







目录
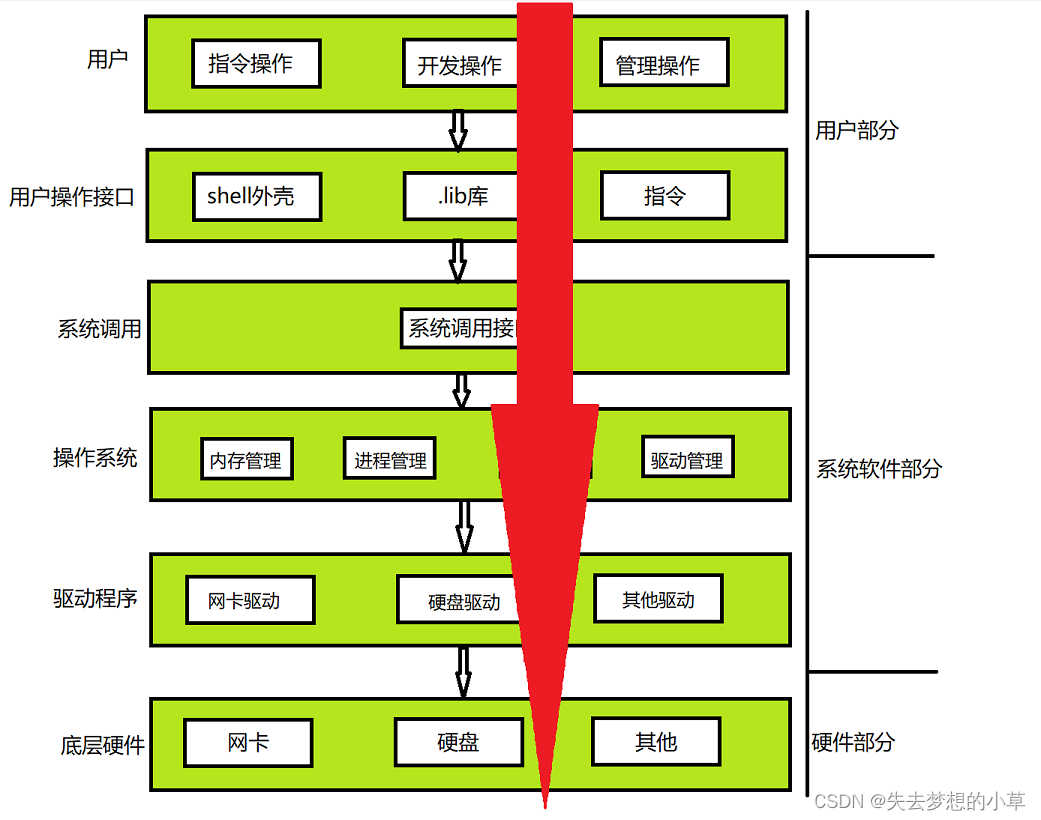
操作系统如何进行软硬件资源管理?
为了方便理解,这里一个简化的学校模型来模拟操作系统对软硬件资源的管理
学校模型里有三种角色:校长-管理者,学生-被管理者,辅导员
校长为了管理学生,执行决策,需要知道学生的信息,如果校长自己一个个询问学生的信息会非常麻烦,效率非常低,所以需要辅导员,辅导员帮助校长获取学生的信息,所以这里辅导员对于获取信息这项事务来说就是执行者
对应到计算机中,校长就是操作系统,辅导员就是驱动程序,学生就是软硬件资源,驱动程序能够获取、控制软硬件资源,比如:网卡驱动,从网卡中读取到无法连接到网络,将这个信息告诉操作系统,操作系统多次尝试修复,若无法修复,就暴露给用户——“网卡故障,请及时更换网卡”
回到学校模型,校长获取学生的信息是为了做出决策,但在数据量过大的时候,就算是校长拿到这些数据,也很难做出决策,所以为了管理这些数据,校长把数据放进了一个excel表格,通过学生的属性(共性):姓名、电话、籍贯、学号等作为表头,然后把学生的具体信息放到后面,我们去思考有哪些共性,做出excel表格表头的过程,就是一个描述学生的过程,如果这个校长是一个程序员,那么他就会把这些属性放到一个struct Student{};里面,所有的信息,比如通过一个单链表链接起来,此时,我们对学生做出管理,也就是对这个单链表做增删查改
对应到计算机中,操作系统为了能够高效的管理底层的硬件,对设备的管理,也就转换成了对数据结构的增删查改
这里贡献出六字金言:先描述,后组织,先描述,后组织就是——操作系统如何管理的解法
我们为了管理不同类型的设备,操作系统会先描述不同的设备,使得这些不同类型的设备能够放到同一个数据结构中,给每个设备构建出属于该设备的对象,使用数据结构把这些对象链接起来,我们对设备进行操作,也就是对数据结构进行增删查改,这个过程也就是组织的过程,所以操作系统中一定写了大量的数据结构,以便操作系统使用合适的数据结构描述、组织这些设备。
系统调用和库函数概念
思考:我们使用printf(“hello world”);把字符串打印到屏幕上,printf是代码,是软件层的东西,屏幕上进行显示,是硬件层的东西,我们并没有直接与硬件打交道,整个过程如下:开发时调用printf函数,printf来自.lib库,库中实现printf的时候使用了系统调用接口,进而通过操作系统、驱动程序,最终把hello world打印在硬件 - 屏幕上,这整个过程会贯穿整个计算机。
库函数与系统调用接口的关系?上下层关系,库函数在上层,系统调用接口在下层
我们能否直接使用系统调用接口?可以,只不过难度较大
进程
进程概念
我们从上面处理了解了操作系统如何进行软硬件资源管理,而操作系统中就有一块数据结构是用来管理程序中的执行实例(正在执行的程序)的,也就是进程管理
这里也会涉及到先描述后组织
也就是先有描述进程的结构体,该结构体的一个结构体对象,就是一个进程,将这些对象通过数据结构组织起来,就是对数据结构进行增删查改
我们后续就从Linux系统中学习进程相关的内容
ps ajx —— 可以查看所有进程的信息
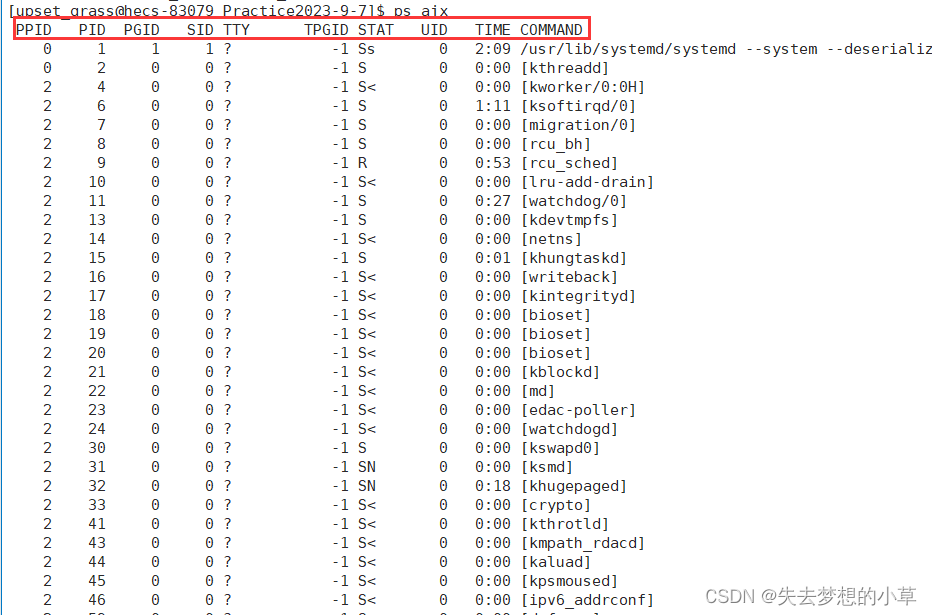
第一排就是进程结构体中主要的属性:PPID、PID、STAT、TIME …
后面的每一排都是一个进程,
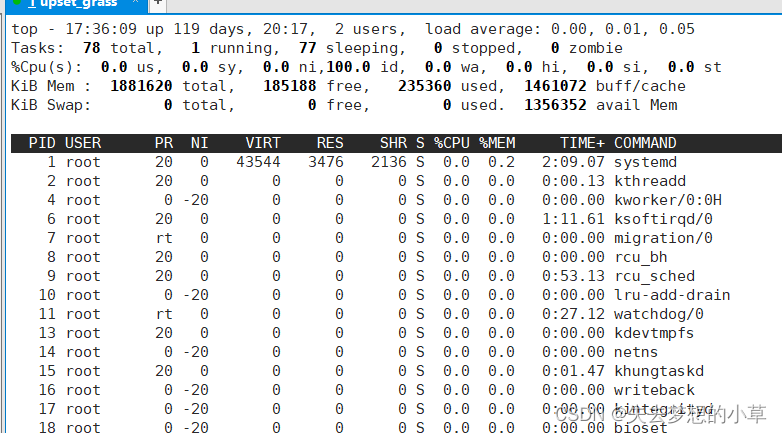
除了ps ajx以外,还有top —— Linux下的任务管理器,一样的可以查看进程相关的信息
我们这里写一个程序
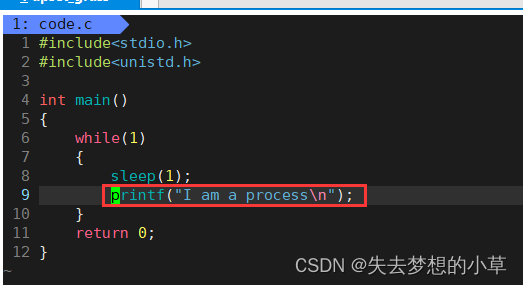
然后运行这个程序,然后再在xshell中开一个会话,去查看我们自己运行起来的这个程序
ps ajx | head - 1 —— 拿到头, ps ajx | grep code.exe,打印含有code.exe的所有行
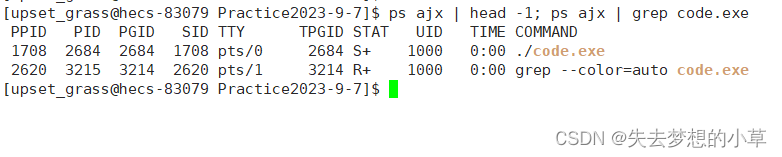
这些进程是磁盘文件中加载到内存中变成的进程
这里就必须清楚:磁盘中的程序,运行起来后其实是CPU在运行我们的代码,只要CPU在跑我们的代码,我们的程序必须要加载到内存中,因为CPU只能通过内存获取代码
CPU在不执行我们的进程时,也会检查我们的计算机的状态,释放计算机资源,将内存中的数据定期刷新到磁盘中这些日常管理工作,那么操作系统本身,也需要在内存中,所以开机的时候,本质上就是在启动操作系统,把操作系统从外设加载到内存中
我们此时来看看磁盘文件加载到内存中变成进程:
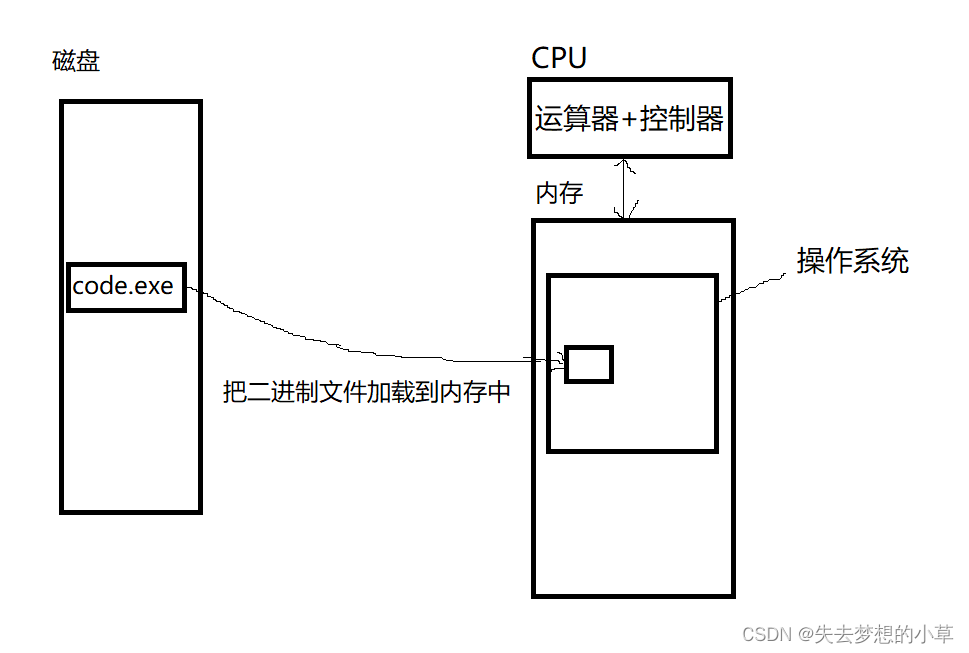
一个程序是由数据和代码构成,数据和代码都是数据,数据比如int a = 4,4 就是数据,char c = ‘a’, 'a’就是数据,所有的代码while循环,switch选择,if判断,define定义,最终都会归为二进制文件,只不过一部分二进制表示的是数据,另一部分表示的是代码,是数据的交给运算器,是代码的交给控制器执行
我们需要知道一个操作系统,经常需要同时运行多个进程,所以操作系统必须把进程管理起来,让资源能够得到合理的利用
PCB
我们描述进程的结构体为PCB(process ctrl block),在很多地方也称进程为任务
任何一个程序,在加载到内存的时候,形成真正的进程时,操作系统要先创建描述进程PCB结构体对象
我们为了描述进程,给定了进程PCB结构体以下属性:进程编号(唯一)、状态(运行、休眠、维护…)、优先级(调度)、指针信息、…
除了为该进程创建对应的PCB结构体对象,还需要把该进程对应的代码和数据,加载到内存当中,所以我们上图需要进行修改
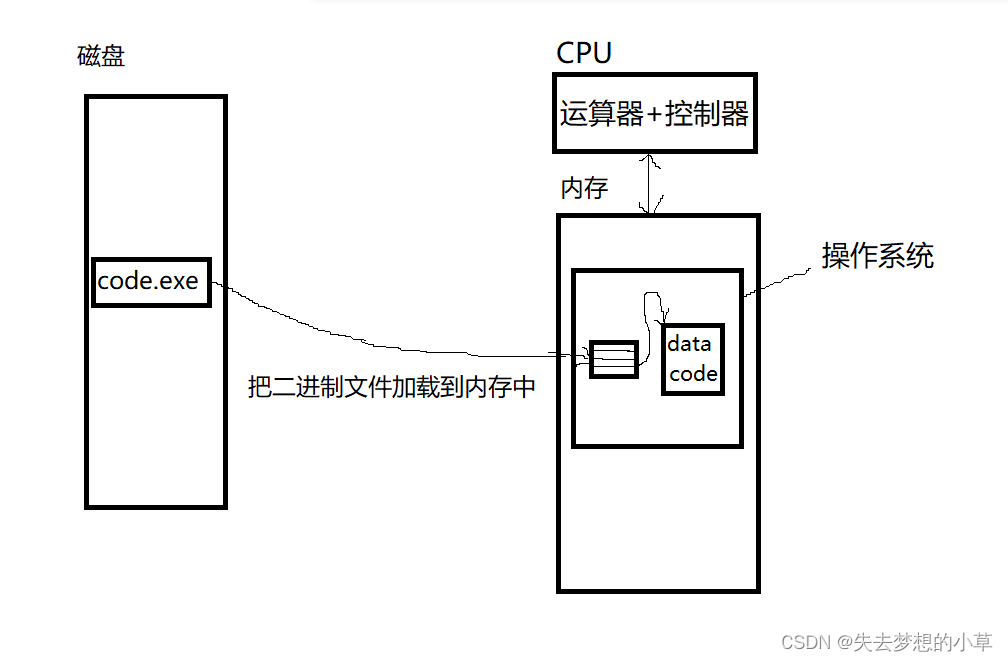
也就是说进程PCB结构体中是有一个指针指向了程序(代码 + 数据)的,使得进程可以在正确的时间执行数据和代码
关于程序 = 代码 + 数据,代码也就是int for while {} main这些程序内的标识符,数据也就是int b = 10的那个10,当然,这些标识符和后面的10,都会被转换成二进制,所以宏观来讲,代码和数据都是数据,我们后面会涉及单独涉及代码和单独涉及数据,所以我把程序的这两部分给分开
所以我们这里在说进程是什么?进程PCB结构体对象 + 对应的Code&&Data
操作系统是通过内核PCB数据结构对象来进行管理,操作系统不会看我们写的二进制代码和数据
不同PCB结构体对象是通过一个struct PCB* next;指针链接起来的,所以我们从管理一个个PCB结构体对象,变成了管理整个进程单链表,也就是对整个进程单链表进行增删查改
Linux下的进程
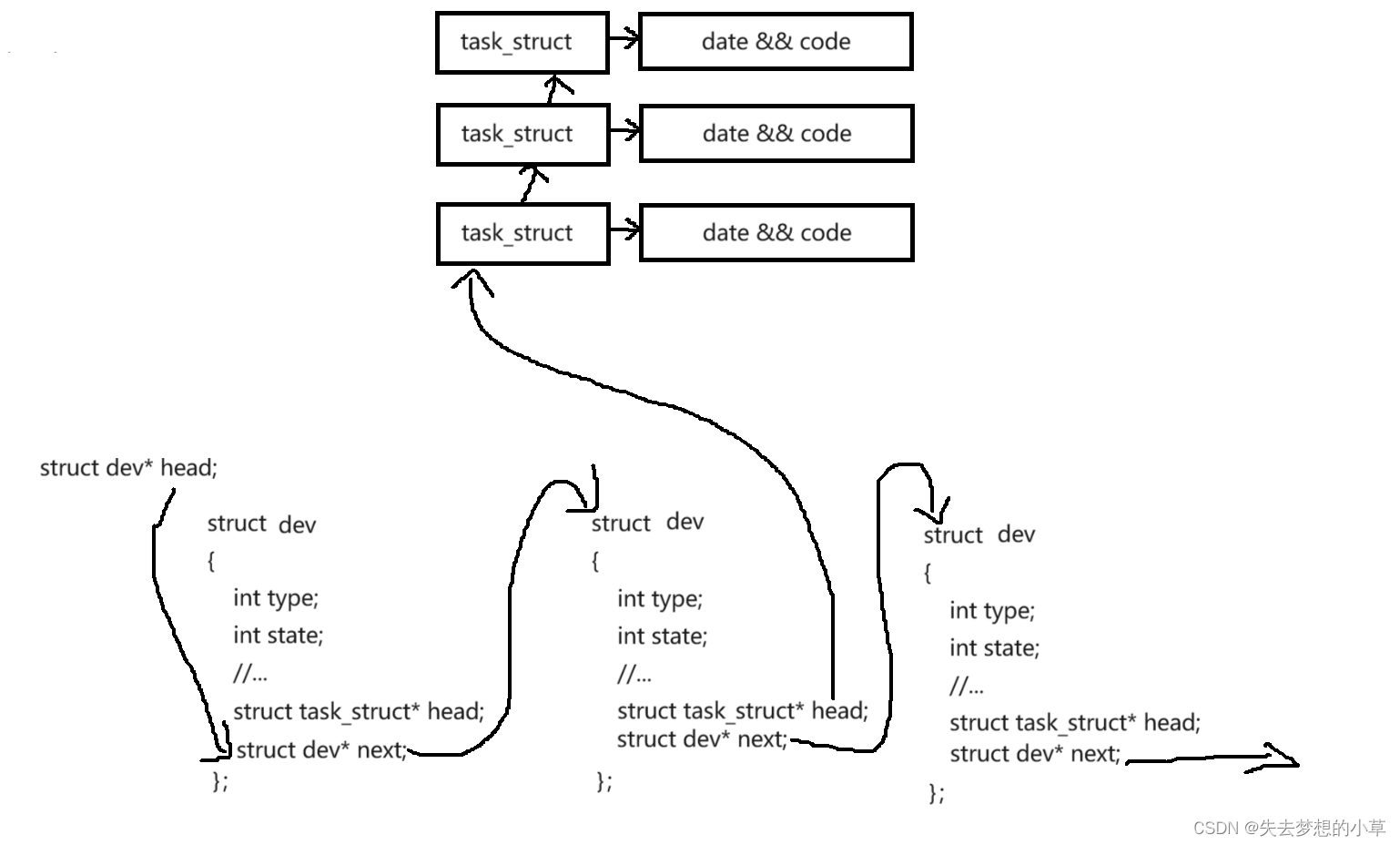
不同平台上进程控制模块都叫PCB,但是实现逻辑都不太相同,在Linux下,PCB结构体命名为task_struct,task_struct是Linux内核中的一种数据类型,是结构体类型,它会被装载到RAM(内存)里并且包含着进程的属性信息
下图是网上找来的task_struct中的属性信息,这还不全,我们只需要关注一些主要的属性

这里我们简单了解一下主要的属性有些啥,大体是干啥的:
1、标识符信息:PID,用于区分于其他进程(还有副进程,进程组)
2、状态:任务状态,新建的,正在运行,暂停,死亡…
3、优先级:竞争CPU的顺序
4、程序计数器(PC指针):表征当前程序运行到哪一行,用于被中断、暂停时重新唤醒后继续操作 - 程序中即将执行的下一条指令的地址
5、内存指针:程序代码和进程相关的数据的指针,还有和其他进程共享的内存块的指针
6、记账信息:CPU运行时长,保持进程之间资源分配的公平(衡量调度器的优劣)
…
Linux中是如何组织进程的?Linux内核中,最基本的组织进程task_struct的方式,采用双向链表组织
但PCB结构体对象不仅仅属于某个双链表,可以把PCB结构体对象链到双链表中,同时也可以把PCB结构体对象放在队列中,同时还能放在搜索二叉树中,也就是一个节点可能属于双链表,也可能属于二叉树,也可能属于队列…
struct task_struct{
......
struct task_struct* list
struct task_struct* que
struct task_struct* tree
};
根据需求,把PCB放在某一个组织的数据结构中,想让进程去等待,就把PCB放到等待队列,想让进程去运行,就把PCB链入到运行队列中,想查找某个进程,就把进程放到AVL树、红黑树中,对进程的管理工作,取决于放到哪一个在组织的数据结构当中,数据结构背后是配套的算法,配套的算法背后是具体的应用场景。
进程唯一标识符PID(process ID)
我们ps ajx查看进程进行
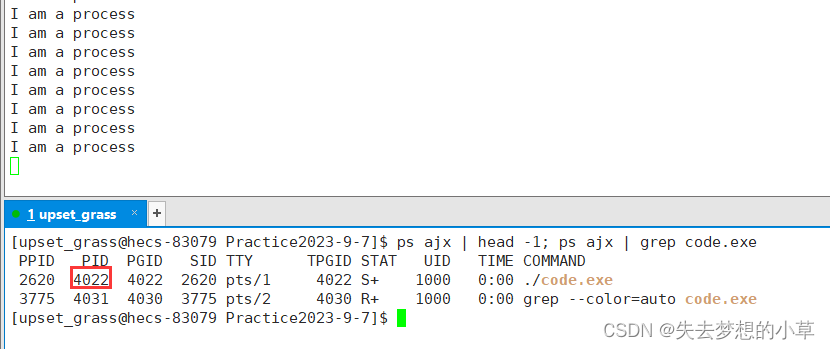
这里的4022就是该进程的唯一标识符PID,我们可以ls /proc查看当前的所有进程PID,在task_struct中是用int来存储的

这里我们看到这些PID,是操作系统通过文件管理系统的方式,把内存中的信息可视化出来的
关机之后,这里的数据都会消失——运行程序时,都是加载到内存中进行运行的,而内存中的数据是通过电子元件存储和维持的,如果断电,内存中的电流也会消失,随之数据也就消失了,放在磁盘中的数据是依靠磁介质存储的,磁不需要电就能长期稳定的保存信息,所以保存在磁盘上的信息不会丢失(除非你给摔咯,摔坏咯)
我们此时在Xshell中多开几个页面
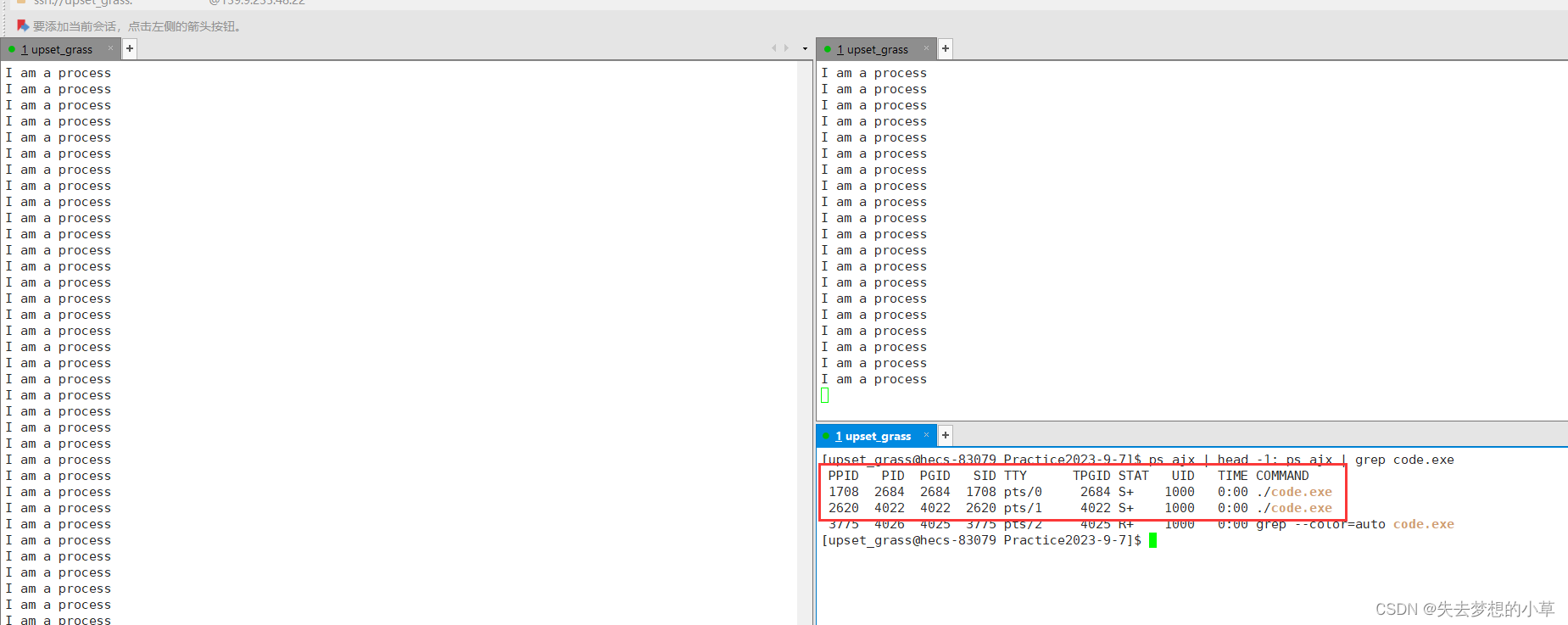
发现这里多了一条进程,也就说明同一个程序,运行两次,是两个进程,两次的PID也不同,比如我们在windows下开了多个word页面,开了多个QQ,其底层就会有多条进程,下图所示
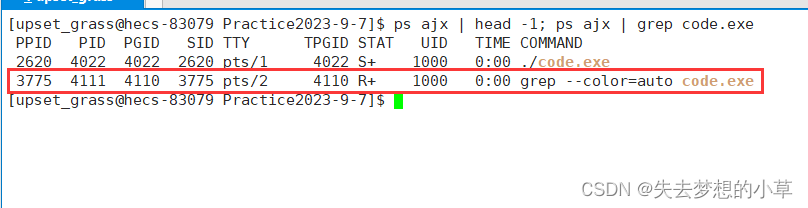
我们再来看看这一条,grep是一条指令,运行grep也需要加载到内存中变成一条进程,因此在过滤的同时,也在进程列表中,需要注意的是这里显示在进程列表的是由于ps ajx | grep code.exe这一条指令,前面的ps ajx | head -1已经执行完成了,已经不是进程了,如果我们在另一个会话中用top实时检测进程的话,是有小概率能够看到接连一闪而过的两个关于grep的进程的
当然我们可以用grep的-v选项——反向选择,不去显示这一行无关信息,再加一个管道,进行一个grep筛选
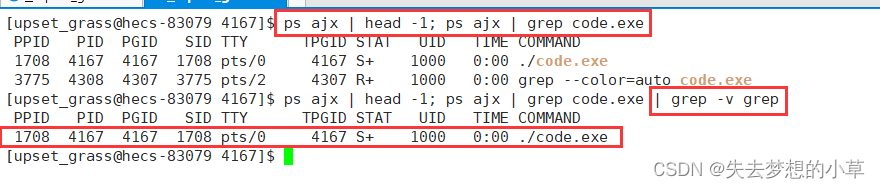
我们再来看看前面的ls /proc
我们观察详细,会发现这些PID其实是一些目录
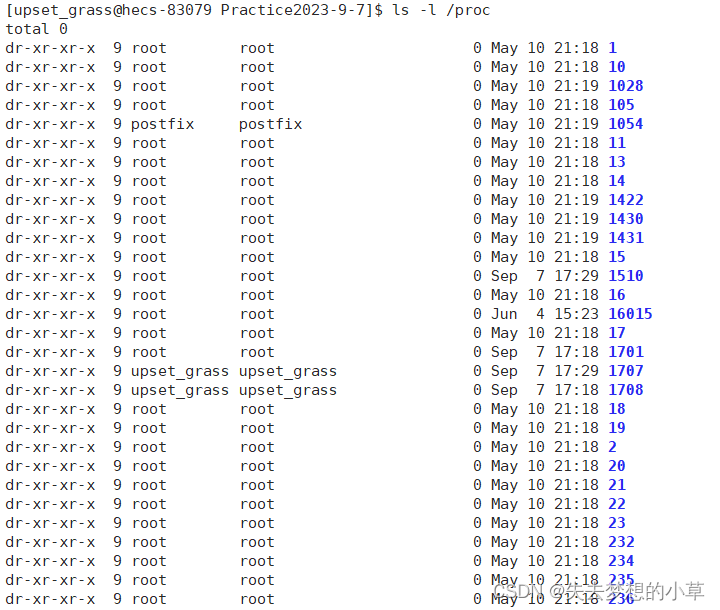
PID的数字是我们把程序运行到内存中变成进程时才会出现的,并不是固定的数字,在我们结束进程后,再次运行该程序,下一次的PID会发生变化
我们是可以进入这些目录查看PID中存储的进程的大部分属性,虽然现在里面的信息基本我们还看不懂
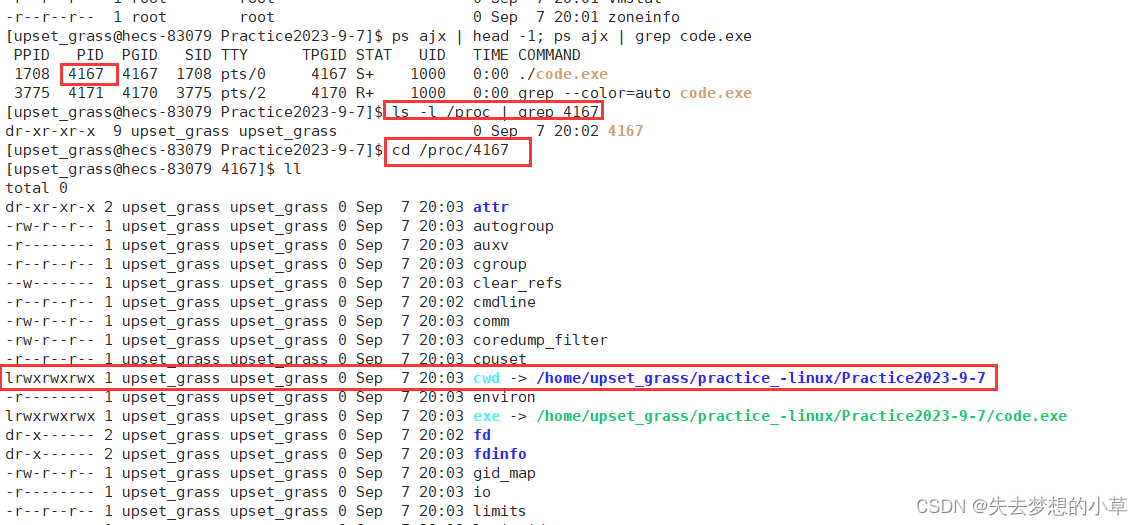
我们浅浅的看一个cwd——current work directory
比如:执行touch test.c命令时,会加载到内存中成为一条进程,touch命令是无法靠指令自身知道test.c应该创建在哪里的,需要靠PCB中的PID目录中存储的当前工作目录cwd,然后就能够通过cwd/test.c来获取创建位置
再比如:我们在代码中用fopen(“code.c”, “w”) 打开code.c,同样也是需要cwd辅助定位到当前目录
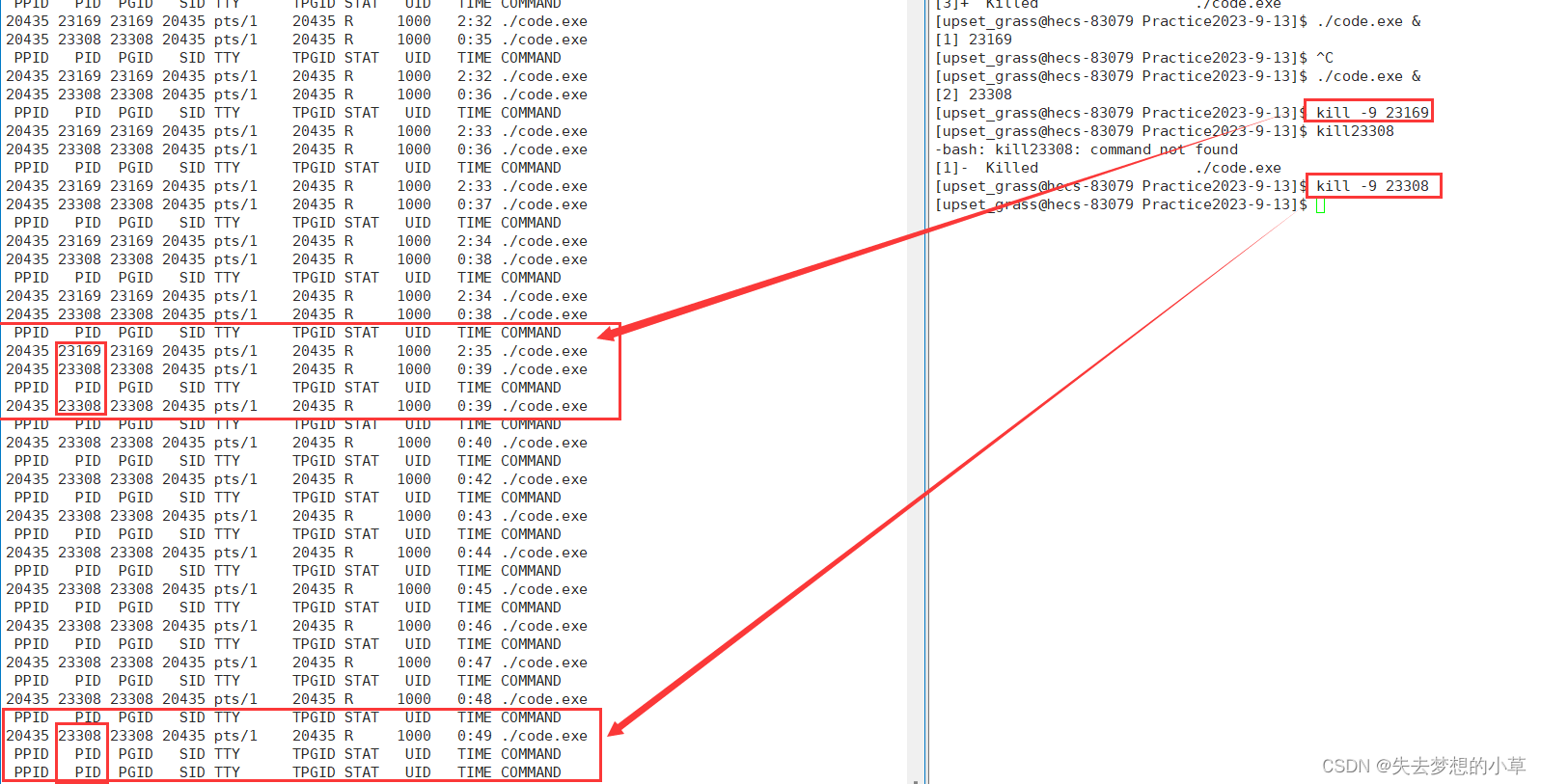
我们还能够通过PID终止掉程序
kill -9 [PID] —— 向[PID]发送9号信号
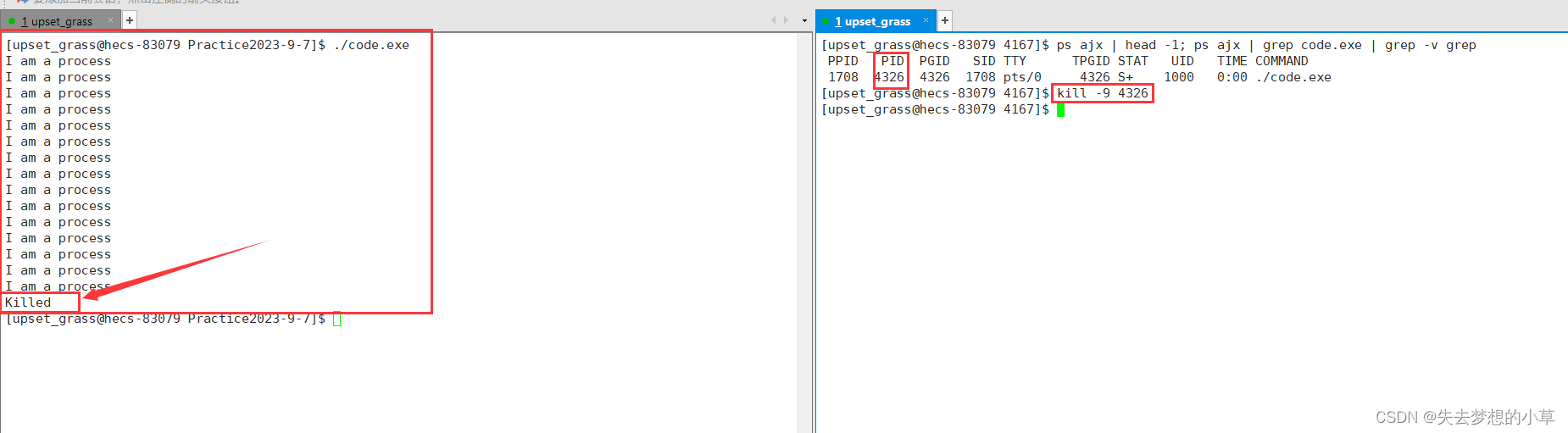
这就能解决有些程序一直无法清除,就可以用ps ajx | head -1 ; ps ajx | grep [文件名] 获取到PID,然后通过kill -9 指令,“杀掉”程序
除了用指令来获取PID,Linux的系统调用还有接口getpid()能够获取PID
运行代码,发现确实能够获取到当前进程的PID

ps ajx | head -1中除了PID还有前面的PPID,PPID是父进程ID,我们也有系统调用接口getppid(),我们在程序中加入这个getppid()
运行起来,发现PPID是1708,也就是父进程的PID是1708
我们ps ajx | grep 1708,查看父进程,发现COMMAND是-bash,-bash不就是命令行解释器吗,不就是一种shell外壳吗?这里我们好像能够窥探到一些东西…

我们这里用一个脚本语言来实时查看进程信息来帮助理解:
while :; do ps ajx | head -1 ; ps ajx | grep code.exe |grep -v grep; sleep 1;done
不需要完全理解这个脚本语言,只需要知道整个脚本的组成 while :; do (XXXXXX) done —— while:; do和done是作为无限循环的开始与结尾,中间可以放多条需要循环的指令
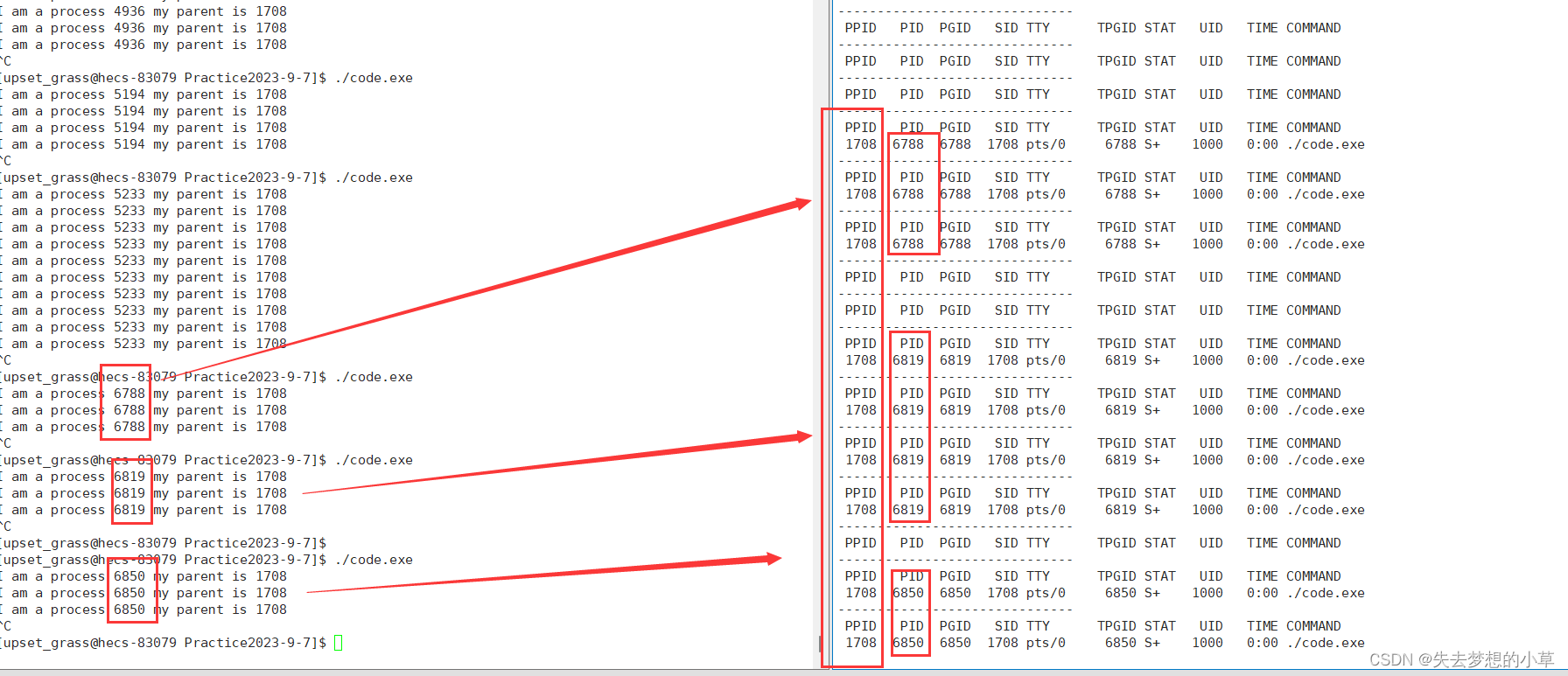
我们多次执行./code.exe指令,然后实时查看PPID和PID,会发现:PPID一直不变,但是PID一直会发生变化
我们简单解释解释为什么PPID一直不变:
bash进程是针对每一个会话创建的,只有在关闭该会话,才会结束该-bash进程,所以我们能看到PPID一直不变
如果我们关闭了该会话,再重新打开了一个会话,这个bash进程的PID就会发生变化了,或者我们换了一个user登陆,也会发现多了一条-bash
下图中我们总共有四个会话,也就有四个-bash进程

有的人可能还会思考:我们之前的图两个会话中的PPID也就是-bash不是一样的吗?
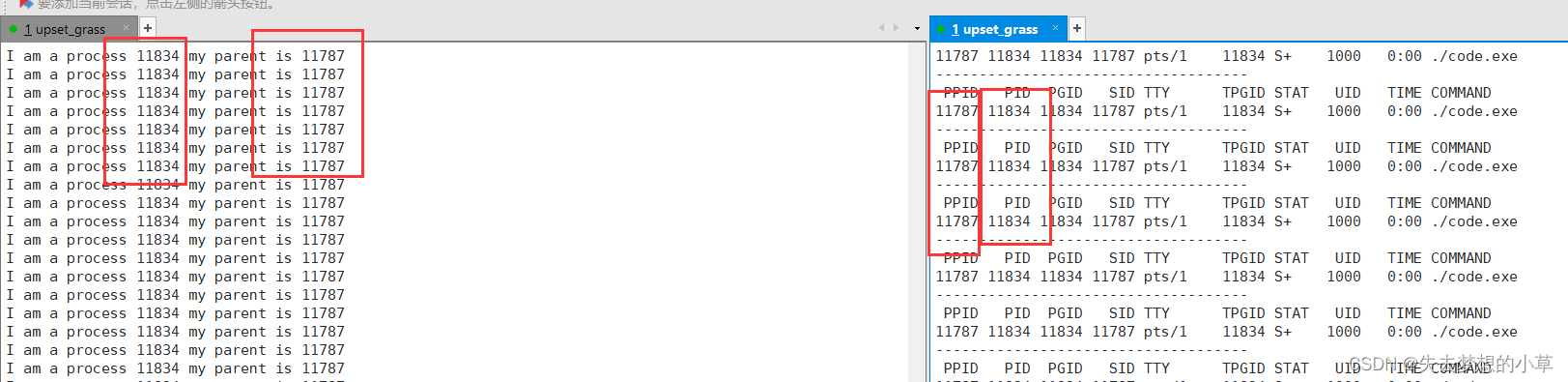
比如这张图中:我们是运行了左边的code.exe文件,其自身有一个PID11834,其父进程的PPID11787,我们右侧的通过ps ajx | grep code.exe拿到的左边code.exe的进程(程序中没有其他的同名进程,有的话右边能观察到多条进程), 所以PPID显示的是左边会话的bash进程,而右边会话的进程我们可以直接通过ps ajx | grep bash来获取到,或者还是代码中使用getppid()获取该会话的父进程PPID
命令行解释器,其核心是帮助获取用户的输入,帮助用户进行命令行解释,在我们运行一个进程时,我们的命令行解释器会把我们的输入变成bash的子进程,由子进程执行对应的命令,所以当我们子进程出了问题,崩溃了,并不会影响bash进程,相当于儿子出事了,不会影响爸爸(再生一个就行了bushi :) ),但爸爸出事了,一定会影响儿子,关于这一点,后面在讲fork()的时候会更加科学的讲解
每次我们使用一个会话时都会给我们创建一条bash进程-命令行解释的进程,这样多个会话的指令就可以互不干扰、互不冲突,我们在用命令行解释器运行的命令都是bash的子进程,bash只负责命令行的解释,不负责子进程出错的情况
fork
fork是一个系统调用接口,在一个程序中创建以自身为父进程的子进程
不管那么多,我们先在程序中使用使用这个接口,感受感受
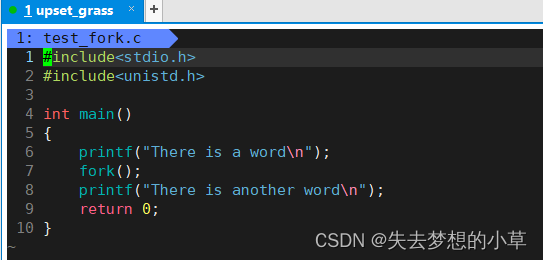
我们运行起来发现,upset_grass@hecs… There is another word,这里打印了两次There is another word
我们修改程序,加上sleep(1)
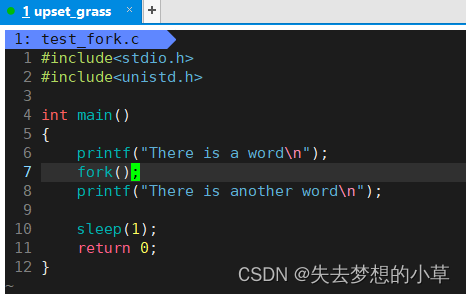
然后再次运行代码
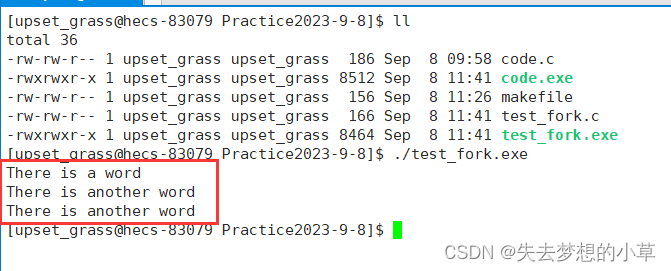
这样就能够先打印,然后再出现命令行解释行[upset_grass@hecs-83079 Practice2023-9-8]$ …
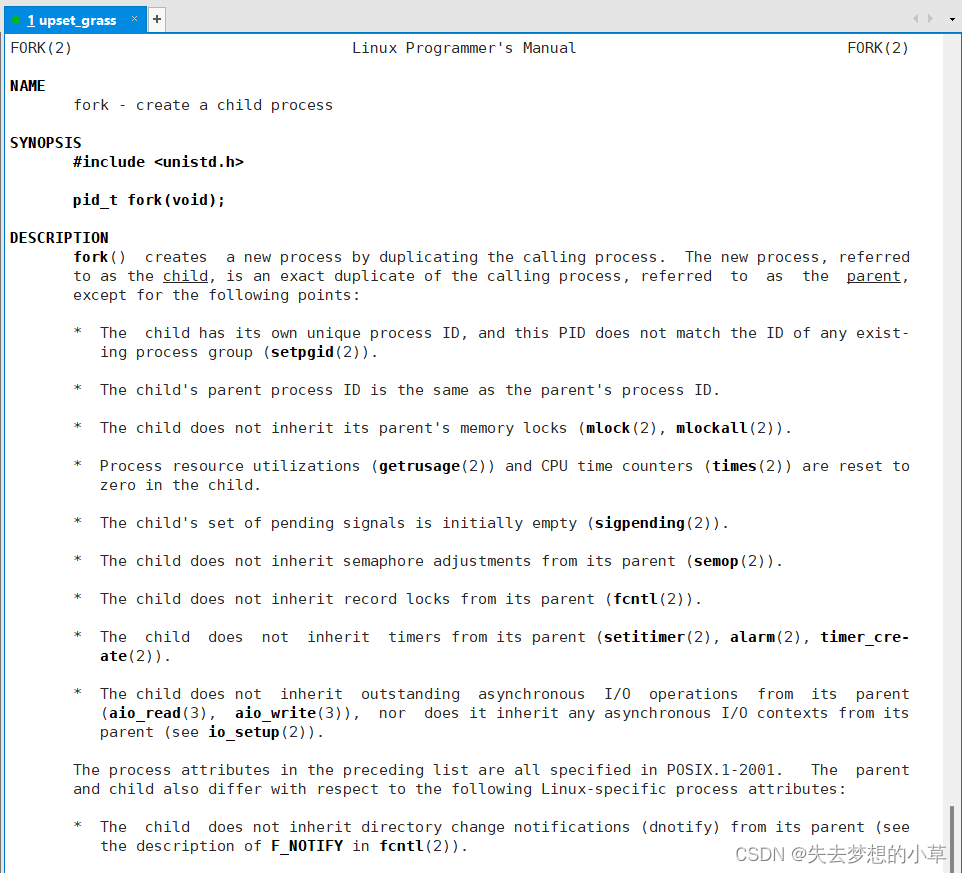
我们去阅读man fork中对fork的description和return value:fork会创建一个子进程,并且fork对于父进程会返回子进程的PID,对于子进程会返回0,都是pid_t类型的(也就是typedef int pid_t)

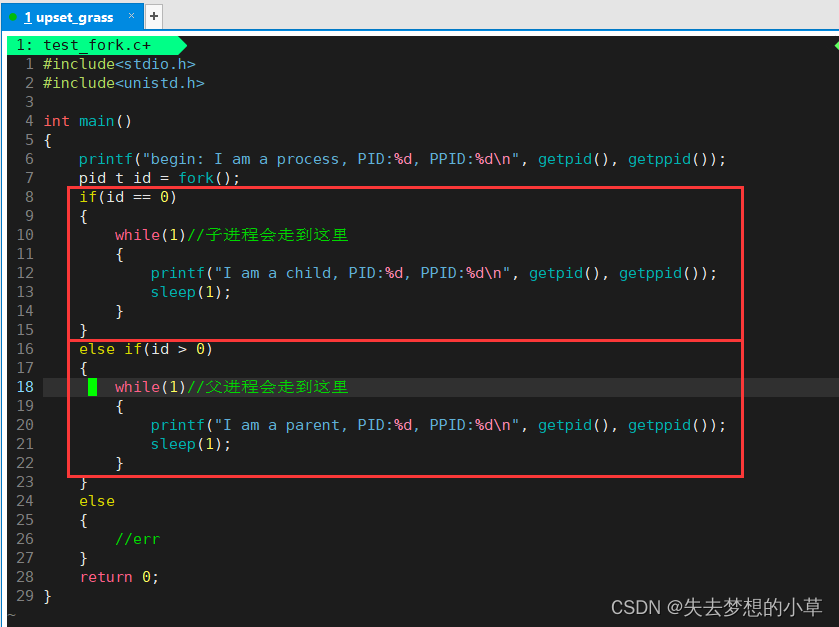
所以我们修改修改程序,来探究探究fork()来的程序运行机制
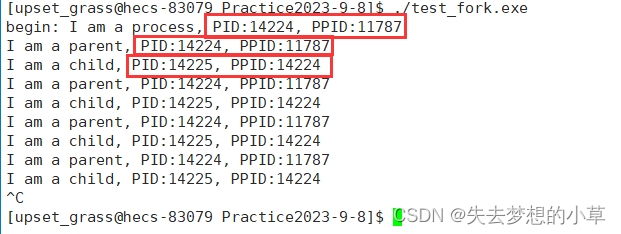
三个PID的关系如下图
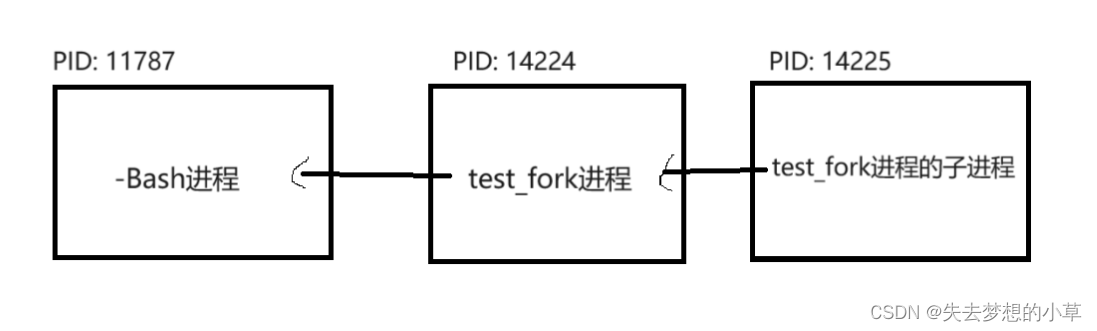
我们再查一下fork的英文意思:分叉,很形象的理解这个程序,就是再fork之后,程序分成了两个程序,也就是从单一的执行流,变成了两个执行流,也就是在fork返回的时候返回了两次,放到了两个id变量中,一个存储父进程的PID,一个存储子进程的PID
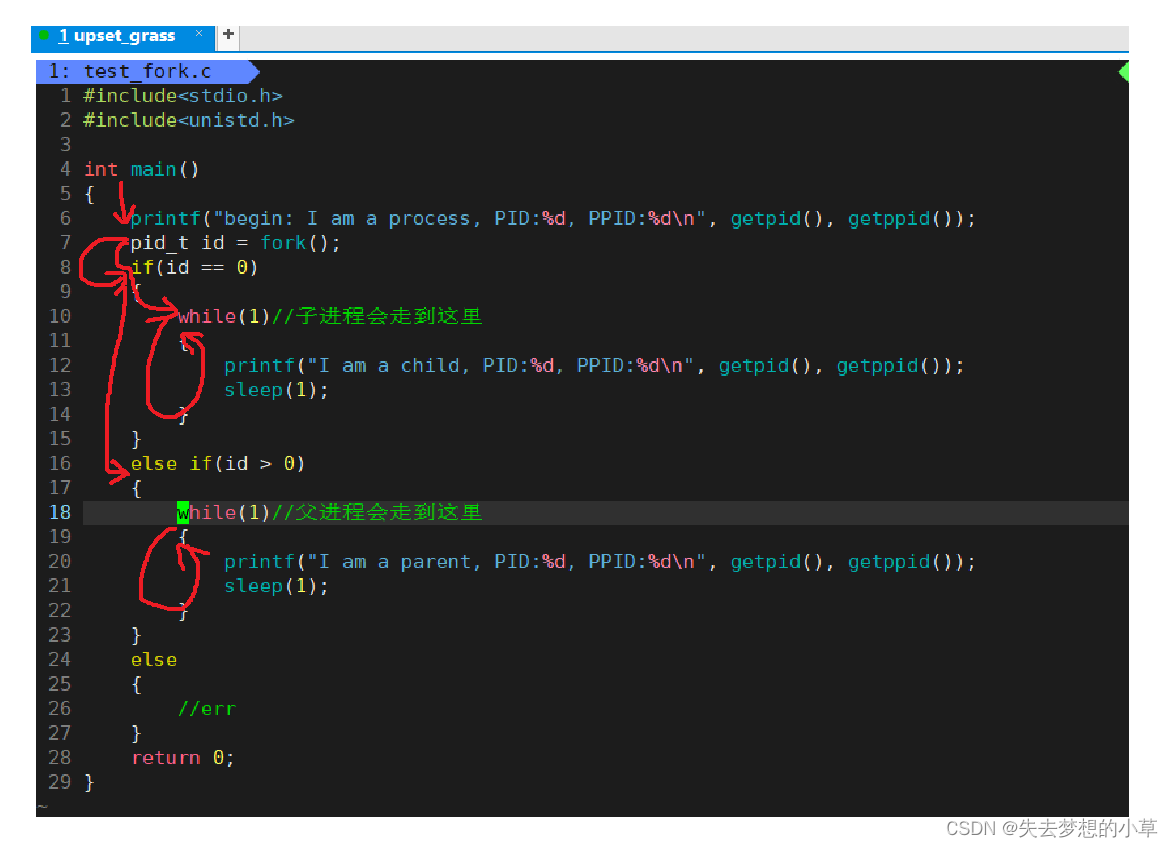
系列发问
1、为什么fork要给子进程返回0,给父进程返回子进程PID?
一般而言,fork之后的代码父子共享,因此可以让fork之后可以根据不同的if判断,让父子进程执行不同的代码片段,返回不同的返回值,因此需要返回值不同(就算相同也需要有其他方法区分父子进程)
父进程知道子进程的PID,以便进行进一步的处理。父进程可以根据返回的PID来跟踪、管理、等待子进程,所以父进程需要获取子进程的PID,而子进程拿到0,是为了确认自己是子进程,可以根据需要执行特定的任务
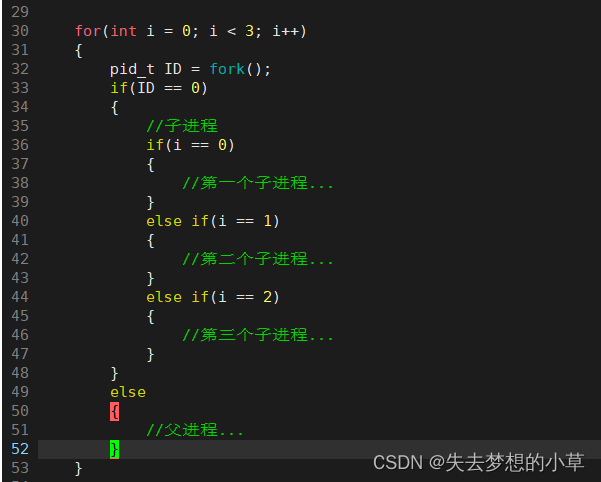
1)、追问:如果有多个子进程,此时的id变量存储的是谁的PID?
存储的是最新的fork()出来的子进程,我们可以用循环来让多个子进程完成不同的任务
2、fork函数中干了什么?
fork中创建了子进程,也就是创建了新的PCB结构体,也就是新的task_struct(大部分是以父进程为模板创建的,会修改部分内容,例如自己有一个新的pid,ppid修改成子进程的父进程,这里的父进程不是bash,是我们写的有fork函数的那个进程,
3、一个函数是如何做到返回两次,如何理解?
一个函数执行到return时,这个函数的工作是否执行完成?
此时已经把核心工作做完了,比如这里fork()
pid_t fork()
{
//创建子进程PCB
//填充PCB的内容
//让子进程和父进程指向相同的代码
//此时,父子进程都是独立的task_struct,可以被CPU同时调度运行
return PID;
}
我们思考,在执行return PID的时候,子进程已经创建完成,父子进程已经独立,父进程走父进程的,子进程走子进程的,互不干扰,所以父进程返回父进程的PID,子进程返回子进程的PID
4、一个变量怎么能存两个不同的值?如何理解?
我们需要知道,任何进程在运行时是可以具有独立性的,比如我的QQ崩了,不能影响我的网易云音乐,对于父子进程,也是两个进程,如果父进程没有用到子进程的某些资源,子进程也没有用到父进程的某些资源,这两个进程也是独立的(如果用到了对方的资源,形成了依赖关系,那么对方崩了,势必会影响到自身,非父子进程也可能会发生这种情况),父子进程为了防止数据被另一个进程修改,子进程在形成时,会把父进程的程序(代码 + 数据)中的数据拷贝一份,而代码是共享用同一份,此时一个进程运行时,就不会影响另一个进程了
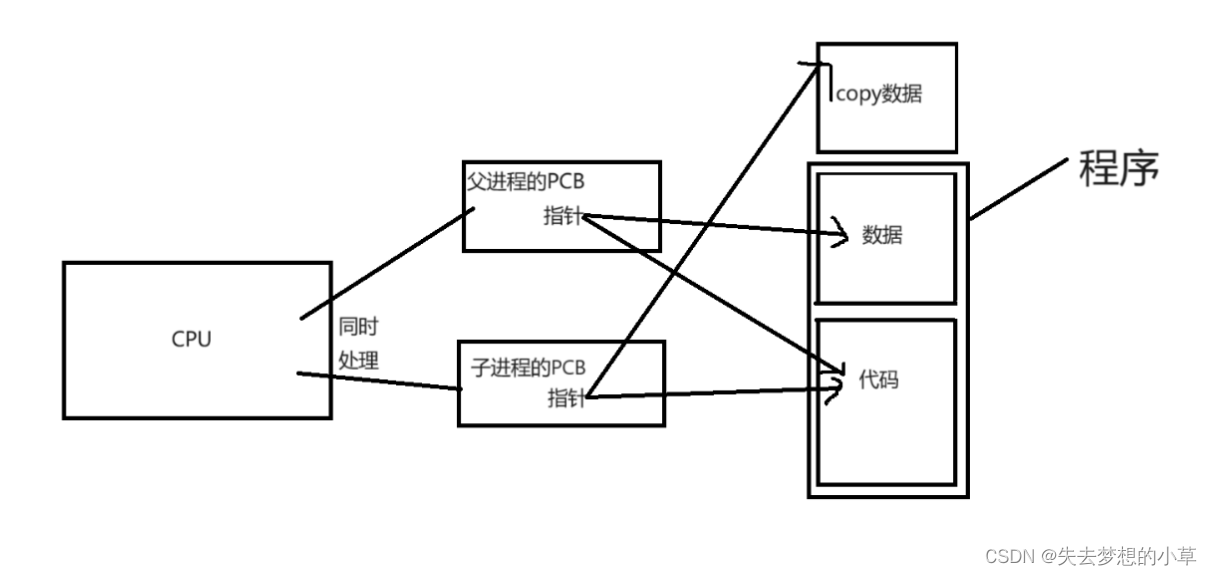
但是上面这种粗暴的把所有数据拷贝一份的方式对于资源的浪费较多,而大多数时候只会访问修改一部分数据,所以操作系统这部分的处理方式是:
当子进程想要对父进程某个数据进行修改时,拷贝一份该变量,然后对拷贝后的变量进行修改,这种技术叫做父子进程数据层面的写时拷贝
所以上面的程序对id变量,父进程return就直接写入,而子进程return就会发生写时拷贝,此时父子进程看到id值的内容就会不一样
5、算是拷贝了一份该变量,但变量名还是相同的,父子进程怎么就能够看到不同的数据呢?
目前无法解释,地址空间的时候讲解
6、我们为什么要创建子进程呢?
为了让父子进程执行不同的事情,执行不同的代码块,让父子进程能够协同
7、如果父子进程被创建好,fork(),往后,谁先运行?
一般而言,谁先运行,由调度器决定,所以谁先执行是不确定的,而且在用户层面是无法干预的
我们的所有进程会以链表的形式组织起来,对进程的管理变成了对链表的增删查改,对于进程运行,我们一般会有大量的进程,运行哪一个,是由调度器决定的,不同的操作系统的调度器是一套查找算法,是一种函数,是用来查找到合适的进程来给到CPU执行,调度器需要平均、公平。
所以我们再次理解为什么我们执行的指令和程序,其父进程都是-bash进程
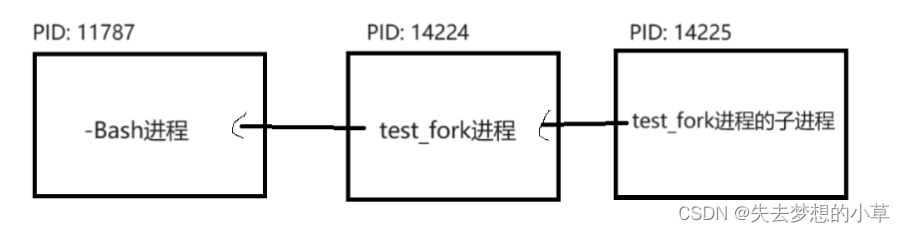
bash进程为了防止其他进程影响到自己,是通过创建子进程完成的,bash如何创建子进程?推断:调用fork(); fork()让bash自己的代码继续执行命令行解释,而让子进程去执行解释新的命令。所有的命令、可执行程序都是bash的子进程,也就是说所有的命令程序,都是通过fork()去执行自己的代码
总述进程状态
一个进程一定会有几种状态,用来表征和标识
这是我在网上找到的状态图
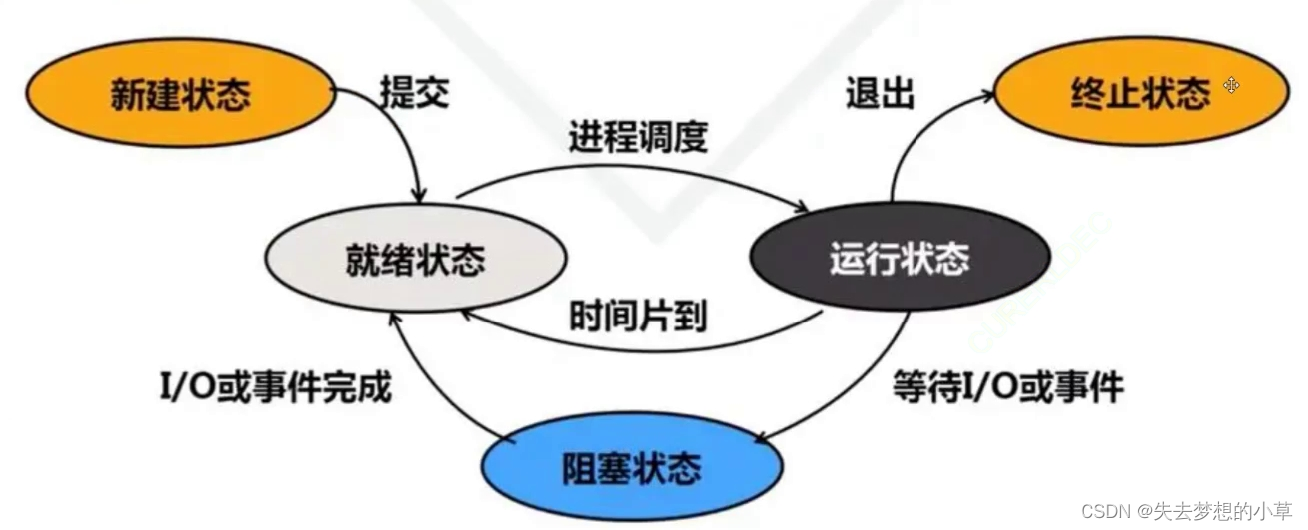
最主要的就有三种进程状态:运行、阻塞、挂起(等待/就绪)
我们一个个来介绍
运行状态
众多进程会竞争CPU,每个CPU都会维护自己的struct runqueue{} —— 运行队列,队列中有struct task_struct* head、struct task_struct* tail,去指向运行队列的队头和队尾
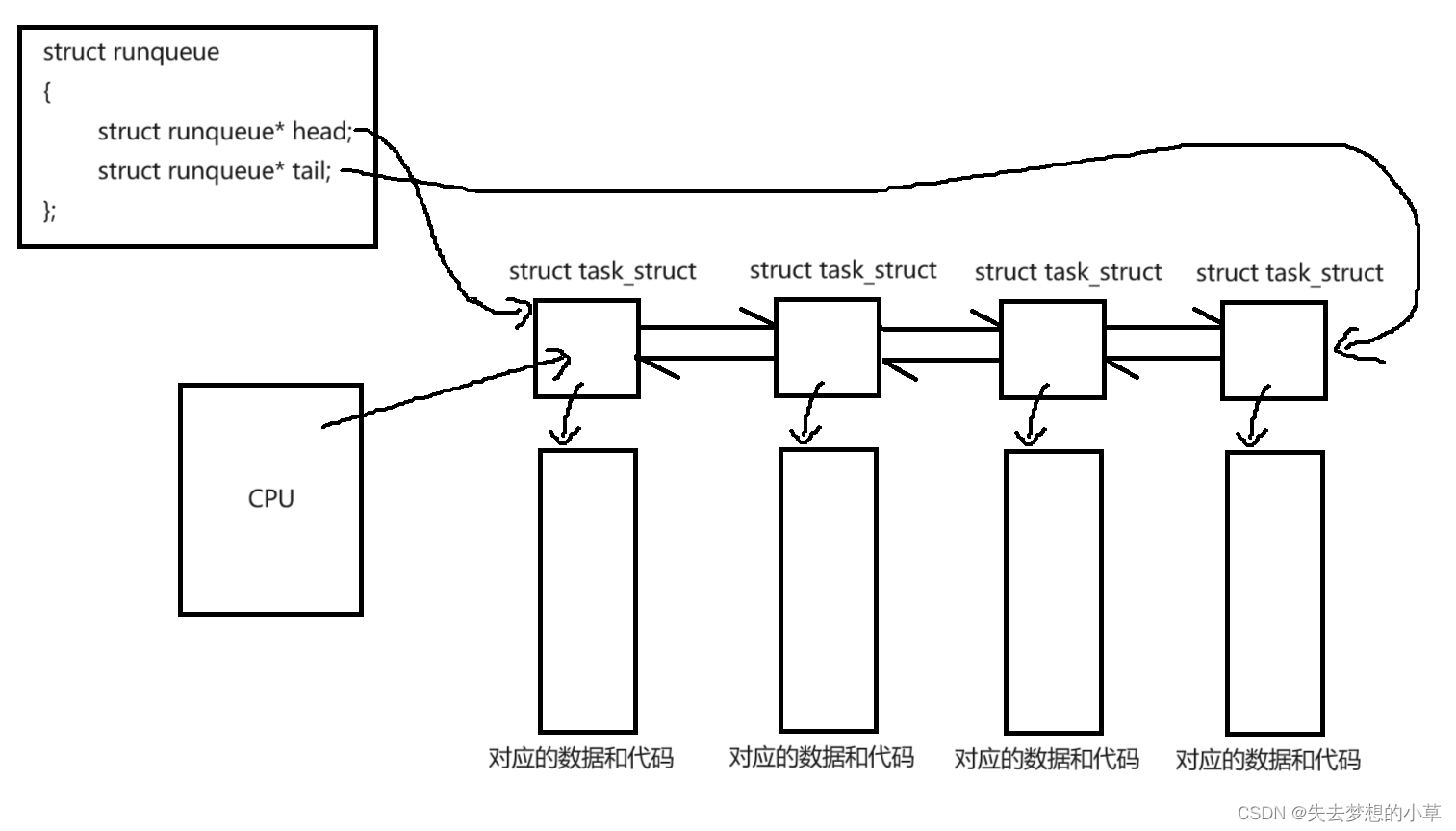
这就是进程在CPU上排队,该队列叫做运行队列,在运行队列上的进程所处的状态就是运行状态,即运行态
在一个程序加载到CPU上时,是否需要等待该进程执行完毕,才把自己从CPU上放下来?
如果是:那么效果就是,一个程序在运行时,其他程序完全卡住,等待该进程执行结束,所以显然根据实际:不是这样的
我们为了防止这种情况,(不同操作系统的解决方案不统一):每一个进程都有一个时间片(int time_space),时间片也就是一个时间结点,进程在CPU上运行会记录运行时间,运行时间超过这个时间片,就会把这个进程从CPU上拿下来,如果还需要继续运行,就放在运行队列的队尾继续排队等待
小案例:现在有5个进程,每个进程的时间片设置为10ms,那么在一秒内,每个进程会在CPU上运行20次(1000ms = 1s 1000/5/10),所以我们看到的现象就是,这五个进程都在CPU上同时运行(一段时间内多个进程的代码同时被执行),这种方式在计算机中称为并发执行
我们也称大量把进程从CPU上拿下来,放上去的动作称为进程切换
CPU太快了,进程切换的时间我们人无法感受到
阻塞状态/等待状态
考虑一个队硬件做管理的例子,来理解这个等待状态
我们用一个结构体描述硬件struct dev{int type; int status; struct task_struct* head; struct dev* next; … };结构体中有设备的类型、设备的状态、设备的进程指针、设备next指针、… ,我们有大量的硬件,硬件之间通过指针链接起来,对设备的管理,也就是对这个链表做管理,设备的进程指针大多数情况是作为等待队列,也就是说每一个设备都有一个等待队列,一台计算机可能有成百上千个等待队列(运行队列的数量与CPU数量相同),在进程需要该设备的一些资源时,就会把进程链接到设备的等待队列上
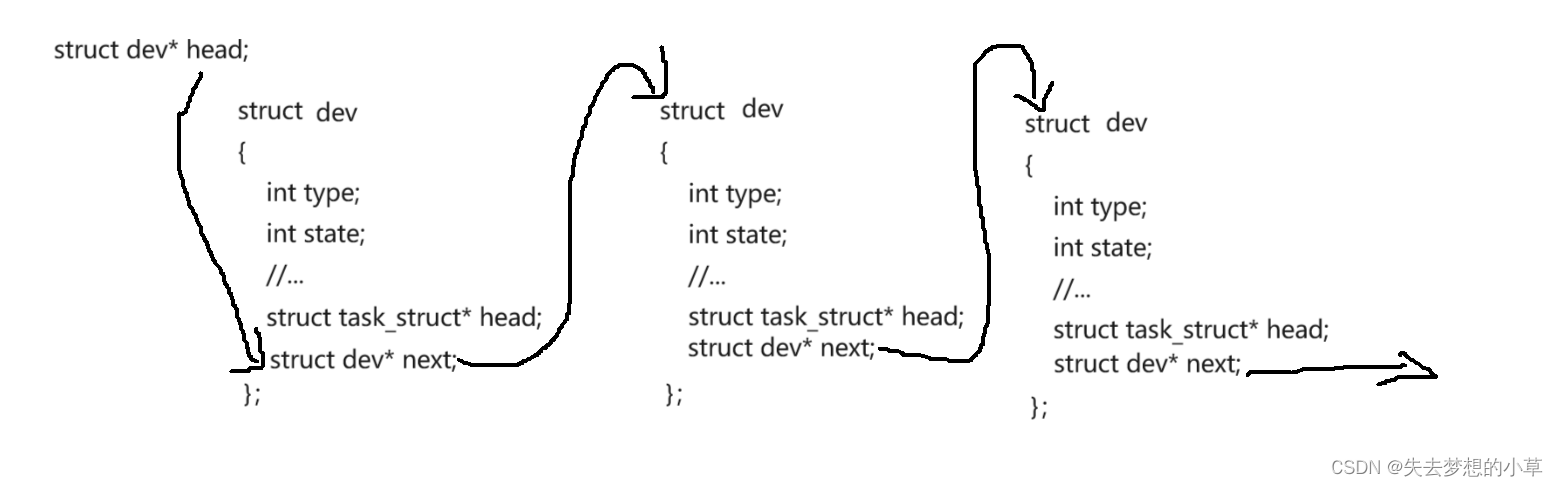 现在我们想要从键盘中读取数据,那必然有一个进程,有PCB,也有对应的程序代码和数据,这个程序想要从键盘中读取数据,此时进程就会链接到键盘设备的进程指针、也就是等待队列中,如果有多个进程,都需要键盘进行输入,那么就会有多条进程,都会链接到键盘的等待队列中,我们把这种在等待硬件设备、软件、系统事件的进程的状态称为阻塞状态/等待状态
现在我们想要从键盘中读取数据,那必然有一个进程,有PCB,也有对应的程序代码和数据,这个程序想要从键盘中读取数据,此时进程就会链接到键盘设备的进程指针、也就是等待队列中,如果有多个进程,都需要键盘进行输入,那么就会有多条进程,都会链接到键盘的等待队列中,我们把这种在等待硬件设备、软件、系统事件的进程的状态称为阻塞状态/等待状态
如果键盘有了输入,驱动设备读取键盘,发现其中有数据,此时就会把等待队列中的进程(队头的那一个)“唤醒”,也就是阻塞状态改成运行状态,放到运行队列中
需要注意的是:等待队列不只是设备会存在,甚至一个进程A可以等待另一个进程B,此时也会把A链入到B的等待队列中(进程和硬件设备之间、进程和进程之间都存在等待队列)
挂起状态
挂起状态是操作系统内部的内存资源严重不足时,保证正常的情况下,为了省内存资源的一种状态,比如大量的进程都处于阻塞状态中,此时这些进程是处于内存中,空闲没有被使用的状态,此时操作系统就会把PCB保留,把代码数据,交换到外设中(磁盘…)即换出,当我们资源就绪(键盘有输入,麦克风有输入,屏幕有输出…)时,会把外设中的代码数据重新换入到内存中进行
这种PCB在内存,代码和数据在外设中的状态称为挂起状态
这些代码数据是放在磁盘交换分区中(在windows中和C盘D盘E盘是并列的关系)
问题
1、三种状态存储在哪里?内存中,内存的任意位置
2、我们如果主动去运行一个进程,但是这个进程还在排队,那么可以跳过排队吗?一般而言,都是还是会排队运行的,但比如Linux中会涉及优先级,高优先级能够插队运行,但这种情况比较少
3、运行队列是CPU只运行头进程,运行完之后在将其放到队尾继续排队吗?这与操作系统的调度算法有关,我们上述的调度算法是基于时间片的轮转算法,这种算法下是运行完放到队尾
Linux中具体相关进程的维护
R(running)
S(sleeping)
D(disk sleep)
T(stopped)
t(tracing stop)
X(dead)
Z(zombie)
运行状态
运行状态用R表示,我们简单的先写一个程序
我们可以通过ps ajx中的STAT项来查看状态

这里检测到,STAT基本都是S+,而我们去掉printf();再次运行,发现就变成了R+,也就是运行状态

这是因为前者大部分时间都在等待显示器设备就绪(可能高达99.99%——CPU太快了-纳秒级别,外设太慢了-毫秒级别,也就是10^6的差异,所以几乎不会在检测的那一瞬间是R状态),所以大部分都是S状态,对应到操作系统中就是等待状态/阻塞状态
而后者去掉printf(),就是单纯的运行代码,没有I/O或其他等待设备就绪的情况,也就不会出现S+状态,而是长期保持R+状态
上面的这些状态后面有一个’+',这个是表示该任务是处于前台运行的状态,我们可以通过在运行该可执行程序时带上&,让程序后台运行,后台运行就没有这个+号

我们如果再次./code.exe &,那么就会出现两个进程
后台程序,我们只能通过kill -9 [PID]来删除进程
除了ps ajx可以查看STAT,还有top这个类似于任务管理器的命令可以查看
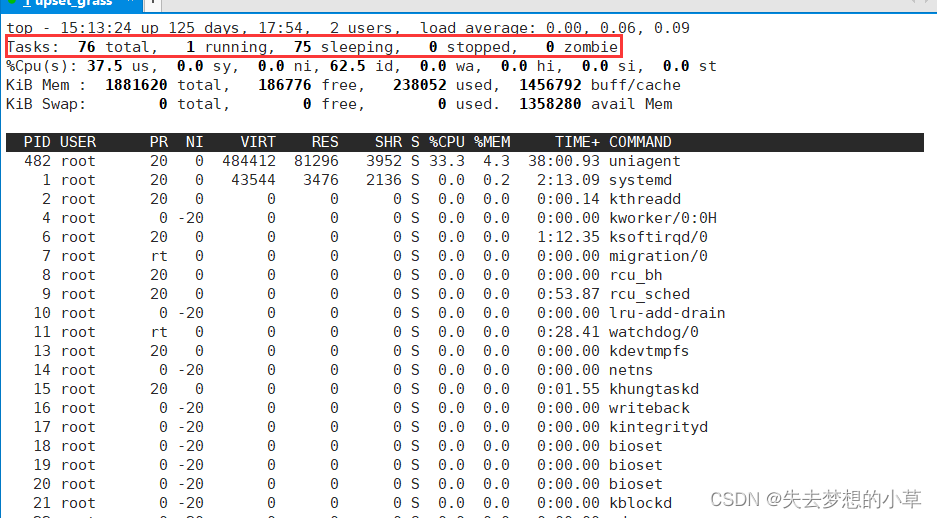
浅度睡眠状态
是用S(sleep)表示,比较标准的等待状态比如sleep(1)等待一秒、scanf()等待键盘输入,以及前面遇到的printf()等待屏幕响应,这个睡眠状态也就是等待状态/阻塞状态
在一个系统中最多的就是睡眠状态,也就是等待某些事件的触发,某些资源的就绪
写了一个简单的程序

input:后面一直没有键盘输入的话,程序就一直处于S状态,这个一直处于,就是100%处于了,不是while(1){printf(“…”);}这种跑一行代码,然后去等待屏幕设备,然后再跑一行代码,再等待屏幕设备这种有极小的可能性能看到R(这运气留着去买彩票更佳),同理,像sleep(1),这等待的1秒中,也是100%的S状态
再分析为什么printf()时大部分情况处于S状态:
我们使用xshell,登陆了远程的机器,我们printf让屏幕显示,实质上是把数据放进了网络里让远程的机器执行printf,然后把执行结果通过网络又传输到本地,在本地的屏幕上显示,那么网络在传输的时候必然会进行等待
深度睡眠状态
深度睡眠是用D表示(disk sleep)(对于应用级别的程序员不需要深入了解D状态)(是Linux特有的,不是操作系统理论中的状态)
,也是一种阻塞状态,浅度睡眠状态是可以直接被唤醒或者kill掉的,也就是能够响应,深度睡眠主要是用于内存中有大量数据需要写入磁盘等外设时的一种状态
进程给磁盘中写入1GB数据,需要有发起,有反馈,进程在要有反馈,那么一定会需要等待这1G的数据的上传,上传成功/上传失败,磁盘都会反馈信息给进程,进程再反馈 给用户
而如果进程太多,操作系统检测到CPU资源严重不足,操作系统会kill 进程,kill那些操作系统认为不太重要的进程(比如windows中也有类似的情况,进程闪退,排除掉可执行程序本身的BUG问题之后,也可能是操作系统kill了可执行程序)
会有如下情况:进程让磁盘写1GB数据,磁盘去写了,但此时内存严重不足,操作系统直接把该进程kill了,磁盘在写入成功、写入失败时,不知道向谁反馈,如果写入失败,此时磁盘就直接把数据丢掉了(各种硬件的做法不相同,有再试试的,有直接丢掉的)
所以为了避免这种情况,就出现了D状态,设为D状态的进程,在等待磁盘写入数据 磁盘不能立刻反馈给进程时,不能被任何其他进程、操作系统kill掉,当磁盘写完了数据、给到写入成功/失败的反馈,该进程就由D状态改为R状态然后执行后序操作,如果想要强制kill该进程,只能断电(重启操作系统都没用)—— 用官方的话,不响应任何请求(除了写入磁盘的数据反馈)
在实际中,如果被用户以ps axj / top观测到D状态时,操作系统就已经快挂了(操作系统一般会有D状态,但数据量不会太大,一般不会被用户观测到,用户都能观察到D状态,只能说明此时磁盘压力太大了)一般高IO的状态,能够正常显示出D状态
暂停状态
暂停状态在Linux有T和t,不过现在T和t的区别已经很小了,可以把这两个状态当成一个状态
之前我们用过kill -9,给机器发送九号信号,我们还有其他的信号,可以用kill -l来查看
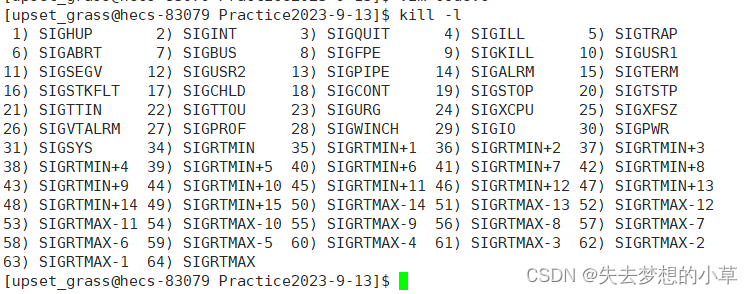
其中19号信号 - SIGSTOP就是暂停进程,18号信号 - SIGCNT就是继续进程
我们这里有一个while(1){printf(“hello world\n”);}的程序,程序从S+状态,变成了T+状态
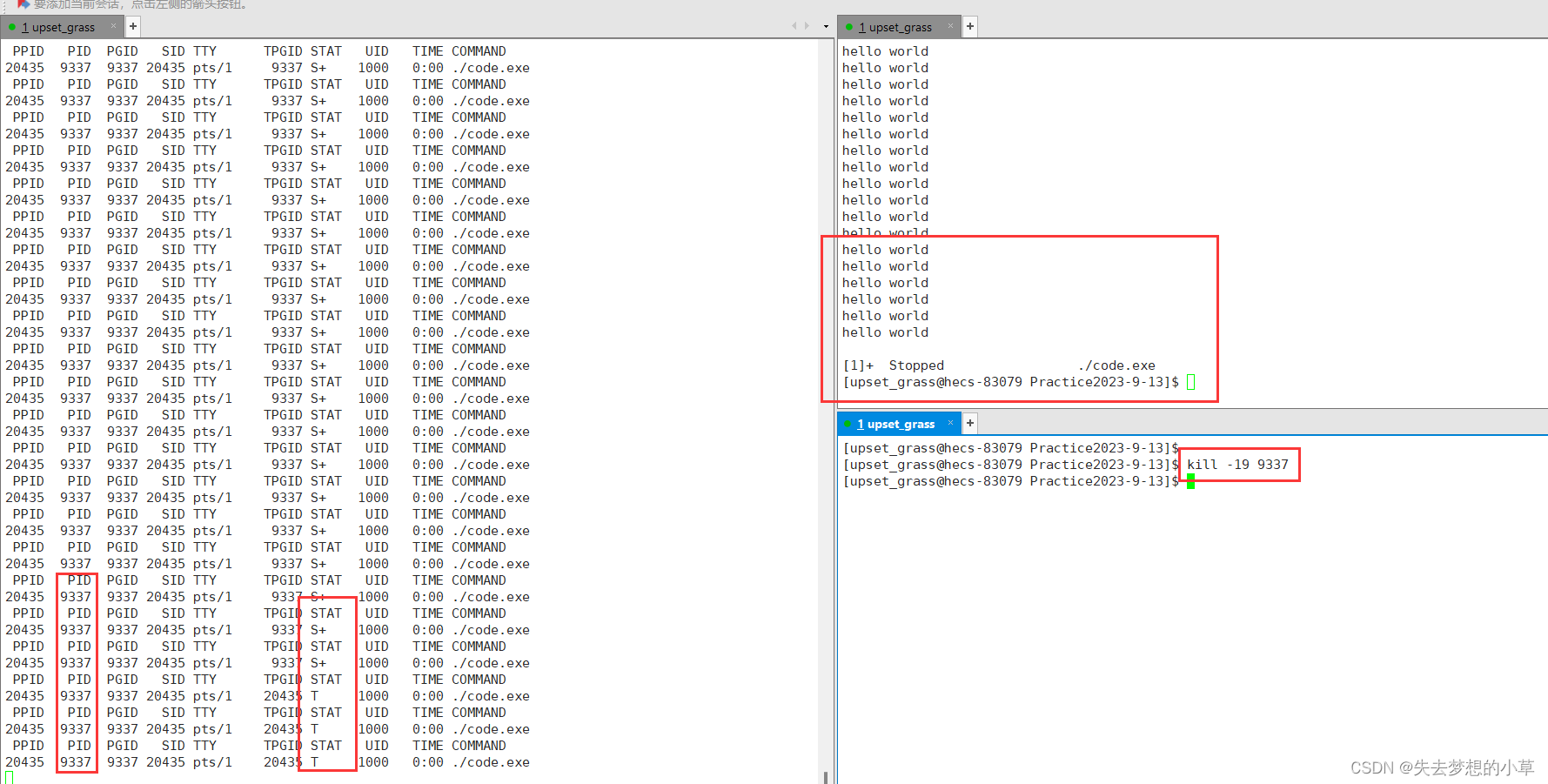
然后我们用kill -18,让程序再次运行起来了
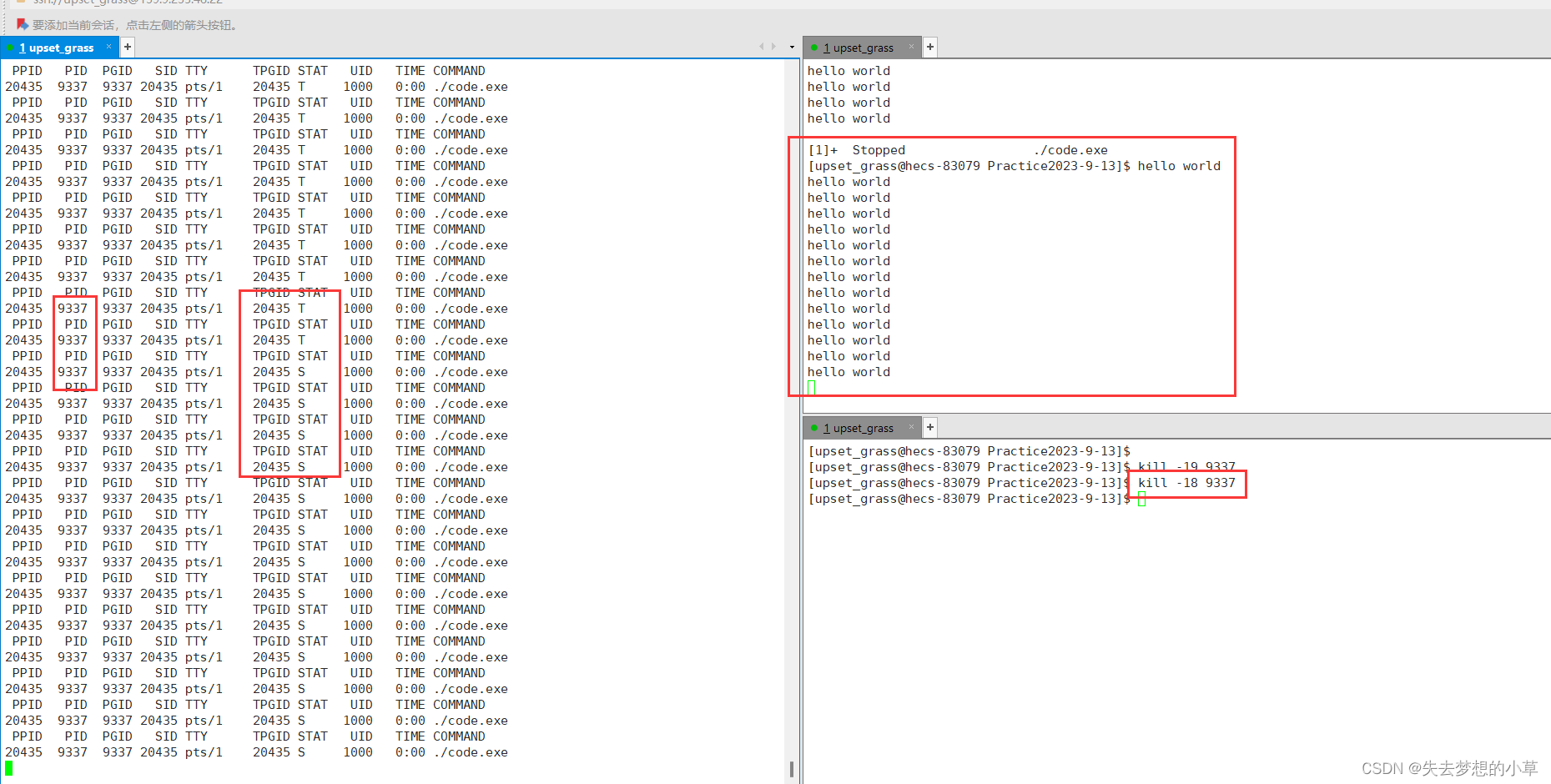
暂停状态和睡眠状态(阻塞状态)的比较:
暂停状态和睡眠状态都是在等待一些事件的发生(比如接收某些信号、硬件资源的就绪等)
暂停状态下是直接把程序停掉了,只会去等待某些信号的出现,是被其他进程控制,或者是等待某种资源,比如kill -18,而睡眠状态就是等待各种资源或其他的事件
(暂停状态和睡眠状态的差异不大)
所以从行为上,等待状态也可以理解为一种阻塞状态
使用场景:
比如:gdb调试工具,我们在用gdb调试程序时,gdb进程在运行着,gdb调试的那个程序受到gdb调试工具的控制,如果在gdb调试时,用r指令,也就是F5让跑起来了,此时被调试的那个程序就是在运行状态,而如果我们打了一个断点,或者用s n指令,分别执行到断点、执行了一行、执行了一个函数,这些了这些代码之后,gdb调试工具就会对被调试的代码程序发送kill -19让其暂停下来
终止状态
终止状态是用X表示(dead),进程执行完成,会把进程放到垃圾回收队列中,操作系统会释放其资源,这是进程的最后状态,基本监测不到
僵尸状态
僵尸状态是用Z(zombine)表示,也就是一个进程在结束时,并不是立刻把所有资源立刻释放,而是让其处于Z状态一段时间,用于收集信息,让所有与这个进程相关的进程知晓这件事,比如父进程关心(后面进程控制章节会讲如何控制),所以在父进程还未关心之前,进程结束之后,这段时间保持的状态,就是Z状态
这里我写了一段程序,让子进程执行6次printf就exit结束进程,让父进程一直处于while(1)的状态
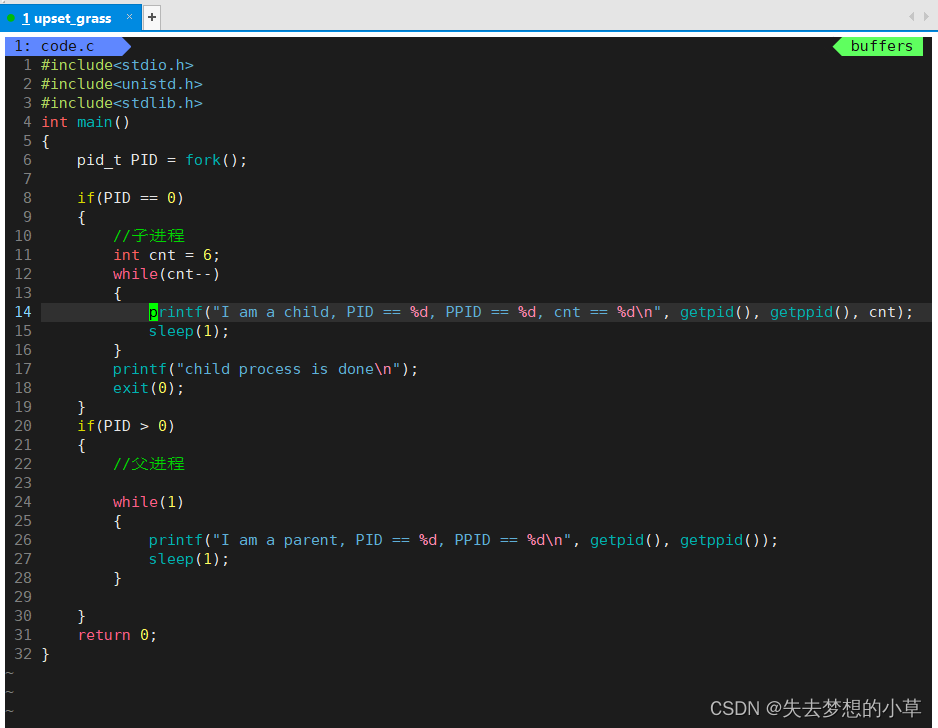
此时运行程序
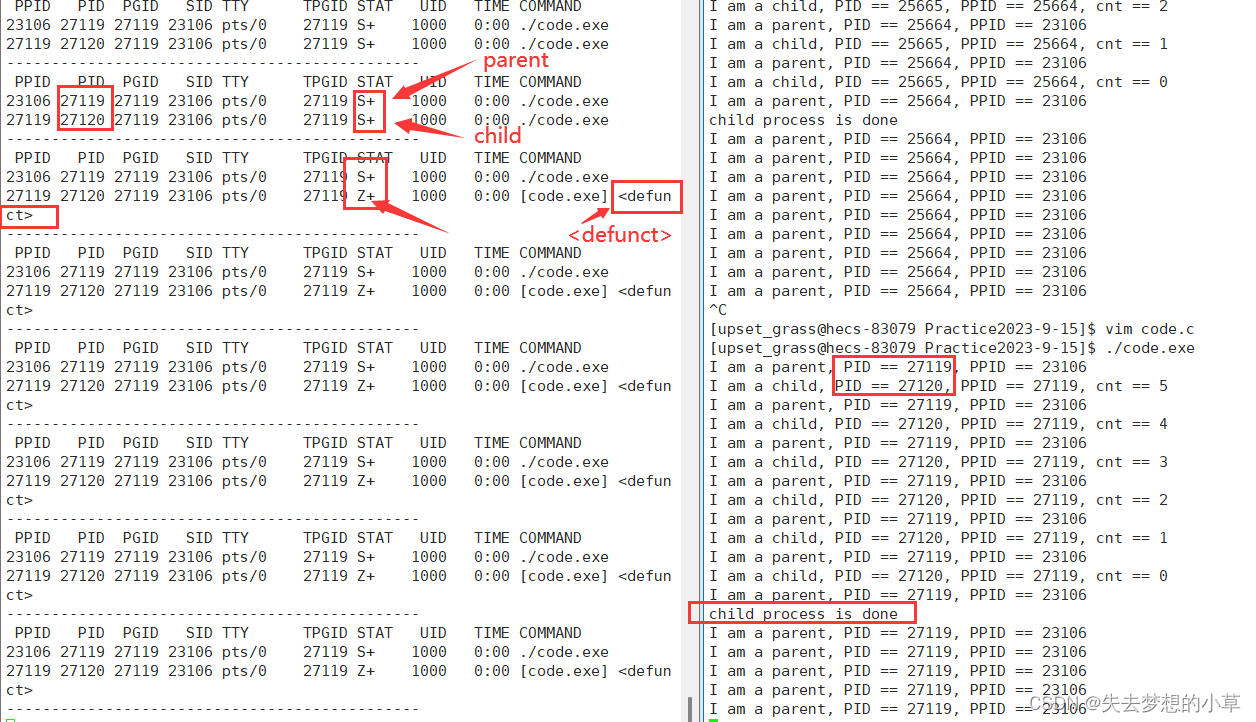
父进程目前没有针对子进程做任何事情,此时运行此进程时,子进程五秒就exit结束了,但是父进程还在while(1),所以此时,就能够观察到,子进程处于僵尸状态/Z状态
这里监视窗口中看到< defunct >字样,意思是该程序是无用的、销毁的、失效的
如果父进程对子进程进行了回收,就会变成X状态,然后操作系统一段时间回收一次(一段时间 - 很短),如果父进程一直不回收子进程,子进程资源会一直被占用,也就是一个进程退出了,但是由于父辈未主动回收子进程,该进程的资源还在占用,这也就是一种内存泄漏 ,这个问题具体后面会讲
危害
维护僵尸状态是需要数据维护的,也就是需要进程的PCB结构体,如果僵尸状态一直不退出,PCB就需要一直维护
如果一个父进程有大量子进程,但是子进程结束,不回收这些子进程,就会浪费大量的内存资源
孤儿进程
我们对上面的程序进行修改,让父进程printf 5次,让子进程一直处于while(1)
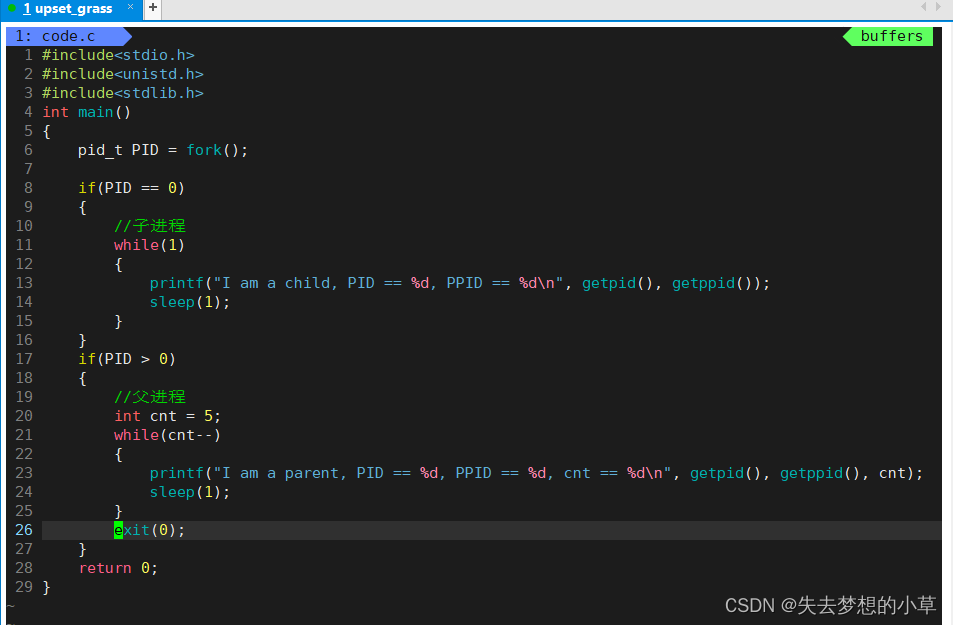
运行
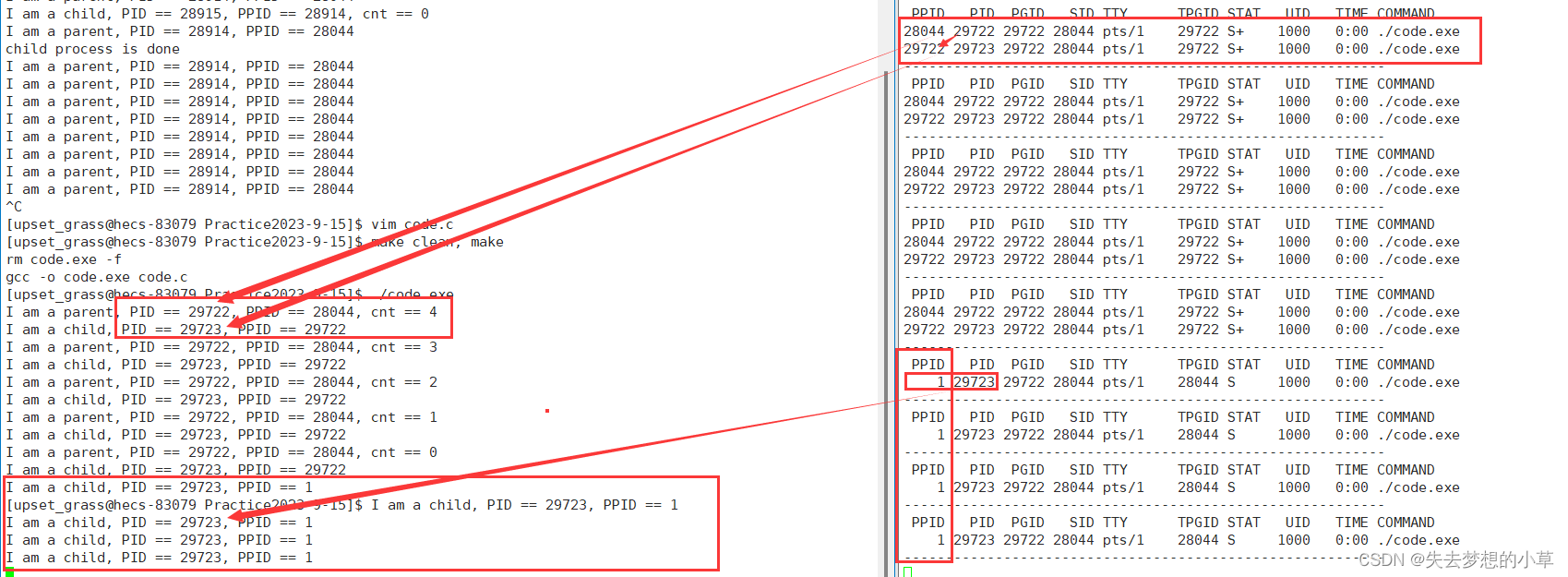
发现父进程退出后,子进程的PPID变成了1,我们top查看PID,1号进程是root,其对应的进程COMMAND是systemd,即是操作系统
父子进程,父进程先退出,子进程的父进程会被改成1号进程(操作系统)
一个进程的父进程是1号进程也就是孤儿进程(没爹的进程)
该进程被系统1号进程所领养,为什么要被领养呢?因为孤儿进程未来也需要退出,处于僵尸状态也要被释放,所以被系统领养,在其跑完之后进行回收
PCB如何存储于多种数据组织形式
之前我们说过进程之间是通过双链表进行链接起来的,但从另一个角度,进程之间是父子关系,也就是一颗多叉树,所以操作系统也让进程以多叉树的模式链接起来,在PCB结构体中,既有left和right指向左右孩子的指针,也有prev和next指向链表前后的指针,具体如何实现,我们看下图
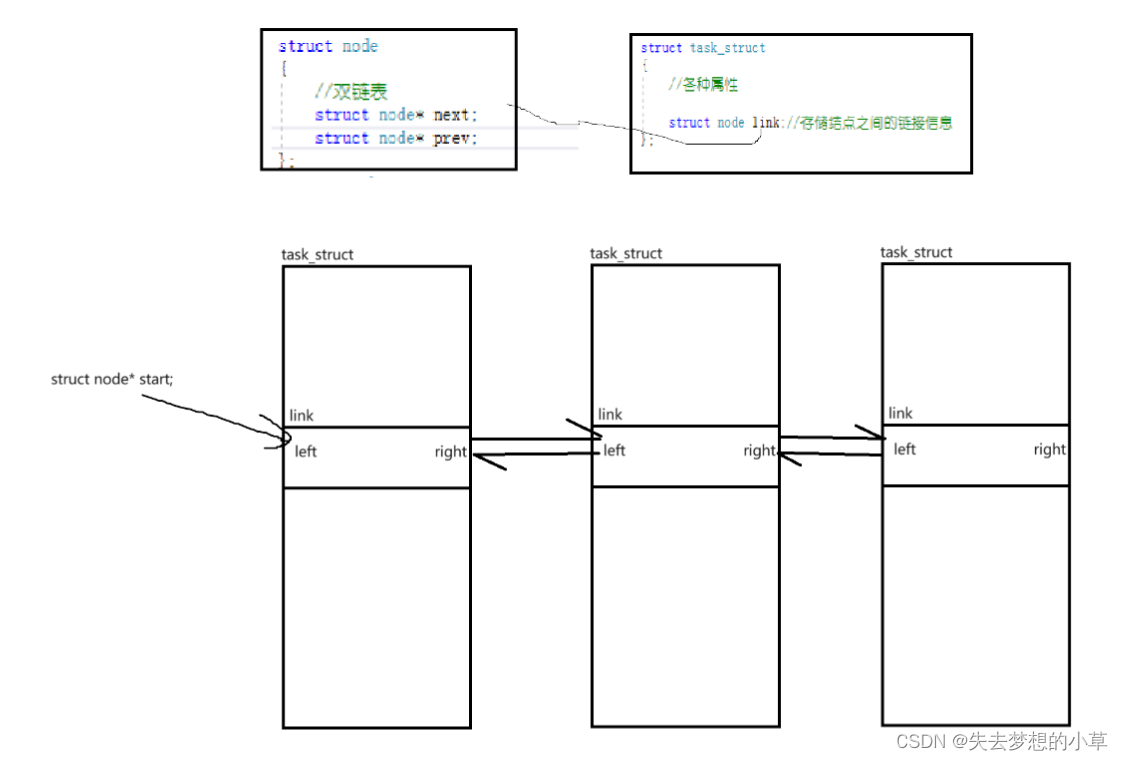
之前我们是struct node里面存数据、指针,数据可能是自定义类型,而这里是反过来,在一个的task_struct自定义类型中存储一个struct node link结构体,node结构体用于管理节点间的链接,对于第一个task_struct,有一个struct node*类型的start指向这个node位置
这里需要注意到这个struct node link,并没有放在task的首地址,我们需要访问结点中的其他属性,那么就需要找到结构体首地址:
(task_struct*)(start - &(task_strcut*)0->link)->other
我们逐步分析:
(task_struct*)0 —— 以task_struct类型的方式去看待0,也就是0x00000000地址后面是一个task_struct类型
(task_struct*)0->link —— 拿到link结构体
&(task_struct*)0->link —— link结构体取其地址,由于首地址是0x00000000,所以link结构体的的地址,就是task_struct结构体中link结构体的偏移量
上面我们通过0地址强转拿到了偏移量,下面我们利用偏移量去得到task_struct首地址,进而访问其他属性
(start - &(task_struct*)0->link)—— 有了偏移量,start指针(真实存储的地址)是指向的struct node link位置,减去偏移量,就找到了这个link结构体所在的task_struct的起始地址(这里更严谨的角度应该给start和后面这一堆强转为char*,这样减1才不是减的整个结构体的空间大小)
(task_struct*)(start - &(task_struct*)0->link)—— 以task_struct*的视角看待这个地址
(task_struct*)(start - &(task_struct*)0->link)->other 访问该结点中的其他成员
这种设计,可以面对task_struct1 task_struct2 … 不同的结构体构成的双向链表,我们只需要知道构成这些双向链表的task_struct的类型即可 —— 多个不同的类型的对象,依旧可以通过链表链接起来
同理我们还可以定义struct node1{left; right;},然后在task_struct中有一个struct node1 link1; struct node2 link2;此时,这个结构体就既能够放到双向链表中,也能放到二叉树中

进程优先级
进程的优先级就是CPU资源分配的先后顺序
优先级高的进程有优先执行的权力,合理的配置进程优先级堆多任务环境的Linux很有用,可以改善系统性能
可以把进程运行到指定的CPU上,可以把不重要的进程安排到某个CPU上,改善系统整体性能
我们先来了解了解PCB结构体中的一些属性
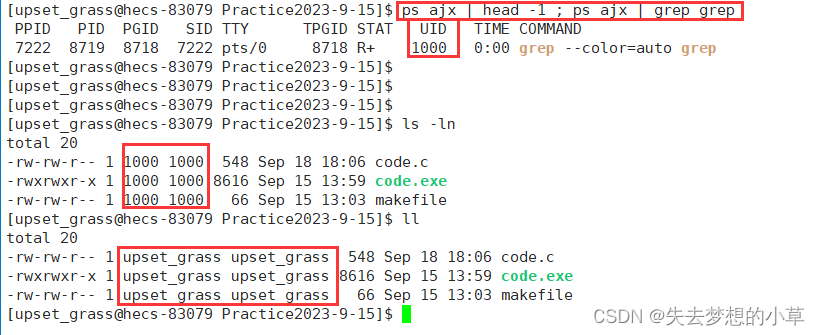
UID
Linux中其实只认数字,甚至不认字符串,所以对于每一个用户账号来说,都有其自己的UID,我们可以通过ps ajx 或者 ls -ln在原来文件拥有者、所属组的显示位置查看到用户的UID
PRI和NI
priority - 优先级 - 越小,进程的优先级越高,越先执行
nice值 - 进程优先级的修正数据 - 说明优先级可更改,可以启动前更改,可以运行时更改,是通过更改NI来改变优先级的,NI为正->降低优先级,NI为负->提高优先级,但需要注意的是Linux中,不想用户过多的参与优先级的调整,我们只能在一个范围里调整优先级,超过优先级,会以极值作为调整nice值∈[-20, 19],加上PRI,则为PRI(新) ∈[60, 99] - 40个级别 ( 大部分情况都不用改 )
PRI(新) = PRI(旧) + NI

nice/renice指令可以调整优先级,网上自行寻找
除了nice和renice可以修改优先级,top指令中也可以修改优先级(root权限)
先用top指令进入下面画面:
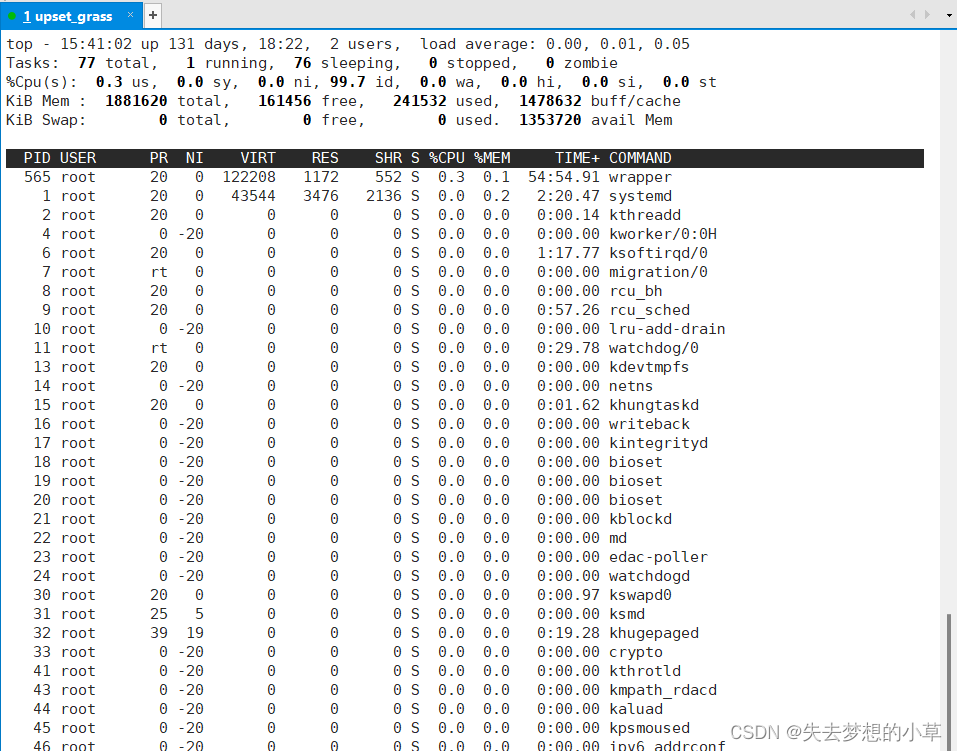
然后按r:
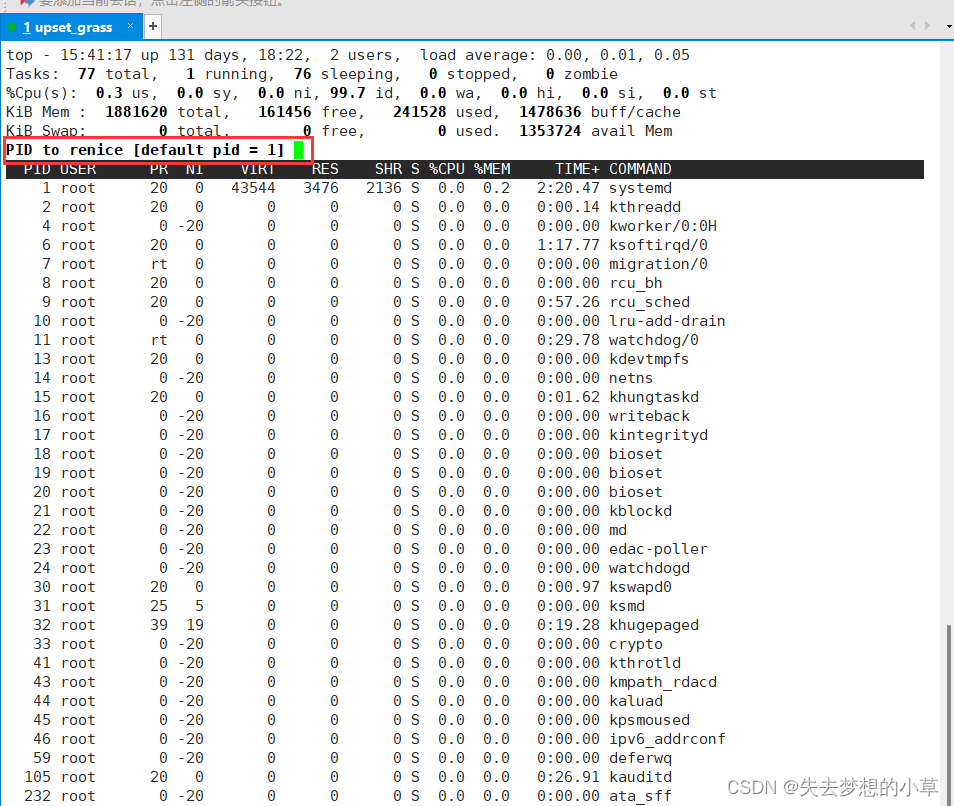
输入需要调整优先级的进程的pid,回车
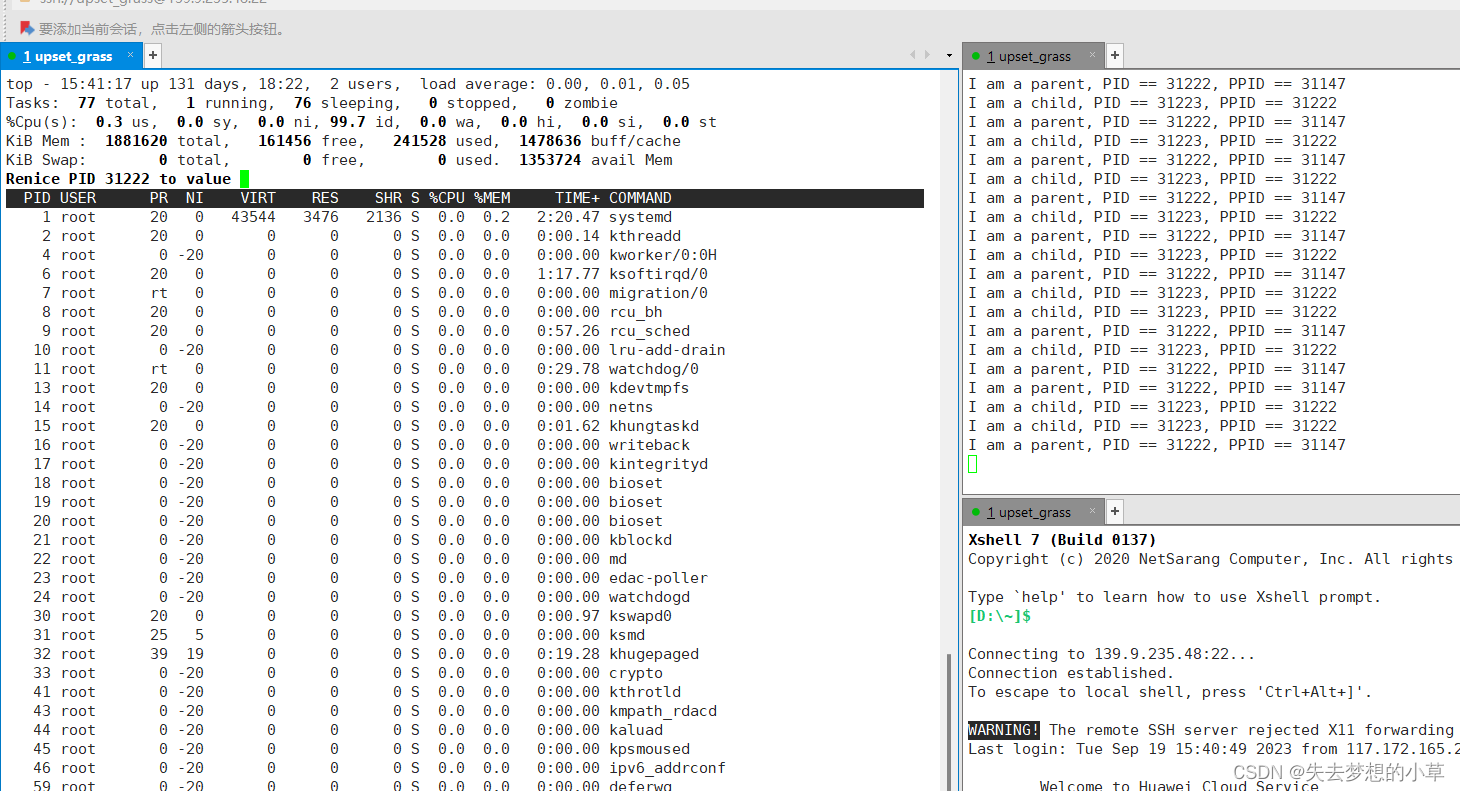
输入NI值,确定,退出任务管理器
ps -al 就能够查看此时的PRI NI

如果多次修改NI,会发现,PRI(新) = PRI(旧) + NI这个公式中的,PRI(旧)恒等保持为80,并不是上一次修改的结果,这能够有效的控制PRI的范围
操作系统的优先级调度
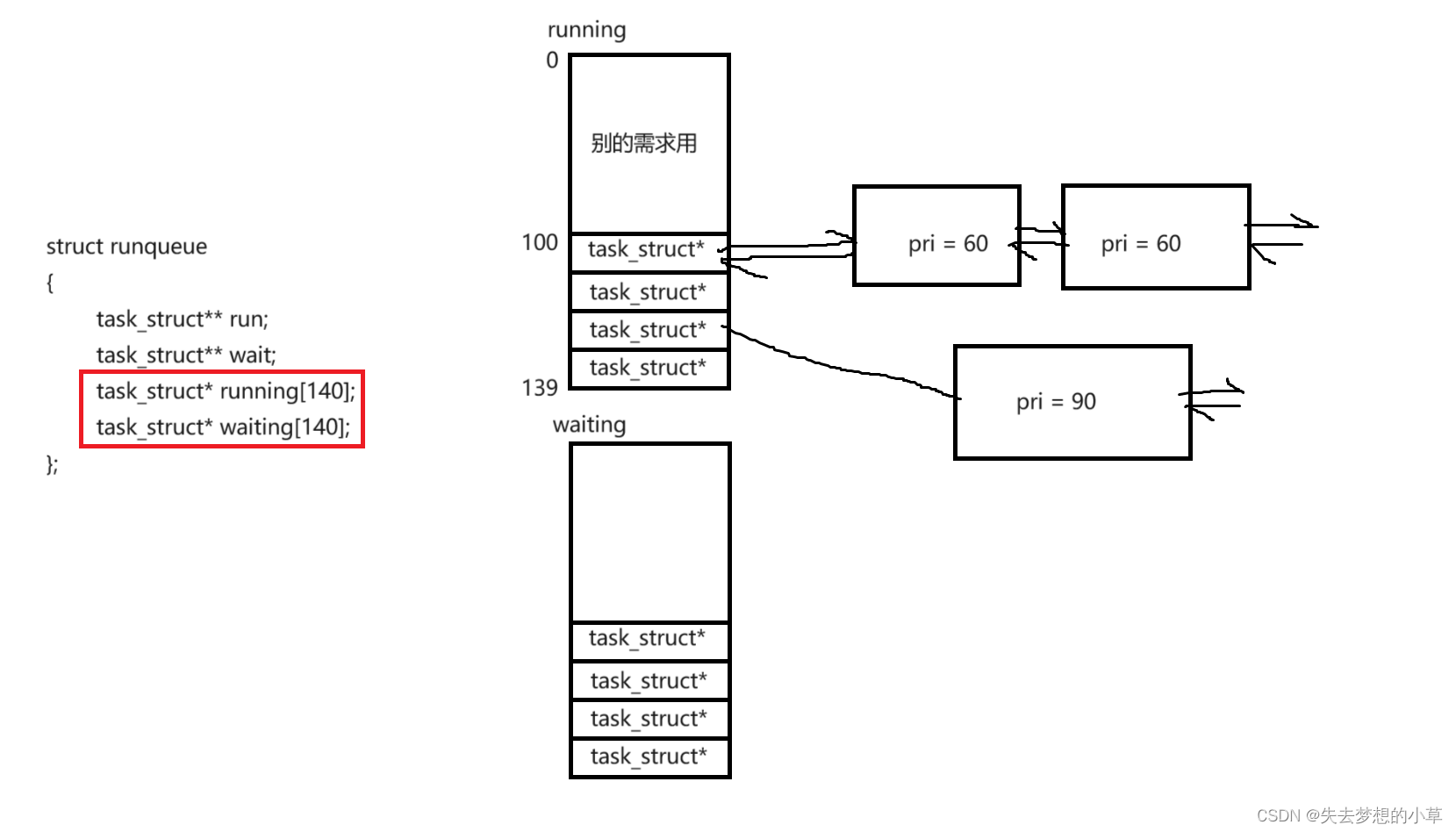
优先级主要是用于运行队列中,一般runqueue结构体中主要存储了两个task_struct* running[140]; task_struct* waiting[140];指针数组,以及两个分别指向runnnig和waiting的二级指针
running数组存的是当前正在运行的进程,我们目前只需要关注100 ~ 139这40个空间((0~99是控制实时进程的,现在基本已经抛弃了,只有一些特殊的领域会用,比如汽车车载系统,踩下刹车,立马执行,方向盘左拧,立马执行 这是区别于现在大多数的时间片轮转的方式的另一种调度方式时使用的)),这40个空间也就是40条队列
我们回顾前面pri的取值范围[60, 99]也是40个优先级,这里就用了哈希的思想,将[60, 99]一一映射到[100, 139],也就是说,进程进入running[100] ~ running[139]是看优先级pri,如果一个进程的优先级是60,那么就会链入到running[100]指针所在队列的队尾,如果一个进程的优先级是90,那么就链入到running[130]的队尾
在running数组中的进程在CPU上运行计算时,还会有其他进程申请进入运行队列,此时不会让进程直接链入到running数组中的队列中,而是链入到waiting数组后的队列中,当running数组中所有队列的进程跑完之后,就会交换两个二级指针run和wait,让waiting数组作为新的running数组,running作为新的waiting数组,一直这么更替运行下去。
我们对于CPU运行进程,则是通过这个数组,从低下标到高下标(不同优先级),以及先链接到后链接的顺序(相同优先级,先来先执行,后来后执行)调度执行进程
这里还有一个点,对于判断整个指针数组指向是否为都空,需要遍历整个数组,效率较低,所以这里还会涉及一个概念 —— 位图
bitmap isempty;
这个isempty中我们约定每一个bit位为1/0代表对应位置为空情况(空为0,非空为1)
比如这里,我们有40个数组元素需要检测为空,那我们只需要用char bits[5]来判断,我们可以约定,第一个比特位代表了下标为100的为空情况,… 最后一个比特位代表了下标为139的为空情况,这样,我们只需要判断这个bits(位图)是否为0即可,并且这个位图,还能够帮助我们:快速找到非零的比特位,进而快速确定优先级最高、来的最早的进程进行调度执行
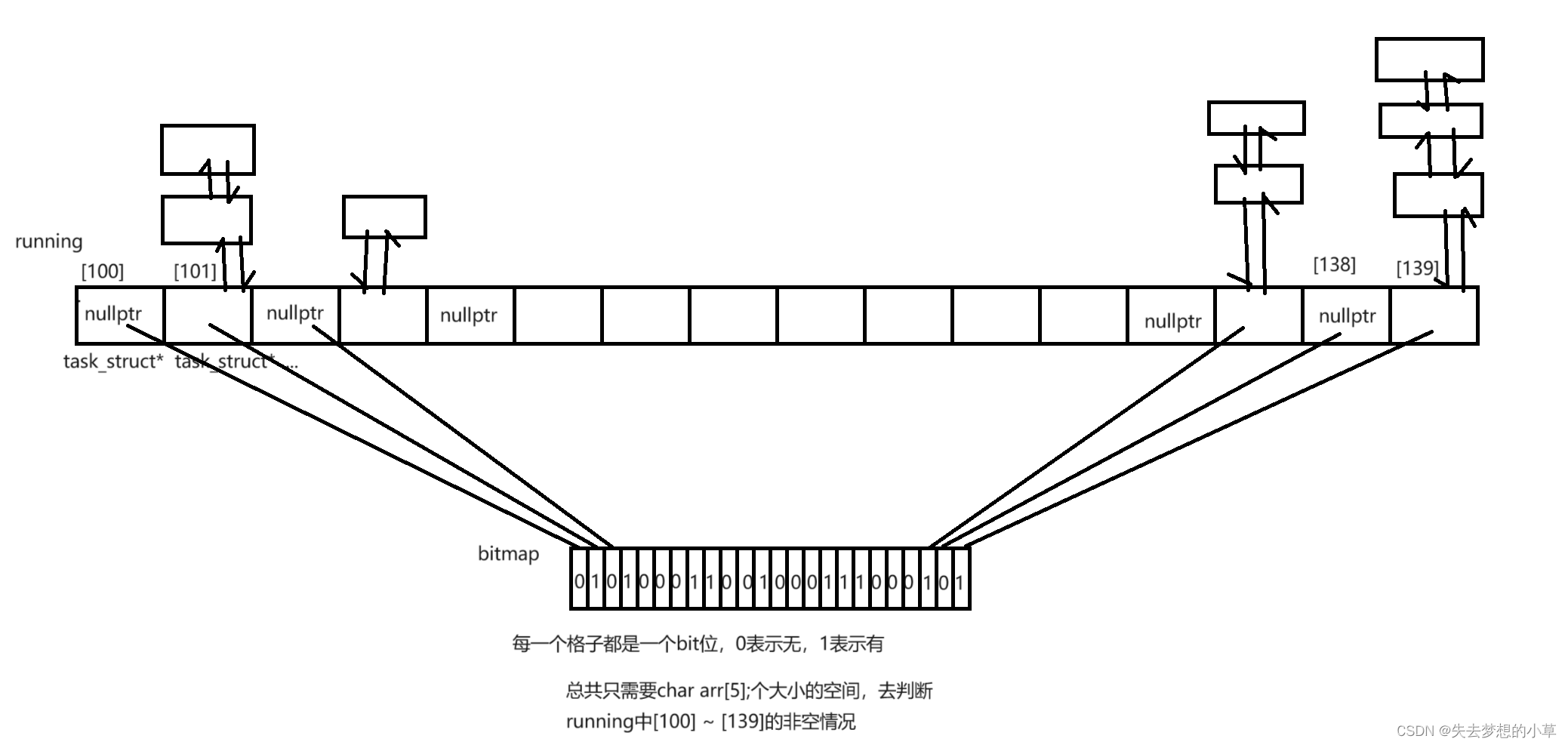
这个逻辑也称为Linux内核2.6版本的O(1)调度算法
一句话总结进程的调度逻辑:不同的进程赋予了不同的优先级,进而插入在运行队列中的PCB指针数组的不同位置上,而不同的位置就决定了进程的调度先后顺序
进程的特点
进程的竞争性
硬件资源是稀缺的,CPU、网卡、磁盘数量都不多,所以进程在使用这些资源时,都会考虑优先级,所以,进程之间具有竞争性,这种竞争性不止体现在加载进运行队列中,在网卡、磁盘的等待队列中去排队也会考虑优先级
独立性
硬件资源一般是很难多到多线程、并行操作,所以进程在运行时,都是独立占用硬件资源,当前进程在运行时,是不允许影响别人的
并行性
一台电脑拥有多个CPU,同一时刻多个进程在不同的CPU上运行,这就称为并行
并发性
一台电脑仅拥有一个CPU,一段时间内,采用进程切换的方式,让多个进程都能推进,这就称为并发
这种切换速度非常快,人感受不到,这种切换是基于时间片概念的,操作系统给每个进程设置了一个时间片,可能10ms,20ms,也就是一个进程如果在10ms之内,跑完了,就直接去销毁,如果没有跑完,就从CPU上拿下来,重新去runqueue中排队(重新排队是排到waiting指针数组上去)(基于时间片的轮转调度算法)
进程的切换过程是怎么样的?通过下面的问题,来回答这个问题
1)局部变量具有临时性、局部性,那为什么函数返回值能被外部拿到呢?
我们比如int a = 10; return a; 这里会被翻译成 mov eax 10,也就是把10放到某个寄存器中,虽然在内存中数据是临时的,函数调完,栈帧结构就释放了,但是会把返回值写入寄存器,而外部接收时 int ret = add(10, 20); 这个赋值号,也会被翻译成一些mov指令,把返回值又从寄存器中写入到对应变量中去(函数中new了空间,返回值传new的指针也是这个原因,如果空间过大,mov写入到寄存器的量会很大,占用的寄存器数量会很多,影响效率,所以也就只传指针)
2)CPU怎么知道,我们当前的程序执行到哪一行代码?顺序语句应该执行哪一行?判断语句应该到哪个分支?循环语句应该跳转到哪里?
CPU中又一个eip寄存器,是用于程序计数的,称为程序计数器——pc指针(point code),具体是用于记录正在执行的指令(当前行代码)的下一行指令的地址,比如此时代码是第49行,在顺序语句下,那么此时eip寄存器存储的是第50行,49行执行结束后,想要继续执行,那么就通过eip指向的指令,把这条指令加载到CPU中,然后让eip去存储51行的地址,或者当前在执行第30行指令(第30行代码),需要跳转到调用的函数中,也就是让eip存储函数入口的指令行数的地址,然后就能够跳转执行代码程序
寄存器的分类:
通用寄存器:eax、ebx、ecx、edx,
栈帧寄存器:ebp、esp、eip
状态寄存器:status
…
目前只需要知道:寄存器很多
3)寄存器扮演什么样的角色?寄存器对数据具有临时保存的能力,寄存器中存储的数据都是一些高频的数据,这些数据虽然是可以只存储在内存中,但是存储在寄存器中可以大大的提高效率,所以在运行进程时,寄存器中存储的是进程相关的数据,方便CPU频繁访问,读取或修改,这些数据都是一些临时数据 —— 称为进程的上下文数据
4)为什么进程第二次被CPU执行时,能够紧接着上一次执行?寄存器存储的都是进程的临时数据,那么如果一个时间片内,没有执行完,这些临时数据在其他进程进入时,就会被覆盖,所以当前进程在时间片到了需要进行进程切换时,CPU会把寄存器中的上下文数据全部交给进程,让进程保存起来(保存上下文数据),使得下一次切换到该进程时,能够接着上一次执行的末尾继续执行(恢复上下文数据)
CPU内寄存器中的这些临时数据,在切换时,是保存在进程的PCB中的,具体怎么从寄存器保存到PCB,是需要很多软硬件结合的知识(全局段描述符、局部段描述等)
下图是一种方式,但是这种方式效率很低,只能说便于这里的理解,具体的还是需要大家去深入了解,全局段描述符、局部段描述这些知识
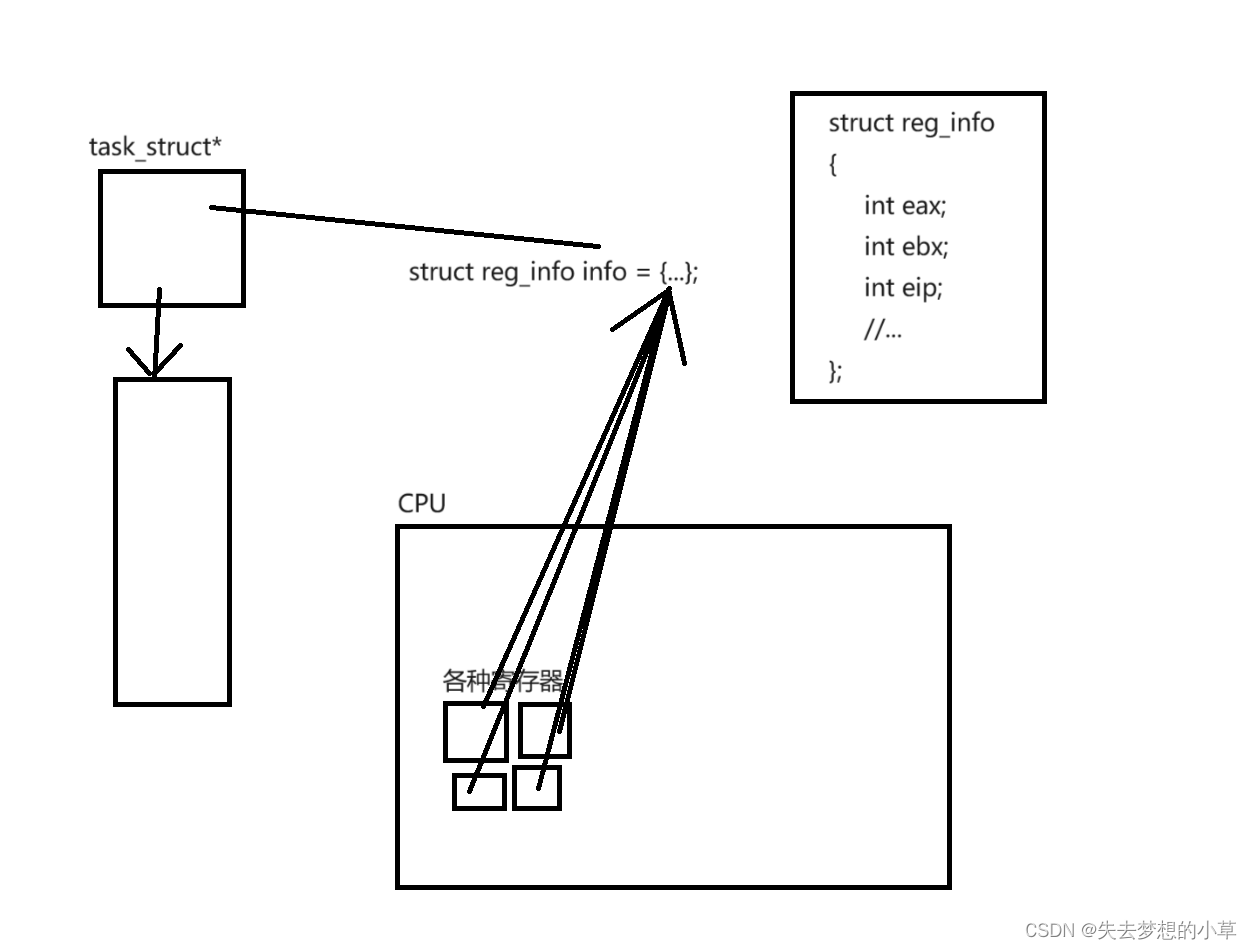
综上,进程的切换过程是怎么样的?进程在CPU上运行时会利用寄存器保存进程的上下文数据,高效的读取、写入数据,并在进程切换之间,把这些进程的上下文数据,存入进程的PCB中,并在下一次运行该进程时,回复上下文数据到CPU寄存器中,使得进程能够紧接着上一次继续执行进程
















 2816
2816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











