






本来想着不挖坑的,结果转眼半个月就没了,趁这两天有时间,赶紧把坑填一下……
--------------------------------------------------------------------------------分割线--------------------------------------------------------------------------------------------
前情提要
上一篇主要分析阐述了java中数据如何存储在堆、栈中,是为更好的解释传值、传引用做一个铺垫,本篇将以非常简单的方法调用作为切入点,来分析什么是值的传递,什么是引用的传递。
正文
众所周知,在java中,所有的方法可分为有参方法和无参方法两类,有参方法的参数按照java的数据类型分为两类——基本数据类型和引用数据类型,结合一篇的内容和传值、传引用的字面意思,我们应该能猜到,基本数据类型对应的是传值,引用数据类型对应的是传引用,我们可以笼统的理解为,传值和传引用其实就是调用有参方法时传入的参数。
看到这里,可能有的人就在想,参数传递就是参数传递,为什么还有传值和传引用之分呢?在讨论这个问题之前,我们应该先弄明白,在java中,一个有参方法的参数的作用是什么。举个例子:
class TheValue{
public void calculate(int number){
System.out.println(number);
}
}在TheValue这个类中,我们定义了一个公共的、参数为一个int类型的且无返回值的方法calculate,方法内我们直接将参数number打印出来。我们把重点放在方法参数的小括号内,抛去我们对方法的认知和其他干扰,很明显的,在参数小括号这个域内,我们声明了一个名为number的int类型的变量,上一篇我们说过,在java中,所有的变量都必须声明初始化之后才可以使用,但是现在calculate方法参数的小括号内这个变量number并没有初始化,而且,这样的方法定义是完全没有问题的,那是不是java中对方法参数的域有特殊的处理?实则不然,看代码:
public class ValueTest {
public static void main(String[] args) {
int numberA ;
}
}在java中,所有的变量都必须声明初始化之后才可以使用,换句话说,当我们要使用这个变量的时候,这个变量必须声明且初始化,很明显,ValueTest类中main方法的numberA变量并未被使用,它的初始化与否并不会影响到整个应用程序的健康运行。那这和方法中参数未初始化又有什么关系呢?上代码:

在main方法中,声明一个int类型的变量numberA(不予初始化),然后在创建一个TheValue类型的对象value,执行value对象的calculate方法,传入变量numberA,这个时候,大家肯定都很清楚,编译器会明确的告诉我们,numberA这个变量需要先初始化。从代码中我们可以得知,真正使用到numberA这个变量的地方是TheValue类中的calculate这个方法,为什么在main方法中调用calculate这个方法的时候就已经抛出错误了呢?说到这里,我们需要重新认识一下方法调用的概念,(在《Thinking in java》一书中,作者将调用某个类或者某个对象的某个方法这一说法称为接口调用),一个可见方法的实质,其实是这个方法向外界暴露出的一个可调用接口,这个接口的作用就是告诉外界当前方法需要满足什么样的条件才能够执行(习惯起见,我们之后还是称之为方法调用)。让我们把上述代码转换的更直截了当一点:
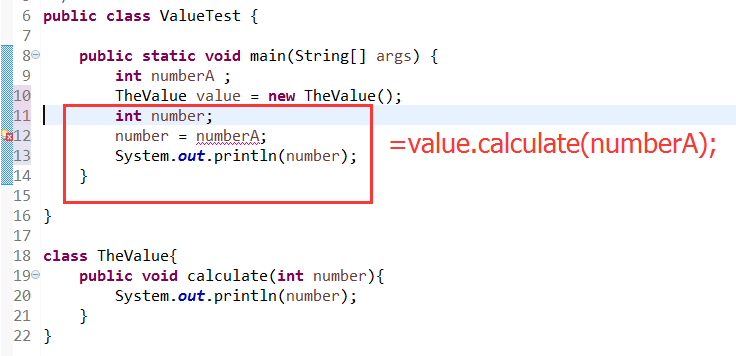
一目了然,调用对象value的calculate方法,传入numberA的值,相当于将numberA赋值给参数number,然后再执行打印语句,我们在进行方法调用的时候,会对方法的参数进行初始化操作,由于numberA并未初始化,所以在赋值操作的过程中,编译器便会抛出变量未初始化的错误,这完全符合编译器必须在程序运行之前知悉栈内所有数据项的生命周期这一原则。与此同时,我们也明白了方法参数在方法执行的过程中承担的是承上启下的角色,通俗一点来说,就是夹在外界和方法之间的一个传递参数的搬运工。
我们已经知道了方法参数的作用,接下来,说说什么是传值。
传值
细心的朋友可能已经发现,上述对方法参数的分析就是建立在传值的基础上,但并未深究其底层原理,现在让我们从栈内内存分配的角度来详细说明什么是传值。来,先让我们看个栗子(为了直观起见,代码中加入了注释):
public class ValueTest {
public static void main(String[] args) {
//声明一个int类型名为numA的变量,并赋初值10
byte numA = 10;
//声明一个int类型名为numB的变量,并将numA赋值给它
byte numB = numA;
}
}public class ValueTest {
public static void main(String[] args) {
//声明一个int类型名为numA的变量,并赋初值10
byte numA = 10;
//声明一个int类型名为numB的变量,并赋初值10
byte numB = 10;
}
}

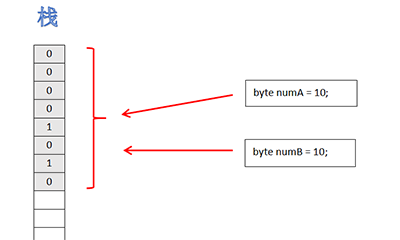
将numA赋值给numB,实质上就是将numA指向栈内值为10的地址传给numB并让numB也指向栈内值为10的地址,所以numA和numB是完全相等的;而给numB赋值10的操作的实质是:编译器在变量声明初始化的过程中,会首先检查栈内是否存在与当前变量类型一致、值相同的存储项,如果有就将新声明的变量指向栈内已有的相同存储项的地址,最后所得结果也是numA和numB是完全相等的。
所以这两个不同的赋值操作,实质上是等价的,接下来,让我们玩点不一样的:
public class ValueTest {
public static void main(String[] args) {
// 声明一个int类型名为numA的变量,并赋初值10
byte numA = 10;
// 声明一个int类型名为numB的变量,并将numA赋值给它
byte numB = numA;
// 对numB进行减法运算后再赋值给numB
numB = (byte) (numB - 5);
// 分别打印numA、numB
System.out.println("numA = " + numA);
System.out.println("numB = " + numB);
}
}
问题来了,按照我之前说的,numA和numB既然都同时指向同一栈内存储项,那为什么对numB进行运算赋值操作后,按理说numA的值也应该变为5,为什么numA的值没有变?而numB却又按照预期值变为5呢?看图:

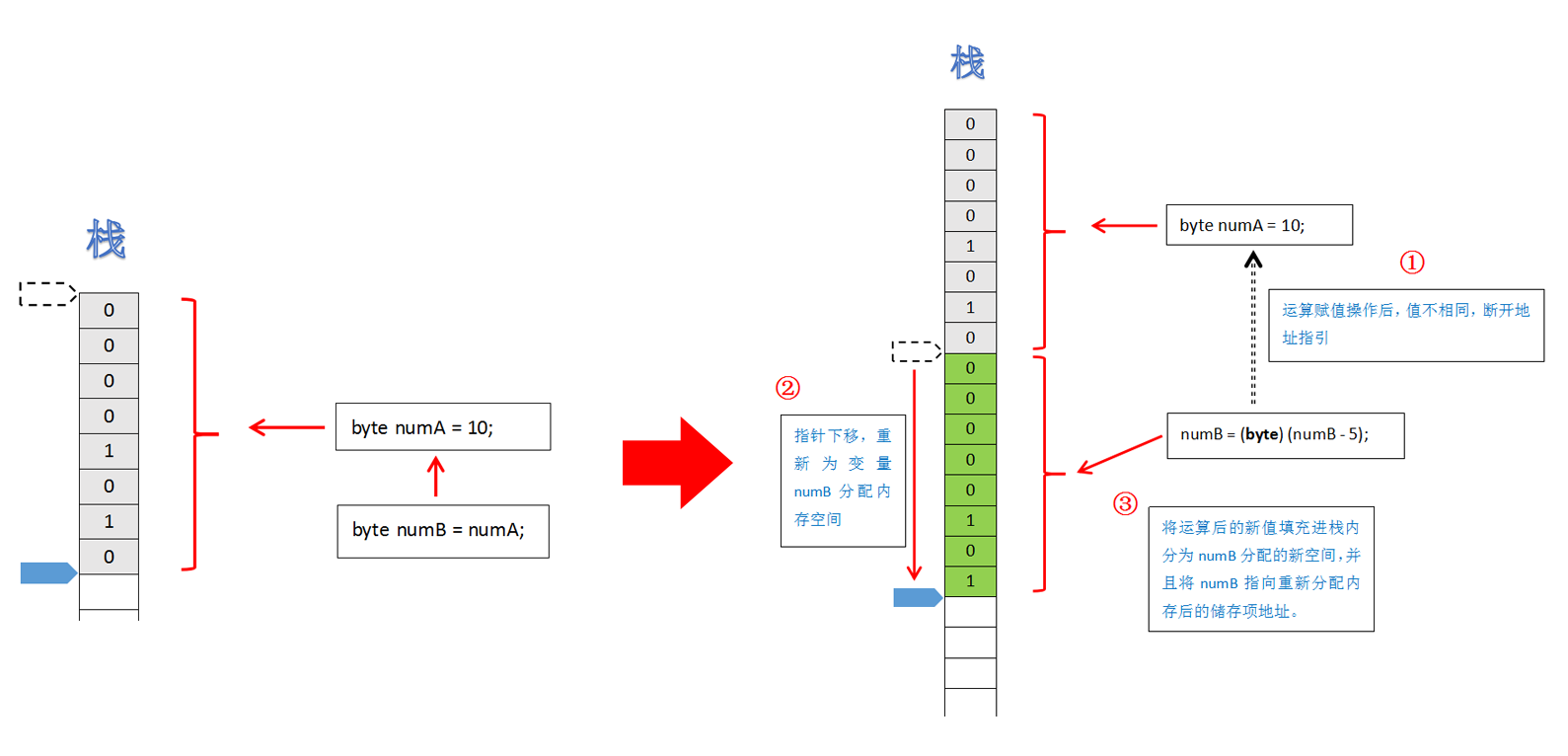
我们在对numB进行运算重新赋值后,很明显numB的值已经与numA的值不相等,所以,栈内的指针会往下移动,为numB重新分配一块大小为1byte的内存空间并且赋予5的二进制值,同时,numB将会指向栈内与之相匹配的内存项地址。再来个更复杂的测试:
/**
* 传值测试
*/
public class ValueTest {
public static void main(String[] args) {
// 声明一个int类型的变量numberA,并赋初值10
byte numberA = 10;
// 创建一个TheValue类型的对象value
TheValue value = new TheValue();
// 方法调用之前,先打印一次
System.out.println("numberA = " + numberA);
// 调用calculate方法,传入参数numberA
value.calculate(numberA);
// 在calculate方法执行之后,打印numberA
System.out.println("numberA = " + numberA);
}
}
class TheValue {
public void calculate(byte number) {
// 声明一个int类型的变量numberB,将方法参数的number赋值给numberB
byte numberB = number;
// 运算赋值操作之前,先打印一次
System.out.println("number = " + number);
System.out.println("numberB = " + numberB);
// 方法参数的number加上5之后再次赋值给number
number = (byte) (number + 5);
// numberB减去5之后,再次赋值给numberB
numberB = (byte) (numberB - 5);
System.out.println("******赋值操作分割线******");
// 打印结果
System.out.println("number = " + number);
System.out.println("numberB = " + numberB);
}
}

一开始的声明初始化方法调用操作,使得变量numberA、numberB和方法参数number的值都为10,且三个变量都指向栈内唯一存储项地址;当我们进行了运算赋值操作后,方法参数number,变量numberB的值都发生了变化,而变量numberA在对象value的calculate的方法调用之后,值并未发生改变。
综上所述:传值可以理解为拿来主义。在栈内已经存在的数据项,java不会浪费性能做重复工作,当指向栈内同一数据项的不同变量的值发生改变时,java会为发生改变的变量重新匹配数据项或者重新分配内存空间,保证栈内数据的唯一性——这就是值的传递。
相对的,我们来说说传引用。
传引用
这次我们用面向对象的编程思想举个比较形象的例子:
/**
* 传引用测试
*/
public class ObjectTest {
public static void main(String[] args) {
// 创建一个狗对象
Dog dog1 = new Dog();
// 为dog1起个名字,并赋予它毛色
dog1.setName("哈士奇");
dog1.setColor("黑色");
// 打印dog1的基本信息
System.out.println("狗狗是一条" + dog1.getColor() + "的" + dog1.getName());
System.out.println("*************************************************");
// 重新声明一条狗,并将dog1赋值给dog2
Dog dog2 = dog1;
// 为dog2起个名字,并赋予它毛色
dog2.setName("萨摩耶");
dog2.setColor("白色");
// 将dog1和dog2的信息同时打印出来
System.out.println("狗狗是一条" + dog1.getColor() + "的" + dog1.getName());
System.out.println("狗狗是一条" + dog2.getColor() + "的" + dog2.getName());
}
}
看到这里,估计很多小伙伴们就已经一脸懵逼了,你这不按套路出牌啊!我明明只给dog2起了名字赋予了颜色,为啥dog1也跟着变了?来张图理理思路:
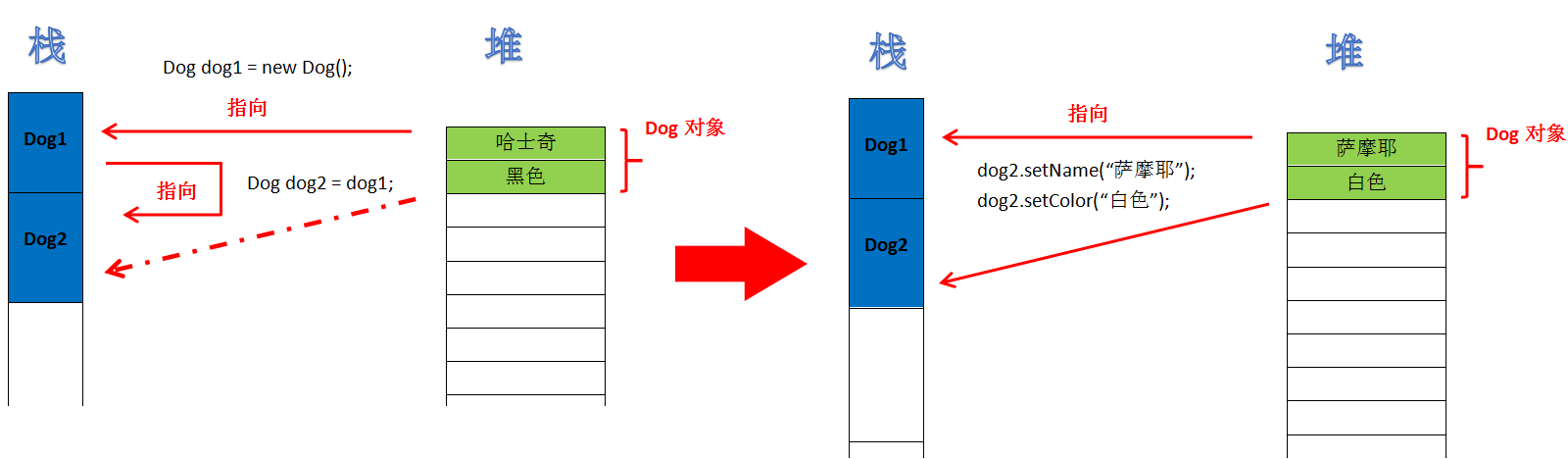
虽然我们声明了两个Dog类型的对象,但是new语句只执行了一次,也就是说,堆内只有一个Dog对象。
Dog dog2 = dog1;
这行代码的实际作用是将dog1所代表的堆内对象的地址赋值给dog2(为了验证这一说法,你可以尝试按照同样的编码,将dog1和dog2执行toString()方法的返回值打印出来,看是否相等)。这样一来,堆内的Dog对象便持有了两个对象引用(dog1和dog2所代表的是同一个对象),所以,我们调用dog2的get&set方法改变堆内唯一的Dog对象的属性,由dog1打印出来的对象属性也会随之改变。
举个更通俗易懂的例子:
小明和小红是一对龙凤胎,他们的父母给他们买了一条狗,让他们俩一起养,他们两个任何一个人改变这条狗的任何性状,所造成的影响对他们两个是共同的,因为他们两个拥有的是同一条狗,只不过在他们两个分别出去遛狗的时候,别人会说,小明你的狗真乖,或者是:小红你的狗真乖。狗是同一条狗,只不过在不同的环境下主语发生了变化,小明和小红就相当于对象引用,而这唯一的一条狗,就是对象本身。
由此看来,我们在引用传递(对象传递)的时候,一定要牢记赋值(=)语句只不过是复制了对象的引用(传引用),并没有new出新的对象,这样一来,你就能够确保你清楚的知道你当前操作的对象引用所代表的对象到底是哪一个,从而减少程序中一些难以发现的bug。
《【基础篇-堆栈】传值?传引用?(二)》就写到这里,本篇虽然说的是传值、传引用,但是并没有过多的叙述“传”,实质上还是在分析数据在堆、栈内的值的问题。这一篇也算是【基础篇-堆栈】的核心内容,整个【基础篇-堆栈】的全部内容应该还会有二到三章,我会在清明假期尽力的写完。
by The_Ashes















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









