







Redis Module拓展模块
redis4.0以上版本,用户可以在redis定义自己的扩展module了,可以快速实现新的命令和功能。redis模块使用动态库,可以在redis启动的时候加载或者启动后使用命令加载,API定义在了一个叫redismodule.h的头文件里,可以使用c++或者其他c语言绑定的程序编写模块。
模块介绍
模块函数
编写拓展模块时,只需要#include "redismodule.h"这个文件就可以编写了(该头文件里定义了一些常量以及可以使用的API)。
模块里必须有一个RedisModule_OnLoad()函数,是模块入口点,可以在函数里自定义模块名、新命令、新数据类型等等:
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc);
解释:
ctx:上下文
argv:传入参数
argc:传入参数的个数
argv可以通过MODULE LOAD myModuleTest.so arg1 arg2传入,因此可以根据传入的参数使用不同的新命令RedisModule_OnLoad()函数里需要最先调用RedisModule_Init()函数,该函数用来注册函数名:
int RedisModule_Init(RedisModuleCtx *ctx, const char *modulename, int module_version, int api_version);
解释:
ctx:上下文
modulename:自定义模块名,不能跟已有的冲突
module_version:模块版本
api_version:api版本号注册新命令使用RedisModule_CreateCommand()函数,但必须要在RedisModule_OnLoad()里面使用:
int RedisModule_CreateCommand(RedisModuleCtx *ctx, const char *cmd_name, RedisModuleCmdFunc cmdfunc, const char *strflags, int firstkey, int lastkey, int keystep);
解释:
ctx:上下文
cmd_name:命令名称
cmdfunc:实现该命令的函数。例如下面例子中的mycommand()
strflags:命令标志。读,写等等,多个标志中间用空格分开
firstkey:第一个参数索引(索引是从1开始的,0表示命令无key)
lastkey:最后一个参数索引(负数表示从后开始,0表示命令无key)
keystep:第一个参数和最后一个参数之间的距离(0表示命令无key)实现自定义命令的函数原型:
int mycommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc);
解释:
ctx:上下文
argv:传入的参数。argv[1]才是用户传入的第一个参数,argv[0]是命令名
argc:传入参数的数量。命令无参数的时候argc为1模块可以被卸载,卸载模块时redis会自动注销命令和取消订阅消息,有时候命令里有一些持久内存或者配置,可以使用RedisModule_OnUnload()函数进行处理,在模块卸载的时候将被自动调用,函数原型:
int RedisModule_OnUnload(RedisModuleCtx *ctx);
正常应该返回REDISMODULE_OK,但是返回REDISMODULE_ERR可以阻止模块被卸载;有个一叫自动内存管理的函数RedisModule_AutoMemory(),在自定义函数的开始的地方调用该函数即可,因为通常c程序员需要自己管理内存,redis也提供了自动内存管理(会消耗一些性能),函数原型:
RedisModule_AutoMemory(ctx);示例
下面编写一个test.c测试Demo,用来实现将传入的数字乘以2后返回:
#include "redismodule.h"
int MyCmd(RedisModuleCtx *ctx, RedisModuleString ** argv, int argc)
{
if (argc != 2)
{
return RedisModule_WrongArity(ctx);
}
RedisModule_AutoMemory(ctx);
long long myparam;
//将字符串转换成数字
if (RedisModule_StringToLongLong(argv[1], &myparam) == REDISMODULE_OK)
{
RedisModule_ReplyWithLongLong(ctx, myparam * 2);
}
else
{
RedisModule_ReplyWithError(ctx, "ERROR wrong type of arguments");
}
return REDISMODULE_OK;
}
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv,int argc)
{
if (RedisModule_Init(ctx, "mymodule", 1, REDISMODULE_APIVER_1) == REDISMODULE_ERR)
{
return REDISMODULE_ERR;
}
if (RedisModule_CreateCommand(ctx, "mycmd", MyCmd, "readonly", 0, 0, 0) == REDISMODULE_ERR)
{
return REDISMODULE_ERR;
}
return REDISMODULE_OK;
}编译成so:执行gcc test.c -fPIC -shared -o test.so

使用redis-cli登录redis,加载so文件并测试新命令:

布隆过滤器
使用场景
比如用软件刷短视频时,如何做到每次推荐给该用户的内容不会重复,过滤已经看过的内容呢?你会说我们只要记录了每个用户看过的历史记录,每次推荐的时候去查询数据库过滤存在的数据实现去重。
实际上,如果历史记录存储在关系数据库里,去重就需要频繁地对数据库进行 exists 查询,当系统并发量很高时,数据库是很难扛住压力的。如果使用缓存,把历史数据存在 Redis 中,虽然这种做法能提高查询速度,但是会浪费大量得内存空间,显然这也不可取。
所以,这个时候我们就能使用布隆过滤器去解决这种去重问题。又快又省内存,互联网开发必备杀招!
当你遇到数据量大,又需要去重的时候就可以考虑布隆过滤器,如下场景:
- 解决 Redis 缓存穿透问题(面试重点);
- 邮件过滤,使用布隆过滤器实现邮件黑名单过滤;
- 爬虫爬过的网站过滤,爬过的网站不再爬取;
- 推荐过的新闻不再推荐;
布隆过滤器介绍
布隆过滤器:一种数据结构,是由一串很长的bit数组(bitmaps),可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。

布隆过滤器判断数据是否存在:当布隆过滤器判定某个数据不存在,则该数据肯定不存在;当判定某个数据存在,则该数据可能存在。
布隆过滤器可以插入元素,但不可以删除已有元素。
其中的元素越多,false positive rate(误报率)越大,但是 false negative (漏报)是不可能的。
布隆过滤器原理
首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
添加元素
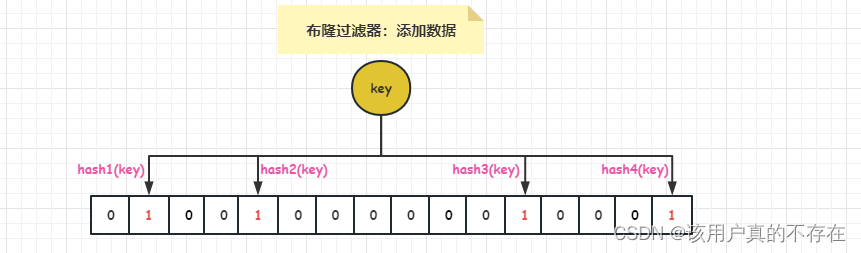
当要向布隆过滤器中添加一个元素key时,我们通过N个hash函数,算出一个值,然后将这个值所在的方格置为1。
比如,下图hash1(key)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(key)=7,那么将第8个格子置位1,依次类推。
判断元素是否存在
检测 key 是否存在,仍然用这 N 个 hash 函数计算出 N 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
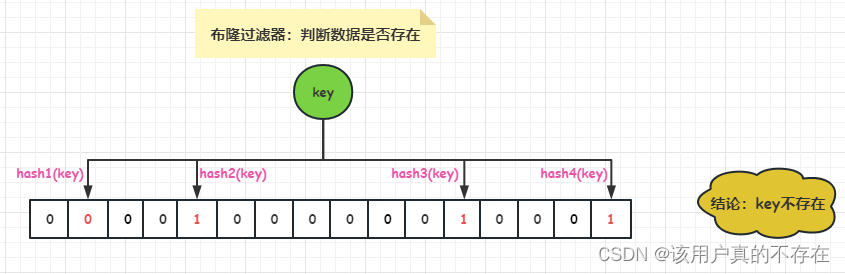
哈希函数会出现碰撞,所以布隆过滤器会存在误判。例如:布隆过滤器添加了key1,bit数组对应的1、3、5、7位都是1;然后判断key2是否存在,经过hash后,发现bit数组对应的位置也是1、3、5、7,这些位现在都是1,布隆过滤器会判断key2存在,实际上key2是不存在的。这就会造成误判。
为什么布隆过滤器不支持删除元素呢?
删除意味着需要将对应的 N 个 bits 位置设置为 0,其中有可能是其他元素对应的位。因此,不允许删除。
布隆过滤器的优缺点
优点:优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
缺点:随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
布隆过滤器的安装
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
make
cp redisbloom.so /path/to
vi redis.conf
MODULE LOAD /path/to/redisbloom.so布隆过滤器命令
【核心命令】添加元素:BF.ADD(添加单个)、BF.MADD(添加多个)、BF.INSERT(添加多个);
【核心命令】检查元素是否存在:BF.EXISTS(查询单个元素)、BF.MEXISTS(查询多个元素)
| 命令 | 功能 | 参数 |
| BF.RESERVE | 创建一个大小为capacity,错误率为error_rate的空的Bloom | BF.RESERVE {key} {error_rate} {capacity} [EXPANSION expansion] [NONSCALING] |
| BF.ADD | 向key指定的Bloom中添加一个元素item | BF.ADD {key} {item} |
| BF.MADD | 向key指定的Bloo向key指定的Bloom中添加多个元素 | BF.MADD {key} {item} [item…] |
| BF.INSERT | 向key指定的Bloom中添加多个元素,添加时可以指定大小和错误率,且可以控制在Bloom不存在的时候是否自动创建 | BF.INSERT {key} [CAPACITY {cap}] [ERROR {error}] [EXPANSION expansion] [NOCREATE] [NONSCALING] ITEMS {item…} |
| BF.EXISTS | 检查一个元素是否可能存在于key指定的Bloom中 | BF.EXISTS {key} {item} |
| BF.MEXISTS | 同时检查多个元素是否可能存在于key指定的Bloom中 | BF.MEXISTS {key} {item} [item…] |
| BF.SCANDUMP | 对Bloom进行增量持久化操作 | BF.SCANDUMP {key} {iter} |
| BF.LOADCHUNK | 加载SCANDUMP持久化的Bloom数据 | BF.LOADCHUNK {key} {iter} {data} |
| BF.INFO | 查询key指定的Bloom的信息 | BF.INFO {key} |
| BF.DEBUG | 查看BloomFilter的内部详细信息(如每层的元素个数、错误率等) | BF.DEBUG {key} |
# 创建一个容量为5且不允许扩容的过滤器;
127.0.0.1:6379> bf.reserve bf2 0.1 5 NONSCALING
OK
#向布隆过滤器添加多个元素
127.0.0.1:6379> bf.madd bf2 1 2 3 4 5
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 1
5) (integer) 1
# 添加第6个元素时即提示BloomFilter已满;
127.0.0.1:6379> bf.madd bf2 6
1) (error) ERR non scaling filter is full
#查询布隆过滤器信息
127.0.0.1:6379> bf.info bf2
1) Capacity
2) (integer) 5
3) Size
4) (integer) 155
5) Number of filters
6) (integer) 1
7) Number of items inserted
8) (integer) 5
9) Expansion rate
10) (integer) 2
#查看5是否存在
bf.exists bf2 5
(integer) 1
# 批量检查多个元素是否存在
127.0.0.1:6379> bf.mexists bf2 3 4 5
1) (integer) 1
2) (integer) 1
3) (integer) 1
#插入元素。
#EXPANSION:布隆过滤器会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以expansion。
#NONSCALING:不会扩容过滤器
127.0.0.1:6379> bf.insert bfinsert CAPACITY 5 ERROR 0.1 EXPANSION 2 NONSCALING ITEMS item1 item2
1) (integer) 1
2) (integer) 1
HyperLogLog
使用背景
网站日活月活
日活:每天一个HLL,用户登录时则PFADD HLL20200719 userID;
月活:合并当月的所有日活数据,PFMERGE HLL202007 HLL20200701 HLL20200702 HLL20200703 …
网页UV
UV(Unique Visitor)独立访客:1天内;cookie为标识;相同的客户端多次访问只计为1个访客。
比如老板想实时查看公司网站某些页面从今天0点到现在被多少独立访客访问。
其他场景
- 搜索引擎关键词搜索量;
- 用户在线人数统计;
- 基于基数计数的数据分析场景。
跟Bitmaps对比
假设需要统计1亿用户的日活,如果使用bitmaps,则需要10^8 / (1024 * 1024 * 8) ≈ 12M空间,但是大型互联网公司除了日活,还有UV、PV等等需要统计。面对上千甚至更多的需统计模块,1个模块1天需要12M,一年就需要12M * 365 / 1024 ≈ 4.3G ,1000个模块一年就需要 12M * 365 / 1024 / 1024 ≈ 4.2T。
因此,可以使用占用空间更小的HyperLogLog。
HyperLogLog简介
HyperLogLog(HLL)是一种用于基数计算的概率数据结构,通俗的说就是支持集合中不重复元素的统计。
常规基数计算需要准备一块内存空间用于存储已经计数的元素,避免某些元素被重复统计。Redis提供了一种用精度来换取内存空间的算法,标准误差低于1%。仅需要12K 就能完成统计(再加上HLL自身所需的一点bytes),如果HyperLogLog中的元素较少,所需内存空间更小。HyperLogLogs的标准误差是0.81%。
HyperLogLog虽然技术实现是一种 不同的数据结构,但底层依旧是Redis strings,所以可以使用GET命令获取序列化后的数据,使用SET命令反序列化数据存储到Redis。
在 Redis 的HLL中 共有 16384( )个桶,而每个桶是一个 6bit 的数组;数据被hash 生成 64位整数,其中后 14 位用来索引桶子;前面 50位 共有
用来统计累计0的个数;保 存对数的话最大值为 49;6位对应的是
对应整数值为 64 可以容纳存储 49;

让我们看下执行 pfadd key value 实际的例子:
假设hash值是 :{此处省略45位}011 0000 0000 0000 0101
- 前14位的二进制转为10进制,值为5(regnum),即我们把数据放在第5个桶;
- 后50位第一个1的位置是3,即count值为3;
- registers[5]取出历史值oldcount,
- 如果count > oldcount,则更新 registers[5] = count;
- 如果count <= oldcount,则不做任何处理;
去重:相同元素通过hash函数会生成相同的 64 位整数,它会索引到相同的桶子中,累计0的个数也会相同,按照上面计算最长累计0的规则,它不会改变该桶子的最长累计0;
HyperLogLog存储策略
redis 中的 hyperloglog 存储分为稀疏存储和紧凑存储:
- 当元素很少的时候,redis采用节约内存的策略,hyperloglog采用稀疏存储方案;
- 当存储大小超过 3000 的时候,hyperloglog 会从稀疏存储方案转换为紧凑存储方案;
紧凑存储不会转换为稀疏存储,因为hyperloglog数据只会增加不会减少(不存储具体元素,所以没法删除);
HyperLogLog和Set的区别
| 对比/数据类型 | Set | HyperLogLog |
| 是否实际存储统计元素 | 存储 | 不存储元素,仅存储存在的标记 |
| 增加元素 | SADD | PFADD |
| 统计元素数量 | SCARD | PFCOUNT |
| 删除元素 | SREM | 不支持删除元素 |
HyperLogLog核心命令
| 命令 | 功能 | 参数 |
| PFADD | 添加元素到HLL数据结构 | key element [element …] |
| PFCOUNT | 返回HLL的基数值 | key [key …] |
| PFMERGE | 合并多个HLL结构数据到destkey | destkey sourcekey [sourcekey …] |
HLL操作命令中的PF含义:HyperLogLog 数据结构的发明人 Philippe Flajolet 的首字母缩写。
// pfadd、pfcount 示例 @zxiaofan
127.0.0.1:6379> pfadd hll 1
(integer) 1
127.0.0.1:6379> pfadd hll 1
(integer) 0
127.0.0.1:6379> pfadd hll 2 3 4
(integer) 1
127.0.0.1:6379> pfcount hll
(integer) 4
127.0.0.1:6379> pfadd hll2 a b
(integer) 1
127.0.0.1:6379> pfcount hll2
(integer) 2
127.0.0.1:6379> pfcount hll hll2
(integer) 6
127.0.0.1:6379> get hll
"HYLL\x01\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00A\xee\x84[v\x80Mt\x80Q,\x8cC\xf3"
127.0.0.1:6379> pfadd hllm1 1 2 3 4 5
(integer) 1
127.0.0.1:6379> pfadd hllm2 5 6 7 8
(integer) 1
127.0.0.1:6379> pfmerge hllm3 hllm1 hllm2
OK
127.0.0.1:6379> pfcount hllm3
(integer) 8
127.0.0.1:6379> pfadd hllm4 7 8 9 10 11 12 13 13
(integer) 1
127.0.0.1:6379> pfmerge hllm4 hllm1 hllm2
OK
127.0.0.1:6379> pfcount hllm4
(integer) 13
漏斗限流
当今社会,互联网公司的流量巨大,系统上线前需要对系统进行全面的流量峰值评估,以判断系统所能承载的最大瞬时请求数,尤其是像各种秒杀促销活动,为了保证系统不被巨大的流量压垮,会事先评估系统最大请数,并设置限流逻辑,以便在系统流量到达设定的阈值时,拒绝掉这部分流量,从而确保系统不会崩溃。
对于限流有很多方式,最经典的几种就是,计数器法、滑动窗口、漏斗法、令牌桶等,下面要讲的是采用Redis + Lua脚本实现限流。
什么是漏斗限流
漏斗的结构特点:容量是有限的,当漏斗水装满,水将装不进去;水从漏嘴按一定速率流出,当流 水速度大于灌水速度,那么漏斗永远无法装满;当流水速度小于灌水速度,一旦漏斗装满,需要阻 塞等待漏斗腾出空间后再灌水。
所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,流水速度代表着系统允许该行为的 最大频率。
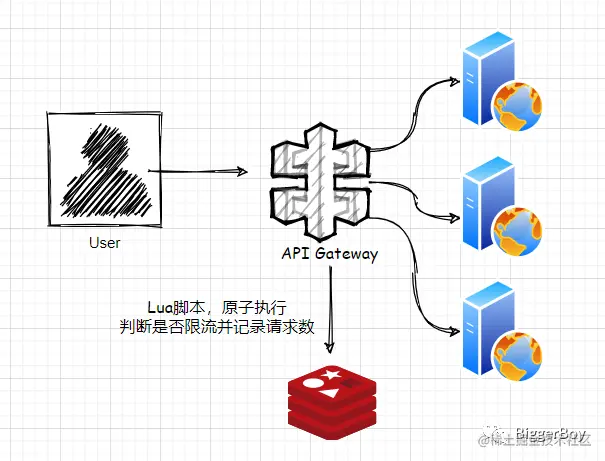
将限流信息存储在分布式环境中某个中间件里(比如redis),每个组件都可以从这里获取到当前时间的流量统计,从而决定是否放行还是拒绝。
使用lua脚本的优点:Redis 将整个Lua脚本作为一个命令执行,原子,无需担心并发。
-- 获取调用脚本时传入的第一个key值(用作限流的 key)
local key = KEYS[1]
-- 获取调用脚本时传入的第一个参数值(限流大小)
local limit = tonumber(ARGV[1])
-- 获取当前流量大小
local curentLimit = tonumber(redis.call('get', key) or "0")
-- 是否超出限流
if curentLimit + 1 > limit then
-- 返回(拒绝)
return 0
else
-- 没有超出
value + 1
redis.call("INCRBY", key, 1)
-- 设置过期时间
redis.call("EXPIRE", key, 2)
-- 返回(放行)
return 1
end
Redis-Cell
Redis-Cell 是一个扩展模块,它采用 rust 编写;它采用了漏斗算法,并提供了原子的限流指令; 该模块只提供了一个指令 cl.throttle ;该指令描述了允许某用户某行为的频率为每 x 秒 n 次行 为(流水速度)。
#安装:
# 源码安装 然后按照 readme.md 编译安装
git clone https://gitee.com/yaowenqiang/redis-cell.git
# bin安装 如下网址下载相应平台的 .so 动态库文件
https://github.com/brandur/redis-cell/releases
cp libredis_cell.so /path/to
vi redis.conf
# loadmodules /path/to/libredis_cell.so
#语法:
# key 为某漏斗容器
# capacity 为某漏斗容器容量
# operations 为单位时间内某行为的操作次数
# seconds 为单位时间 operations / seconds = 流水速度
# quota 单次行为操作次数 默认值为 1
cl.thottle key capacity operations seconds quota
#测试:
CL.THROTTLE cell 1 1 10 1
1) (integer) 0 # 0 标识允许 1 表示拒绝
2) (integer) 2 # 漏斗容量
3) (integer) 1 # 漏斗剩余空间
4) (integer) -1 # 如果被拒绝了,需要多长时间后再试(单位秒)
5) (integer) 10 # 多长时间后,漏斗完全空出来
参考文献:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









