






mysql的索引到底有几种? 有什么区别?
从网上搜到的资料 总说有聚簇索引,唯一索引,主键索引,联合索引,hash索引,全文索引??? 这么多类型到底是啥啊? 总感觉网上的内容看不懂,今天有机会接触到了一节mysql的课程总算是弄明白了;
mysql索引的数据结构
大家可能都知道mysql的索引数据结构是**B+ Tree,**那么为什么会选择B+? B+与B Tree之间又有什么区别? (这里不详细说数据结构,因为我也讲不清!!!)
索引, 我理解的功能就是利用索引能够快速的查询数据; 那么什么样的数据结构能够快速查询数据呢? 下面说几种数据结构, 二叉查找树, 红黑树, B树, B+树;
二叉查找树:
(1)若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值; (2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值; (3)左、右子树也分别为二叉排序树; 这上面是百度对于二叉查找树的描述,看个图就知道了; 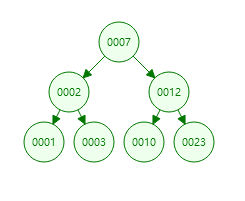 但是二叉树有个比较严重的问题是,在某些情况下会退化成链表结构,如下图:
但是二叉树有个比较严重的问题是,在某些情况下会退化成链表结构,如下图:  这里去查找节点为 7 的数据,就要6次才能查到了;
这里去查找节点为 7 的数据,就要6次才能查到了;
红黑树
红黑树(Red Black Tree) 是一种自平衡二叉查找树; 红黑树在数值插入时为了保持特性,所以需要左旋或者右旋操作来尽量维持平衡;  通过红黑树,查找节点 7,只需要3次了; 6->8->7; 很明显,这种数据结构在我们数据库存储动辄 十万,百万的数据量面前 还是会造成树过高从而导致查找次数过多的问题; 引入下一种数据结构 BTree
通过红黑树,查找节点 7,只需要3次了; 6->8->7; 很明显,这种数据结构在我们数据库存储动辄 十万,百万的数据量面前 还是会造成树过高从而导致查找次数过多的问题; 引入下一种数据结构 BTree
B Tree
百度上的文字解释实在看不懂,上个数据结构图再说一下我自己总结的特点吧;
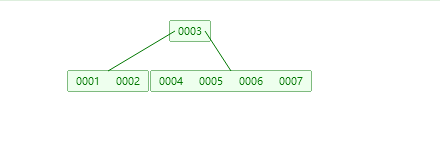
1.所有的元素不重复
2.所有节点的元素都是有序存放的
3.当达到节点的最大深度时会分裂
可以看到,使用这种数据结构已经大大减小了树的高度,而且由于元素是有序的在查询的时候可以基于算再次进行查询优化;
B+ Tree

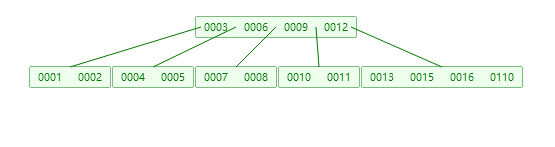
上面是一颗B + Tree, 它与B Tree的特点主要有几个:
1.叶节点存储着所有的数据
2.页节点之间使用指针连接,能够快速在叶节点中进行查找;
3.非叶子节点的数据是冗余的
mysql中实际的索引类型
mysql中使用B+ Tree作为索引实现的数据结构,但是在B+ Tree基础上也做了相应的改进; 
1.在原有B+ Tree基础上 叶节点增加了双向访问的功能;
2.在叶节点上存储所有的数据,也就说一颗B+ Tree, 一个索引 就保存了我们所有的数据; 前提是聚簇索引;
这里引出我们的第一种索引类型:聚簇索引;
mysql 在我们创建表时,会根据是否存在唯一字段 来创建聚簇索引, 当存在唯一字段时就使用这个字段,不存在时会默认生成一个row_id列作为聚簇索引; 我总结的聚簇索引是: 叶子节点存储所有的数据,那么这个索引就是聚簇索引;
非聚簇索引

在叶子节点上存储的是主键,拿到主键以后还需要去聚簇索引进行回表查询
总结: 索引从大类上来讲有聚簇索引和非聚簇索引, 区别是聚簇索引保存了整张表的数据,非聚簇索引只存储了聚簇索引的索引值

在创建索引的时候,可以看到索引类型常用的有 全文,普通,唯一,空间;
我理解的这些类型是小类型,限制字段; 比如经常用的唯一索引,就是用来限制这个字段的值不能重复;
B+Tree,Hash 属于索引的数据结构类型;
联合索引描述是否多个字段组成的索引,下面看一下联合索引的底层存储结构

上面的联合索引 以name,age,position 创建,也是B+Tree的数据结构; 首先依据 name排序, name相同则排序 age, age相同则排序position;
叶子节点存储的是记录的主键;
补充知识:mysql的索引和数据都以页来存储,每页是16KB;














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









