








爬虫可以通过模拟浏览器行为,向目标网站发送HTTP请求。请求头中包含了关键信息,如用户代理(User-Agent)、Cookie、Referer等,这些信息对服务器的请求处理和响应内容产生影响。以下是查找和设置请求头的一般步骤:
步骤 1:查看目标网站的请求头信息
首先,打开浏览器并访问目标网站。然后,使用浏览器的开发者工具查看请求头信息。通常,你可以按下 F12 键或右键单击页面上的元素并选择 “检查” 或 “审查元素” 打开开发者工具。在开发者工具中,切换到 “网络” 或 “Network” 选项卡,并刷新页面或进行目标操作。在此处,你将看到与页面加载相关的所有HTTP请求。
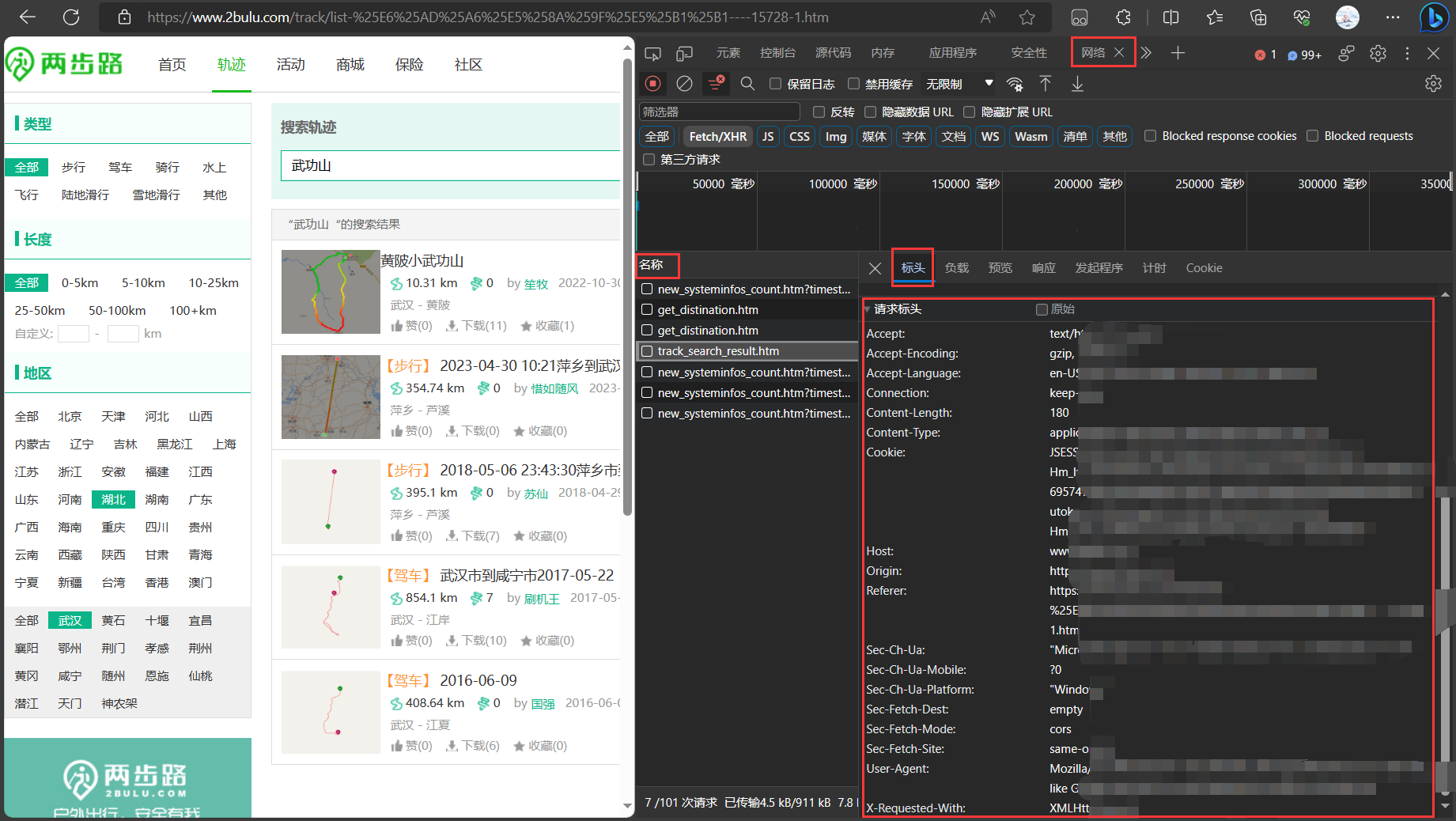
步骤 2:查看特定请求的请求头
在开发者工具的 “网络” 选项卡中,列出了所有HTTP请求,包括HTML页面、CSS、JavaScript、图像等。点击你感兴趣的HTTP请求,然后在右侧面板中选择 “Headers” 或 “标头” 选项卡。在这里,你将找到该请求的请求头信息。
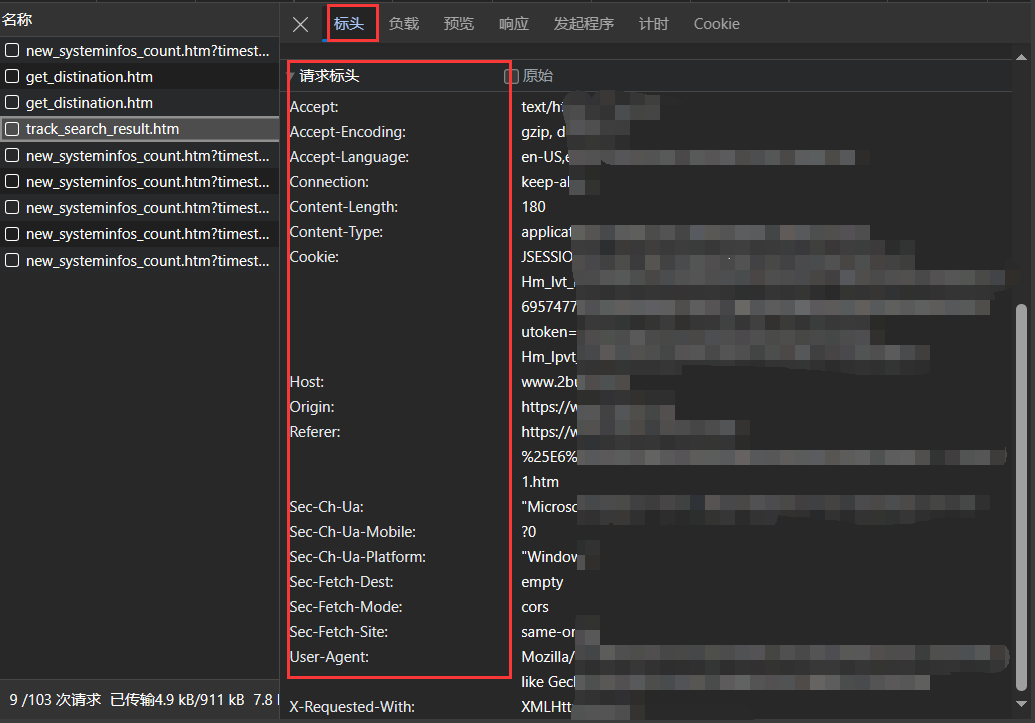
步骤 3:查找关键信息
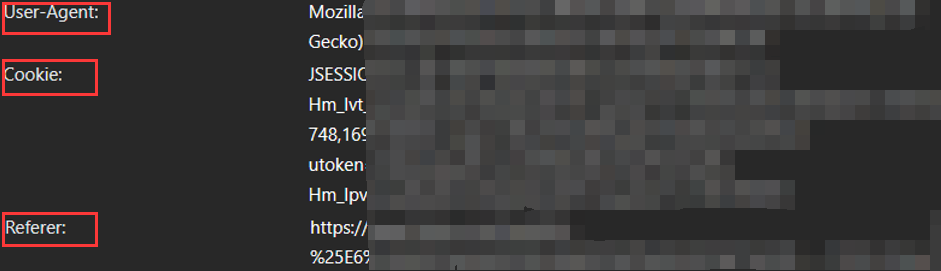
请求头中通常包括以下关键信息:
- User-Agent(用户代理): 用于标识请求的客户端类型和版本。模拟浏览器请求时,你可以设置适当的User-Agent,以表示你是一个浏览器。
- Cookie(Cookie信息): 有些网站使用Cookie来跟踪用户状态和身份验证。你可以通过设置请求头中的Cookie来模拟已登录的状态。
- Referer(引荐来源): 有些网站会检查Referer来确保请求来自其它页面。你可以设置Referer来模拟从特定页面链接到目标页面。
- 其他自定义信息: 根据目标网站的要求,还可以包括其他自定义信息。
步骤 4:使用Python爬虫库发送请求
一旦你了解了所需的请求头信息,可以使用Python的爬虫库(例如requests)发送HTTP请求,并在请求中设置相应的请求头。以下是一个示例:
import requests
url = 'https://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36',
'Cookie': 'your_cookie_here',
'Referer': 'https://referrer_url.com',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 处理响应内容
print(response.text)
通过设置适当的请求头信息,你可以模拟浏览器请求,并获取所需的网页内容。但请注意,爬虫操作必须遵守目标网站的使用政策和法律法规。
| 术语或函数 | 解释 |
|---|---|
| User-Agent | 用于标识客户端的信息 |
| Cookie | 存储在用户计算机上的信息,用于跟踪用户状态 |
| Referer | 表示请求来源的URL |
| requests | Python中用于发送HTTP请求的库 |
如果这对您有所帮助,希望点赞支持一下作者! 😊



















 3134
3134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









