







第三课:数组、链表、跳表
一、数组Array List
数组的底层实现原理
内存管理器:
每次申请数组,计算机实际上是在内存中开辟一段连续的地址,每一个地址直接可以通过内存管理器进行访问
数组的优缺点
优点:
可以随机的访问任何一个元素,访问速度很快
缺点:
对数组元素进行增加或者删除的时候效率很低
数组增加元素


当我们想把这样一个数组中在索引为3的位置上插入新元素D,那么我们需要先把EFG依次往后挪一个位置,给D腾出一个空间,D才能进行插入操作,因此插入最坏的情况下的时间复杂度为O(n),最好的情况下的时间复杂度为O(1)
ArrayList中add()的源码:
//在数组的最后一个元素添加新的元素
public boolean add(E e) {
//判断数组有没有满
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//在数组的指定位置中添加新的元素
public void add(int index, E element) {
//判断传进来的索引是否会导致数组越界
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy():拷贝操作,把原地址的起点位置拷贝到目标地址的起点位置
//elementData, index:数组的原位置;elementData, index + 1:目标地址;size - index:长度,后半部分要挪动的部分
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
因此,如果对数组进行增加操作,会涉及到非常多的array copy的操作,时间复杂度以及空间复杂度就会偏低
数组删除元素


此时若想删除元素Z,则我们需要:
1.将Z元素取出,挪出数组
2.Z元素后的所有元素都向前移动一位
ArrayList中add()的源码:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
数组的增删改查操作的时间复杂度
prepend:头结点处增加元素
append:尾节点处增加元素
| prepend | O(1) |
|---|---|
| append | O(1) |
| lookup | O(1) |
| insert | O(n) |
| delete | O(n) |
二、链表Linked List
链表就是为了解决上述数组存在的问题,提升增加、删除元素效率,在增加和删除操作比较多的情况,优先考虑使用链表
链表中的每个元素一般用class去定义,一般称为node,节点类里面有两个成员变量:
1.value:存放该节点的数值
2.next:指针,指向其下一个元素
如果只有一个指针,则称为单链表;如果往前面也加一个指针,则称为先前指针previous,则该链表称为双向链表,既能向后面走,也能向前面走:头指针用head表示,尾指针用tail表示(一般而言,最后一个元素尾指针指向空);最后一个元素尾指针指向head,此时则变为循环链表

链表的定义
//链表的简单定义
class LinkedList {
Node head; // head of list
/* Linked list Node*/
class Node {
int data;
Node next;
// Constructor to create a new node
// Next is by default initialized
// as null
Node(int d) { data = d; }
}
}
Java里的链表定义

定义的是标准的双向链表结构
链表增加结点
1.原始链表如下图所示

2.现在有个新的结点欲添加进来

3.把前一个结点的next指针指向新结点,将新结点的next指针指向原来的后一个结点

在链表中进行增加操作只需要O(1)的复杂度
链表删除结点
链表删除节点就是刚刚增加节点的逆操作
1.原始链表如下图所示,其中Target Node为欲删除的结点
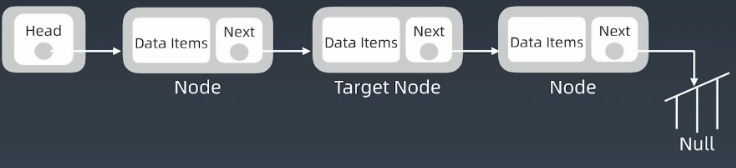
2.将Target Node的前躯的结点的next指向Target Node的后继结点

3.删除操作完成
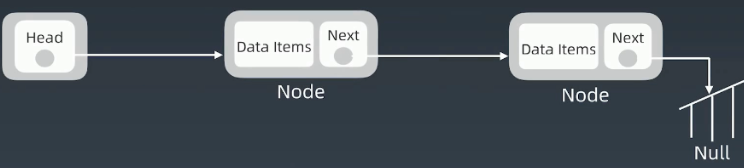
链表删除/增加结点的特点
不管是删除操作还是增加操作都没有引起整个链表的群移操作,操作的过程中也没有复制元素,因此链表删除/增加元素的操作效率十分高,为O(1)
但是这也导致了另一个缺点的暴露:要访问链表中任意一个元素就不再像数组一样简便,必须从头结点依次遍历,直到达到欲访问结点的位置,因此链表查找的时间复杂度为O(n)
链表的增删改查操作的时间复杂度
| prepend | O(1) |
|---|---|
| append | O(1) |
| lookup | O(n) |
| insert | O(1) |
| delete | O(1) |
Tips:
数组、链表的增加删除查找操作的时间复杂度要非常的清楚!
三、跳表SkipList
跳表理解即可,不需要深究
1.对链表进行了优化而产生的SkipList
2.主要在Redis里使用
优化链表的思想:升维(空间换时间)
将链表从一维结构升为二维结构
为了提高链表线性查找的效率,SkipList增加了索引
一级索引:
第一个指针指向头指针
第二个指针指向next+1
...
原始链表的next每次都是只往前走一步,但是一次索引每次都向前走两步,因此加了一级索引之后,访问速度就是原来的两倍
为了更快,我们可以使用二级索引,原始链表的next每次都是只往前走一步,一次索引每次都向前走两步,二次索引每次都向前走四步,因此加了二级索引之后,访问速度就是原来的四倍
...
以此类推,增加多级索引:增加log2n个级索引
非常重要的思想:
1.升维
2.空间换时间
一级索引:

二级索引:

多级索引:

跳表查询的时间复杂度
第k级索引结点的个数是n/(2^k)
假如索引有m级,最高级的索引有2个结点,n/(2^m) = 2,因此m = log2(n)-1
在跳表中查询数据的时间复杂度是O(logn)
跳表的空间复杂度
跳表的空间复杂度是O(n)
实际应用中跳表的形态
由于实际应用中,索引会随着元素的增加和删除发生变化,有些索引在个别地方跨m步,在其他地方跨n步,不是规整的索引结构
跳表的维护成本较高,每增加/删除元素一次就得更新一次索引,因此跳表增加/删除操作的时间复杂度是O(logn)
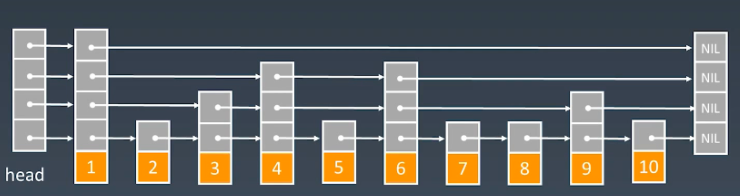
链表及跳表的实际应用场景
1.链表:LRU Cache
https://www.jianshu.com/p/b 1ab4a170c3c
https://leetcode-cn.com/problems/lru-cache
2.跳表:Redis
https://redisbook.readthedocs.io/en/latest/internal-datastruct/skijplist.html
https://www.zhihu.com/question/20202931















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









