







Redis七
1. 基数统计算法-HyperLogLog
为什么要使用 HyperLogLog?
在我们实际开发的过程中,可能会遇到这样一个问题,当我们需要统计一个大型网站的独立访问次数时,该用什么的类型来统计?
如果我们使用 Redis 中的集合来统计,当它每天有数千万级别的访问时,将会是一个巨大的问题。因为这些访问量不能被清空,我们运营人员可能会随时查看这些信息,那么随着时间的推移,这些统计数据所占用的空间会越来越大,逐渐超出我们能承载最大空间。
例如,我们用 IP 来作为独立访问的判断依据,那么我们就要把每个独立 IP 进行存储,以 IP4 来计算,IP4 最多需要 15 个字节来存储信息,例如:110.110.110.110。当有一千万个独立 IP 时,所占用的空间就是 15 bit*10000000 约定于 143MB,但这只是一个页面的统计信息,假如我们有 1 万个这样的页面,那我们就需要 1T 以上的空间来存储这些数据,而且随着 IP6 的普及,这个存储数字会越来越大,那我们就不能用集合的方式来存储了,这个时候我们需要开发新的数据类型 HyperLogLog 来做这件事了。
HyperLogLog 介绍
HyperLogLog(下文简称为 HLL)是 Redis 2.8.9 版本添加的数据结构,它用于高性能的基数(去重)统计功能,它的缺点就是存在极低的误差率。
HLL 具有以下几个特点:
- 能够使用极少的内存来统计巨量的数据,它只需要 12K 空间就能统计 2^64 的数据;
- 统计存在一定的误差,误差率整体较低,标准误差为 0.81%;
- 误差可以被设置辅助计算因子进行降低。
基础使用
HLL 的命令只有 3 个,但都非常的实用,下面分别来看。

添加元素
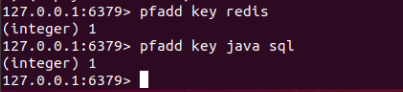
127.0.0.1:6379> pfadd key "redis"
(integer) 1
127.0.0.1:6379> pfadd key "java" "sql"
(integer) 1
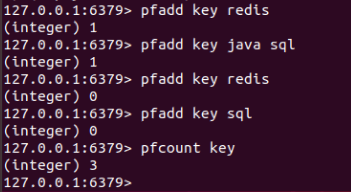
统计元素
pfcount key [key ...]
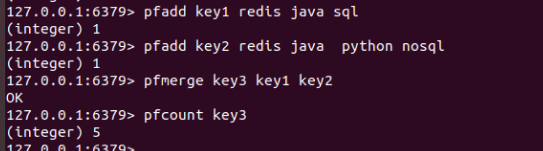
合并
此命令支持统计一个或多个 HLL 结构。
合并一个或多个 HLL 至新结构 新增 k 和 k2 合并至新结构 k3 中
pfmerge destkey sourcekey [sourcekey ...]
2. 布隆过滤器
们前面有讲到过 HyperLogLog 可以用来做基数统计,但它没提供判断一个值是否存在的查询方法,那我们如何才能查询一个值是否存在于海量数据之中呢?
如果使用传统的方式,例如 SQL 中的传统查询,因为数据量太多,查询效率又低有占用系统的资源,因此我们需要一个优秀的算法和功能来实现这个需求,这是我们今天要讲的——布隆过滤器。
开启布隆过滤器 在 Redis 中不能直接使用布隆过滤器,但我们可以通过 Redis 4.0 版本之后提供的 modules(扩展模块)的方式引入,本文提供两种方式的开启方式。
编译方式
下载并安装布隆过滤器
git clone https://github.com/RedisLabsModules/redisbloom.git
cd redisbloom
make # 编译redisbloom


编译正常执行完,会在根目录生成一个 redisbloom.so 文件。

启动 Redis 服务器
src/redis-server redis.conf --loadmodule ./src/modules/RedisBloom-master/redisbloom.so
其中 --loadmodule 为加载扩展模块的意思,后面跟的是 redisbloom.so 文件的目录。

启动验证
服务启动之后,我们需要判断布隆过滤器是否正常开启,此时我们只需使用 redis-cli 连接到服务端,输入 bf.add 看有没有命令提示,就可以判断是否正常启动了,如下图所示:

如果有命令提示则表名 Redis 服务器已经开启了布隆过滤器。
布隆过滤器的使用 布隆过滤器的命令不是很多,主要包含以下几个:
- bf.add:添加元素
- bf.exists:判断某个元素是否存在
- bf.madd:添加多个元素
- bf.mexists:判断多个元素是否存在
- bf.reserve:设置布隆过滤器的准确率
bf.add:添加元素
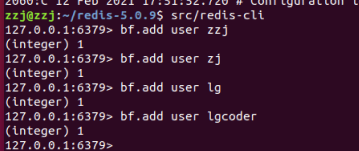
bf.exists:判断某个元素是否存在

bf.madd:添加多个元素

bf.mexists:判断多个元素是否存在

bf.reserve:设置布隆过滤器的准确率

小结
布隆过滤器 说有的不一定存在有一定的误差不过不大
它说没有的一定不存在
3. 缓存雪崩&缓存穿透
缓存雪崩
缓存雪崩是指在短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
我们先来看下正常情况下和缓存雪崩时程序的执行流程图,正常情况下系统的执行流程如下图所示:

缓存雪崩的执行流程,如下图所示:

缓存雪崩的常用解决方案有以下几个。
随机化过期时间
为了避免缓存同时过期,可在设置缓存时添加随机时间,这样就可以极大的避免大量的缓存同时失效。
加锁排队
加锁排队可以起到缓冲的作用,防止大量的请求同时操作数据库,但它的缺点是增加了系统的响应时间,降低了系统的吞吐量,牺牲了一部分用户体验。
缓存穿透
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
缓存穿透执行流程如下图所示:

其中红色路径表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成很大的压力。
缓存穿透的解决方案有以下几个。
使用过滤器
我们可以使用过滤器来减少对数据库的请求,例如使用布隆过滤器
缓存空结果
另一种方式是我们可以把每次从数据库查询的数据都保存到缓存中,为了提高前台用户的使用体验 (解决长时间内查询不到任何信息的情况),我们可以将空结果的缓存时间设置得短一些,例如 3~ 5分钟















 2068
2068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









