







关于MapReduce详细解释参见博客
Mapper的输出排序、然后传送到Reducer的过程,称为Shuffle,Shuffle过程是MapReduce的核心内容。为什么需要Shuffle?Map是映射,负责数据的过滤分发;Reduce需要将具有共同特征的数据汇聚到一个计算节点上进行计算。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过 Shuffle来获取数据。
Map端Shuffle
在Map端的Shuffle过程是对Map的结果进行分区、排序、溢出写磁盘,然后将属于同一分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是Map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认)。流程图如下:

Partition
对于Map输出的每一个键值对,系统都会给定一个partition,partition值默认是通过计算key的hash值后对Reduce task的数量取模获得。如果一个键值对的partition值为1,意味着这个键值对会交给第一个Reducer处理。每一个Reduce的输出都是有序的,但是将所有Reduce的输出合并到一起却并非是全局有序的。
如何做到全局有序?只设置一个Reduce task,但是这样无法发挥集群的优势,而且能应对的数据量也很有限。最佳的方式是定义一个Partitioner,用输入数据的最大值除以系统Reduce task数量的商作为分割边界,即分割数据的边界为此商的1倍、2倍至numPartitions-1倍,就能保证执行partition后的数据是整体有序的。
另一种需要定义一个Partitioner的情况是各个Reduce task处理的键值对数量极不平衡。对于某些数据集,由于很多不同的key的hash值都一样,导致这些键值对都被分给同一个Reducer处理,而其他的Reducer处理的键值对很少,导致数据倾斜。
环形Buffer数据结构——maptask.MapOutputBuffer
每一个Map任务有一个环形Buffer,Map将输出写入到这个Buffer。环形Buffer是内存中的一种首尾相连、专门用来存储Key-Value格式数据的数据结构,使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
Hadoop中,环形缓冲其实就是一个字节数组kvbuffer:
private byte[] kvbuffer; // main output buffer
kvbuffer = new byte[maxMemUsage - recordCapacity];
在kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。kvbuffer包含数据区和索引区kvmeta,这两个区是相邻不重叠的区域,用一个分界点来标识。分界点不是不变的,而是每次Spill之后都会更新一次。初始分界点为0,数据存储方向为向上增长,索引数据的存储方向向下增长:
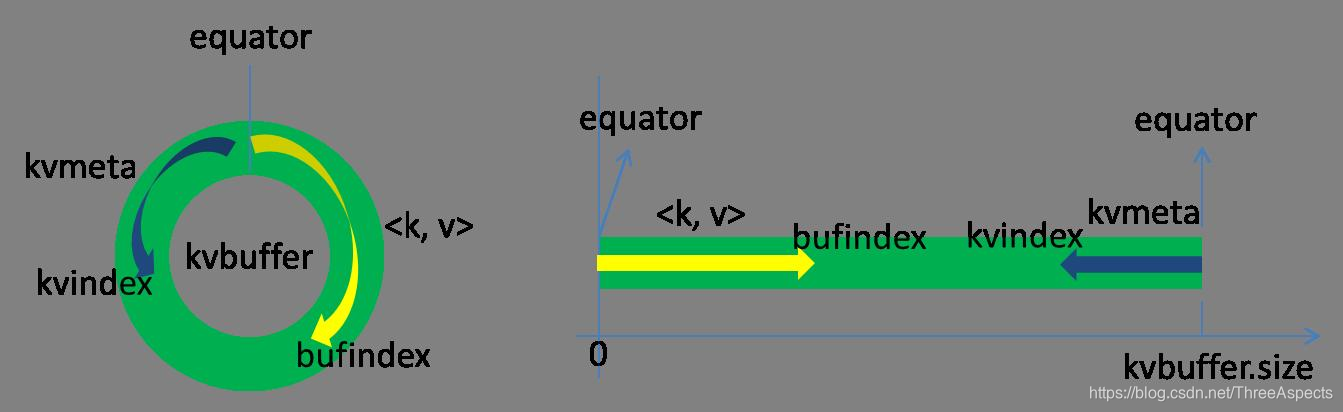
kvbuffer的存放指针bufindex是一直往上增长,比如bufindex初始值为0,写入一个int类型的key之后变为4,写入一个int类型的value之后变成8。索引是对key-value在kvbuffer中的索引,是个四元组,占用四个Int长度,包括:
- value的起始位置
- key的起始位置
- partition值
- value的长度
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









