






数据采集API接口可以实现搜索及商品详情数据的大批量稳定采集
提出问题

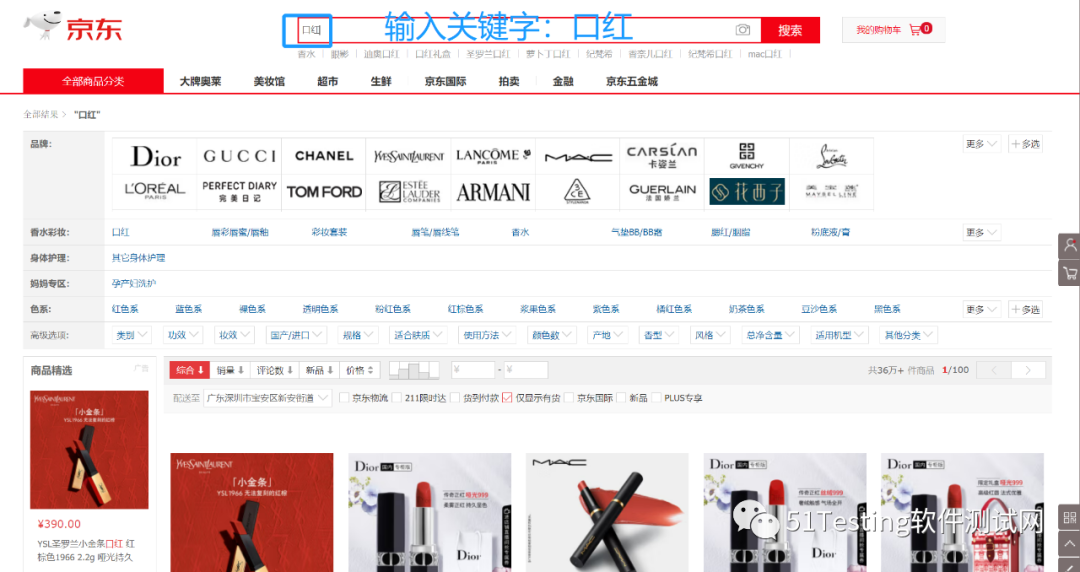
如何在京东商城爬取出各个商品的相关信息(价格、名称、评价、店铺名等等),比如,打开web京东网站,在搜索框输入关键字:口红。那么商品展示列表的所有商品的信息,怎么爬下来,怎么保存到表格中?


我们来看看怎么实现这个功能。
解决思路
1、打开网站,输入关键字,点击搜索按钮;
2、将右侧下拉框拉到最下面,保证获取到全部的数据;
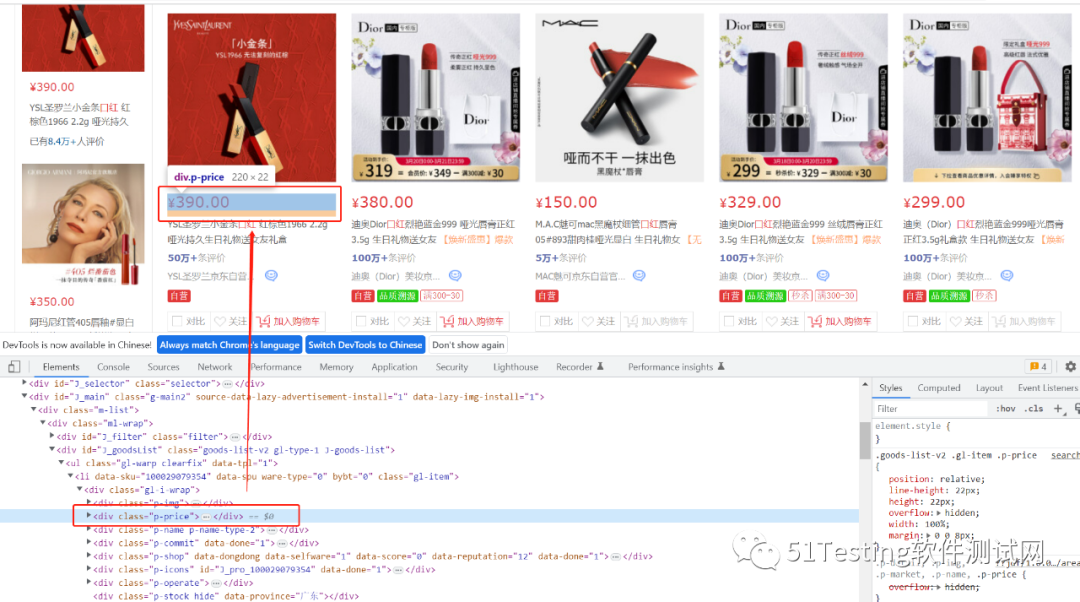
3、将每一个商品进行遍历,把每个item中的价格、名称、店铺、评价数量全部获取到;
4、将获取的信息,装在表格中。
import timeimport pandas as pdfrom selenium import webdriverimport requestsfrom selenium.webdriver import Keysfrom selenium.webdriver.common.by import Byif __name__ == '__main__':search_word = input("请输入你要搜索的商品:")page_size = int(input("请输入你要爬取的页数:"))prices, names, commits, shops = [], [], [], []# 打开浏览器driver = webdriver.Chrome()driver.get("https://www.jd.com")time.sleep(1)# 将web网页窗口最大化driver.maximize_window()# 找到搜索框input_box = driver.find_element(By.ID, "key")# 将搜索的字输入到京东搜索框中input_box.send_keys(search_word)# 按下enter键input_box.send_keys(Keys.ENTER)# range(page_size)for i in range(page_size):# 将下拉框拖到最下面:driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')time.sleep(3) # 确保在向下拖动的过程中,数据全部加载出来,加几秒等待# 获取所有的ligood_lists = driver.find_elements(By.XPATH, '//*[@id="J_goodsList"]/ul/li')for item in good_lists:# 找到产品的价格price = item.find_element(By.CLASS_NAME, "p-price").text# 找到商品的名字name = item.find_element(By.CLASS_NAME, "p-name").text# 找到商品的评论commit = item.find_element(By.CLASS_NAME, "p-commit").text# 找到商品的店铺shop = item.find_element(By.CLASS_NAME, "p-shop").text# 将每一次爬到的数据信息,追加到列表[ ]中prices.append(price)names.append(name)commits.append(commit)shops.append(shop)# 点击下一页driver.find_element(By.CLASS_NAME, "pn-next").click()df = pd.DataFrame({"价格": prices,"名称": names,"评论": commits,"商家": shops})# 将数据保存到excel表格中df.to_excel("{}.xlsx".format(search_word))
(左右滑动查看完整代码)
以上就是一个比较基础的爬虫Demo,通过selenium来实现,爬取的数据的业务逻辑较为简单,最后生成放在表格中就可以了。















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









