







大模型基础知识
Embedding
Embedding是将离散的符号(如单词、字符等)映射到连续的向量空间中的技术。在大模型中,Embedding通常用于将自然语言文本或其他离散数据转换为可以输入到神经网络中的实数向量。
Embedding的目的是将语义上相似的符号映射到向量空间中相近的点。这样,模型可以通过计算向量之间的距离或角度来衡量符号之间的相似性。
Embedding的实现方式多种多样,但其中最著名且广泛使用的是Word2Vec算法,它包含两种主要的训练方式:Skip-gram和CBOW(Continuous Bag of Words)。这些算法通过预测上下文中的单词(Skip-gram)或根据上下文预测中心词(CBOW)来学习词向量。

一个自翻译网路嵌入的框架如图所示
-
内容丰富网络(Content-rich network): 这部分由节点构成,每个节点代表一个文本数据点。节点之间的连线表示文本间的相似性或相关性。这种网络结构有助于捕捉文本间复杂的关系和上下文信息。
-
平行序列(Parallel Sequences): 图中的“V1”和“V2”代表两个不同的文本序列,箭头指示了信息可能从“V1”传递到“V2”,或者反之。这反映了在自翻译过程中源语言和目标语言之间的对应关系。
-
内容到顶点自我翻译(Content-to-vertex self-translation): 这一步骤涉及到将原始文本(内容)转换成相应的嵌入顶点(矢量)。这个过程可能是通过随机游走或其他算法来为每个文本数据点生成一个嵌入向量。
-
随机游走(Random walk): 随机游走是一种算法,用于在图结构中生成或采样路径。在这个框架中,它可能被用来探索内容丰富网络中的节点,并创建有助于学习嵌入的信息丰富的路径。
-
嵌入(Embedding): 这部分关注如何将原始的文本数据点映射到低维空间中的嵌入向量。这些嵌入向量捕捉了文本的特性,同时保留了语义上的相似性。
-
Seq2Seq(Sequence to Sequence): 虽然没有在图中直接提到,但通常自翻译网络会使用Seq2Seq模型架构,该架构包括编码器和解码器,用于处理序列数据的转换任务。
-
网络嵌入向量(Network embedding vectors): 代表与特定文本数据点相关联的网络嵌入向量。这些向量是最终输出,它们可以用于后续的任务如文本分类、聚类或自翻译等。
MLP
MLP(Multi-Layer Perceptron)多层感知机是一种前馈神经网络,由一个或多个全连接层组成。每个全连接层包含一组可学习的权重矩阵和偏置向量,用于将输入数据进行线性变换和非线性激活。MLP可以用于各种任务,如分类、回归等。
在大模型中,MLP通常作为基本的网络组件,用于构建更复杂的结构。例如,在Transformer中,前馈神经网络部分就是一个MLP。此外,MLP还可以与其他网络结构(如卷积神经网络)结合,形成更强大的模型。
典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的( 全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
如图所示

Transformer
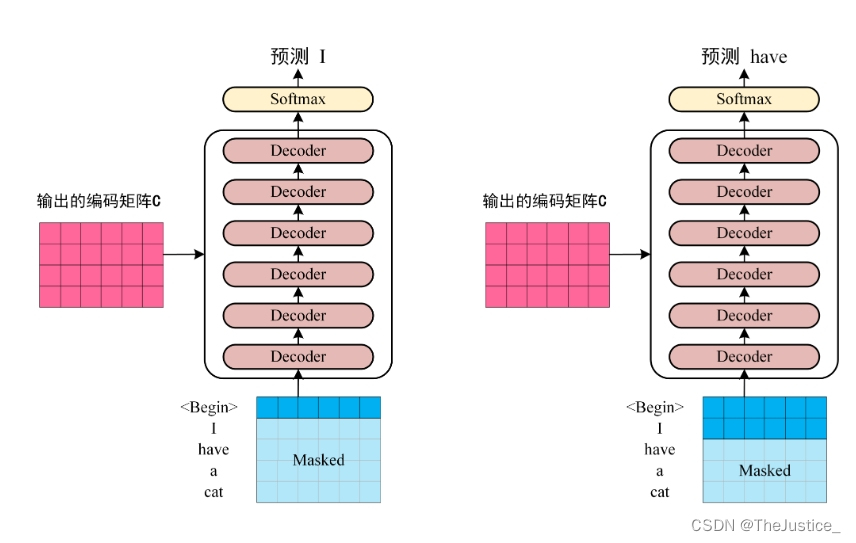
Transformer是一种基于自注意力机制(Self-Attention Mechanism)的神经网络架构,最初由Vaswani等人在2017年提出,用于解决序列到序列(Sequence-to-Sequence)的问题。Transformer的主要特点是放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),而是完全依赖于自注意力机制来捕捉输入序列中的长距离依赖关系。
Transformer的核心组件是自注意力层(Self-Attention Layer),它允许模型在不同位置的输入之间建立动态的关联。自注意力层的输出是一个加权和,其中权重是根据输入之间的相似性计算得到的。这使得模型能够关注到与当前位置相关的其他位置的信息。
除了自注意力层,Transformer还包括前馈神经网络(Feed-Forward Neural Network)和残差连接(Residual Connection)等组件。这些组件共同构成了Transformer的编码器(Encoder)和解码器(Decoder)部分,分别用于处理输入序列和生成输出序列。

Qwen2架构主要内容
整体介绍
 如图所示
如图所示
tokenizer将文本转为词表里面的数值。- 数值经过
embedding得到一一对应的向量。 attention_mask是用来看见左边、右边,双向等等来设定。- 各类下游任务,
Casual,seqcls等,基本都是基础模型model后面接对应的Linear层,还有损失函数不一样。
DecoderLayer

Forward
- 首先复制一份
hidden_states为residual,然后将hidden_states送入Norm,再送入attn模块。 - 得到
attn的输出后,再复制一份residual,再将hidden_states送入Norm,mlp,再与residual进行相加。最后输出的就是这个hidden_states啦。
Attention

Forward
- 首先将
hidden_states送入Linear中得到query、key与value。 - 使用旋转位置嵌入操作
rotary_emb,使用了旋转位置嵌入的余弦和正弦部分,将他们与query和key相乘,并将结果相加,从而实现旋转位置嵌入的效果。 - 将
key_states和value_states重复group次,再执行dot attn操作。 - 在
dot attn操作后得到attn_weights,加上attention_mask从而实现读取掩盖操作,在经过softmax与value_states相乘。得到attn_output。 - 再将上述的
attn_output进行reshape操作,送入o_proj,得到最终的输出。
GQA

主旨:GQA和MQA不需要在推理的过程存储那么多的kv cache, 那么kv cache占用的显存就变小,那么我们LLM serving可以处理的请求数量就更多
repeat-kv
在标准的多头自注意力机制中,输入的特征会被投影成 Query (Q),Key(K)和 Vale(V),然后分成多个头独立计算注意力。每个头都有自己的 Q,K和 V,并在每个头内部进行自注意力计算。这种方法虽然有效,但计算量较大,特别是对于大规模模型和长序列数据
repeat-kv技术主要是通过重复使用键(K)和值 (V)来优化计算。在这种技术中,K和V在组内注意力头之间是共享的。而查询(Q)仍然是独立计算的。可以用卷积神经网络和全连接神经网络做对比。CNN中用卷积层代替了全连接层,而卷积层的卷积核就是权重共享的,每次特征提取他们都和同一个卷积核的相同的参数做卷积运算,最后通过反向传播来更新这个卷积核的权重。这样相比于全连接神经网络,能够大大的减少参数量。这里的repeat kv就是起到一个类似卷积核的作用,能够减少重复计算的次数。
位置编码
位置编码的含义是对每一个token的每一个dim赋予不同的位置信息。

概念:通过旋转编码,使得每个token既有相对位置信息,又有绝对位置信息。
- 既能以自注意力矩阵偏置的形式作用于
直接反映两个token的相对位置信息,又能拆解到向量
和
上,通过直接编码token的绝对位置实现。
- RoPE本质是实现对特征向量的旋转操作,如果以二维特征向量举例,对于相邻两个token来说,其对应同一个
,其定义为:

可得,其本质就是: ,
旋转后的结果,就是
,
乘上cos再加上
,
翻转维度并取反一维后乘上sin。
- 对于高纬向量,由于奇、复数维度两两交错实现较为复杂,则现在可简化为将特征维度一切二,如下图所示,在实现过程中对前后各半进行的操作即为rotate_half操作:

MLP

输入hidden_state并行送入两个Linear层,其中一个激活一下,再与另一个相乘,最终再经过一个Linear,输出最终结果。
RMSNorm

是层的输入的
hidden_state表示的是
hidden_state的最后一个维度的值表示上面输入的最后一个维度的数量。
表示是很小的数,防止除0。














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









