






伪分布式大数据Hadoop安装
文章目录
一、准备工作
1. 查看防火墙运行状态
firewall-cmd --state

- 关闭防火墙及开机自启
systemctl stop firewalld.service
systemctl disable firewalld.service

2. 配置主机名
- 主机名在安装的时候修改过,可以查看主机名
hostname

- 修改
hostnamectl set-hostname tgm(你的主机名)
3. 修改hosts
vim /etc/hosts
- 追加内容
10.10.10.100 tgm
4. 配置免密登录
- 生成公钥和私钥
ssh-keygen -t rsa
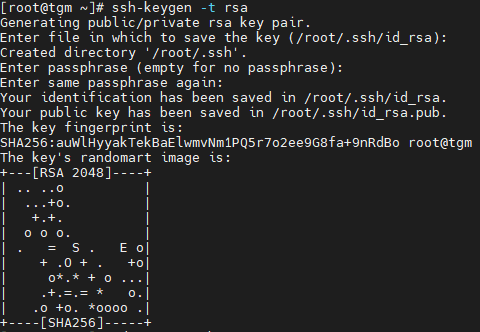
- 进入到 目录
cd /root/.ssh
- 拷贝公钥文件(自己免密登录)
ssh-copy-id tgm
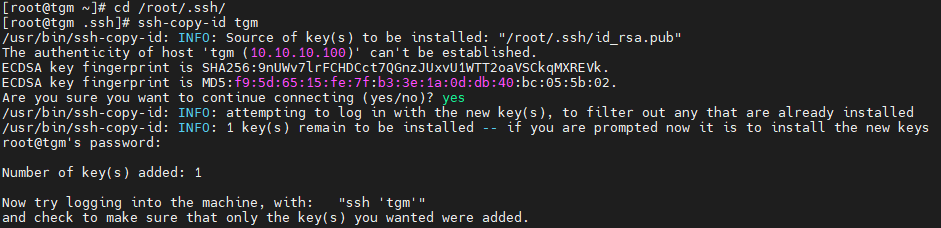
- 检查是否成功
ssh root@tgm

成功登录。
二、安装Hadoop准备
1. 卸载OpenJDK
yum remove *java*
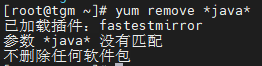
最小安装没有java
2. 上传安装包
把Hadoop、jdk上传到/opt/software下
使用MobaXterm上传文件(也是这个ssh连接的)
使用说明见文章MoaXterm(远程连接与文件传输工具)介绍
3. 解压
tar -zxf jdk-8u11-linux-x64.tar.gz -C /opt/modules/
tar -zxvf hadoop-3.3.3.tar.gz -C /opt/modules/
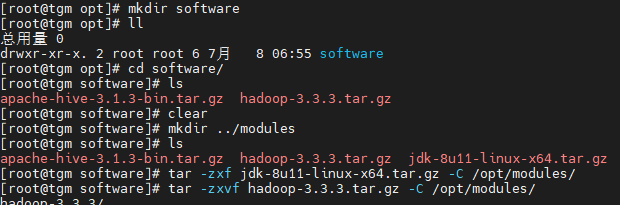
- 查看一下,ok
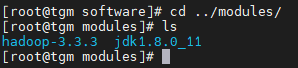
4. 配置环境变量
Linux的环境变量配置文件的路径:/etc/profile ,如果对该配置修改不当,可能会造成系统的其他指令无法正常执行。 在 /etc/profile.d/ 新建一个 my_env.sh 配置文件
vim /etc/profile.d/my_env.sh
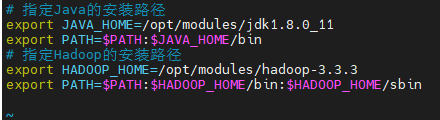
- 刷新配置
source /etc/profile
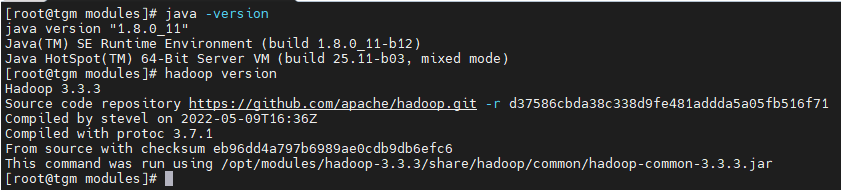
- 使用
java -version和hadoop version进行查询是否成功
三、hadoop伪分布式部署
hadoop的自定义配置文件保存在了 ${HADOOP_HOME}/etc/hadoop/ 目录下。
我们需要配置的配置文件有:
hadoop-env.sh:指定Java路径和使用hadoop时的用户名
core-site.xml:指定namenode地址和数据保存目录
hdfs-site.xml:指定数据块副本数量、NameNode和SecondNameNode的web访问地址、关闭权限检查
mapred-site.xml:指定MapReduce作业使用 Yarn资源协调框架
yarn-site.xml:指定MapReduce程序之间数据传递方式、ResourceManager地址
1. 进入hadoop自定义配置文件目录
cd /opt/modules/hadoop-3.3.3/etc/hadoop/
2. 配置hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_11
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3. 配置core-site.xml
vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定NameNode地址和端口号-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://tgm:9000</value>
</property>
<!--指定数据保存目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-3.3.3/data</value>
</property>
</configuration>
4. hdfs-site.xml
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定数据块的数量为1(伪分布式安装时只有一台DataNode,所以副本数量需要设置为1)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--关闭HDFS权限检查-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--指定NameNode的web访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>tgm:9870</value>
</property>
<!--指定SecondaryNameNode的web访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>tgm:9868</value>
</property>
</configuration>
5. 配置mapred-site.xml
vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定MapReduce作业运行在YARN组件上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--指定历史任务访问的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>tgm:19888</value>
</property>
<!--指定历史任务服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>tgm:10020</value>
</property>
</configuration>
6. 配置yarn-site.xml
vim yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!--指定MapReduce任务使用shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tgm</value>
</property>
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--指定日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>tgm:19888/jobhistory/logs</value>
</property>
<!--设置日志保留时间 7 天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
7. 格式化NameNode
hdfs namenode -format
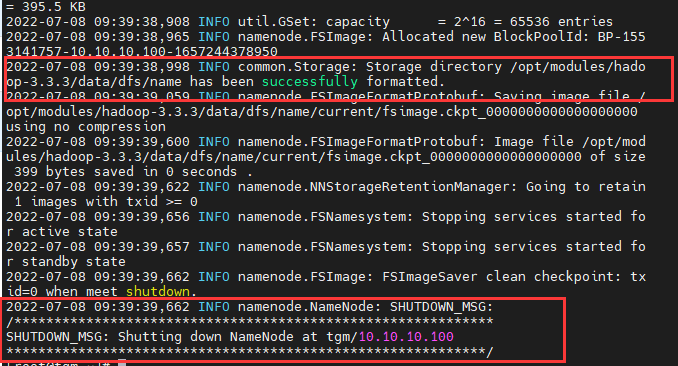
8. 启动
下面是有关Hadoop的启动、暂停指令:
start-all.sh 同时启动 HDFS和Yarn组件;
stop-all.sh 同时暂停 HDFS和Yarn组件;
start-dfs.sh 启动HDFS,
start-yarn.sh 启动yarn组件;
stop-dfs.sh 暂停 hdfs,
stop-yarn.sh 暂停yarn组件
mapred --daemon start historyserver :启动历史任务服务器
mapred --daemon stop historyserver :暂停历史任务服务器
start-all.sh
mapred --daemon start historyserver
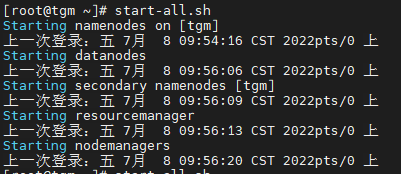
9. 解决问题
如果格式化失败了,可以回到hadoop中的时候,然后删除data目录重新生成。
四、成功检查
1. JPS
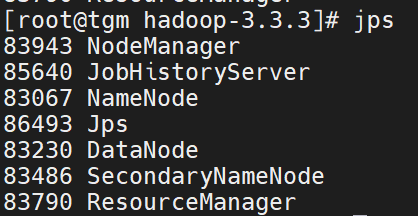
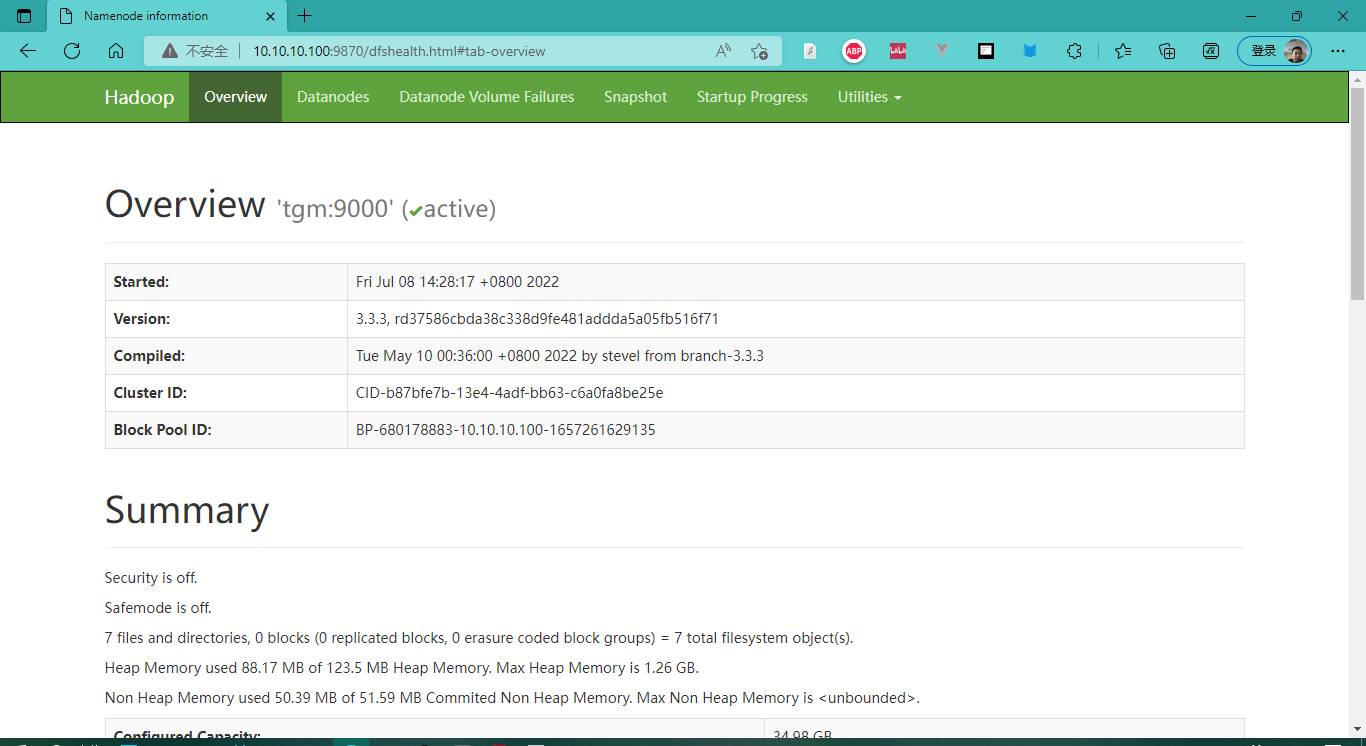
2. 浏览器访问
- 虚拟机IP:9870 :在浏览器中访问 NameNode
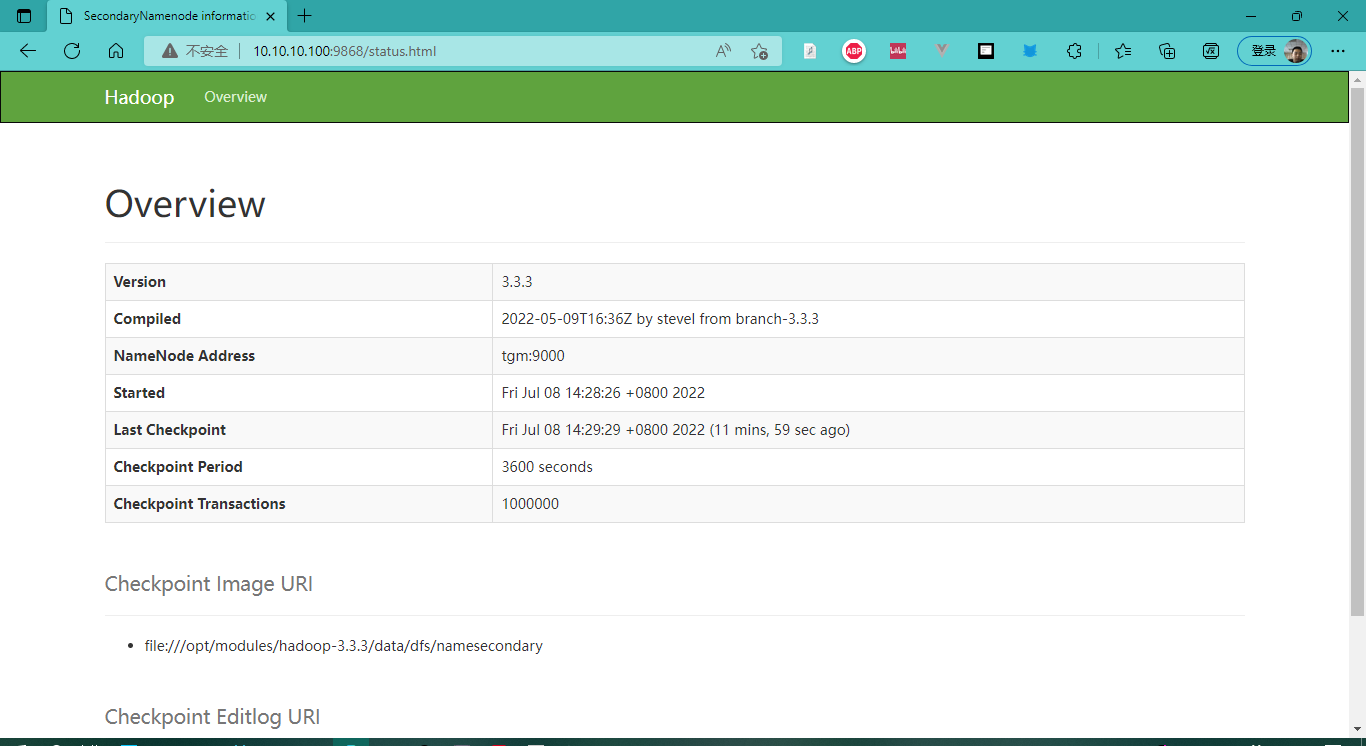
- 虚拟机IP:9868 :在浏览器中访问SecondaryNameNode
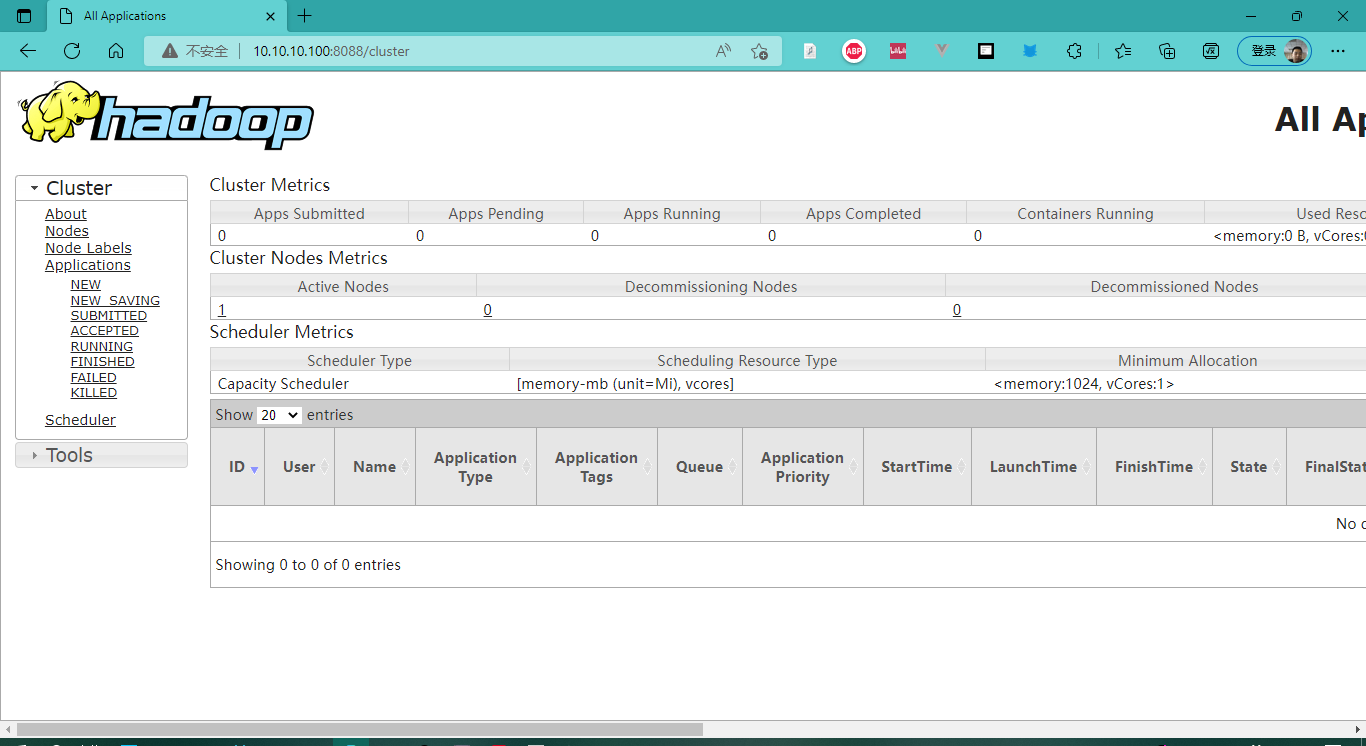
- 虚拟机IP:8088 :在浏览器中访问Yarn组件
- 虚拟机IP:19888 :在浏览器中访问历史任务服务器。
NameNode
SecondaryNameNode
Yarn
历史任务服务器

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









