







导读
OpenKG新开设“TOC专家谈”栏目,推送OpenKG TOC(技术监督委员会)专家成员的观点文章。本期邀请到北京邮电大学石川教授介绍在图基础模型方面的一些探索,本文整理自石川老师在“OpenKG走入苏大”Talk上的分享。
本报告介绍将图学习模型与大型模型融合的基本方法。一方面,应对图神经网络目前面临的挑战;另一方面,利用图技术手段优化大型模型的表现。本文简要介绍了石川教授团队在此领域开展的初步探索工作。
图基础模型

首先,“图基础模型”大概是在2021年由斯坦福的学者提出来的概念,它是在广泛的数据上训练,而且被应用于广泛的下游任务的一个模型。比如:语言模型、视觉模型还有语音模型,实际上都是基础模型的一个具体体现。
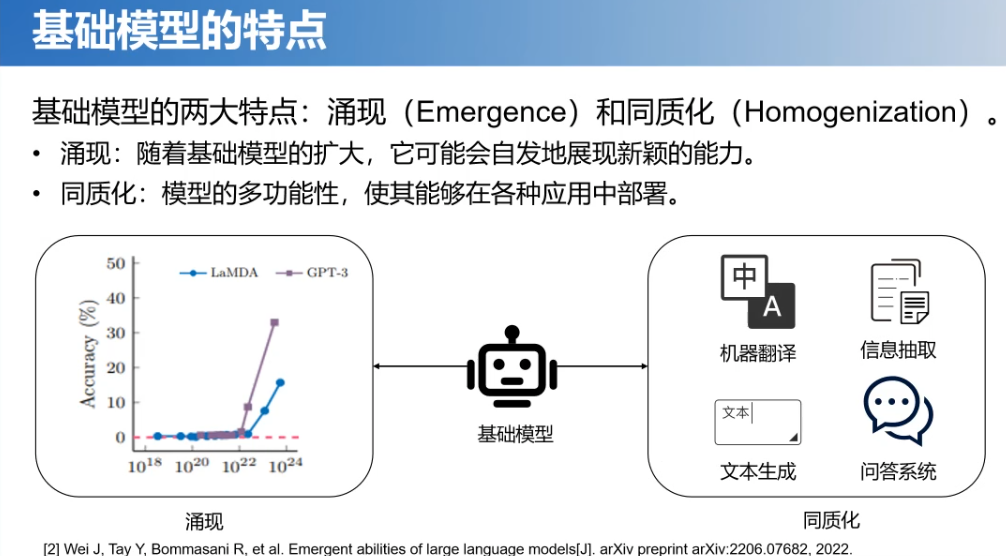
那么,基础模型这个概念具有两大特点:
1.涌现:是说随着这个基础模型的扩大,它可能会自发地展现一些新颖的能力。这一点,我们通过ChatGPT和Sora等等一些模型可以看到通用人工智能的曙光。现在也是流行一个“规模法则”,意思是当一个模型的数据量足够大的话,就会产生一些意想不到的,或者说新的推理能力。
2.同质化:就是说模型的这种多功能性,使其能够用在各种应用中。以前,我们不管是做数据挖掘还是做自然语言,就是针对具体的问题,设计专门的模型。很多做研究的都是各做各的,可以说是“井水不犯河水”。现在有了基础模型之后,一个模型能做所有的事儿,这就是基础模型同质化的能力。
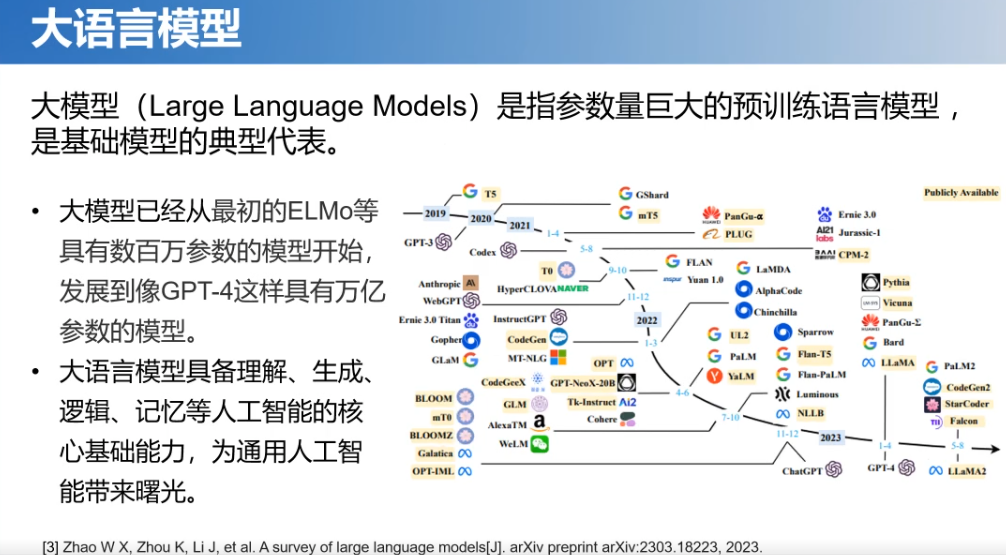
其实,大模型就是基础模型的一个典型代表,是指参数量巨大的预训练语言模型。目前大模型已经从最早的百万参数,发展到现在像GPT-4这种万亿参数了。现在大模型具备理解、生成、逻辑、记忆等人工智能的核心基础能力,也为通用人工智能带来曙光。而且不仅仅是大语言模型,还有多模态模型等都展现了强大的能力。
另一方面,我主要是研究图数据的智能分析。那么图的话,它不仅是一种通用的建模方法,而且是广泛存在的一类数据。我们知道图是用来建模复杂系统的一个通用语言,只要有点和边,并且存在这种交互,我们都可以用图来进行建模。比如像:社交网络、金融网络、生物医药网络等等这种现实中的系统都可以用图来进行建模。
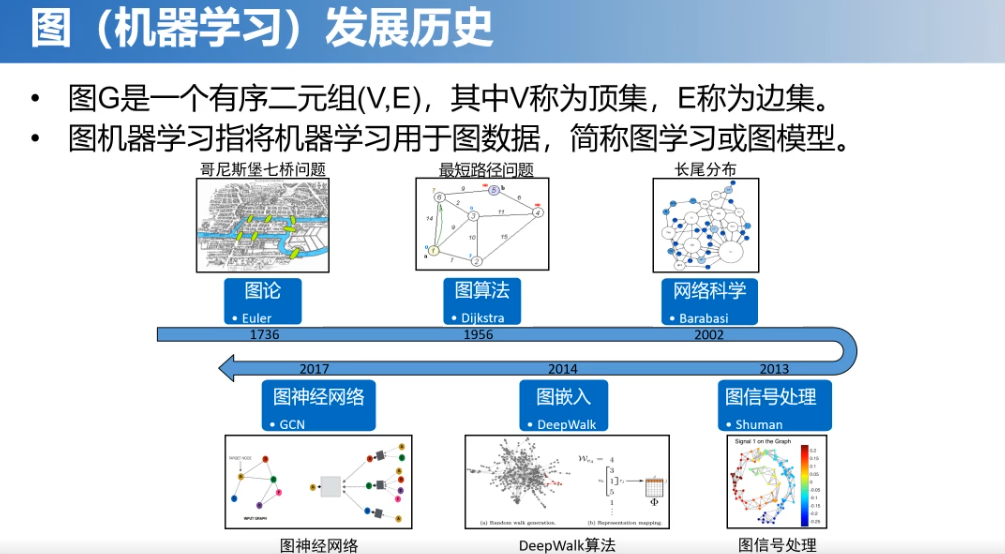
图的定义其实很简单,就是由点和边构成的。而对图的研究也是有很长的历史,从最早的哥尼斯堡七桥问题提出的图论的研究,到各类图算法,再到本世纪初的网络科学。其实图一直都是一个研究热点,特别到近些年的图嵌入和图神经网络。
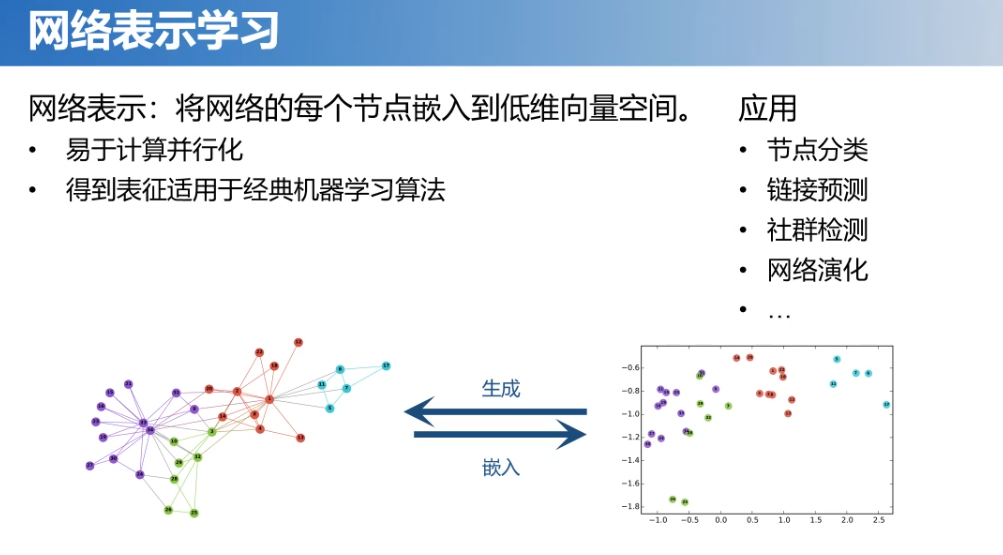
那么,近些年对图的研究热点主要是网络表示学习。它是将网络中的节点应用到低维向量空间,通过这个向量可以易于计算并行化,而且得到的表征也适用于各类经典机器学习算法。有了这个表示之后,我们也可以用于各类下游任务,例如:节点分类、链接预测等等。这也是为什么网络表示学习能成为近些年图数据分析的一个主要的研究方向。

图机器学习的发展,也是经历了由浅层模型到深层模型的这么一个转变。从早期的这种矩阵分解,到近些年的基于随机游走的方法,像DeepWalk、LINE等这些方法也是广泛应用于工业界。再进一步就是深层模型,就是把深度学习的一些技术和方法用到处理图数据中。像基于自动编码器的方法和近些年大热的基于图神经网络的方法。
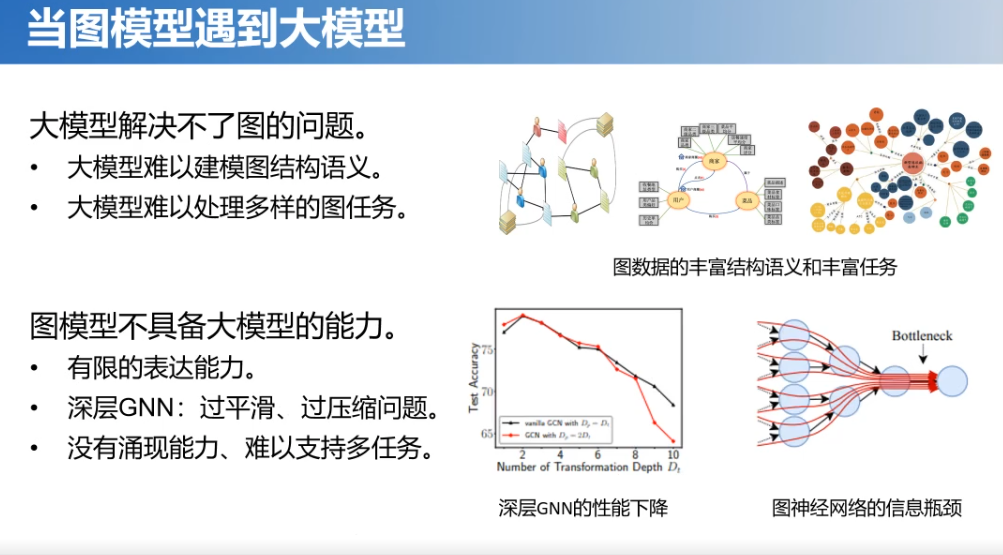
近年来,大模型技术的发展势不可挡,对我们图模型的研究也是产生了很大的冲击。当图模型遇到大模型的时候,会出现什么问题呢?这里分为两方面:
1.大模型目前还解决不了图的一些问题。我们知道大模型主要是解决这种序列数据的,而图模型的话则主要是图数据、非结构化数据,所以从本质上来说大模型是难以建模图结构语义的。另外,大模型也难以处理多样的图任务。因为,图任务主要分点集、边集还有图集等,不同类型的任务差异是很大的,它不像大语言模型用预测下个单词这种模式的话基本可以解决所有的自然语言任务。
2.图模型它也不具备大模型的某些能力。首先,它表达能力有限。其次,也没办法做深,因为图模型主要是学习结构特征,如果做深可能会遇到过平滑、过压缩等问题。最后,没有表现出涌现能力,难以支持多任务。
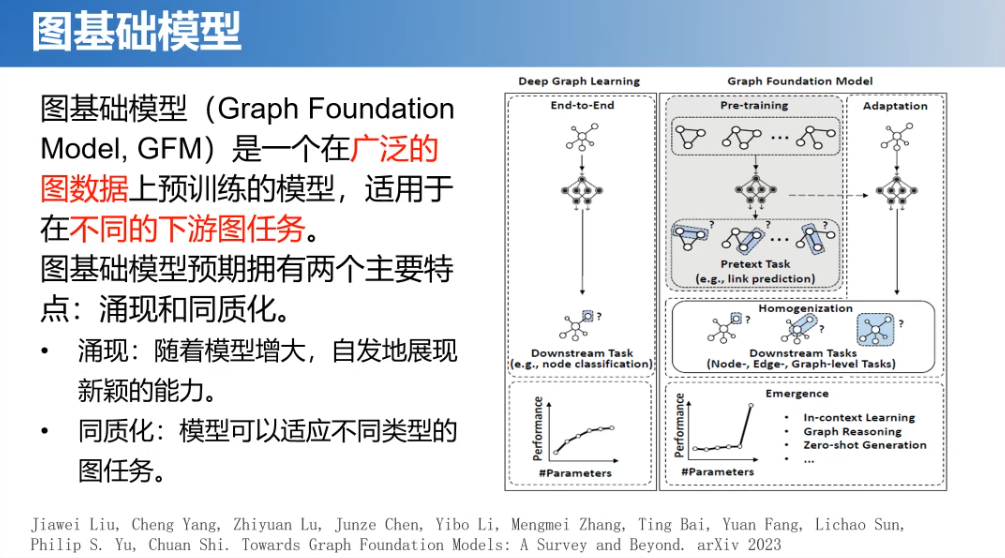
所以,在此基础上,我们就提出了“图基础模型”这个概念,希望图模型具有基础模型的一些特性。仿照基础模型的定义,我们也给了图基础模型一个规范化的定义:是一个在广泛的图数据上预训练的模型,适用于不同的下游图任务。右侧的图展现了我们现有的图机器学习模型跟图基础模型的一个差异。现在的图机器学习模型是一种端到端的训练方法,基本上是针对特定的任务来的。而我们期望图基础模型要具备两个特点:涌现和同质化能力。希望能够随着模型的增大或者数据量的增加,自发展现出一些新颖的能力。并且可以适用不同类型的图任务。
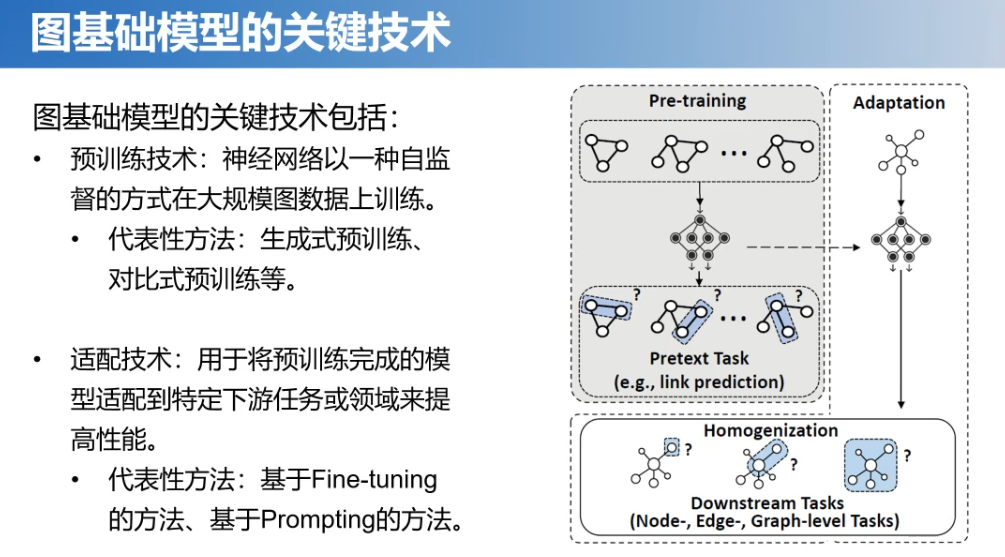
图基础模型的关键技术包括以下几点:
1.预训练技术:就是说神经网络能够以一种自监督的方式在大规模图上面进行训练。比如生成式预训练、对比式预训练等。
2.适配技术:用于将预训练完成的模型适配到特定下游任务或领域来提高性能。这里面可能会用到一些Fine-tuning和Prompting的方法。
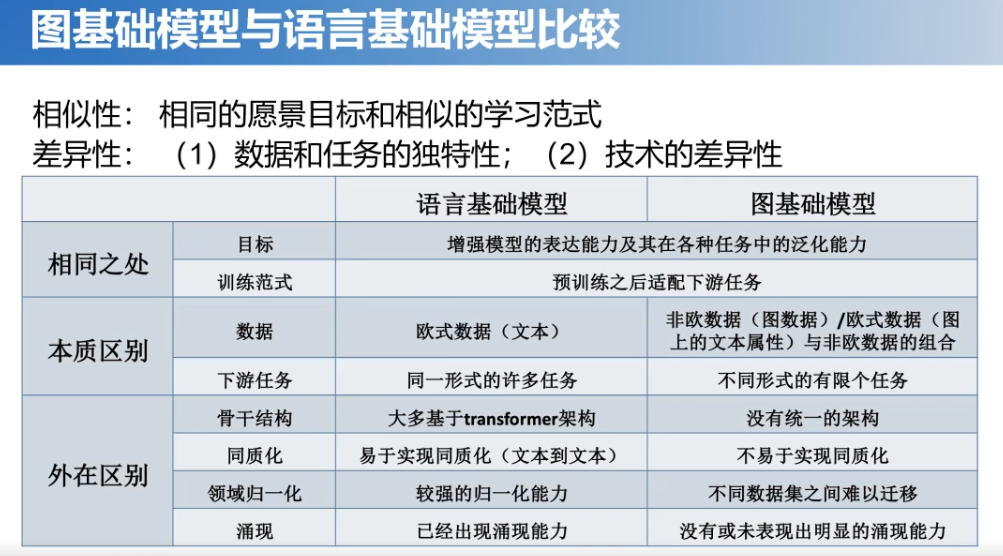
那么,我们将图基础模型和语言基础模型做了一个比较,发现它们具有一定的相似性和差异性。相似性是指它们都具有相同的愿景目标和相似的学习范式。差异性是指数据和任务的独特性以及使用技术的差异性。
简要地总结了一个表格,在相同之处,它们目标都是要增强模型的表达能力以及在各种任务中的泛化能力。它们的训练范式也是模型预训练之后适配下游任务。但是,同样存在一些本质区别和外在区别。在本质区别中,语言基础模型的数据主要是欧式数据(比如:本文、序列数据等)。图基础模型的数据则主要是图结构的非欧式数据,以及欧式数据和非欧式数据的一些组合等。那么对于下游任务,语言基础模型是同一形式的多种任务,而图基础模型则是不同形式的有限个任务。而在外在区别中,在骨干结构上面语言基础模型基本上是采用transformer架构,而图基础模型目前还没有统一的架构。再一个是同质化的能力,语言基础模型容易实现同质化,而图基础模型就不太容易实现了。还有领域归一化能力,语言基础模型具有较强的归一化能力,而图基础模型在不同数据之间、不同领域的数据之间难以迁移。最后在涌现能力方面,语言基础模型已经展现出涌现能力,而图基础模型还没有表现出明显的涌现能力。
相关工作分析
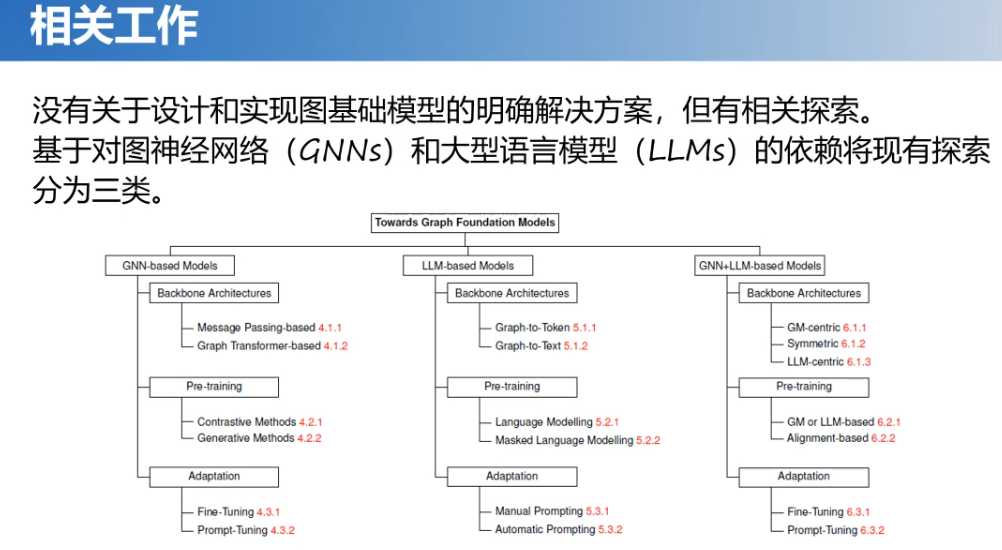
我们对相关工作做了一些分析。目前来说还没有关于设计和实现图基础模型的一个明确的解决方案,但是已经开始有这方面的探索了。图机器学习跟大模型应该怎么结合呢?近年来,也出现了一些相关工作,基于对图神经网络和大语言模型的依赖关系,将现有工作分成三类:
1.基于GNN的模型,它的骨干架构依然采用图神经网络的架构,如:消息传递的机制以及近年来比较火热的将图模型和transformer结合的一些工作,还有Graph-Mamba结合的一些工作。在预训练方面,基本上是采用对比学习的方法和生成方法。在适配方面,主要还是Fine-Tuning的方法以及Prompt-Tuning方法。
2.基于LLM的模型,它的骨干架构则是Graph-to-Token和Graph-to-Text,然后再输入到模型中。在预训练方面,由于是基于大模型的,所以是采用语言建模和Masked的方法,这些也都是自然语言中常用的方法。在适配方面,就是采用Prompt的一些方法。
3.基于GNN+LLM的模型(两种模型都用),它的骨干架构可能是以GNN为中心或者以LLM为中心,也可能是二者混合的形式。在预训练方面,可能采用GM方式、LLM方式或者是对齐的方式。在适配方面,则采用Fine-Tuning或者Prompt-Tuning的一些方法。
以上简要地分析了目前相关的一些探索和研究。
我们的工作

接下来,简要地再说一下我们在这方面的探索。其实图的预训练模型很早就有了,我们也做过几年相关的工作,后面感觉除了预训练,也不知道还有什么用,就消沉了一段时间。但随着语言模型的兴起,这方面又成了一个研究热点。我们也是在这种异构图上面做了一个预训练的工作。还有一个就是我们把图模型跟transformer进行结合,看怎么能够在transformer中把图的一些信息加入进来。利用transformer的attention机制和图神经网络的局部消息传递,看这两种优势如何结合。最近,我们也是跟阿里合作看怎么把图模型跟语言模型对齐,来解决一些开放性的问题。

下面简要地介绍一下这些工作的一些基本的思想。
第一个工作主要是针对异构图,它是由不同类型的点和边构成的关系图。研究如何在这种图上面做预训练,我们的目标是希望在一个大规模的异构图上设计有效的预训练方法。
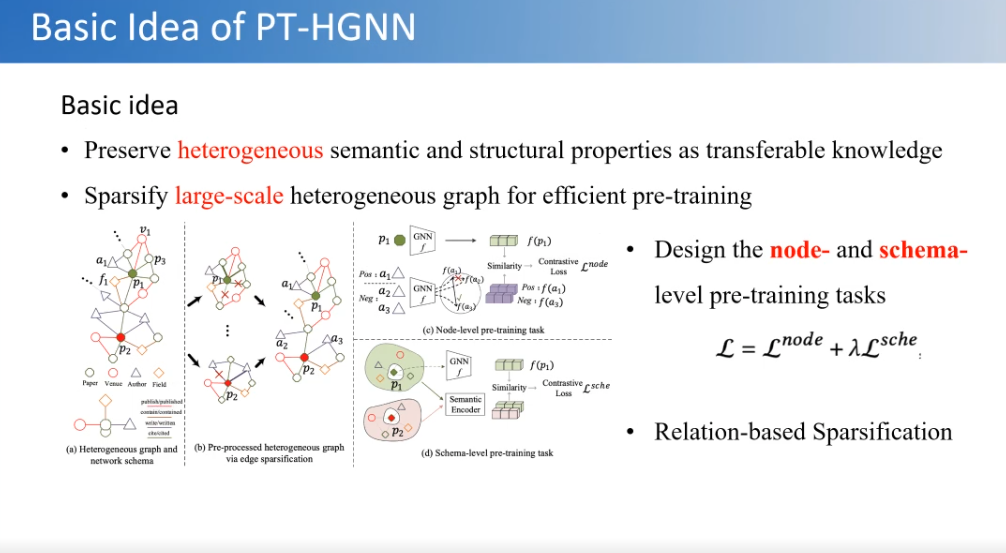
这里存在两个挑战:
1.一个是在异构图中如何提取语义结构信息;我们提出了一个点集和边集两种模式对比学习方法。
2.另一个是考虑如何把大图变小,即稀疏化。比如去掉一些无用的边,保留骨干边。
技术细节这里就不再细说了,有兴趣的同学可以查看原文。
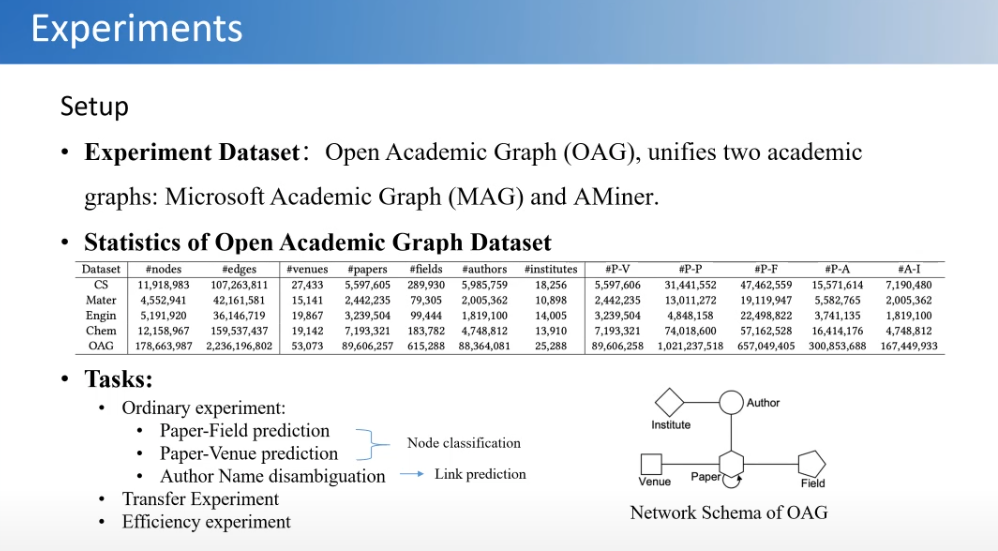
简单说一下实验部分,我们当初是想在最大的异构图上面做这个工作,当时能找到的最大的是OAG数据(科技文献数据),规模大概是上亿的点和十亿级的边,也是能找到的公开的最大的数据了。
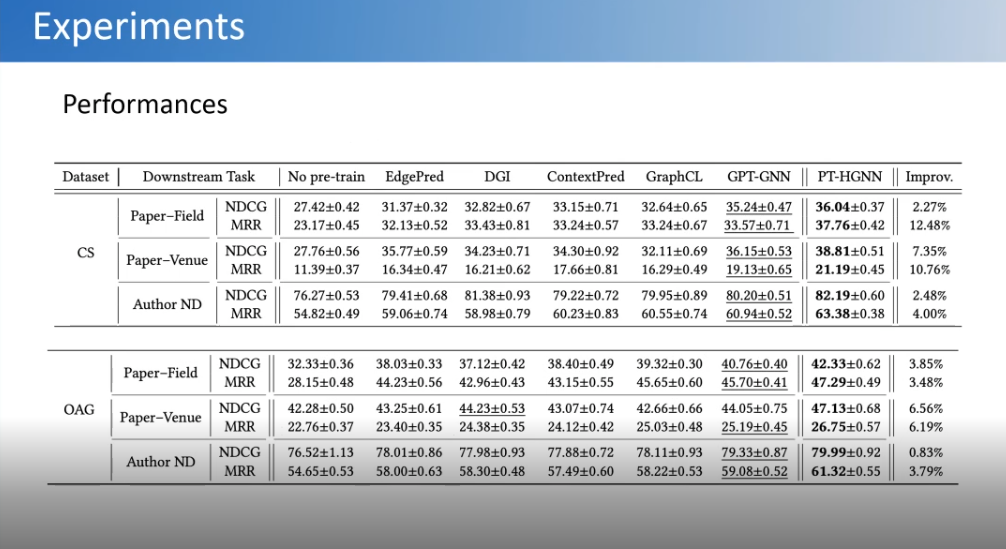
起初我们设想是用大机器在训练这个数据的,但是实验做下来发现只用了一个8卡的V100就做了这件事。因为当时大模型已经流行了,我们想大模型做那么大,图能不能也做大。后面发现并不需要多大的计算资源,而且效果也比当时一些用预训练自监督的方法都要好。
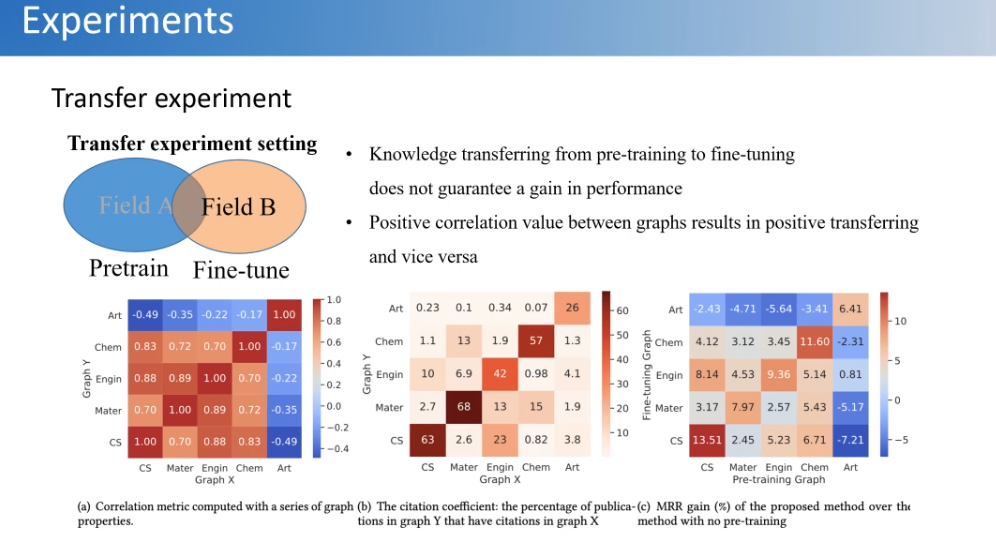
在做迁移实验的过程中发现了一个很有趣的事情,我们是在一个领域的数据上面做预训练,然后在另外一个领域的数据上面做预测。虽然都是科技文献数据,但是不同研究领域,比如计算机的、材料的、工程的、化学的以及艺术的等等,只不过是不同的研究方向。按理说这些数据同质性还是很高的,我们也分析了这些数据在结构上面的差异性,可以看见计算机跟工程、跟化学相近,跟艺术差距比较大。最后我们发现相同领域迁移效果还是不错的,相近领域也会有一些正向的迁移,但是领域差距较大,比如艺术跟计算机,就成了负迁移。这也反映了图数据里面研究的一个很重要的问题,就是不同的图数据、跨域的图数据,它的结构实际上是很难迁移的。这也是跟语言模型相比存在的一个巨大的挑战和难题。
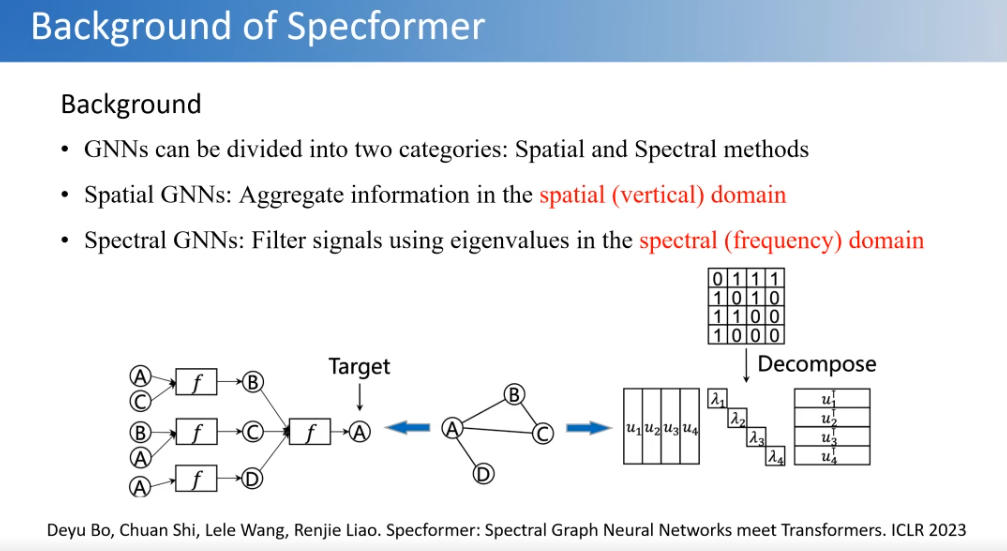
第二个工作是想把图模型和transformer模型结合,探索如何在transformer中加入一些图信息。
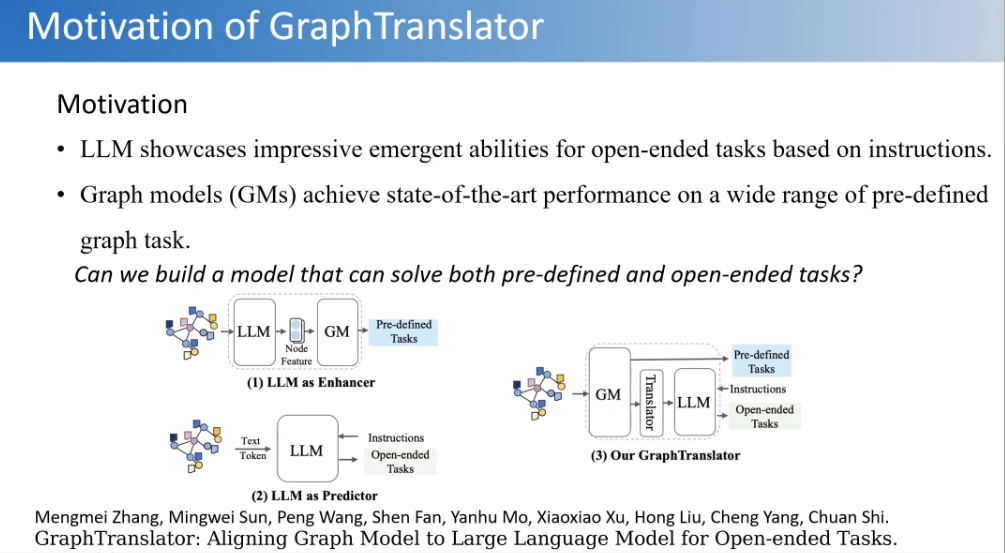
第三个工作是我们近期做的,考虑怎么把语言模型跟图模型对齐来解决他们各自存在的一些问题。比如上图中,如果采用图模型为基座,然后用语言模型做一个增强器,那么它主要是能解决一些图里面预定好的问题,这正是图神经模型擅长的。如果用语言模型来做,把图转化成Token或者Text输入,它可以解决一些开放式的问题,但在预定好的图的问题上效果就不太好。
因此,我们希望能够结合两种模型的优点,把图模型和语言模型进行对齐。让它不仅能够解决图上面一些预定义的问题,而且也能够回答一些开放性的问题。这就是我们本工作的一个基本思想。
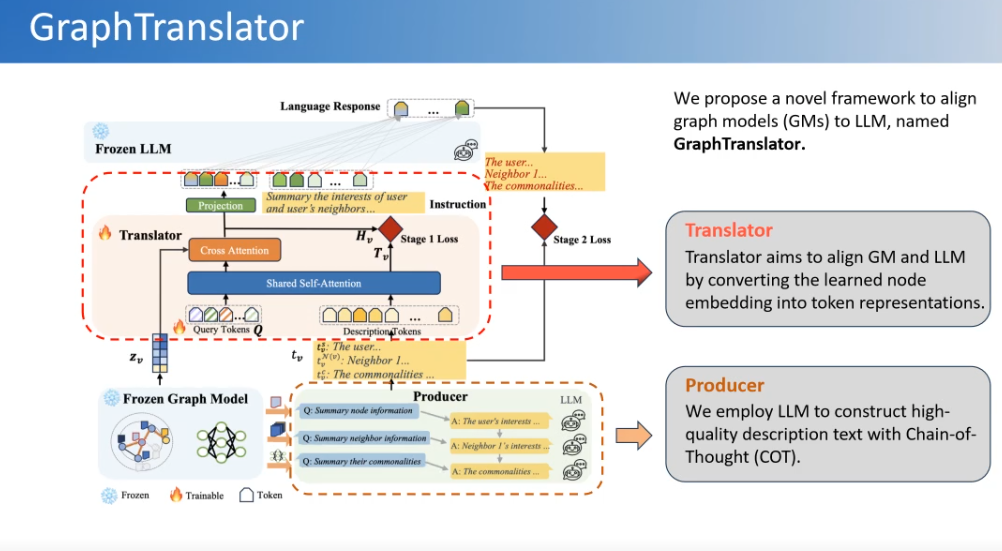
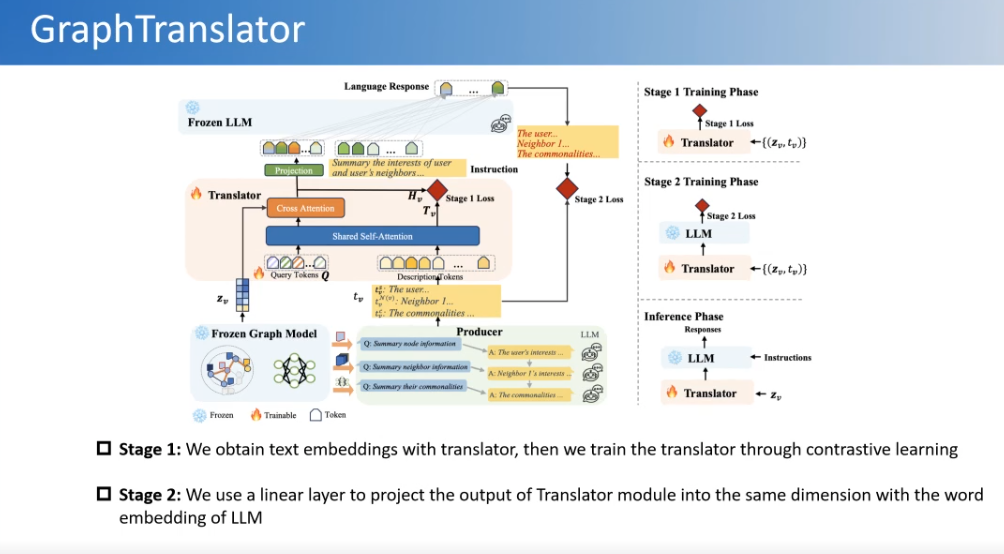
我们也设计了一个图模型跟语言模型对齐的架构。比如用固定的语言模型和学习好的图模型,让它们产生一些instruction,然后再设计一些分析的机制和一些自监督的学习目标,二者进行对齐,也相当于对语言模型做了一个微调。这样做可以让语言模型理解图的结构,更好地回答一些开放式的问题。
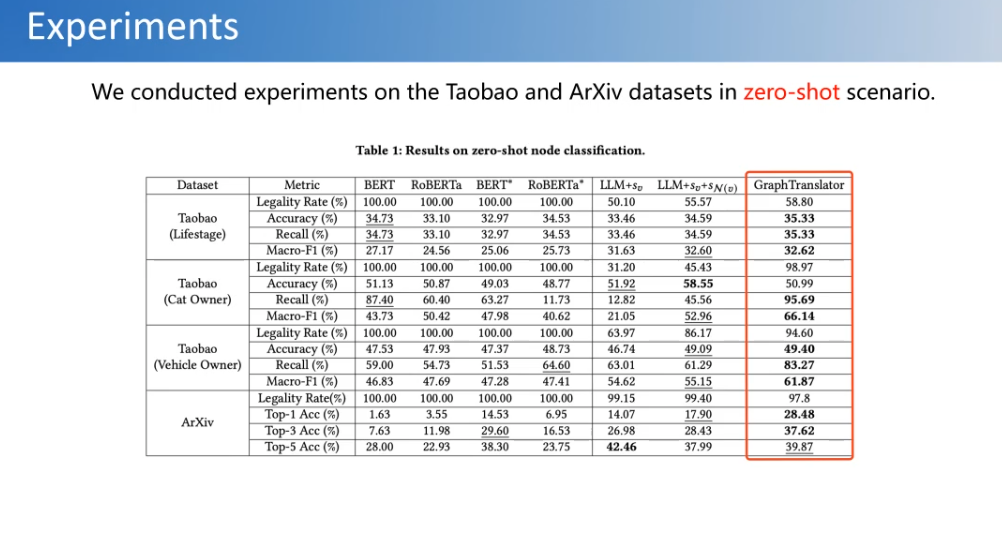

这里我们进行了定量的实验,发现做了对齐之后模型,可以更好地理解这个结构,也能够更好地回答一些问题。
总结与展望
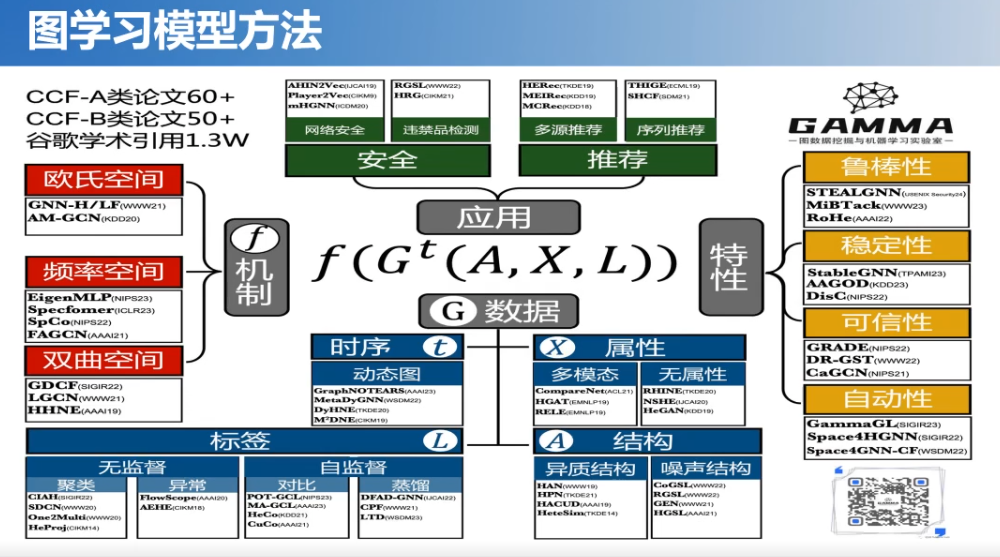
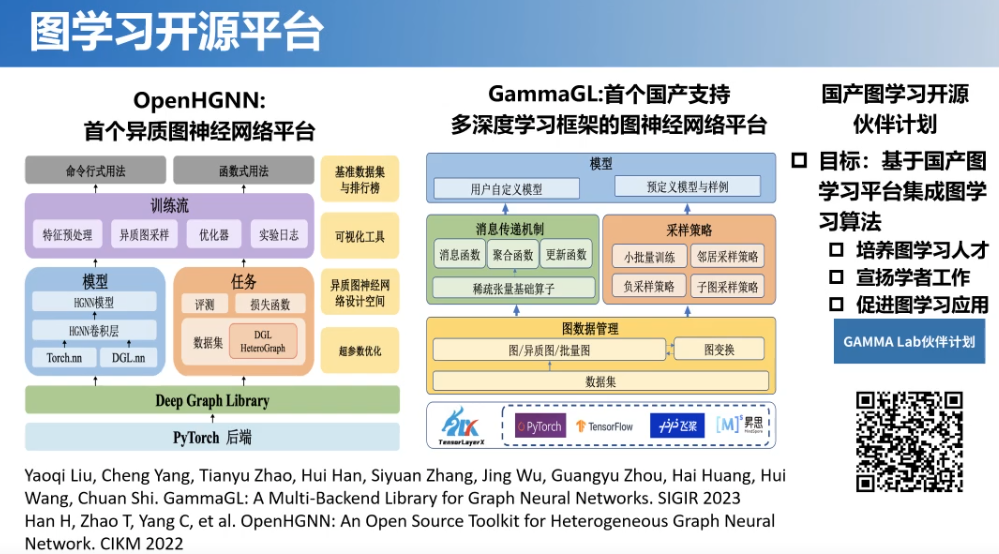
最后,简单做个总结。在图学习方面,我们做了大量的工作,从图学习的机制到不同类型的图数据任务,还有这种特性的图学习方法以及将图应用到安全、推荐和生物医药等领域。我们也做了两个开源系统,分别是异质图神经网络平台(OpenHGNN)和支持多深度学习框架的图神经网络平台(GammaGL),目前这两个平台均在OpenKG社区开源。而且牵头制定了图学习的标准。本次所讲的主要工作也是我们近期写的一篇文章,大家如果有兴趣的话可以了解一下。
那未来研究方向的话,一方面是如何提升数据量和数据质量,这也是本次活动的一个宗旨;另一方面是改进骨干架构和训练策略;最后是模型评估以及寻找杀手级的应用。
以上就是本次分享的内容,谢谢!


作者简介
INTRODUCTION

石川

北京邮电大学计算机学院教授、博士研究生导师、智能通信软件与多媒体北京市重点实验室副主任。主要研究方向: 数据挖掘、机器学习、人工智能和大数据分析。以第一或者通讯作者发表高水平学术论文100余篇,包括数据挖掘领域的顶级期刊和会议IEEE TKDE、ACM TIST、NeurIPS、KDD、AAAI、IJCAI、CIKM等。在Springer出版异质信息网络方向第一部英文专著。获得ADMA2011和ADMA2018等国际会议最佳论文奖、WWW21最佳论文候选、CCF-腾讯犀牛鸟基金及项目优秀奖,并指导学生获得顶尖国际数据挖掘竞赛IJCAI Contest 2015 全球冠军。获得2021年北京市科学技术自然科学奖二等奖(排名第一)、2020年中国计算机学会科学技术自然科学奖二等奖(排名第一)、2020年吴文俊人工智能科技进步一等奖(排名第三)以及2023年中国电子学会科技进步一等奖(排名第一)。

OpenKG TOC(Technical Oversight Committee)作为OpenKG开放社区的技术监督机构,在OpenKG授权范围内,为开放社区提供技术指导、技术监督和宣传布道等工作,以帮助OpenKG更加规范化的管理和运行。首批OpenKG TOC专家由二十名来自浙江大学、东南大学、同济大学、清华大学、南京大学、北京大学、武汉科技大学、北京邮电大学、苏州大学、天津大学、中科院信工所、国防科技大学、东北大学、英国爱丁堡大学、意大利卑尔根大学、蚂蚁集团、华为、阿里通义实验室、恒生电子、柯基数据等国内外高校和企业的知识图谱方向负责人和一线专家组成。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









