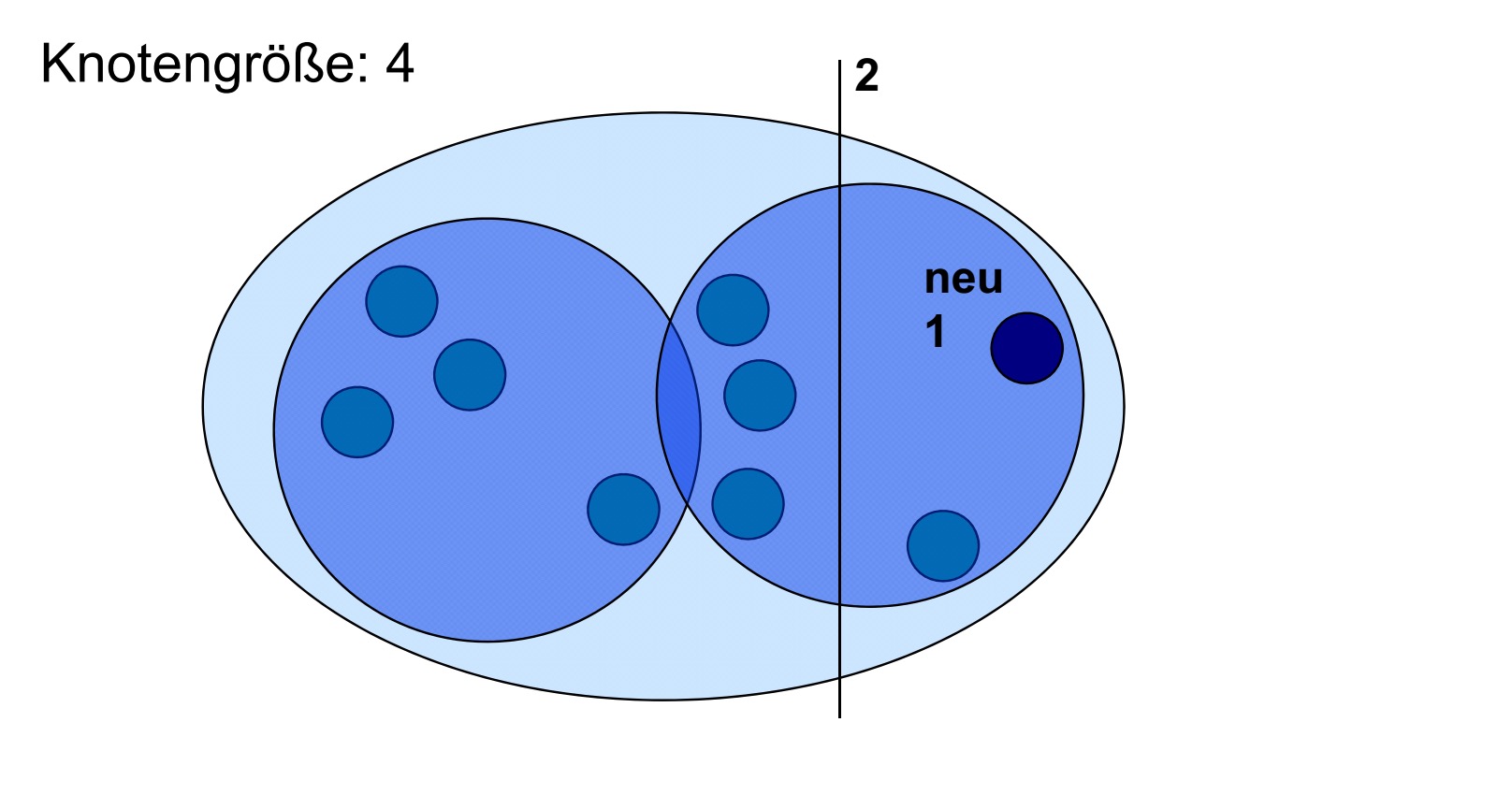
B等于四,新加入的节点使它必须进行分裂。但分裂后很丑不是吗,中间四个点明明应该分一起才比较好啊。针对这种问题,我们采取的方法是融合(Merge)再分裂法。
Merg
*Merg直接发生在分裂之后
*我们观察分裂后获得两个新的节点的所有的孩子节点(Wir betrachten die Kinder des Knotens, der zwei neue Knoten nach Splitting enthält)
*我们把相互距离最近的两个子节点进行合并(如果他不是刚分裂出来的两个节点的话)
//从这里应该可以看出内部节点中除了子节点之外,还应该保留有属于自己的CF值
*然后我们把合并后的节点重新进行分裂。然后重复吧。
BIRCH算法
- 构建CF树
- 通过全局聚类算法重新调整所有叶节点中的子簇
//不知为何需要这一步骤,上面的全局聚类算法应该是指前面提到的方法????比如新建叶节点的时候,可能已经存在的某个节点,相对于旧的簇的质心,他离新的节点的质心比较近,而这种情况,在建树的时候是没有考虑在内的。
/Neuanordnung der Subcluster in den Bl’ttern durch globalen Clustering-Algorithmus(wegen Skewed Input und Splitting gemäß Page Size).Illustration:Ausreißer ‘neben’ Cluster, Abstand < T./ - 把得到的簇的质心作为中心,重新分配数据点
//这个不是包含在前面那步里面了吗???
(Centroide der Cluster als Seeds, Neuverteilung der Datenpunkte)
因此在这里我们应该明白,生成的CF树,并不是作为一个结果,而是应该对它进行进一步的处理。
讨论
Idee, räumliche Indexstruktur beim Clustering zu verwenden, nicht auf partitionierende Verfahren beschränkt.
*DBSCAN tut es
*Beschleunigung von LOF so ebenfalls möglich
Räumlicher Index ist kompakte Zusammenfassung des Datenbestands hier also hilfreich
高维数据聚类
高维数据带来的问题
前面介绍的方法一般适用于维度不高的情况,在少于10个属性时,其运行效果比较好。而在高维空间中,这种距离的度量可能就会没有效果。
那么高维数据都会带来哪些问题呢???
1. 首当其冲得就是前面说到的一些具体的聚类方法了
*zu geringe Dichte mit Dichte-basierten Ansätzen
*es ergibt sich keine sinnvolle Strukturierung der Daten mit hierarchischen Verfahren
//这是两个例子,不是很懂
2. 除了1之外还有一些问题,他们在一般的聚类中已经存在,但是在高维数据中,这个却问题得到了升级。
*应该首先找到用于生成簇的维度
*不能事先对维度进行剪枝
(Problem, das im Hochdimensionalen mehr Gewicht hat:
Dimensionen, in denen Punkte Cluster bilden, müssen erst einmal gefunden werden.
Dimensionen können nicht apriori gepruned werden)
//其实两个问题都不是很了解
//一下对于问题部分的描写来自《数据挖掘:概念与技术》
在高维空间中,传统的距离度量可能没有效果。这种距离度量可能被一些维删得噪音所左右。因此,在整个高维空间上得簇可能不可靠,而发现这样的簇可能没有意义。
那么,高维数据上什么样的簇才是由意义的呢?对于高维数据聚类分析来说,我们仍然想把相似的对象聚在一起。然而,数据空间常常太大,太混乱。另一个挑战是,我们不仅仅需要发现簇,而且还要对每个簇,找出显露该簇的属性集。换言之,高维空间中的簇通常用一个小属性集,而不是用整个数据空间定义。本质上,聚类高维数据应该返回最为簇的对象分组(与传统的聚类分析一样);此外,对于每个簇,还要返回刻画该簇的属性集。(这对应了下面PROCLUS的输出)
面对高维数据的聚类通常使用的又四种方法,分别是:
1. Subspace clustering
2. Projected clustering
3. Hybrid clustering
4. Correlation clustering
//课上老师只讲了第二种方法,但是在他推荐的书上,除了第二种方法,其他的方法都讲了。所以他的意思很明确了。。。。
Projected Clustering
问题描述
输入:
1. 簇的数量k
2. 每个簇的平均维度
//不是很了,为什么是平均?也就是说每个簇的维度还能是不同的了???
(M.E. etwas willkürlich, dass der Benutzer diese Parameter vorgeben muss, ist aber bei diesem Verfahren so.)不知缩写是何意??
输出:
1. 把数据分成k+1个集合(多出的一个是给噪音的)
2. 每个簇i对应的一个所有维度的子集
//我还是去前面补点东西吧
PROCLUS算法流程
先认识一下PROCLUS算法的大概流程
1.确定初始的Medoid集
2.确定每个Medoid对应的维度
3.把数据分配到最近的Medoid中
4.重新计算Medoid集
5.无优化则停止,否则跳转到步骤2
//neuer Schritt muss jenes I Kriterium berücksichtigen这里的I标准表示不认识???
下面来看看具体的实现细节
确定一个Medoid对应的维度
在确定Medoid集之后,会为每一个Medoid选择其对应的维度集。
(Unterschied zum bisherigen Verfahren:Zu jedem Medoid Menge von Dimensionen explizit wählen(in jedem Schritt neu, nachdem Medoide ermittelt wurden))//不知道这里的explizit表达的是神马意思
确定 Li
我们用
Li
表示靠近Medoid
mi
的点(L代表local的意思),我们通过下面的方式来定义这个
Li
:
*
δi=mini≠j(dist(mi,mj))
*
Li
就是指到点
mi
的距离比
δi
小的点得集合
//看见了上面还是使用了原来的dist函数,这样没问题吗??
特殊情况下,
Li
可以为空
//这种情况是不是就是对应了没有属于这个
mi
的维度,也就是说这个
mi
最好还是换了比较好???
计算 Xij
计算每个维度j中,
Li
中的点得
∅
距离
Xij
//
∅
距离好像就是指各维上L中点到对应Medoid的阿基米德距离之和。不是很清楚啊???
计算 Yi
Yi
代表的是
Xij
的中值,其中i代表的是簇i。
确定一个Medoid对应的维度
当
Xij−Yi
为负数时,我们就说维度j杜宇Medoid
mi
来说是重要的。否则则是不重要的。
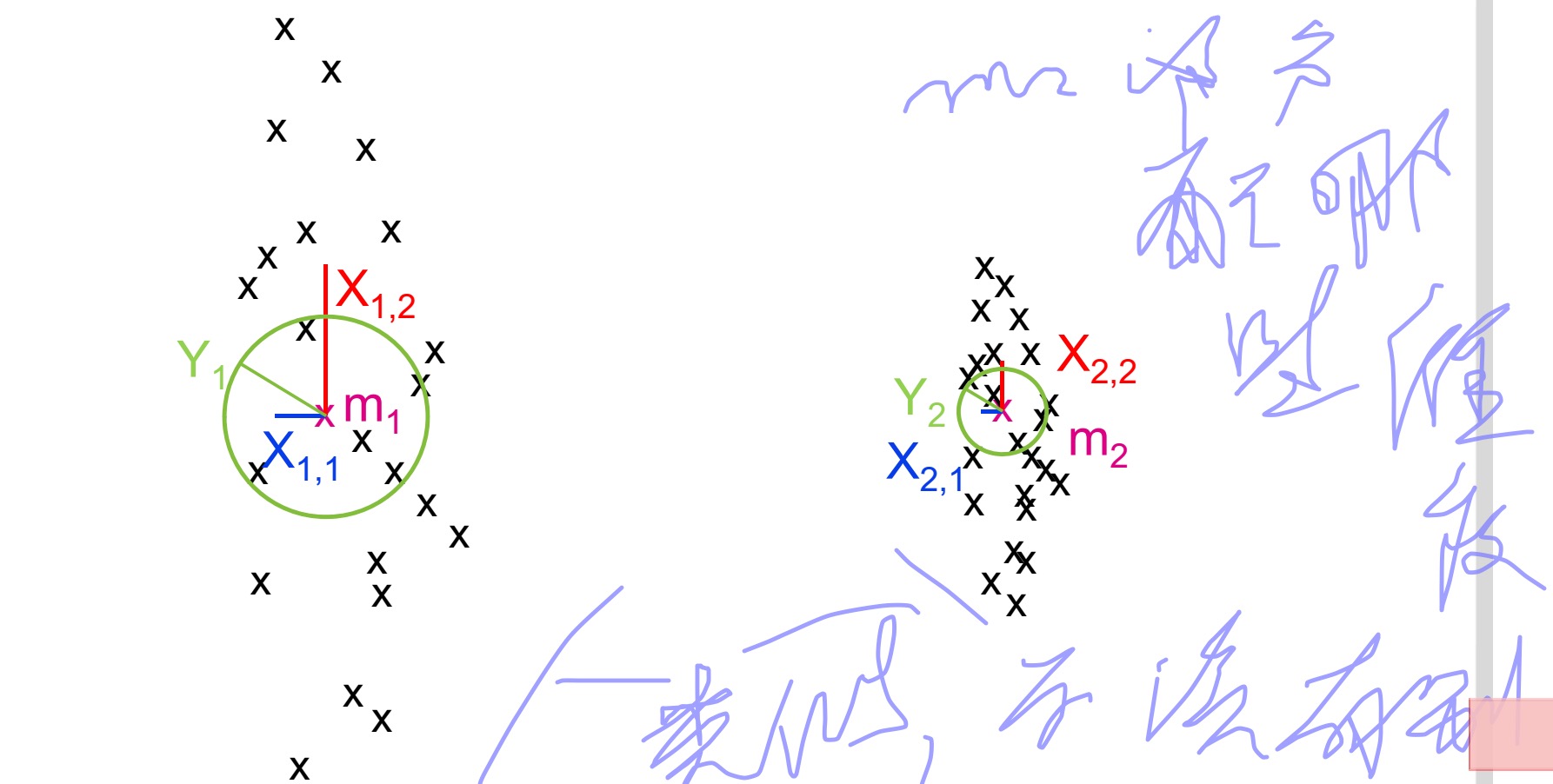
在给定I的条件下,怎么分配维度呢
I指的是每个簇维度的平均数量。
前面我们计算了
Xij和Yj
, 但现在我们对这个确定的
Xij
和差值并不感兴趣,因为我们给定了一定数量的I,所以我们现在更感兴趣的是这个维度上的
Xij
相对于均值的偏差(Interessant sind aber nicht absolute X werte bzw. Differenzen, sondern relative Abweichung vom Durchschnitt.)
因此我们对标准差进行了如下定义:
//不是d维吗,为什么会是初一d-1呢???
接下来我们计算(Jetzt Vergliech der Differenz für unterschiedliche Cluster Hierzu Zij berechnen)
当标准差越小时对应的Z值越大(Wenn Standardabweichung klein, dann ist Z-Wert tendenziell groß)
对Z进行排序,根据需求取出对应的维度
确定簇
计算每个数据点到各个Medoid的曼哈顿距离(Manhattan Segmental Distance),并把数据点分配到离他醉经的Medoid上。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









