






前言
本人是一名材料行业转行的三流程序员,在学习机器学习过程中遇到了很多问题,很多比较简单的博客都是看了很久才能弄懂,为了加深自己的理解,于是就把自己学习之后的一些理解记了下来。本文主要参考了文刀煮月的这篇博客https://www.cnblogs.com/liuqing910/p/9121736.html,把自己当时看的时候不太容易理解的地方加以了自己的说明,希望能够方便想要学习决策树的跟我一样的小白们,如有误,欢迎指出。
什么是决策树?
顾名思义,就是构建一棵能够帮助我们做出决策的树形结构
什么是树形结构?
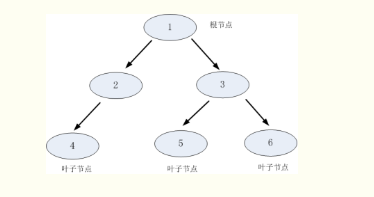
如上图所示,树形结构包含:根节点,父节点,子节点和叶子节点。根节点没有父节点,也就是初始的节点。父节点和子节点是一组相对概念,以图中为例,1是根节点同时又是2,3的父节点,2,3是1的子节点,同时2又是4的父节点,3是5,6的父节点,4是2的子节点,5,6是3的子节点,如果该节点不再向下进行延伸,那么这个节点就是叶子节点,图中的4,5,6就是叶子节点。
怎么通过树形结构来做出决策判断呢?
步骤1:将所有地数据视为一个节点(根节点),进入步骤2
步骤2:根据划分准则从该节点中选择出一个属性也就是一个特征,来对该节点进行划分,生产多个子节点,选择的划分属性中每一类值对应一个节点,(例如选择性别作为划分属性,性别分男女,那么就产生男,女两个子节点)进入步骤3
步骤3:对步骤2生成的n个子节点逐一进行判断,如果子节点满足停止分裂的条件,那么从根节点-子节点这条路线就进入步骤4,否则,回到步骤2
步骤4:设置该节点为叶子节点,它的输出就是该节点中数量占比最大的类别
停止分裂的条件是什么呢?
1.当前节点包含的样本全属于同一类别,无需划分
2.当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
3.当前结点包含的样本集合为空,不能划分
有哪些划分准则呢?(重点)
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的"纯度"越来越高。
A.信息增益
要了解信息增益,首先需要了解信息熵的概念
信息熵:假设样本集合D中第k类样本所占的比例为
ρ
k
(
k
=
1
,
2...
∣
y
∣
)
ρ_{k}^{(k=1,2...|y|)}
ρk(k=1,2...∣y∣),则样本D的信息熵为:
E
n
t
(
D
)
=
−
∑
k
=
1
∣
y
∣
ρ
k
l
o
g
ρ
k
Ent(D)=-\sum_{k=1}^{|y|}ρ_{k}logρ_{k}
Ent(D)=−k=1∑∣y∣ρklogρk
Ent(D)越小,则样本D的纯度越高
举个简单的例子,样本集合D表示一个班的学生手机品牌统计数据,其中有6个iphone,10个华为,4个小米,有三类手机品牌那么y=3,
ρ
i
p
h
o
n
e
=
6
20
=
0.3
ρ_{iphone}=\frac{6}{20}=0.3
ρiphone=206=0.3,
ρ
华
为
=
10
20
=
0.5
ρ_{华为}=\frac{10}{20}=0.5
ρ华为=2010=0.5,
ρ
小
米
=
4
20
=
0.2
ρ_{小米}=\frac{4}{20}=0.2
ρ小米=204=0.2,那么:
E
n
t
(
D
)
=
−
(
0.3
×
l
o
g
0.3
+
0.5
×
l
o
g
0.5
+
0.2
×
l
o
g
0.2
)
≈
0.447
Ent(D)=-(0.3\times log0.3+0.5\times log0.5+0.2\times log0.2)\approx0.447
Ent(D)=−(0.3×log0.3+0.5×log0.5+0.2×log0.2)≈0.447
注:
1.约定ρ=0时,ρlogρ=0
ρ=0按照上面的例子就是说我们在统计的时候其实还统计了锤子手机的使用人数,那么y=4,不幸的是锤子手机使用的人数为0
2.当D只含有一类时(纯度最高),此时Ent(D)=0(最小值)
只含有一类,那么
ρ
k
=
1
ρ_k=1
ρk=1,log1=0,故Ent(D)=0
3.当D中所有类所占比例相同(纯度最低),此时Ent(D)=log|y|(最大值)
为什么D中所有类所占比例相同时Ent(D)=log|y|呢?为什么Ent(D)的最大值是log|y|呢?
这篇博客里面有比较详细的证明过程,感兴趣的朋友可以去看一下:https://blog.csdn.net/feixi7358/article/details/83861858
信息增益:假设离散属性a有V个不同的取值,若使用a来对样本集D进行划分,则会产生V个分支节点,每个分支节点上的样本在a上的取值都相同,记第V个分支节点上样本为
D
v
D^v
Dv,则可计算
D
v
D^v
Dv的信息熵,然后再根据每个节点上的样本占比给分支节点赋予权重
∣
D
v
∣
/
∣
D
∣
|D^v|/|D|
∣Dv∣/∣D∣,可以计算出以属性a作为划分属性,所获得的”信息增益“为:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\frac{|D^v|}{|D|}Ent(D^v)
Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
举个简单例子,样本集合D有两个离散属性,手机品牌,性别,统计了10个顾客是否会购买健身卡,数据如下表:

首先计算在不进行划分时,样本集合D的信息熵:
ρ
买
=
0.6
ρ_买=0.6
ρ买=0.6,
ρ
不
买
=
0.4
ρ_{不买}=0.4
ρ不买=0.4
E
n
t
(
D
)
=
−
(
0.6
×
l
o
g
0.6
+
0.4
×
l
o
g
0.4
)
≈
0.292
Ent(D)=-(0.6\times log0.6+0.4\times log0.4)\approx0.292
Ent(D)=−(0.6×log0.6+0.4×log0.4)≈0.292
然后我们选择离散属性性别对样本集合D进行划分:
E
n
t
(
D
~
男
)
=
−
(
3
6
l
o
g
3
6
+
3
6
l
o
g
3
6
)
=
0.301
Ent(\tilde{D}^{男})=-(\frac{3}{6}log\frac{3}{6}+\frac{3}{6}log\frac{3}{6})=0.301
Ent(D~男)=−(63log63+63log63)=0.301
E
n
t
(
D
~
女
)
=
−
(
3
4
l
o
g
3
4
+
1
4
l
o
g
1
4
)
=
0.244
Ent(\tilde{D}^{女})=-(\frac{3}{4}log\frac{3}{4}+\frac{1}{4}log\frac{1}{4})=0.244
Ent(D~女)=−(43log43+41log41)=0.244
G a i n ( D , 性 别 ) = E n t ( D ) − 6 10 E n t ( D 男 ) − 4 10 E n t ( D 女 ) = 0.0138 Gain(D,性别)=Ent(D)-\frac{6}{10}Ent(D^男)-\frac{4}{10}Ent(D^女)=0.0138 Gain(D,性别)=Ent(D)−106Ent(D男)−104Ent(D女)=0.0138
然后我们选择离散属性手机品牌对样本集合D进行划分:
E
n
t
(
D
~
华
为
)
=
−
(
2
5
l
o
g
2
5
+
3
5
l
o
g
3
5
)
=
0.292
Ent(\tilde{D}^{华为})=-(\frac{2}{5}log\frac{2}{5}+\frac{3}{5}log\frac{3}{5})=0.292
Ent(D~华为)=−(52log52+53log53)=0.292
E
n
t
(
D
~
i
p
h
o
n
e
)
=
−
(
2
5
l
o
g
2
5
+
3
5
l
o
g
3
5
)
=
0.292
Ent(\tilde{D}^{iphone})=-(\frac{2}{5}log\frac{2}{5}+\frac{3}{5}log\frac{3}{5})=0.292
Ent(D~iphone)=−(52log52+53log53)=0.292
G a i n ( D , 手 机 ) = E n t ( D ) − 5 10 E n t ( D 男 ) − 5 10 E n t ( D 女 ) = 0 Gain(D,手机)=Ent(D)-\frac{5}{10}Ent(D^男)-\frac{5}{10}Ent(D^女)=0 Gain(D,手机)=Ent(D)−105Ent(D男)−105Ent(D女)=0
通过计算信息增益我们可以得知, G a i n ( D , 性 别 ) Gain(D,性别) Gain(D,性别) > G a i n ( D , 手 机 ) Gain(D,手机) Gain(D,手机),因此选择性别作为我们的划分属性。
注:著名的ID3决策树算法就是使用的信息增益为准则来选择划分属性
B.增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,可以试想,选择一个唯一对应一个样本的属性进行分类,每一类都是最纯的,对应的信息增益也是最大的,然而这样的划分无疑是不具备泛化能力的。
怎么理解这一句话呢?
还是用简单例子,假设样本集合D中有5个学生,5个学生都是用不同品牌的手机,每个手机品牌的ρ=1/5,根据上面介绍地这种情况下的Ent(D)最大,也就是纯度最低,那么我们根据手机品牌划分可以划分出5个子节点,每个节点上都只含有一个类别的数据,根据上面介绍只含有一类时,纯度最高,Ent(D)=0,那么我们算出来地信息增益是最大-最小,当然这个信息增益也是最大地,所以说信息增益准则对于可取数值较多的属性具有偏好
因此著名的C4.5决策树算法不直接使用信息增益,而是使用增益率来选择最优划分属性:
G
a
i
n
R
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
GainRatio(D,a)=\frac{Gain(D,a)}{IV(a)}
GainRatio(D,a)=IV(a)Gain(D,a)
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
l
o
g
∣
D
v
∣
∣
D
∣
IV(a)=-\sum_{v=1}^{V}\frac{|D^v|}{|D|}log\frac{|D^v|}{|D|}
IV(a)=−v=1∑V∣D∣∣Dv∣log∣D∣∣Dv∣
其中,IV(a)称为a的“固有值”,a的可能取值数目越多,IV(a)的值通常越大。分母越大,得到的GainRatio越小,故增益率准则对可取值数目较少的属性有所偏好
因此, C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C.基尼指数
CART决策树使用“基尼指数”来选择划分属性:
G
i
n
i
(
D
)
=
∑
k
=
1
∣
y
∣
∑
k
‘
≠
k
ρ
k
ρ
k
‘
=
1
−
∑
k
=
1
∣
y
∣
ρ
k
2
Gini(D)=\sum_{k=1}^{|y|}\sum_{{k^`}\ne{k}}ρ_kρ_{k^`}=1-\sum_{k=1}^{|y|}ρ_k^2
Gini(D)=k=1∑∣y∣k‘=k∑ρkρk‘=1−k=1∑∣y∣ρk2
Gini反映的是从数据集D中随机抽取两个样本,这两个样本类别不一样的概率,因此Gini越小,说明D的纯度越高
属性a的Gini指数定义为:
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
V
∣
∣
D
∣
G
i
n
i
(
D
V
)
Gini\_index(D,a)=\sum_{v=1}^V\frac{|D^{V}|}{|D|}Gini(D^V)
Gini_index(D,a)=v=1∑V∣D∣∣DV∣Gini(DV)
选择使上式最小的属性a作为划分属性
决策树剪枝处理
剪枝是决策树学习算法对付"过拟合"的主要手段。
过拟合原因:
1)噪声导致的过拟合:拟合了被误标记的样例,导致误分类。
2)缺乏代表性样本导致的过拟合:缺乏代表性样本的少量训练集作出的决策会出现过拟合。简单点说就是样本少,不具有代表性。
3)多重比较造成的过拟合:属性过多,模型复杂。
多重比较与过拟合之间有什么关系?
举一个简单的例子,我们把每一个属性比作成一个股票分析师,50个属性代表50个不同的分析师,股票分析师预测股票涨或跌。假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为 0.0547,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为 0.9399,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的
预防过拟合的策略有哪些?
预剪枝:是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
后剪枝:则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
如何判断决策树泛化性能是否提升呢?
留出法:即预留一部分数据用作"验证集"以进行性能评估。
例如:在预剪枝中,对于每一个分裂节点,对比分裂前后决策树在验证集上的预测精度,从而决定是否分裂该节点。而在后剪枝中,考察非叶节点,对比剪枝前后决策树在验证集上的预测精度,从而决定是否对其剪枝。
两种方法对比:
1)预剪枝使得决策树的很多分支都没有"展开”,不仅降低过拟合风险,而且显著减少训练/测试时间开销;但,有些分支的当前划分虽不能提升泛化性能,但在其基础上进行的后续划分却有可能导致性能显著提高,即预剪枝基于"贪心"本质禁止这些分支展开,给预剪枝决策树带来了欠拟含的风险。
2)后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树,但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
如何处理连续值属性?
以上都是基于离散属性进行讨论,而连续属性的可取值数目不再有限, 因此,不能直接根据连续属性的可取值来对节点进行划分。此时需要进行连续属性离散化,常见的离散化策略是二分法,C4.5决策树就是采用的二分法。
如何采用二分法对于连续值属性离散化呢?

不知道上面的公式大家有没有理解,通俗来说就是分为以下几个步骤:
1)首先对于连续值属性a进行升序排序,例如{0.243,0.245,0.343,0.360,0.403…}
2)计算排序后相邻两个值地平均值,例如1中相邻两个值地平均值{0.244,0.249,0.351,0.381,0.420…}
3)然后将2中的每一个值都作为划分节点将连续值属性a进行划分,小于所选平均值的为一类,大于所选平均值的为另一类,然后就可以按照计算离散属性信息增益的方法来计算了
4)将所有的平均值均代入公式计算后,选择出信息增益最大的一个平均值作为最终的划分节点
如何处理缺失值呢?
在我们拿到的数据中,往往会存在着缺失值,这种情况下应该怎么处理呢?
如果我们的样本数据量足够大,而且缺失值又比较少的情况下,那么就直接把含有缺失属性的值通通去除掉,这样最简单粗暴,但在数据样本本身就不多,而且缺失值又特别多的情况下,这种方法就不可取了。
那么在我们需要保留缺失值并其进行处理时就要考虑两个问题:
1)如何在属性值缺失的情况下进行划分属性选择?
2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
解决方法:
问题1:给定训练集D和属性a,仅对D中在属性a上没有缺失值地样本子集
D
~
\tilde{D}
D~来判断属性a的优劣。假定我们给每一个样本x赋予一个权重w(x),(初始化为1),定义:
ρ
:
无
缺
失
样
本
占
训
练
集
D
的
比
例
ρ:无缺失样本占训练集D的比例
ρ:无缺失样本占训练集D的比例
ρ
k
~
:
表
示
无
缺
失
样
本
中
第
k
类
所
占
比
例
\tilde{ρ_k}:表示无缺失样本中第k类所占比例
ρk~:表示无缺失样本中第k类所占比例
r
v
~
:
表
示
无
缺
失
样
本
中
在
a
上
取
值
为
a
v
的
样
本
占
a
的
比
例
\tilde{r_v}:表示无缺失样本中在a上取值为a^v的样本占a的比例
rv~:表示无缺失样本中在a上取值为av的样本占a的比例

问题2:若样本x在a上的取值缺失,则将x同时划入所有子节点,且样本权值对应于属性值
a
v
a^v
av,调整为
r
v
~
⋅
w
(
x
)
\tilde{r_v}\cdot w(x)
rv~⋅w(x),即让同一个样本以不同概率划入不同的子节点中去。
可能不太好理解,以周志华老师《机器学习》书中的西瓜数据集为例:

以属性“色泽”为例,根节点包含全部17个样例,各样本初始权重为1,该属性上无缺失的样例子集包含编号为{2 ,3 ,4, 6 , 7, 8, 9 , 10, 11 , 12 , 14, 15, 16, 17}的14个样例,其信息熵为:

对应的属性取值为“青绿”,“乌黑”,“浅白”的样本子集的信息熵分别为:
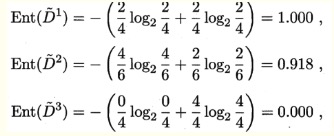
因此,非缺失样本子集的信息增益为:
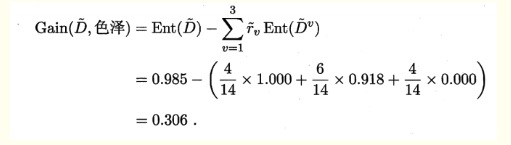
从而,计算得所有样本集的信息增益为:

类似地可计算出其他所有属性在D上的信息增益:

选择信息增益最大对应的属性“纹理”进行划分,划分结果为:
“清晰”分支:编号为{1 ,2 ,3 ,4, 5 ,6 ,15}的样本
“稍糊”分支:编号为{7 ,9, 13, 14, 17}的样本
“模糊”分支:编号为{11 ,12, 16}的样本
缺失样本:{8},同时进入三个分支中,权重分别调整为7/15,5/15和3/15;编号{10}类似。
泛化误差估计
再代入估计
再代入估计方法假设训练数据集可以很好地代表整体数据,因此,可以使用训练误差(再代入误差)提供对泛化误差的乐观估计。此情形下,决策树算法将简单地选择产生最低训练误差的模型作为最终的模型,尽管,使用训练误差通常是泛化误差的一种很差的估计。
使用验证集
此方法中,不使用训练集来估计泛化误差,而是把原始数据集分为训练集和验证集,验证集用于估计泛化误差。通常是通过对算法进行调参,直到算法产生的模型在验证集上达到最低的错误率。















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









