







本文包含CCF-CSP模拟考试系统中历年考试全部第二题的答案,目前更新至202012-2。
- 202012-2 期末预测之最佳阈值
- 202009-2 风险人群筛查
- 202006-2 稀疏向量
- 201912-2 回收站选址
- 201909-2 小明种苹果(续)
- 201903-2 二十四点
- 201812-2 小明放学
- 201809-2 买菜
- 201803-2 碰撞的小球
- 201712-2 游戏
- 201709-2 公共钥匙盒
- 201703-2 学生排队
- 201612-2 工资计算
- 201609-2 火车购票
- 201604-2 俄罗斯方块
- 201512-2 消除类游戏
- 201509-2 日期计算
- 201503-2 数字排序
- 201412-2 Z字形扫描
- 201409-2 画图
- 201403-2 窗口
- 201312-2 ISBN号码
202012-2 期末预测之最佳阈值
【题目背景】
考虑到安全指数是一个较大范围内的整数、小菜很可能搞不清楚自己是否真的安全,顿顿决定设置一个阈值 θ,以便将安全指数 y 转化为一个具体的预测结果——“会挂科”或“不会挂科”。
因为安全指数越高表明小菜同学挂科的可能性越低,所以当 y≥θ 时,顿顿会预测小菜这学期很安全、不会挂科;反之若 y<θ,顿顿就会劝诫小菜:“你期末要挂科了,勿谓言之不预也。”
那么这个阈值该如何设定呢?顿顿准备从过往中寻找答案。
【题目描述】
具体来说,顿顿评估了 m 位同学上学期的安全指数,其中第 i(1≤i≤m)位同学的安全指数为 yi,是一个 [0,10^8] 范围内的整数;同时,该同学上学期的挂科情况记作 resulti∈0,1,其中 0 表示挂科、1 表示未挂科。
相应地,顿顿用 predictθ(y) 表示根据阈值 θ 将安全指数 y 转化为的具体预测结果。
如果 predictθ(yj) 与 resultj 相同,则说明阈值为 θ 时顿顿对第 j 位同学是否挂科预测正确;不同则说明预测错误。
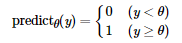
最后,顿顿设计了如下公式来计算最佳阈值 θ*:
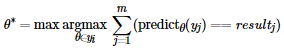
该公式亦可等价地表述为如下规则:
1.最佳阈值仅在 yi 中选取,即与某位同学的安全指数相同;
2.按照该阈值对这 m 位同学上学期的挂科情况进行预测,预测正确的次数最多(即准确率最高);
3.多个阈值均可以达到最高准确率时,选取其中最大的。
【输入格式】
从标准输入读入数据。
输入的第一行包含一个正整数 m。
接下来输入 m 行,其中第 i(1≤i≤m)行包括用空格分隔的两个整数 yi 和 resulti,含义如上文所述。
【输出格式】
输出到标准输出。
输出一个整数,表示最佳阈值 θ*。
【样例1输入】
6
0 0
1 0
1 1
3 1
5 1
7 1
【样例1输出】
3
【样例1解释】
按照规则一,最佳阈值的选取范围为 0,1,3,5,7。
θ=0 时,预测正确次数为 4;
θ=1 时,预测正确次数为 5;
θ=3 时,预测正确次数为 5;
θ=5 时,预测正确次数为 4;
θ=7 时,预测正确次数为 3。
阈值选取为 1 或 3 时,预测准确率最高;
所以按照规则二,最佳阈值的选取范围缩小为 1,3。
依规则三,θ* = max1,3 = 3。
【样例2输入】
8
5 1
5 0
5 0
2 1
3 0
4 0
100000000 1
1 0
【样例2输出】
100000000
【子任务】
70% 的测试数据保证 m≤200;
全部的测试数据保证 2≤m≤10^5。
#include <bits/stdc++.h>
using namespace std;
struct node {
int y;
int result;
};
int cmp(node n1, node n2) {
return n1.y < n2.y;
}
node nodes[100005];
int smaller0[100005];
int bigger1[100005];
int main() {
int n;
cin>>n;
node* nodes = new node[n];
nodes[0].y = -1;
for(int i = 1; i <= n; i++) {
cin>>nodes[i].y>>nodes[i].result;
}
sort(nodes + 1, nodes + 1 + n, cmp);
for(int i = 1; i <= n; i++) {
if(nodes[i].result == 0) {
smaller0[i] = smaller0[i - 1] + 1;
} else {
smaller0[i] = smaller0[i - 1];
}
}
for(int i = n; i >= 1; i--) {
if(nodes[i].result == 1) {
bigger1[i] = bigger1[i + 1] + 1;
} else {
bigger1[i] = bigger1[i + 1];
}
}
int besty;
int bestsum = 0;
for(int i = 1; i <= n; i++) {
if(nodes[i].y == nodes[i - 1].y) {
//相同y值,只判断第一个
continue;
}
int sum = 0;
sum = smaller0[i - 1] + bigger1[i];
if(sum >= bestsum) {
bestsum = sum;
besty = nodes[i].y;
}
}
cout<<besty;
return 0;
}
202009-2 风险人群筛查
【题目背景】
某地疫情爆发后,出于“应检尽检”的原则,我们想要通知所有近期经过该高危区域的居民参与核酸检测。
【问题描述】
想要找出经过高危区域的居民,分析位置记录是一种简单有效的方法。
具体来说,一位居民的位置记录包含 t 个平面坐标 (x1,y1),(x2,y2),…,(xt,yt),其中 (xt,yt) 表示该居民 i 时刻所在位置。
高危区域则可以抽象为一个矩形区域(含边界),左下角和右上角的坐标分别为 (xl,yd) 和 (xr,yu),满足 xl<xr 且 yd<yu。
考虑某位居民的位置记录,如果其中某个坐标位于矩形内(含边界),则说明该居民经过高危区域;进一步地,如果其中连续 k 个或更多坐标均位于矩形内(含边界),则认为该居民曾在高危区域逗留。需要注意的是,判定经过和逗留时我们只关心位置记录中的 t 个坐标,而无需考虑该居民在 i 到 i+1 时刻之间位于何处。
给定高危区域的范围和 n 位居民过去 t 个时刻的位置记录,试统计其中经过高危区域的人数和曾在高危区域逗留的人数。
【输入格式】
输入共 n+1 行。
第一行包含用空格分隔的七个整数 n、k、t、xl、yd、xr 和 yu,含义如上文所述。
接下来 n 行,每行包含用空格分隔的 2t 个整数,按顺序表示一位居民过去 t 个时刻的位置记录 (x1,y1),(x2,y2),…,(xt,yt)。
【输出格式】
输出共两行,每行一个整数,分别表示经过高危区域的人数和曾在高危区域逗留的人数。
【样例输入1】
5 2 6 20 40 100 80
100 80 100 80 100 80 100 80 100 80 100 80
60 50 60 46 60 42 60 38 60 34 60 30
10 60 14 62 18 66 22 74 26 86 30 100
90 31 94 35 98 39 102 43 106 47 110 51
0 20 4 20 8 20 12 20 16 20 20 20
【样例输出1】
3
2
【样例1说明】
如下图红色标记所示,前三条位置记录经过了高危区域;
但第三条位置记录(图中左上曲线)只有一个时刻位于高危区域内,不满足逗留条件。

【样例输入2】
1 3 8 0 0 10 10
-1 -1 0 0 0 0 -1 -1 0 0 -1 -1 0 0 0 0
【样例输出2】
1
0
【样例2说明】
该位置记录经过了高危区域,但最多只有连续两个时刻位于其中,不满足逗留条件。
【评测用例规模与约定】
全部的测试点满足 1≤n≤20,1≤k≤t≤10^3,所有坐标均为整数且绝对值不超过 10^6。
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
int k;
int t;
int xl, yd, xr, yu;
cin>>n>>k>>t>>xl>>yd>>xr>>yu;
int pass = 0, stay = 0;
for(int i = 0; i < n; i++) {
int* pos = new int[t * 2];
for(int j = 0; j < t * 2; j++) {
cin>>pos[j];
}
int passFlag = 0, stayFlag = 0;
int stayCount = 0;
for(int j = 0; j < t * 2; j += 2) {
if(pos[j] >= xl && pos[j] <= xr && pos[j + 1] >= yd && pos[j + 1] <= yu) {
stayCount++;
passFlag = 1;
if(stayCount == k) {
stayFlag = 1;
break;
}
} else {
stayCount = 0;
}
}
if(stayFlag == 1) {
pass++;
stay++;
} else if(passFlag == 1) {
pass++;
}
}
cout<<pass<<endl<<stay;
return 0;
}
202006-2 稀疏向量
【题目描述】
对于一个n维整数向量v∈Zn,其在第index个维度上的取值记作vindex。这里我们约定index的取值从1开始,即v=(v1,v2,…vn)。下面介绍一种向量的稀疏表示方法。
如果v仅在少量维度上的取值不为0,则称其为稀疏向量。
例如当n=10时,v=(0,0,0,5,0,0,-3,0,0,1)就是一个稀疏向量。
由于稀疏向量的非零值较少,我们可以通过仅存储非零值的方式来节省空间。具体来说,每个非零值都可以用一个(index,value)对来表示,即该向量在第index个维度上的取值vindex=value≠0。在上面的例子中,v就可以表示为[(4,5),(7,-3),(10,1)]。
接下来给出这种稀疏表示一般化的定义。
·对于任意一个n维整数向量v∈Zn,如果其在且仅在a个维度上取值不为0,则可以唯一表示为:
[(index1,value1),(index2,value2),…,(indexa,valuea)]
·其中所有的index均为整数且满足
1≤index1<index2<…<indexa≤n
· valuei表示向量v在对应维度indexi上的非零值。
给出两个n维整数向量u,v∈Zn的稀疏表示,试计算它们的内积。

【输入格式】
从标准输入读入数据。
输入的第一行包含用空格分隔的三个正整数n、a和b,其中n表示向量u、v的维数,a和b分别表示两个向量所含非零值的个数。
第二行到第a+1行输入向量u的稀疏表示。第i+1行(1≤i≤a)包含用空格分隔的两个整数indexi和valuei,表示vindexi=valuei≠0。
第a+2行到第a+b+1行输入向量v的稀疏表示。第j+a+1行(1≤j≤b)包含用空格分隔的两个整数indexj和valuej,表示vindexj=valuej≠0。
【输出格式】
输出到标准输出。
输出一个整数,表示向量u和v的内积u·v。
【样例输入】
10 3 4
4 5
7 -3
10 1
1 10
4 20
5 30
7 40
【样例输出】
-20
【样例解释】
u=(0,0,0,5,0,0,-3,0,0,1)
v=(10,0,0,20,30,0,40,0,0,0)
u·v=5×20+(-3)×40=-20
【子任务】
·输入数据保证0<a,b<n;
·向量u和v在每一维度上取值的绝对值|ui|,|vi|≤10^6(1≤i≤n)。

#include <bits/stdc++.h>
using namespace std;
int main()
{
int n,a,b;
cin>>n>>a>>b;
map<int,int> m;
int i;
int index,value;
for(i=0;i<a;i++)
{
cin>>index>>value;
m[index]=value;
}
long long sum=0; //sum使用int型会越界
for(i=0;i<b;i++)
{
cin>>index>>value;
if(m[index]!=0) //u、v在同一维度上值均不为0,积才不为0
sum+=m[index]*value;
}
cout<<sum;
return 0;
}
201912-2 回收站选址
【题目背景】
开学了,可是校园里堆积了不少垃圾杂物。
热心的同学们纷纷自发前来清理,为学校注入正能量~
【题目描述】
通过无人机航拍我们已经知晓了n处尚待清理的垃圾位置,其中第i(1≤i≤n)处的坐标为(xi,yi),保证所有的坐标均为整数。
我们希望在垃圾集中的地方建立些回收站。具体来说,对于一个位置(x,y)是否适合建立回收站,我们主要考虑以下几点:
·(x,y)必须是整数坐标,且该处存在垃圾;
·上下左右四个邻居位置,即(x,y+1)、(x,y-1)、(x+1,y)和(x-1,y)处,必须全部存在垃圾;
·进一步地,我们会对满足上述两个条件的选址进行评分,分数为不大于4的自然数,表示在(x±1,y±1)四个对角位置中有几处存在垃圾。
现在,请你统计一下每种得分的选址个数。
【输入格式】
从标准输入读入数据。
输入总共有n+1行。
第1行包含一个正整数n,表示已查明的垃圾点个数。
第1+i行(1≤i≤n)包含由一个空格分隔的两个整数xi和yi,表示第i处垃圾的坐标。
保证输入的n个坐标互不相同。
【输出格式】
输出到标准输出。
输出共五行,每行一个整数,依次表示得分为0、1、2、3和4的回收站选址个数。
【样例1输入】
7
1 2
2 1
0 0
1 1
1 0
2 0
0 1
【样例1输出】
0
0
1
0
0
【样例1解释】

如图所示,仅有(1,1)可选为回收站地址,评分为2。
【样例2输入】
2
0 0
-100000 10
【样例2输出】
0
0
0
0
0
【样例2解释】
不存在可选地址。
【样例3输入】
11
9 10
10 10
11 10
12 10
13 10
11 9
11 8
12 9
10 9
10 11
12 11
【样例3输出】
0
2
1
0
0
【样例3解释】
1分选址:(10,10)和(12,10);
2分选址:(11,9)。
【子任务】
·测试点1和2,保证对于任意的i皆满足0≤xi,yi≤2;
·测试点3、4和5,保证对于任意的i皆满足0≤xi,yi≤500;
·测试点6、7和8,保证对于任意的i皆满足0≤xi,yi≤10^9;
·测试点9和10,保证对于任意的i皆满足|xi|,|yi|≤10^9,即坐标可以是负数。
所有的测试点保证1≤n≤10^3。
【提示】
本题中所涉及的坐标皆为整数,且保证输入的坐标两两不同。
#include <bits/stdc++.h>
using namespace std;
struct Trash{
int x;
int y;
int isstation; //是否可作为回收站
int score; //回收站分数
};
int main()
{
int n;
cin>>n;
Trash t[n];
int i,j;
for(i=0;i<n;i++)
{
cin>>t[i].x>>t[i].y;
t[i].isstation=0;
t[i].score=0;
}
int count;
for(i=0;i<n;i++)
{
count=0;
for(j=0;j<n;j++) //判断上下左右四个邻居位置是否存在垃圾
{
if(t[j].x==t[i].x+1 && t[j].y==t[i].y)
count++;
else if(t[j].x==t[i].x-1 && t[j].y==t[i].y)
count++;
else if(t[j].y==t[i].y+1 && t[j].x==t[i].x)
count++;
else if(t[j].y==t[i].y-1 && t[j].x==t[i].x)
count++;
}
if(count==4) //邻居位置全部存在垃圾,可作为回收站
{
t[i].isstation=1;
for(j=0;j<n;j++) //计算回收站得分
{
if(t[j].x==t[i].x+1 && t[j].y==t[i].y+1)
t[i].score++;
else if(t[j].x==t[i].x+1 && t[j].y==t[i].y-1)
t[i].score++;
else if(t[j].x==t[i].x-1 && t[j].y==t[i].y+1)
t[i].score++;
else if(t[j].x==t[i].x-1 && t[j].y==t[i].y-1)
t[i].score++;
}
}
}
int score0=0,score1=0,score2=0,score3=0,score4=0;
for(i=0;i<n;i++)
{
if(t[i].isstation==1)
{
if(t[i].score==0)
score0++;
else if(t[i].score==1)
score1++;
else if(t[i].score==2)
score2++;
else if(t[i].score==3)
score3++;
else if(t[i].score==4)
score4++;
}
}
cout<<score0<<endl<<score1<<endl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









