







笔记整理:徐雅静,浙江大学博士,研究方向为多模态知识图谱、生成模型
论文链接:https://arxiv.org/abs/2406.02030
发表会议:ACL 2024
1. 动机
大型语言模型(LLMs)在进行多模态推理时常常遇到幻觉和知识库中知识不足或过时的问题。现有的一些方法尝试通过使用文本知识图谱来缓解这些问题,但这些方法的单一模态知识限制了跨模态理解的全面性。为了克服这些限制,论文提出了一种利用多模态知识图谱(MMKGs)的MR-MKG方法,该方法通过跨模态学习丰富和语义化的知识,显著提升了LLMs的多模态推理能力。
2. 方法
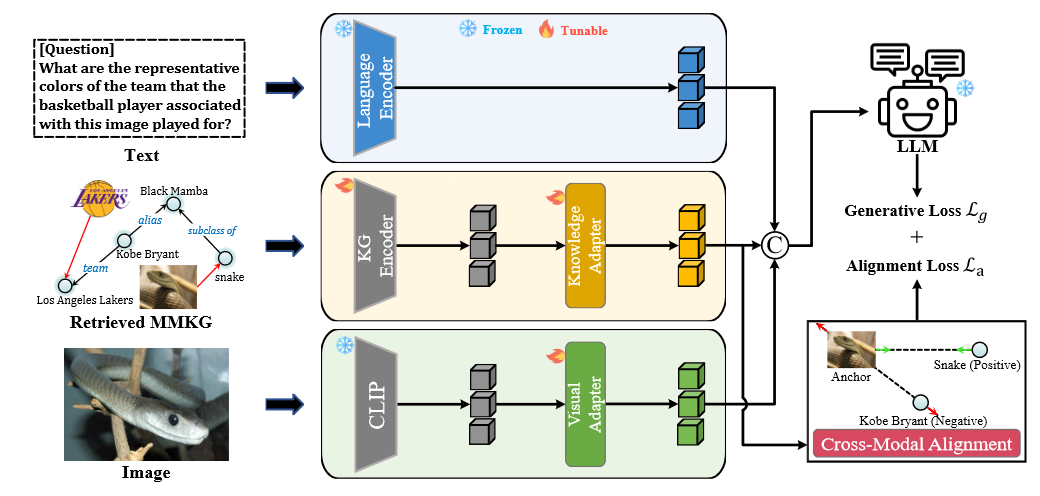
图1. MR-MKG方法示意图
如图1所示,MR-MKG方法主要包含五部分:
语言编码器. 使用现成的大型语言模型(如LLaMA和T5)的嵌入层作为语言编码器,并在训练和推理阶段保持不变。文本经过语言编码器处理后生成文本嵌入.
视觉编码器. 采用预训练的视觉编码器(如CLIP)将图像转换为视觉特征。为了确保视觉特征与语言空间的兼容性,使用线性层实现的视觉适配器将视觉特征转换为视觉-语言嵌入.随后,利用单头注意力网络获得与文本嵌入关联的最终视觉特征.
KG编码器. 给定文本或图像,MR-MKG首先从多模态知识图谱(MMKG)中检索一个子图G。然而,检索到的子图G可能引入噪声。作者采用了关系图注意力网络(RGAT)来考虑子图G的复杂结构对知识节点进行嵌入。具体来说,我们首先使用CLIP初始化节点和关系的嵌入,然后使用RGAT网络对子图G进行编码,生成知识节点嵌入.
知识适配器. 为了使大型语言模型(LLM)理解多模态知识节点嵌入,我们引入了一个知识适配器,将转换为LLM可以理解的文本嵌入。这个知识适配器旨在弥合多模态知识与文本之间的固有差距,促进更流畅的对齐。
跨模态对齐. 从子图G中随机选择一组图像实体,并提示模型将其与对应的文本实体进行精确匹配。所选图像对应的节点嵌入表示为,其相关文本节点的嵌入表示为。我们使用三元组损失进行校准。当一个图像实体的嵌入作为锚点时,其对应的文本实体嵌入作为正样本。同时,其他文本实体嵌入作为负样本。对齐的目标是最小化正样本与锚样本之间的距离,同时最大化负样本与锚样本之间的距离。
MR-MKG的训练分为两个阶段:第一阶段是预训练,使模型具备基础的视觉能力和理解多模态知识图(MMKGs)的能力;第二阶段则是将模型应用于需要高级多模态推理的具体场景。需要注意的是,在整个训练过程中,LLM和视觉编码器的权重保持不变。
3. 实验
3.1 实验细节
数据集:在ScienceQA数据集上进行了多模态问答任务实验,在MARS数据集上进行了多模态类比推理任务实验。多模态数据集MMKG与ScienceQA结合使用,而MarKG用于支持MARS。
实现细节:在两个数据集上选择ViT-L/32作为视觉编码器,RGAT作为知识嵌入模型。在ScienceQA任务中,我们采用FLAN-T5 3B和FLAN-T5 11B作为大型语言模型,并实现了多模态连锁思维提示方法(Multimodal-CoT)。为验证MR-MKG的通用性,还使用了FLAN-UL2 19B作为骨干模型。在MARS任务中,选择LLaMA-2 7B初始化模型。关于知识三元组检索,我们将三元组数量设置为10或20,检索的跳跃距离保持为1。所有实验均在NVIDIA 8×A800-SXM4-80GB机器上进行。
基线方法:在ScienceQA任务中,我们将方法与四类基线进行比较:零样本和小样本GPT模型,最新的SOTA方法MM-Cot,代表性的端到端多模态大型语言模型LLaVA,以及参数高效的方法如LLaMA-Adapter和LaVIN。在MARS任务中,我们与两类基线方法进行比较:包括IKRL、TransAE、RSME等MKGE方法,以及多模态预训练Transformer模型(MPT)、VisualBERT、ViLT和MKGformer等。每个基线方法都在MarKG上进行了预训练,提供了关于实体和关系的基本先验知识,以增强多模态推理能力。
3.2 主要实验结果
表1 ScienceQA 数据集上的结果
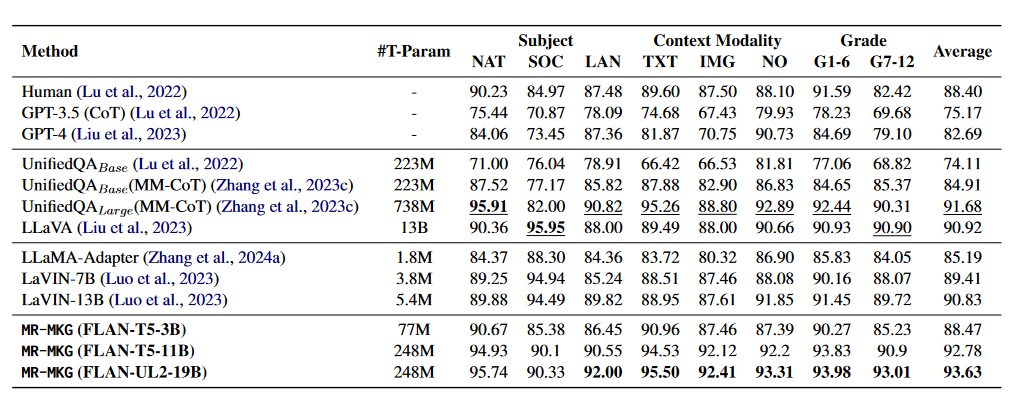
从表1可以看出,在多模态问答任务中,MR-MKG方法在平均准确率方面优于所有基线方法。即使零样本和小样本方法应用于像GPT这样流行的LLM,仍然无法达到人类水平的表现。值得注意的是,GPT-4由于其增强的多模态能力和更大的参数规模,相比GPT-3.5有显著提升。尽管UnifiedQALarge(MM-CoT)达到了之前的SOTA,它需要使用全部参数进行训练,导致高昂的训练成本。相比之下,MR-MKG仅需训练少量参数就能取得更好的结果。
表2 MARS 数据集上的结果
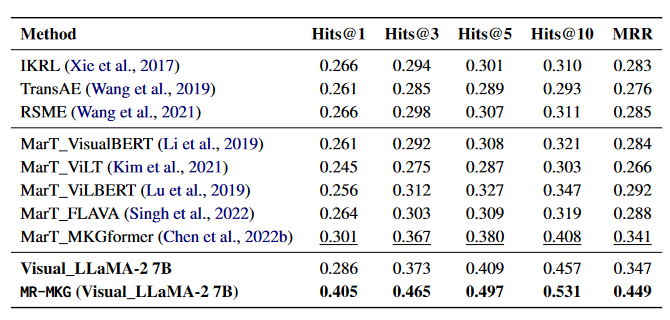
从表2可以看出,在多模态类比推理任务中,MR-MKG在MARS数据集上显著优于所有其他方法。多模态知识图嵌入方法和多模态预训练Transformer模型的性能相对相近,其中MKGformer表现出较优的性能。相比之下,配备视觉适配器的视觉LLaMA-2 7B模型的结果与MKGformer相当,尽管Hits@1得分略低,但在其他指标上有所提升。这突显了视觉适配器组件的有效性和精心设计的优势。更值得一提的是,经过MR-MKG增强后,视觉LLaMA-2 7B在Hits@1得分上提高了10.4%,并且在其他指标上也有显著改进。
4. 总结
在本文中,我们通过多模态知识图增强大型语言模型(LLMs)的多模态推理能力。我们提出的方法称为MR-MKG,旨在利用多模态知识图(MMKGs)中丰富的知识(图像、文本和知识三元组)赋予LLMs高级的多模态推理能力。在多模态问答和多模态类比推理任务上的综合实验显示了MR-MKG方法的有效性,并在这些任务中取得了最先进的结果。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









