








获取电脑IP地址的方法有多种,下面详细介绍两种简单易用的方法:通过命令提示符(CMD)和网络与共享中心。无论您是偏好命令行还是图形界面,这两种方法都可以轻松帮助您找到电脑的IP地址。
方法一:通过命令提示符(CMD)
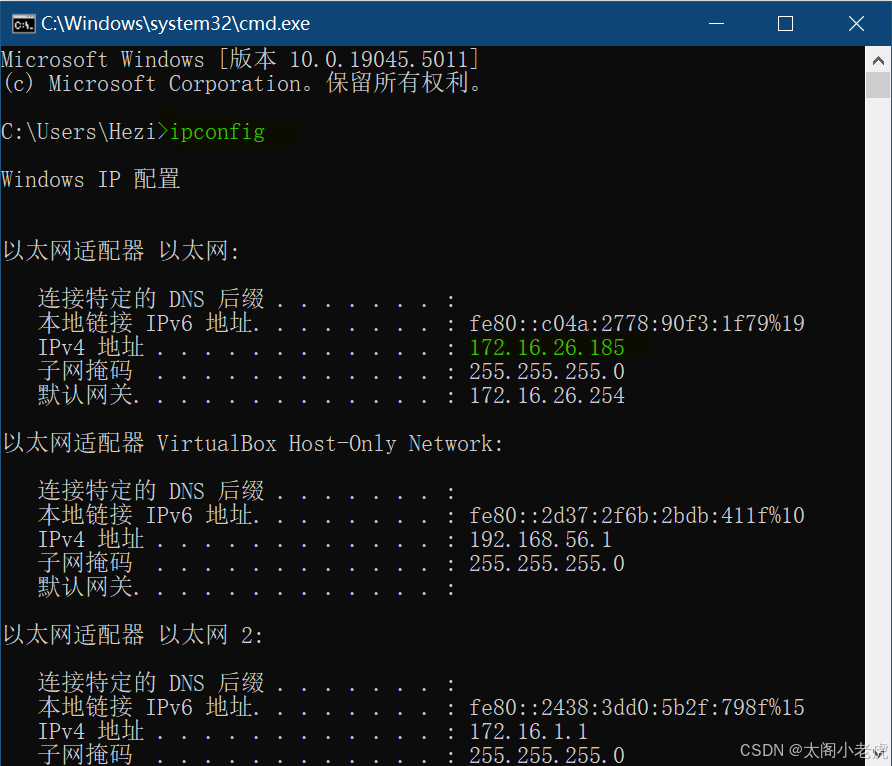
这是最直接、快速的方法,特别适合熟悉命令行的用户。具体步骤如下:
1. 按下 Win + R 键打开“运行”窗口。
2. 在“运行”对话框中输入 cmd,然后按下回车键,打开命令提示符窗口。
3. 在命令提示符中输入 ipconfig 并按下回车。
4. 系统会显示所有网络适配器的配置信息,找到“IPv4 地址”一行,即可看到当前网络连接的IP地址。
这种方法适用于所有Windows版本,快速便捷。命令行能直接显示设备所有网络接口的信息,适合快速查询以及获取更多网络参数,例如子网掩码和默认网关。
方法二:通过网络和共享中心
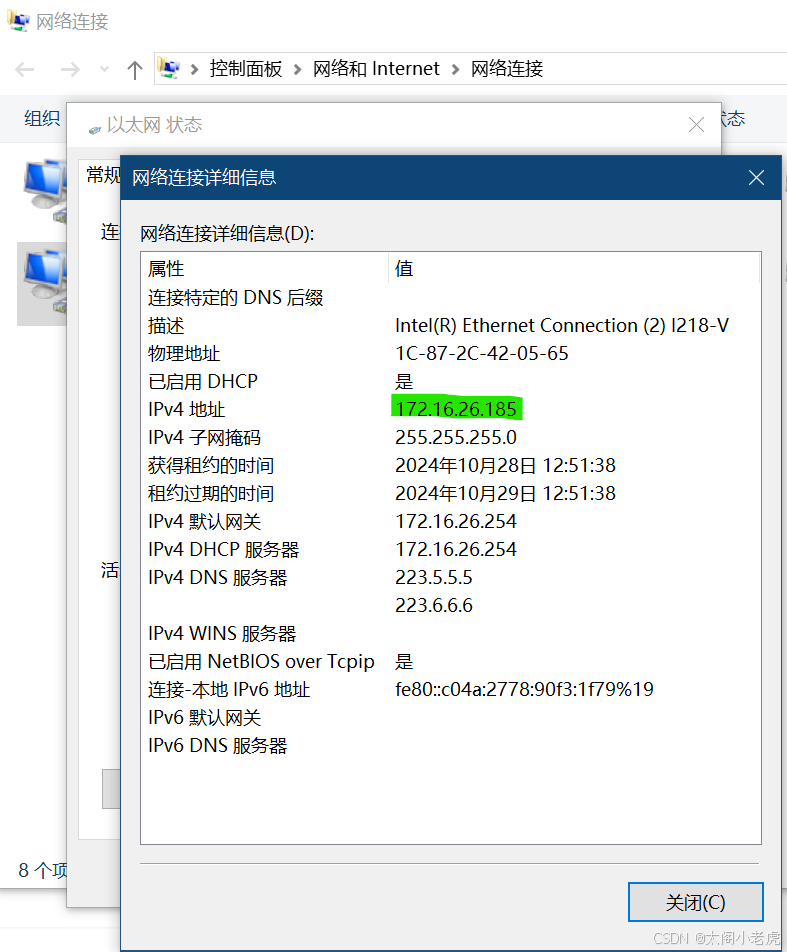
如果您不喜欢使用命令行,更倾向于图形界面的操作,可以通过“网络和Internet设置”查看IP地址。这种方法操作步骤简单,适合不熟悉命令行的用户,特别是Windows 10和Windows 11用户:
1. 右键点击任务栏右下角的网络图标(WiFi或以太网图标),选择“打开网络和Internet设置”。
2. 在打开的窗口中,点击“状态”选项卡,然后选择“查看网络属性”。
3. 向下滚动,找到“IPv4 地址”一行(在有线连接情况下,也可在“本地连接”中找到),即为当前设备的IP地址。
这种方法更直观友好,所有操作均在图形界面完成,非常适合不熟悉命令行的用户,尤其是新版本Windows系统用户。此外,网络属性窗口可以直接查看DNS、网关等网络配置,方便用户整体了解网络状态。

















 7914
7914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









