







导读
OpenKG新开设“TOC专家谈”栏目,推送OpenKG TOC(技术监督委员会)专家成员的观点文章。本期邀请到天津大学王鑫教授介绍“大模型与知识图谱协同机制”方面的一些探索,本文整理自王鑫老师在“OpenKG走进苏州大学”Talk上的分享。
本报告将回顾大语言模型和知识图谱的基本概念,介绍两者之间的协同机制,并通过几个案例来引出一些思考。本文简要介绍了TOC专家天津大学王鑫教授在此领域开展的初步探索工作。

今天给大家带来的分享是大模型与知识图谱的协同机制。首先回顾一下大语言模型和知识图谱,然后介绍两者之间的协同机制,最后通过几个案例来引出一些思考。
大语言模型

通用人工智能AGI,当前的趋势表明其重要性日益凸显。过去,人们普遍认为AGI是一种科幻概念,并主要专注于实现特定任务的狭义弱人工智能。然而,随着⼤语⾔模型能力的提升,它们展现出来的能⼒和出现的应⽤引发了对通⽤⼈⼯智能的更多讨论,特别是高级推理决策等场景。例如,最近的研究成果显示,使用大型模型参与策略游戏(例如“星际争霸”)的工作已经取得突破的进展。
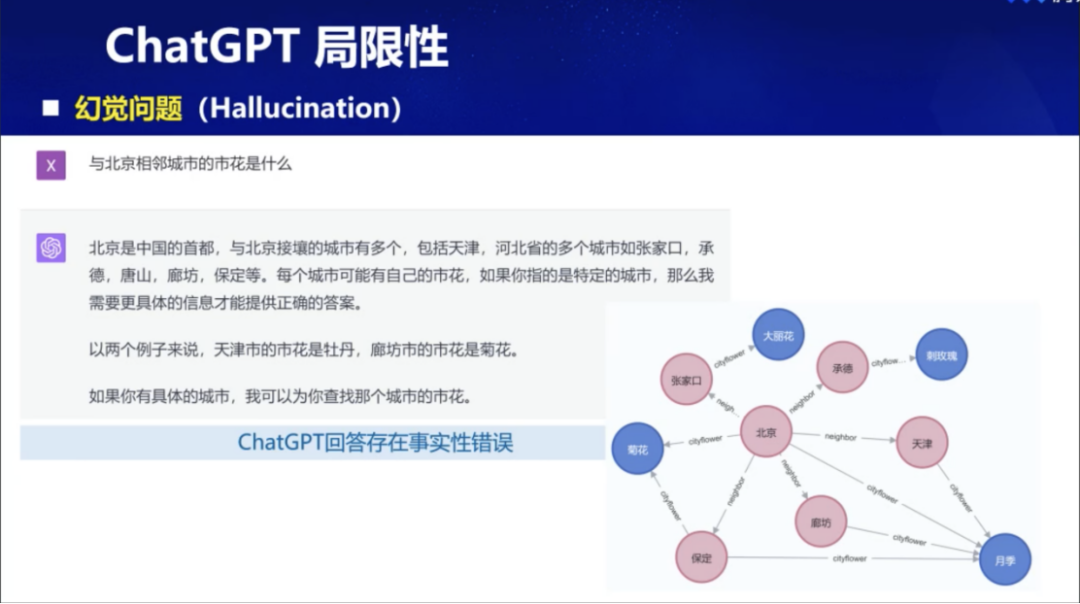
然而,目前的大模型仍存在一些局限性,比如幻觉问题。以一个小例子来说明:查询与北京相邻城市的市花,这个问题涉及典型的知识性信息。尽管大模型可以给出多段回答,但这些答案提供的事实信息并不准确——比如,天津市的市花并不是牡丹,廊坊市的市花也不是菊花,但是通过构建知识图谱,可以更有效地解决这类问题。

另外还有一类问题是计算能力弱,如图所示大模型的计算步骤是对的,但是解应该是整数7,而结果却显示约等于7.007。
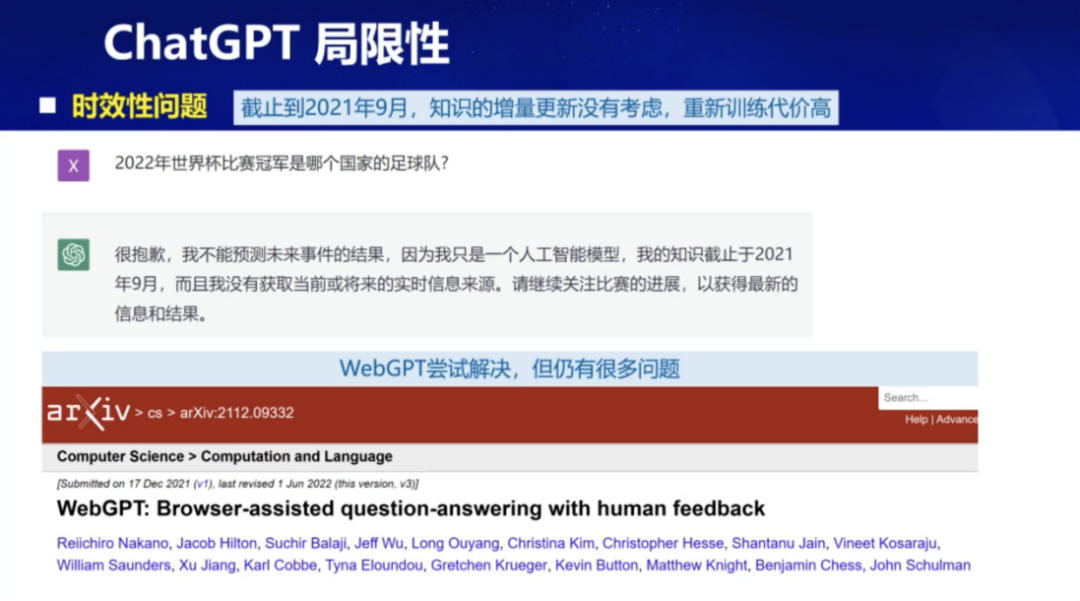
此外,大模型还存在知识时效性的缺陷。当询问最新信息时,大模型在处理更新知识和增量学习方面表现不佳。目前的大模型的知识更新仍然依赖于外部知识的补充与增强。
总的来说,大模型在通用和部分领域任务上,其性能已超越传统方法。然而,在知识计算方面特别是在知识获取、推理与应用上仍存在一些局限性。大模型与知识图谱可以相辅相成,通过相互融合能够实现优势互补,从而增强整体的智能处理能力,共同推动人工智能技术的进步。
知识图谱
关于知识图谱,目前基本被视为知识工程的最新代名词。知识工程的历史悠久,早期的人工智能主要依靠符号主义,强调知识的获取、表示和使用。然而,人类的大脑如何组织知识尚未完全理解,因为当前的神经网络模型主要模仿人脑的神经元网络。此外也请教过搞脑神经的专家,尽管脑神经学的研究对大脑各个区域的功能上有一定认识,但并未达到细胞级别的精确解析,这受到多种因素的影响,包括伦理限制等等。但这并不妨碍我们从机器和数据的角度来模拟和理解知识。
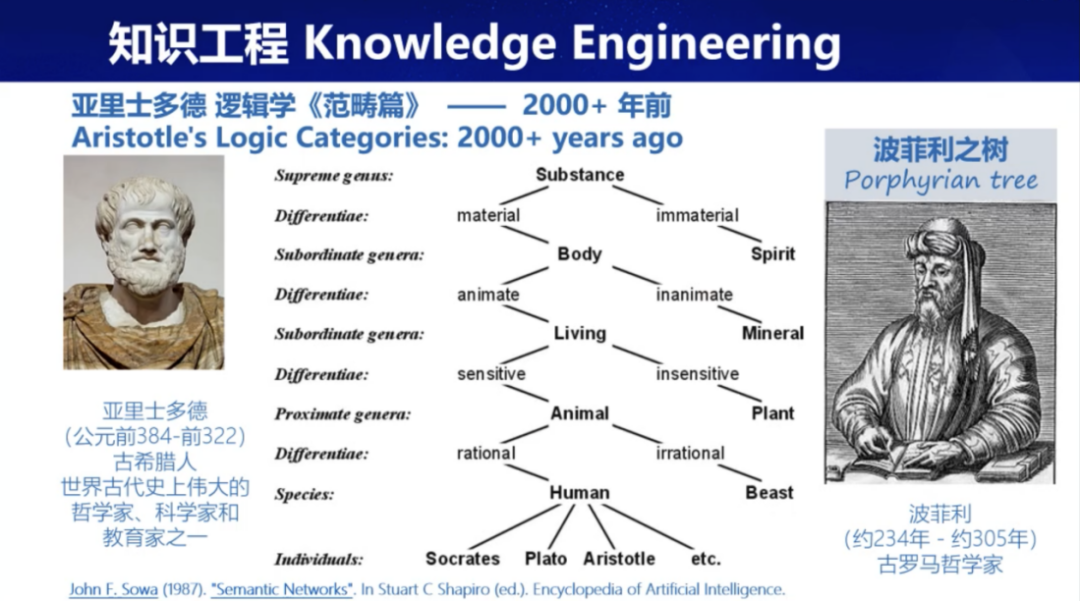
知识表示的起源可追溯至亚里士多德的《范畴篇》,这大约在两千年前,实质上构成了我们现今所谓的本体。之后被古罗马哲学家波菲利归纳总结,通过分类方式组织知识的方法。该方法类似于现代面向对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









