






文章目录
前言
Hadoop伪分布式安装在前文Hadoop单机安装基础上进行。
一、Hadoop伪分布式安装
1.Hadoop配置文件
首先修改两个配置文件,分别是core-site.xml文件和hdfs-site.xml文件,进入到hadoop目录下的etc/hadoop目录,执行下面的操作。
修改core-site.xml文件,添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改hdfs-site.xml文件,添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
value值指定了数据块的备份数量,在伪分布式模式下,因为只有一台机器,所以设置为1即可。
修改 mapred-site.xml文件,添加内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml文件,添加内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
2.格式化namenode
hdfs namenode -format
格式化成功后的提示:

3.启动
./sbin/start-dfs.sh
启动完成后:

二、Hadoop集群的组成
伪分布式的hadoop集群其实就两大核心组件构成:
- HDFS
- MapReduce
回顾一下上面启动hadoop后我们用JDK的JPS命令看到的JAVA进程:

可以看到一共有三个东西:
- secondNameNode
- DataNode
- NameNode
这三个东西是属于HDFS的,dataNode是具体存放数据的节点,nameNode用来记录所有dataNode的信息,secondNameNode是nameNode的备份:
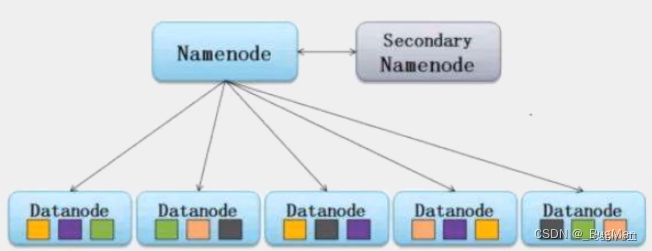
以上是节点在HDFS维度扮演的角色,除此之外节点还在MapReduce维度扮演有角色,MapReduce在跑一个大的任务的时候会把节点分为两类:
- jobTracker,负责总的来协调位于不同节点的小任务,将多个小任务的计算结果汇成最终的结果。
- taskTracker,dataNode节点上跑的小任务。















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









