






排序
dense_rank() over ():排序,相同的值会并列排序(比如:Salary是100,200,300,300,400则是1,2,3,3,4)
row_number() over():相当于Oracle中的列名,不会并列排序(比如:Salary是100,200,300,300,400则是1,2,3,4,5)
rank() over():相同的值会并列排序,但相同的值的下一个值依然展示的是个数(比如:Salary是100,200,300,300,400则是1,2,3,3,5)
分区函数
partition by:按照什么进行分区
例题:
Employee 表工资前三名的员工并关联Department表查出部门
select a.name as Department,b.name as Employee,b.Salary from Department as a,(select dense_rank() over (partition by DepartmentId order by Salary desc) as rmk,Salary,DepartmentId,name from Employee ) as b
where a.id = b.DepartmentId and rmk <=3
判断是否为null
ifnull(a,b):如果为空则执行b,不为空执行a
limit
limit i,j:i为起始位置的索引(默认是0可省略,所以一般省略了),j是偏移量
例题:
输出第二高的工资,如果没有输出null
select ifnull(
(select distinct(Salary) from Employee order by Salary desc limit 1,1 )
,NULL) as SecondHighestSalary ;
分组查询
group by
例题:
超过2个的邮箱
select Email from (select Email,count(Email) as a from Person group by Email) as temp where temp.a>1
计算时间差
DATEDIFF(a,b):计算结束时间b与开始时间a之间的时间差
if
if(a,b,c):a满足则返回b,不满足返回c
case when
例子:
SELECT
case username
when ‘a’ then 1
when ‘b’ then 2
else 3
end
FROM users;
函数
- 定义函数:
create function 函数名(参数)returns 返回类型
begin
函数体
return(返回的);
end - 调用函数
SELECT function_name(parameter_value,…) - 删除函数
drop function function_name
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
select Salary from (
select Salary,dense_rank() over(order by Salary desc) as rmk from Employee ) as tep where tep.rmk=N
);
END
连接字符串
- CONCAT 连接多个字符串
select CONCAT(t.id,’–’,t.ticket_id,’–’,t.shopper_id) from parking_coupon_shop_ticket_relate t GROUP BY t.shopper_id ;
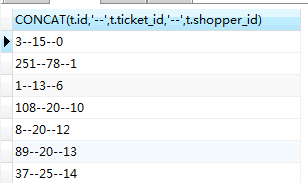
- GROUP_CONCAT 连接字符串可以与order by一起使用;并且必须与group by 一起使用,不然只返回一条数据
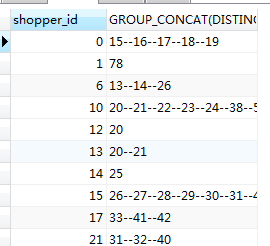
select t.shopper_id,GROUP_CONCAT(DISTINCT t.ticket_id order by t.ticket_id SEPARATOR ‘–’) from parking_coupon_shop_ticket_relate t GROUP BY t.shopper_id ;
(ticket_id 去重并且排序再用–连接)















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









