







在Java中,JVM为8种基本类型以及String类型提供了常量池。
基于String类型使用常量池,通常有两种方法:
- 在直接使用双引号声明的String对象会直接存储在常量池中。
- 否则,使用String的intern方法。
String的intern方法会从字符串常量池中查询当前字符串是否存在,如果不存在则将当前字符串放入常量池,否则返回字符串。
注意,String的字符串是一个固定大小的Hashtable(可通过-XX:StringTableSize=1009进行调节),默认值是1009,如果字符串常量池中的String非常多,就会造成Hash冲突,从而导致链表很长,性能会大幅下降(因为要一个一个找)。
一个问题:
先给出一段代码,
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);false true如果把s2.intern语句放在s4声明之下,如下:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
false false
解释如下:
这里要明确一点,在JDK6中字符串常量池是放在Perm区中的,Perm区是一个类静态的区域,主要存储一些加载类的信息,常量池,方法片段等内容,默认大小只有4M,一旦常量池中大量使用intern方法会直接产生java.lang.OutOfMemoryError: PermGen space错误。 所以在JDK7之后,字符串常量池从Perm区移到了Heap中。
第一段代码片段示意图如下:
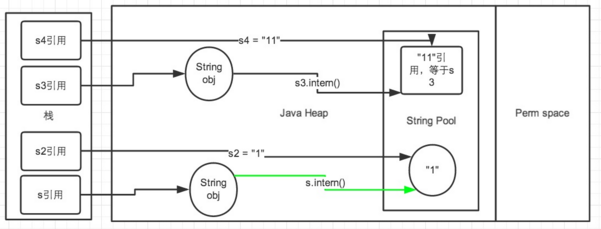
"String s = new String("1");" ——第一句代码生成了两个对象,常量池中(由创建参数而来)和堆中各有一个"1",引用s指向的是堆中的那一个对象。
"s.intern();"————这一句是s对象去常量池中寻找,发现常量池中存在"1"。
"String s2 = "1";"————这句代码是生成一个引用s2指向常量池中为"1"的对象。结果就是s和s2的引用地址明显不同。
"String s3 = new String("1") + new String("1");"————此时s3引用对象内容是"11″,但此时常量池中没有"11"(因为String创建参数只有"1")。
"s3.intern();"————这一句代码,是将 s3中的"11"字符串放入String常量池中,因为此时常量池中不存在"11"字符串,因此在常量池中生成一个"11" 的对象,注意此时常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。
"String s4 = "11";"———— 这句代码中"11″是显式声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以s4引用就指向和s3一样。因此最后的比较s3 == s4是true。
第二段代码片段示意图:
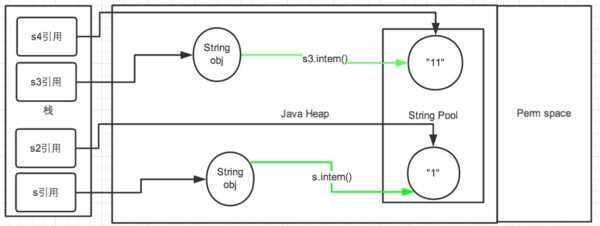
第一段代码和第二段代码的改变就是
s3.intern();语句
的顺序是放在
String s4 = "11";
后面。这样,首先执行
String s4 = "11";
声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行
s3.intern();
时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。
第二段代码中的s和s2代码中,s.intern();这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。
Note:对于String#intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象!















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









