







 本文介绍了如何使用Python的selenium库配合京东商品API抓取动态加载的洗面奶商品信息,包括名称、价格、URL等,并处理了动态加载页面中的数据问题。后续还展示了如何进一步抓取商品的评论数据,以完成全面的商品数据分析。
本文介绍了如何使用Python的selenium库配合京东商品API抓取动态加载的洗面奶商品信息,包括名称、价格、URL等,并处理了动态加载页面中的数据问题。后续还展示了如何进一步抓取商品的评论数据,以完成全面的商品数据分析。
项目背景
需要获取京东的某一领域的商品信息数据,为后续项目推进做准备
实现思路
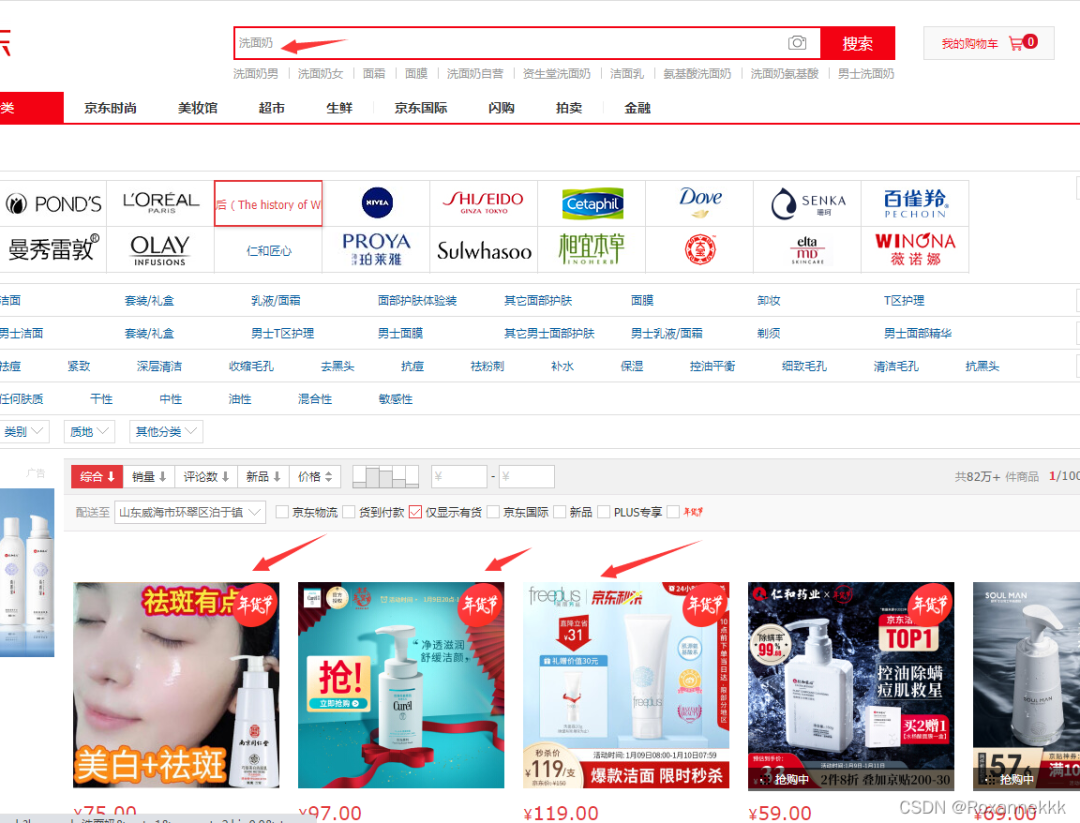
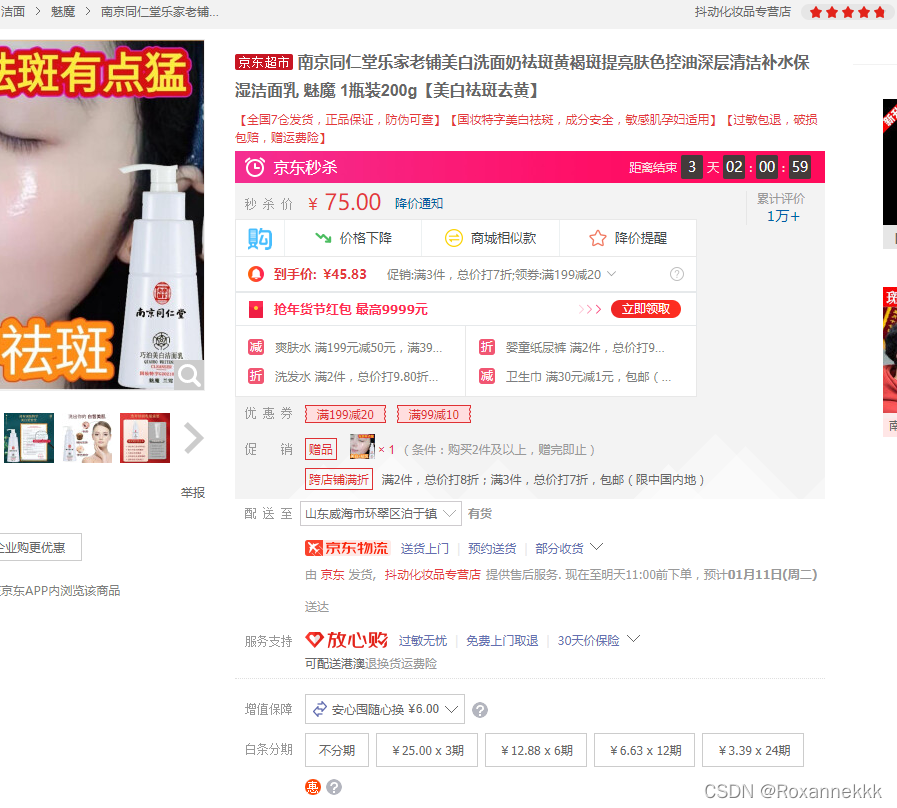
京东商品API数据采集接口可以实现大批量稳定数据采集。去获取每一个商品的数据首先需要去利用京东的搜索,利用关键字得到相关商品信息,由搜索结果去进行信息获取;这里以洗面奶商品举例:
具体实现
在搜索页面,我们关注的信息是每个商品的商品名称,商品价格,商品uid,商品备注,以及商品网址
的独特之处。
很多人学习蟒蛇,不知道从何学起。
很多人学习寻找python,掌握了基本语法之后,不知道在哪里案

需要获取京东的某一领域的商品信息数据,为后续项目推进做准备
京东商品API数据采集接口可以实现大批量稳定数据采集。去获取每一个商品的数据首先需要去利用京东的搜索,利用关键字得到相关商品信息,由搜索结果去进行信息获取;这里以洗面奶商品举例:
在搜索页面,我们关注的信息是每个商品的商品名称,商品价格,商品uid,商品备注,以及商品网址
的独特之处。
很多人学习蟒蛇,不知道从何学起。
很多人学习寻找python,掌握了基本语法之后,不知道在哪里案
 6589
4694
4209
6589
4694
4209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























