








Pandas的数据清洗、函数应用、排序
1、pandas数据清洗
1-1 判断是否存在空值
import pandas as pd
import numpy as np
#新建一个df对象
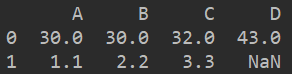
df1 = pd.DataFrame([np.random.randint(10,50,4),[1.1,2.2,3.3,]],columns=list('ABCD'))
print(df1)
如图所示
.isnull()/.notnull()
print('####判断是否存在缺失值##')
ret = df1.isnull()
print(ret)
如果为NaN,则返回True

1-2 删除空值
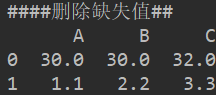
print('####删除缺失值##')
ret3 = df1.dropna(axis='columns')
print(ret3)
drop()方法中属性axis默认删除一行,设置为columns则删除一列
1-3 填充空值
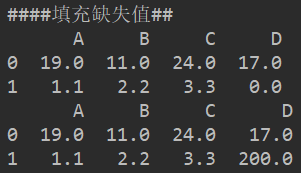
print('####填充缺失值##')
ret4 = df1.fillna(0)
print(ret4)
ret5 = df1.fillna({0:0,3:200})
print(ret5)
注意点:
1、如果在fillna这个函数中填值,代表所有的nan数据直接换成指定的值
2、如果参数是字典,那么表示对于不同的列有不同的值,字典的键名是列名,值为填充的值
1-4 处理重复数据
#判断重复数据
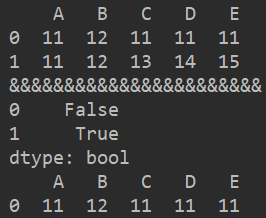
df2 = pd.DataFrame([np.random.randint(10,15,5),[11,12,13,14,15]],columns=list('ABCDE'))
print(df2)
print('&&&&&&&&&&&&&&&&&&&&&&&')
print(df2.duplicated('A'))
print(df2.drop_duplicates('A'))
df2.duplicated(‘A’)返回的是一个Boolean类型的DF对象,括号中填写查找的列
df2.drop_duplicates(‘A’)是在‘A’列中查找,如果有重复值,则删除重复值所在的行,通过删除完成后的DF对象,也可以通过inplace来修改原DF对象
1-4 替换数据
df3 = pd.DataFrame(np.random.randint(-5,10,(3,4)),index=list('abc'),columns=list('ABCD'))
print(df3)
ret1 = df1.replace('b',1,)
#将数据中的'b'全部替换成1
ret1 = df1.replace(['b','d'],1,)
#将全部的b和d,替换成1
ret1 = df1.replace({'b':1,'d':2})
#将b替换成1,'d'替换成2
ret2 = ret1.replace({'A':1},'m')
#将data1这一列的1,替换成'm'
print(ret1)
print(ret2)
总结:
repalce(替换前的值,替换后的值)
repalce([替换值1,替换值2…],都由这个值替换)
repalce({‘替换值1’:换后值1,‘替换值2’:换后值2})
repalce({替换值所在列:替换值}:换后值)
注意:正则只能匹配字符串的值,如果DF数据中有int类型,则不能匹配
#正则只能匹配字符串
df4 = pd.DataFrame([np.array(['a','1'])],columns=list('AB'))
print(df4.replace(regex=['a'],value=100))
print(df4.replace(regex=['\d'],value=100))
print(df4.replace({'A':'a'},'qqqqqqq'))
2、pandas函数应用
新建一个函数,返回传入值的和
def func(x):
return np.sum(x)
新建一个Series对象和一个DataFrame对象
ser1 = pd.Series(np.random.randint(-10,10,10),index=list('abcdefghij'))
df1 = pd.DataFrame(np.random.randint(-10,10,(4,5)),index=list('abcd'),columns=list('ABCDE'))
print(ser1)
print(df1)
返回如下
调用函数
df1.loc['和',:]=df1.apply(func)
print('求和:',df1)
在此调用该函数,DF对象以列的方式传输进去,也就是说返回的是每列的和(默认按照列输入,也可以设置axis每行输入)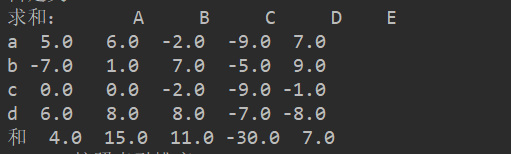
3、pandas排序
print('######按照索引排序############')
print(ser1.sort_index()) #默认按照升序进行排序
print(ser1.sort_index(ascending=False)) #按照降序
print('#######按照值进行排序##########')
print(ser1.sort_values()) #升序
print(ser1.sort_values(ascending=False)) #降序
#dataframe默认是按照列排序,如果要按行排序需要设置axis='columns'
print(df1.sort_values(by='a',axis='columns'))














 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









