



在做目标检测时候,都会通过一些方法获得大量的数据集,或是网上下载,或是自己用软件一个一个的打标签。
不会打标签的可以看下这个文章
Win10下安装LabelImg及使用技巧--全网最快最简单Win10下安装LabelImg及使用--全网最快最简单 https://blog.csdn.net/Thebest_jack/article/details/124260693?spm=1001.2014.3001.5501 综合来说,网上的数据集绝大部分也是VOC数据文件
https://blog.csdn.net/Thebest_jack/article/details/124260693?spm=1001.2014.3001.5501 综合来说,网上的数据集绝大部分也是VOC数据文件
这是为了标签数据的最大化。在日常生活中,我们也通常会打VOC格式的标签(xml文件),因为它所包含的数据最多。例如下图:
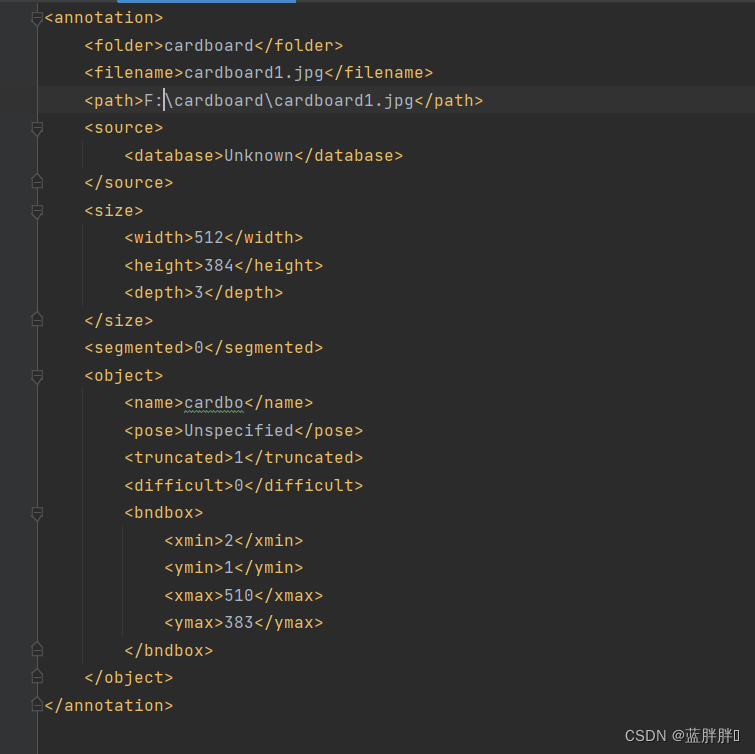 而在使用YOLO算法的时候,我们需要使用YOLO格式的数据才可以运行代码,训练自己模型。那么什么是YOLO格式的数据呢?可以看下下面图:
而在使用YOLO算法的时候,我们需要使用YOLO格式的数据才可以运行代码,训练自己模型。那么什么是YOLO格式的数据呢?可以看下下面图:![]()
那么接下来,就跟我一起来做这些那个伟大的工作吧!
代码已经放在了GitHub上,可以去这个【GitHub网址】下载,使用办法看ReadMe.md~
接下来说下大体怎么使用
在所有事情之前,你需要将XML数据的标签和图片放置到对应文件下
首先,需要给XML文件按照一定的比例分成train、val、test三个数据集。trainval_percent和train_percent 代表trainval和train的占比率,trainval_percent表示的是train+val之和。若不需要test集则改为1。train_percent 代表拿来训练的比例。这里我设置了trainval_percent = 0.9,
train_percent = 0.7。
修改的话只需要修改这三部分的占比率。运行【images_tag.py】,代码如下:
# 该脚本文件需要修改第11-12行,设置train、val、test的切分的比率
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/Annotations', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/Imagesets', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.7 #这里的train_percent 是指占trainval_percent中的
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
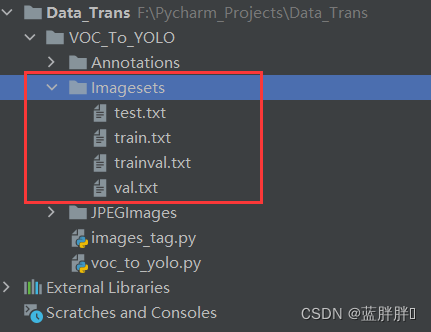
file_test.close()运行成功之后,会出现这个效果:红圈的就是生成的分类txt
然后,将xml格式标签转换为txt格式标签。运行【voc_to_yolo.py】,代码如下:
#该脚本文件需要修改第10行(classes)即可
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
sets = ['train', 'test','val']
#这里使用要改成自己的类别
classes = ['glass', 'metal', 'paper','plastic']
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
x = round(x,6)
w = round(w,6)
y = round(y,6)
h = round(h,6)
return x, y, w, h
#后面只用修改各个文件夹的位置
def convert_annotation(image_id):
#try:
in_file = open('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/Annotations/%s.xml' % (image_id), encoding='utf-8')
out_file = open('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
#except Exception as e:
#print(e, image_id)
#这一步生成的txt文件写在data.yaml文件里
wd = getcwd()
for image_set in sets:
if not os.path.exists('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/labels/'):
os.makedirs('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/labels/')
image_ids = open('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/Imagesets/%s.txt' %
(image_set)).read().strip().split()
list_file = open('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
list_file.write('F:/Pycharm_Projects/Data_Trans/VOC_To_YOLO/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
然后你会看到你的项目里多了个【labels】文件(用来存放转换后的yolo的标签)和三个txt文件。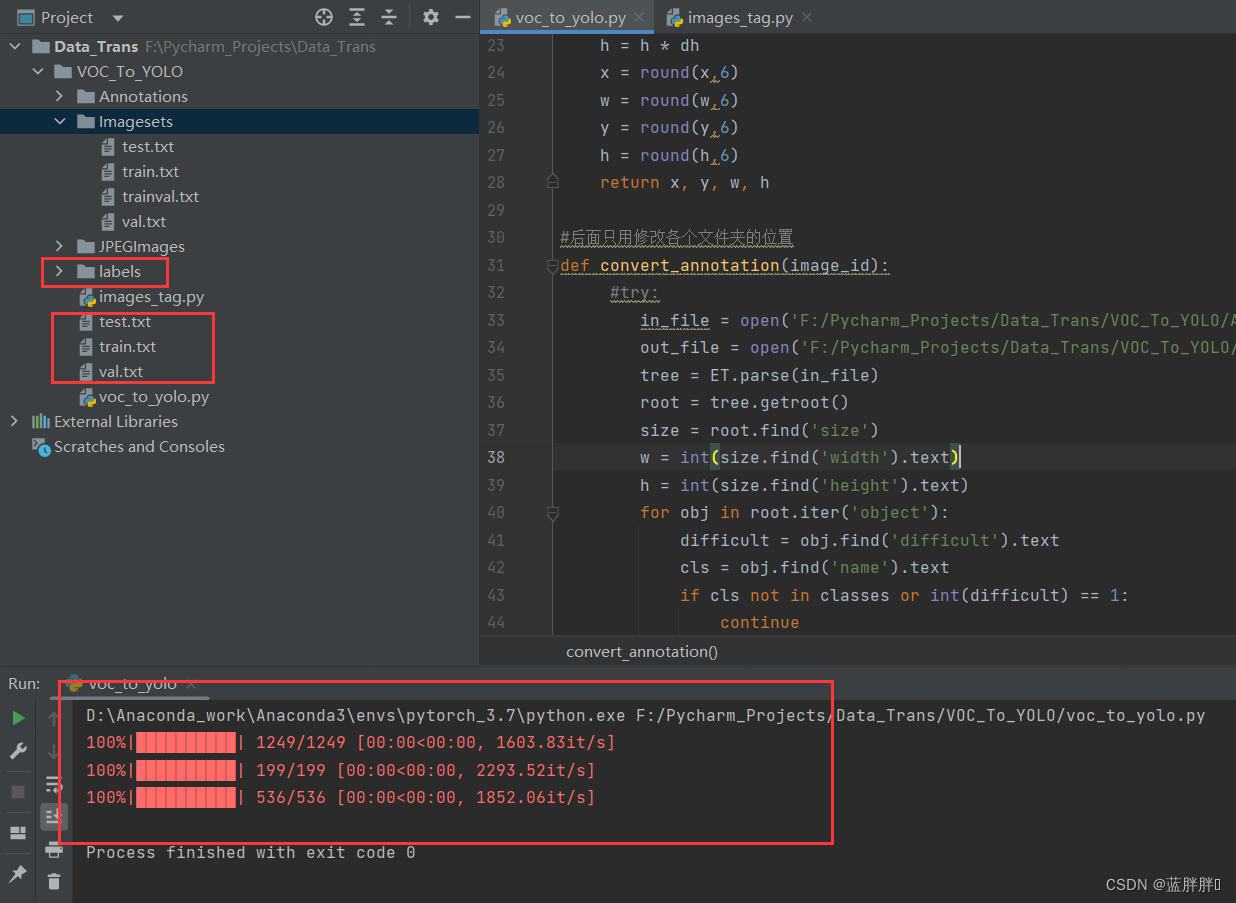
是不是该很简单?不会的留言评论加关注吧~~~


















 6407
6407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











