






电商数据采集的方法有哪些呢?我给大家分享一下我使用爬虫的个人经验,我们在采集类似电商数据网站的时候会遇到什么技术问题,然后再根据这些问题给大家分享采集方案。
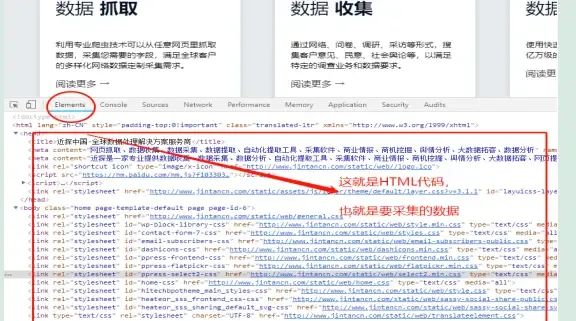
我们平时说的采集网站数据、数据抓取等,其实不是真正的采集数据,在我们的职业里这个最多算是正则表达式,网页源代码解析而已,谈不上爬虫采集技术难度,因为这种抓取主要是采集浏览器打开可以看到的数据,这个数据叫做html页面数据。
比如您打开:www.baidu.com这个网址,然后键盘按F12 ,可以直接看到这个网址的所有数据和源代码,这个网站主要是提供一些爬虫技术服务和定制,里面有些免费新工商数据,如果需要采集它数据,你可以写个正则匹配规则html标签,进行截取我们需要的字段信息即可。
京东获得JD商品详情 API 返回值说明
item_get-获得JD商品详情 API 注册开通
jd.item_get
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=10335871600
参数说明:num_iid:JD商品ID
响应参数
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| item | item[] | 0 | 获得JD商品详情 |

下面给大家总结一下采集类似这种工商、天眼、商标、专利、亚马逊、淘宝、app等普遍网站常用的几个方法,掌握这些访问几乎解决了90%的数据采集问题了。
「方法一:用python的request方法」
用python的request方法,直接原生态代码,python感觉是为了爬虫和大数据而生的,我平时做的网络分布式爬虫、图像识别、AI模型都是用python,因为python有很多现存的库直接可以调用,比如您需要做个简单爬虫,比如我想采集百度 几行代码就可以搞定了,核心代码如下:
import requests #引用reques库
response=request.get(‘https://www.tianyancha.com/’)#用get模拟请求
print(response.text) #已经采集出来了,也许您会觉好神奇!
「方法二、用selenium模拟浏览器」
selenium是一个专门采集反爬很厉害的网站经常使用的工具,它主要是可以模拟浏览器去打开访问您需要采集的目标网站了,比如您需要采集天眼查或者企查查或者是淘宝、58、京东等各种商业的网站,那么这种网站服务端做了反爬技术了,如果您还是用python的request.get方法就容易被识别,被封IP。
这个时候如果您对数据采集速度要求不太高,比如您一天只是采集几万条数据而已,那么这个工具是非常适合的。我当时在处理商标网时候也是用selenum,后面改用JS逆向了,如果您需要采集几百万几千万怎么办呢?下面的方法就可以用上了。
「方法三、用scrapy进行分布式高速采集」
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。scrapy 特点是异步高效分布式爬虫架构,可以开多进程 多线程池进行批量分布式采集。
比如您想采集1000万的数据,您就可以多设置几个结点和线程。
Scrapy也有缺点的,它基于 twisted 框架,运行中的 exception 是不会干掉 reactor(反应器),并且异步框架出错后 是不会停掉其他任务的,数据出错后难以察觉。我2019年在做企业知识图谱建立的时候就是用这个框架,因为要完成1.8亿的全量工商企业数据采集和建立关系,维度比天眼还要多,主要是时候更新要求比天眼快。















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









