







笔记整理:刘一春,天津大学硕士,研究方向为规则学习、自然语言处理
链接:https://aclanthology.org/2023.emnlp-main.138.pdf
1、动机
文档级关系提取(DocRE)旨在提取文档中实体对之间的关系。一些工作将逻辑约束引入到DocRE中,解决了原始DocRE模型中不透明和逻辑性弱的问题。然而,它们只关注正向逻辑约束,同时这些工作中挖掘的规则经常受到置信度高但支持度低的伪规则影响。在本文中,我们提出了 Beta 规则双向约束(BCBR),一种新颖的逻辑约束框架。BCBR 首先引入了一个新的规则挖掘器,它通过 Beta 分布对规则进行建模。然后根据Beta规则构建正向和逆向逻辑约束。最后,BCBR通过双向约束重构规则一致性损失来调节DocRE模型的输出。实验表明,BCBR 在关系抽取性能方面与逻辑一致性方面优于原始 DocRE 模型(2.7 F1分数与3.1 逻辑分数)。此外,BCBR 始终优于其他两个逻辑约束框架。
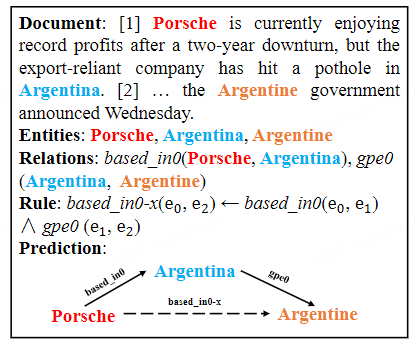
图1. 逻辑规则约束文档级关系抽取示例
2、亮点
BCBR的亮点主要包括:
据我们所知,本文是第一个提出利用 Beta分布建模规则学习的工作。
本文引入了逆向逻辑约束来确保 DocRE 模型的输出满足规则的必要性。
本文将双向逻辑约束建模为合理的概率模式并将其转变为规则一致性损失。
实验表明 BCBR在关系抽取性能和逻辑一致性上都优于LogiRE和MILR。
3、概念及模型
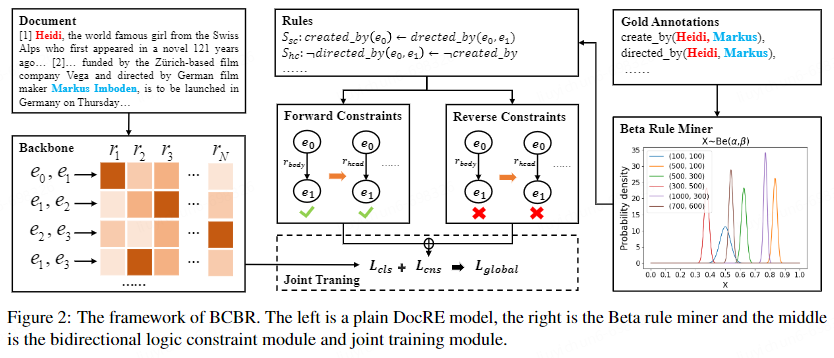
(1)Beta规则抽取
知识图谱的规则挖掘方法主要基于知识图谱大规模、数据密集的本质。然而,当这些方法转移到文档数据时,它们仍然依赖于置信度来过滤规则。这就导致了存在大量标准置信度高但支持度低的伪规则的不适应现象。因此,我们放弃单独使用置信度或支持度的方法,而是使用Beta分布来建模规则。在本节中,我们提出了一种新的规则挖掘方法,称为Beta规则。我们通过每条规则的Beta分数积分来衡量规则的质量。公式如下:
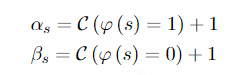
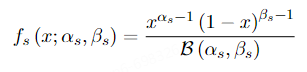
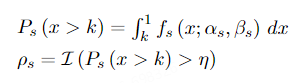
(2)双向规则约束
我们利用上述规则对DocRE任务施加约束。然而,以前的方法仅采用从 rbody 到 rhead 的前向逻辑约束。由于规则体原子的不确定性,他们无法利用从 rhead 到 rbody 的反向逻辑约束。BCBR基于头部覆盖规则对反向逻辑约束进行建模,从而补偿约束条件的损失。
正向规则约束
高标准置信度规则中存在正向逻辑约束。当rbody出现,rhead也同时出现时,则认为满足正向向逻辑约束。 反之,如果没有发生rhead,则认为不满足正向逻辑约束。 它代表了 rbody 对 rhead 的充足性。我们对前向约束的理想形式进行建模如下:
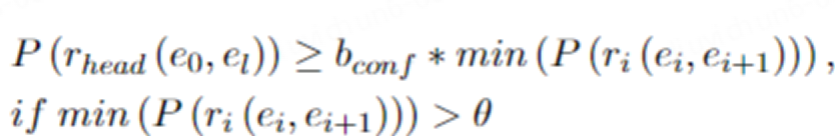
逆向规则约束
高头部覆盖规则中存在反向约束。当rhead存在时,如果rbody也存在。它被称为满足逆向约束。相反,如果rbody 不存在,则被视为不满足逆向约束。它代表了rbody对于rhead的必要性。反向约束与正向约束的规则形式不同,因为它从rhead导出rbody。rbody包含多个不确定的体原子,但连接三元组的实体可能不存在。合取规则则要求在构建约束概率模型时考虑每个三元组。 因此,我们将德摩根定律用于原有的规则模式,并得到如下面公式所示的析取规则,该规则指出,如果任何体原子不存在,则rhead不存在。这种形式方便我们对规则建模。我们对逆向向约束的理想形式进行建模如下:
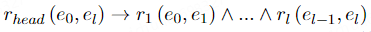
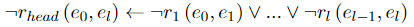
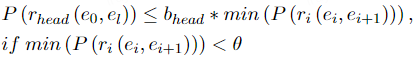
(3)规则一致性损失
除了骨干模型原有的关系分类损失之外,我们还基于beta规则的双向约束构建了规则一致性损失。这个损失与关系分类损失联合训练一起提高关系抽取的逻辑一致性和性能。规则一致性损失源自beta规则的双向约束,由两部分组成:高标准置信度规则产生的正向损失和高头覆盖率产生的逆向损失。 损失函数的公式如下:
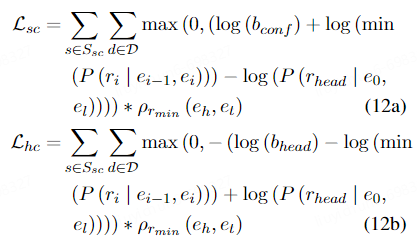
4、实验
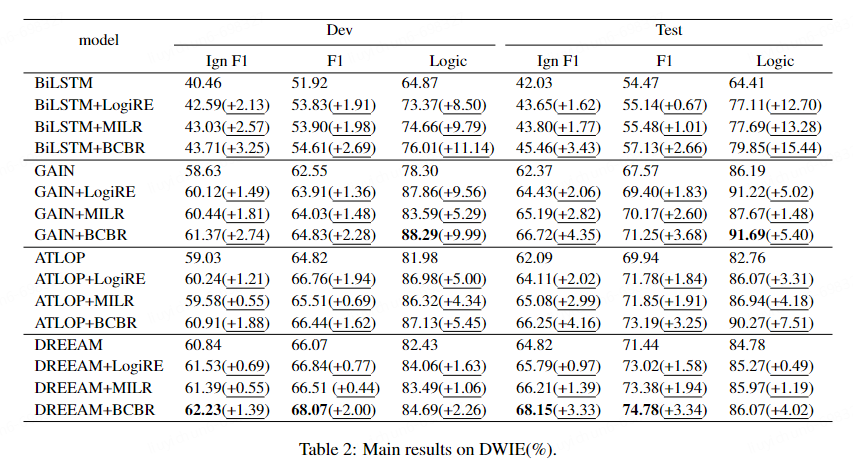
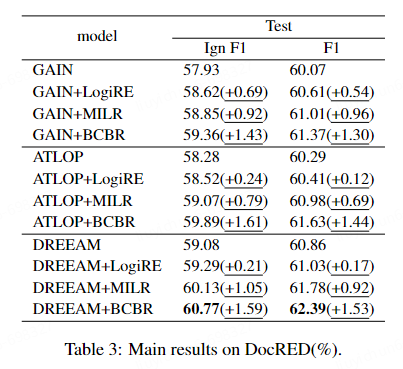
为了证明我们方法的有效性和优势。我们在三个数据集上采取了多个Baseline进行了实验。实验结果如下:
同时我们也在inductive场景下对问答任务进行测试。

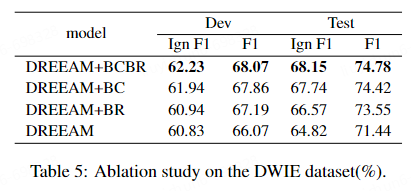
为了证明每个模块的有效性,我们做了消融实验,其中BC是逻辑一致性模块,BR是Beta规则抽取器模块。
下面是案例学习与以及与大模型的区别,点出了在大模型时代下规则学习的意义。

5、总结
在本文中,我们提出了一种新颖的逻辑约束框架BCBR,它利用Beta规则的双向逻辑约束来调节DocRE的输出。我们率先提出使用Beta分布对规则进行建模,有效解决了伪规则的问题。然后,我们对反向逻辑约束进行建模,并利用 Beta 规则的双向约束来构造规则一致性损失。通过与关系分类损失联合训练,我们提高了 DocRE 的性能。多个数据集上的实验结果证明 BCBR 优于基线模型和其他逻辑约束框架。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。














 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









