






转载公众号 | 知识图谱科技

摘要
最近的进展表明,大型语言模型(LLMs)在解决复杂推理问题时容易出现幻觉,导致错误结果。为解决这一问题,研究人员结合知识图谱(KGs)以提高LLMs的推理能力。然而,现有方法面临两个限制:1)它们通常假设问题的所有答案都包含在KGs中,忽略了KGs的不完整性问题;2)它们将KG视为静态的知识库,忽略了KGs中固有的隐含逻辑推理结构。本文介绍了SymAgent,一种创新的神经符号代理框架,实现了KGs与LLMs之间的协同增强。我们将KGs概念化为动态环境,并将复杂推理任务转化为多步骤交互过程,使KGs能够深入参与推理过程。SymAgent由两个模块组成:代理规划器和代理执行器。代理规划器利用大型语言模型(LLM)的归纳推理能力从知识图谱(KGs)中提取符号规则,指导高效的问题分解。代理执行器自主调用预定义的动作工具来整合来自知识图谱和外部文档的信息,解决知识图谱不完整的问题。此外,我们设计了一个自学习框架,包括在线探索和离线迭代策略更新阶段,使代理能够自动合成推理轨迹并提高性能。实验结果显示,使用较弱LLM(即7B系列)的SymAgent与各种强大的基线相比,表现出更好或相当的性能。
进一步分析显示,我们的代理可以识别缺失的三元组,促进知识图谱的自动更新。
核心速览
研究背景
研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在处理复杂推理问题时容易出现幻觉,导致错误结果。为了应对这一问题,研究人员将知识图谱(KGs)引入到LLMs中以提高推理能力。然而,现有方法存在两个局限性:一是假设KG中的所有答案都包含在KG中,忽略了KG的不完整性问题;二是将KG视为静态的知识库,忽视了KG中隐含的逻辑推理结构。
研究难点:该问题的研究难点包括:语义差距、KG的不完整性以及有限监督下的学习。具体来说,需要将KG的符号结构与LLMs的神经表示对齐,处理KG信息不足的情况,并在仅有自然语言输入输出对的情况下解锁LLMs的全部推理潜力。
相关工作:该问题的研究相关工作有:语义解析方法和检索增强方法。语义解析方法将问题解析为可执行的正式语言(如SPARQL)并在KG上进行精确查询以获得答案。检索增强方法从KG中检索相关事实三元组并将其输入到LLMs中以帮助生成最终答案。
研究方法
这篇论文提出了SymAgent,一种创新的神经符号代理框架,用于解决复杂推理问题。具体来说,
Agent-Planner模块:该模块利用LLMs的归纳推理能力从KG中提取符号规则,指导高效的问题分解。具体步骤如下:
使用BM25从训练集中检索出一组与问题结构相似的种子问题。
对每个种子问题,采用广度优先搜索(BFS)在KG中采样一组闭路径。
将这些闭路径泛化为符号规则,并作为提示输入到SymAgent中以生成适当的规则体。
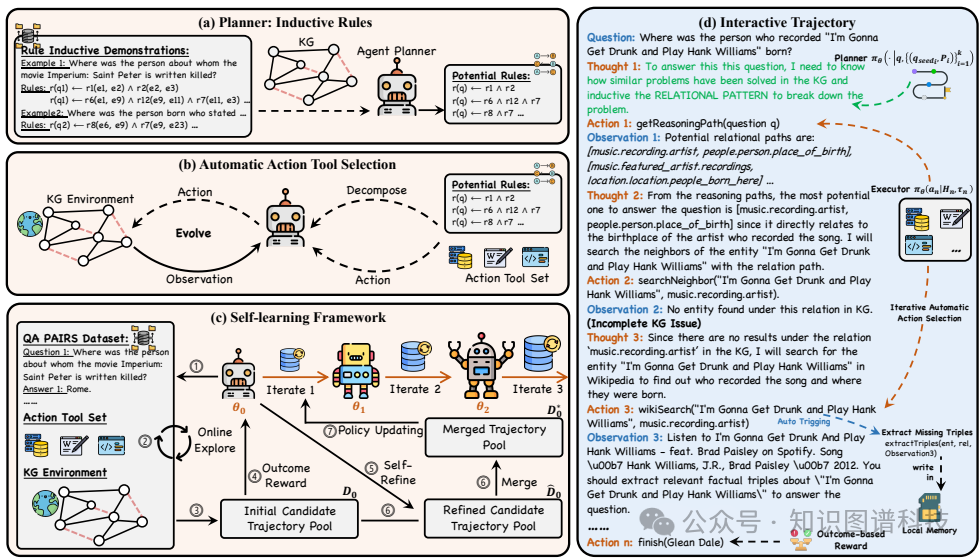
2. Agent-Executor模块:该模块通过调用预定义的动作工具集来整合KG和外部文档的信息,解决KG不完整性的问题。动作空间包括以下功能工具:
getReasoningPath:接收子问题并返回潜在的象征规则。
wikiSearch:在KG信息不足时从维基百科或互联网检索相关文档。
extractTriples:从检索到的文档中提取与当前查询实体和关系相关的三元组。
searchNeighbor:返回KG中特定实体在给定关系下的邻居。
finish:返回最终答案列表,表示推理过程结束。
3. 自学习框架:为了解决缺乏注释的推理数据问题,提出了一个自学习框架,包括在线探索和离线迭代策略更新两个阶段。具体步骤如下:
在线探索阶段:基础代理通过与环境的自主交互合成一组初始轨迹,并使用基于结果的奖励机制进行优化。
离线迭代策略更新阶段:在初始轨迹集上进行微调,并通过重复的自我探索和轨迹合并过程不断提高性能,直到验证集上的性能提升可以忽略不计。
实验设计
数据集:实验采用了三个广泛使用的知识图谱问答数据集:WebQuestionSP(WebQSP)、Complex Web Questions(CWQ)和MetaQA-3hop。为了模拟不完整的KG,采用广度优先搜索方法从问题实体到答案实体提取路径,并随机移除一些三元组。
基线方法:评估了SymAgent与三种不同的LLM骨干模型(Mistral-7B、LLaMA2-7B和Qwen2-7B)的性能比较。基线方法包括基于提示的方法(CoT和ReAct)以及强基线方法(ToG和RoG)。
实现细节:使用LoRA进行微调,初始学习率为2e-5,序列长度为4096,训练轮数为3,批量大小为4。推理过程中使用vLLM加速推理。所有训练和推理实验均在4个NVIDIA A800 80G GPU上进行。
结果与分析
性能比较:实验结果表明,SymAgent在所有数据集上均表现出优越的性能。与基线方法相比,SymAgent在不同LLM骨干模型上均实现了显著的提升。例如,Qwen2-7B骨干模型的Hits@1提高了37.19%,Accuracy提高了16.87%,F1得分提高了30.17%。
消融研究:通过消融实验分析了各个组件的贡献。结果表明,规划模块、执行模块和自学习框架都是必不可少的,缺少任何一个组件都会对性能产生显著影响。
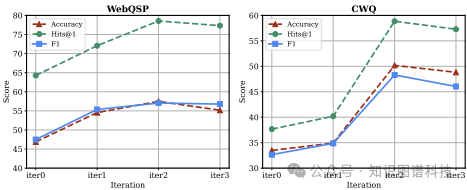
自学习框架分析:自学习框架的迭代次数对模型性能有显著影响。自我细化和启发式合并的协同作用显著提高了模型性能。与从教师模型蒸馏的方法相比,自学习框架在所有数据集上均表现更好。
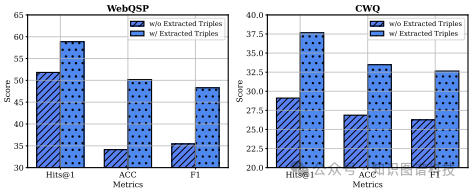
提取三元组的质量:通过增强KG并测试检索增强生成模型RoG的性能,验证了所提取三元组的质量足以集成到现有的KG中。
错误分析:错误分析表明,WebQSP的错误主要是推理错误(94.34%),而CWQ和MetaQA-3hop的错误分布更为多样化,显著存在超出最大步数(EMS)的错误,表明未来在这些领域有改进的空间。
总体结论
这篇论文提出了SymAgent,一种自动代理框架,通过结合LLMs和结构化知识进行复杂推理。SymAgent利用KG中的象征规则指导问题分解,自动调用动作工具解决KG不完整性问题,并采用自学习框架进行轨迹合成和持续改进。广泛的实验证明了SymAgent在复杂推理场景中的优越性,展示了促进KG和LLMs相互增强的潜力。
论文评价
优点与创新
创新的神经符号驱动框架:SymAgent提出了一种新颖的基于大型语言模型(LLM)的代理框架,用于知识图谱上的复杂推理,有效地结合了LLM和KG的优势。
多步交互过程:通过自动调用预定义的动作工具,SymAgent将自然语言问题转化为多步交互过程,实现了KG和LLM的相互增强。
自学习框架:设计了一个包含在线探索和离线迭代策略更新的自学习框架,使代理能够在没有人工注释的情况下自动合成推理轨迹并提高性能。
弱LLM骨干的优越性能:实验结果表明,使用弱LLM骨干(如7B系列)的SymAgent在多个复杂推理数据集上取得了与强基线相当甚至更好的性能。
缺失三元组的识别与自动更新:代理能够识别缺失的三元组,促进KG的自动更新,增强了KG的完整性。
不足与反思
动作工具调用的潜在错误:尽管SymAgent在处理结构化数据方面表现出色,但在调用动作工具时可能会遇到错误,例如参数过多或过少,这可能影响推理过程。
中间步骤错误的处理:当前方法在中间步骤中可能会出现错误,尽管最终答案可能是正确的,但模型的这种能力需要进一步改进。
评估指标和奖励机制的改进:在自学习阶段,模型可能会产生正确但最终结果错误的中间步骤,需要更细致的评价指标和奖励机制来避免模型过度拟合这些虚假的相关性。
特定领域的泛化能力:尽管SymAgent在特定领域(如电影知识图谱)的零样本推理中表现出色,但在其他领域的泛化能力仍需进一步验证。
关键问题及回答
问题1:SymAgent的Agent-Planner模块是如何利用LLMs的归纳推理能力从KG中提取符号规则的?
检索种子问题:使用BM25算法从训练集中检索出一组与原始问题结构相似的种子问题。
广度优先搜索(BFS):对每个种子问题,采用BFS在KG中采样一组闭路径。这些闭路径是从查询实体到答案实体的路径,可以被视为回答问题的符号规则的实例。
泛化符号规则:将这些闭路径泛化为符号规则
通过这种方式,Agent-Planner模块能够利用LLMs的归纳推理能力从KG中提取符号规则,从而指导高效的问题分解。
问题2:SymAgent的Agent-Executor模块如何通过调用预定义的动作工具集来解决KG不完整性的问题?
动作空间:定义了一组功能工具,包括getReasoningPath、wikiSearch、extractTriples、searchNeighbor和finish。这些工具分别用于获取符号规则、检索相关文档、提取三元组、搜索邻居和返回最终答案。
交互过程:将KG视为环境,动作执行结果作为观察值,整个推理过程成为一系列代理动作调用和相应观察值的序列。代理通过反复调用这些动作,逐步收集必要的信息并进行推理,直到找到最终答案或达到预定的停止条件。
通过这些动作工具的组合使用,Agent-Executor模块能够有效地整合KG和外部文档的信息,解决KG不完整性的问题,从而提高推理的准确性和完整性。
问题3:SymAgent的自学习框架是如何通过在线探索和离线迭代策略更新来提高模型性能的?
在线探索阶段:基础代理通过与环境的自主交互合成一组初始轨迹,并使用基于结果的奖励机制定义奖励。具体步骤包括:
基础代理生成初始轨迹。
使用奖励机制评估轨迹的质量。
通过自我反思和修正生成新的精细轨迹。
离线迭代策略更新阶段:在自学习框架中,通过反复进行自我探索和自我反思,生成新的轨迹数据进行微调,直到验证集上的性能提升可以忽略不计。具体步骤包括:
使用初始轨迹进行微调。
通过多次迭代,不断生成新的轨迹数据。
在验证集上评估模型性能,并根据评估结果进行参数调整和优化。
通过这种在线探索和离线迭代策略更新的方法,SymAgent能够不断与环境进行交互,合成高质量的轨迹数据,并通过微调提高模型性能,从而实现自主学习和持续改进。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

















 2018
2018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









