







本文目的:正值年报季节,各家上市公司逐渐披露年报数据,想通过分析年报部分数据窥探一下A股上市公司的情况。
数据来源:通过爬虫爬取财经网页所得。
文章框架:
1. 上市公司年报数据爬取
1.1 使用爬虫工具
本文使用selenium进行爬取数据,selenium使用起来比requests方便,原理是模拟人点击浏览器查看网页的过程,更具有灵活性,而且获取数据的方式也很便利。
2. 年报数据处理
2.1 数据格式转化
2.2 删除不必要符号
2.3 删除数据单位
2.4 空值填充
2.5 数据类型转化
3. 年报数据分析
3.1 A股上市公司净利润情况分析
3.2 A股上市公司营业收入情况分析
3.3 A股上市公司分红情况分析
4. 总结
由于2021年的年报数据只出了一部分,还有很多没有出来,所以用2020年的年报数据进行本文的分析,如果要分析2021年的情况可以同理所得。截止2020年A股上市公司数量为4697家。
-
上市公司年报数据爬取
爬取思路:先打开网页,接着定义两个函数,一个函数用来获取页面信息,并保存爬取到的数据,为下面的get_page()。另一个函数为主函数,用来进行页面的切换。当然,为了防止被网页识别出是爬虫所为,在抓取网页之前定义了一个反屏蔽的内容,避免被反爬。
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
url = '财经网页网址'
# 添加反屏蔽
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
web = webdriver.Chrome(options=option)
web.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source':'Object.defineProperty(navigator,"webdriver",{get:() => undefined})'})
time.sleep(2)
# 打开网页
web.get(url=url)
# 定位到沪深A股板块,点击
web.find_element(By.XPATH, 'XPATH地址').click()
time.sleep(3)
# 获取页面信息,并保存在TXT文档
def get_page():
divs = web.find_elements(By.XPATH, 'XPATH地址')
for div in divs:
# 将爬取的数据写入TXT文本
with open('年报2020.txt', mode="a") as f:
f.write(div.text)
f.write('\r\n')
def main():
"""
函数目的:抓取财经网页展示的公司年报数据
由于下一页的定位经常变换,所以使用输入页码并转到的方式进行页面的切换。
每次打开网页时转到的输入框会显示当前的页码,所以在输入页码之前需要先进行清除。
每一页有50家公司。
"""
# 定义需要爬取的页码
for i in range(13, 15):
print("正在抓取第{}页...".format(i))
try:
input = web.find_element(By.XPATH, 'XPATH地址')
input.clear() # 清除搜索框的内容
time.sleep(2)
input.send_keys("{}".format(i), Keys.ENTER) # 输入需要爬取的页码
time.sleep(4) # 这里必须设置缓冲时间,因为输入代码之后会刷新页面。如果还没刷新完就执行下一步就会错失这一步数据的抓取
web.find_element(By.XPATH, 'XPATH地址').click() # 点击Go
time.sleep(6) # 等待网页刷新
get_page() # 调用抓取页面信息的函数
print("第{}页抓取完毕".format(i))
except:
pass
# 爬完关闭网页
web.close()
main() # 调用主函数爬取完的数据保存在TXT文本当中,如下截图所示:

2. 年报数据清洗
对获取到的数据进行相应的处理,变成可以进行数据分析的格式,难度不大。其中有以下几点需要处理:
-
将数据由TXT存取转为CSV格式
-
删除掉不必要的换行符
-
删除数据单位,比如亿、万等
-
将空值用0填充
-
将数据由字符型转为浮点型
2.1 数据格式转化
2.2 删除不必要符号
下面步骤将数据格式转成CSV,并将不必要的符号删除:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.DataFrame()
data_list = []
for line in open('年报2020.txt'):
a = line.split(' ')
if len(a) > 1:
b = pd.DataFrame(a)
data = pd.concat([data, b.T])
data.columns = ['序号', '股票代码', '股票简称', '相关', '每股收益', '营业总收入', '同比增长', '季度环比增长',
'净利润', '同比增长', '季度环比增长', '每股净资产', '净资产收益率', '每股经营现金流量',
'销售毛利率', '利润分配', '所处行业', '公告日期']
# 去除掉日期后面换行符\n
list_ = []
for ele in data['公告日期']:
list_.append(ele.split('\n')[0])
data.drop(columns=['公告日期'],inplace=True)
data['公告日期'] = list_
data.to_csv('年报.csv') # 保存处理后的数据2.3 删除数据单位
由于营业收入和净利润单位存在中文,有些是亿、有些是千万,先将这些数据统一转成以亿为单位的数值。
# 定义一个改变单位的函数
def change_unit(data):
a = '亿'
b = '万'
c = '万亿'
list_1 = []
for i in data:
if a in i and c not in i:
list_1.append(float(i.split('亿')[0])) # 注意需要转为数值型
elif b in i:
list_1.append(float(i.split('万')[0]) / 10000)
elif c in i:
list_1.append(float(i.split('万亿')[0]) * 10000)
else:
list_1.append(i)
return list_1
df['营业总收入'] = change_unit(data['营业总收入'])
df['净利润'] = change_unit(data['净利润'])2.4 空值填充
许多数据里面存在空值,其中空值的表现形式是“-”,所以将这些全部使用0来进行填充。
def change_data(data):
list_2 = []
for i in data:
if i == "-":
list_2.append(0)
else:
list_2.append(i)
return list_2
for i in range(2,15):
df.iloc[:,i] = change_data(df.iloc[:,i])
df.dtypes # 查看数据的类型处理完,查看数据类型,发现很多本来应该是数字的,但却是字符串类型,所以需要将这些类型转为浮点型(因为存在小数点)。
2.5 数据类型转化
df.iloc[:,2:13] = df.iloc[:,2:13].astype('float64')到此,数据清洗就算完成了,下面查看一下数据情况:
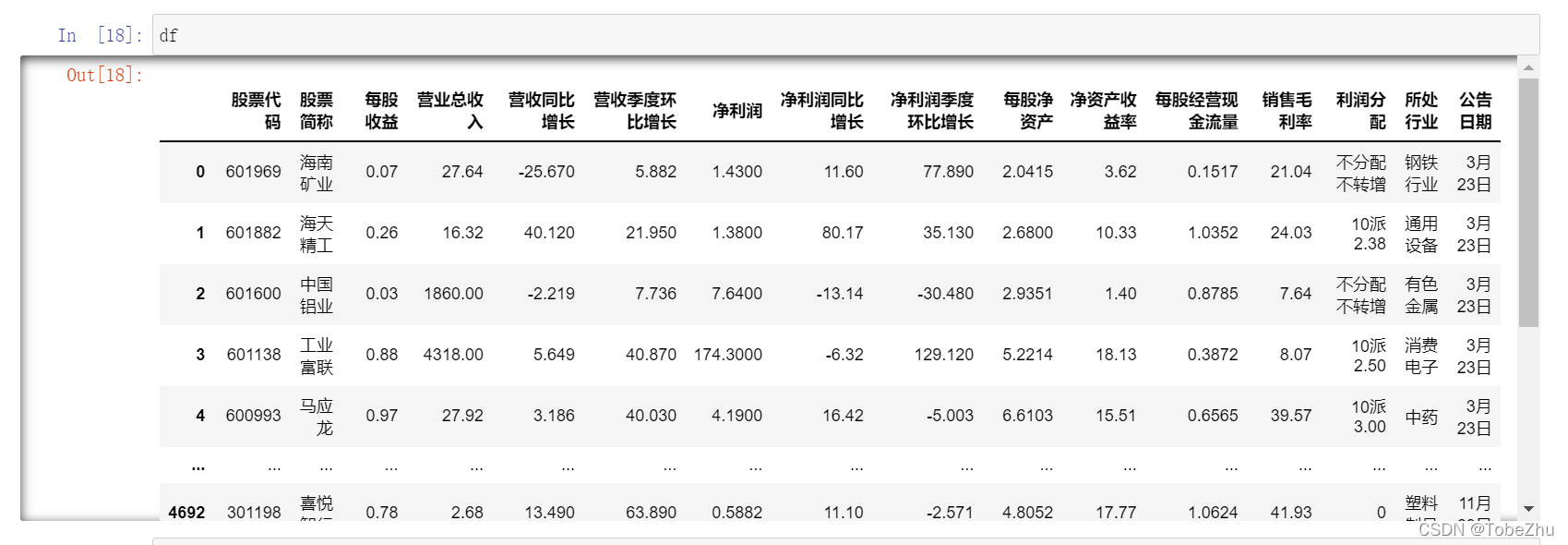
3. 年报数据分析
先查看一下整体数据的情况:
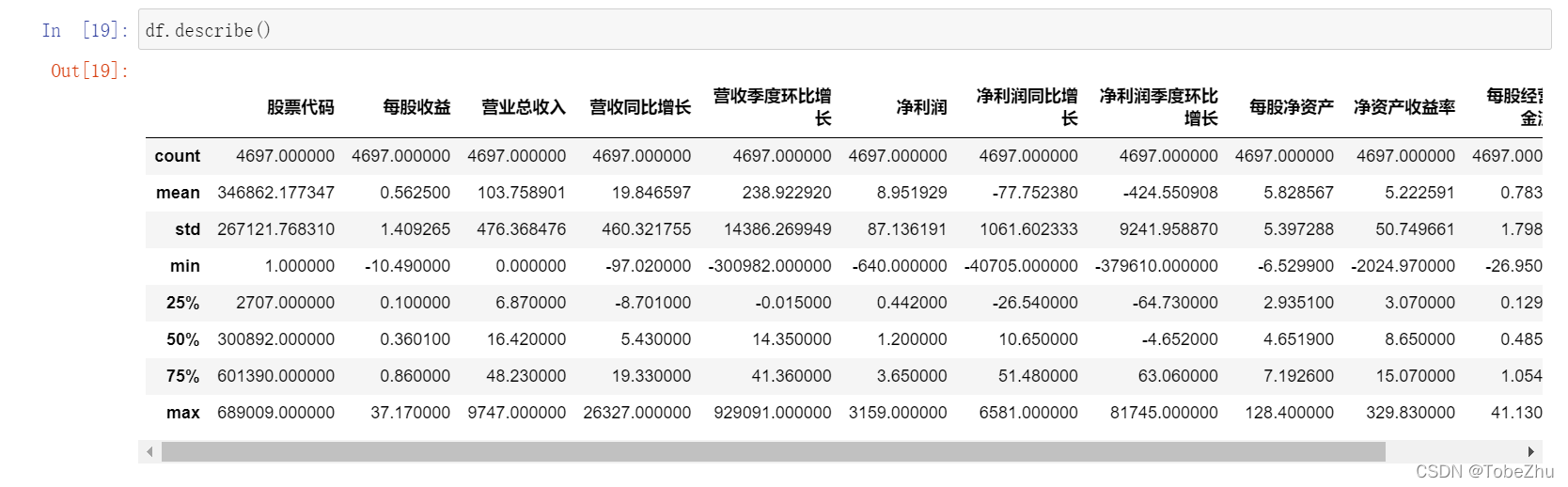
营业总收入平均值为103.758901亿,最大值和最小值分别为9747亿、0亿(0应该是没有数据,毕竟一家公司一年的营收不可能为零),上四分数为48.23亿,意味着有超过四分之三的公司营收低于(等于)48.23亿。净利润平均值是8.951929,最大值和最小值分别是3159亿、-640亿(很好奇哪家公司可以亏这么多?!),上四分位数为3.65亿元,意味有超过四分之三的公司净利润小于等于3.65亿元。
巨亏640亿的公司是海航,一年亏光了十年的利润。因为疫情影响,航空行业业绩大受打击,关于为什么亏损这么多的原因网上随便一搜很多讨论。
3.1 A股上市公司净利润情况分析
查看净利润前10的公司都有哪些:
df_profit_10 = df.sort_values(by='净利润',ascending=False)[0:10] 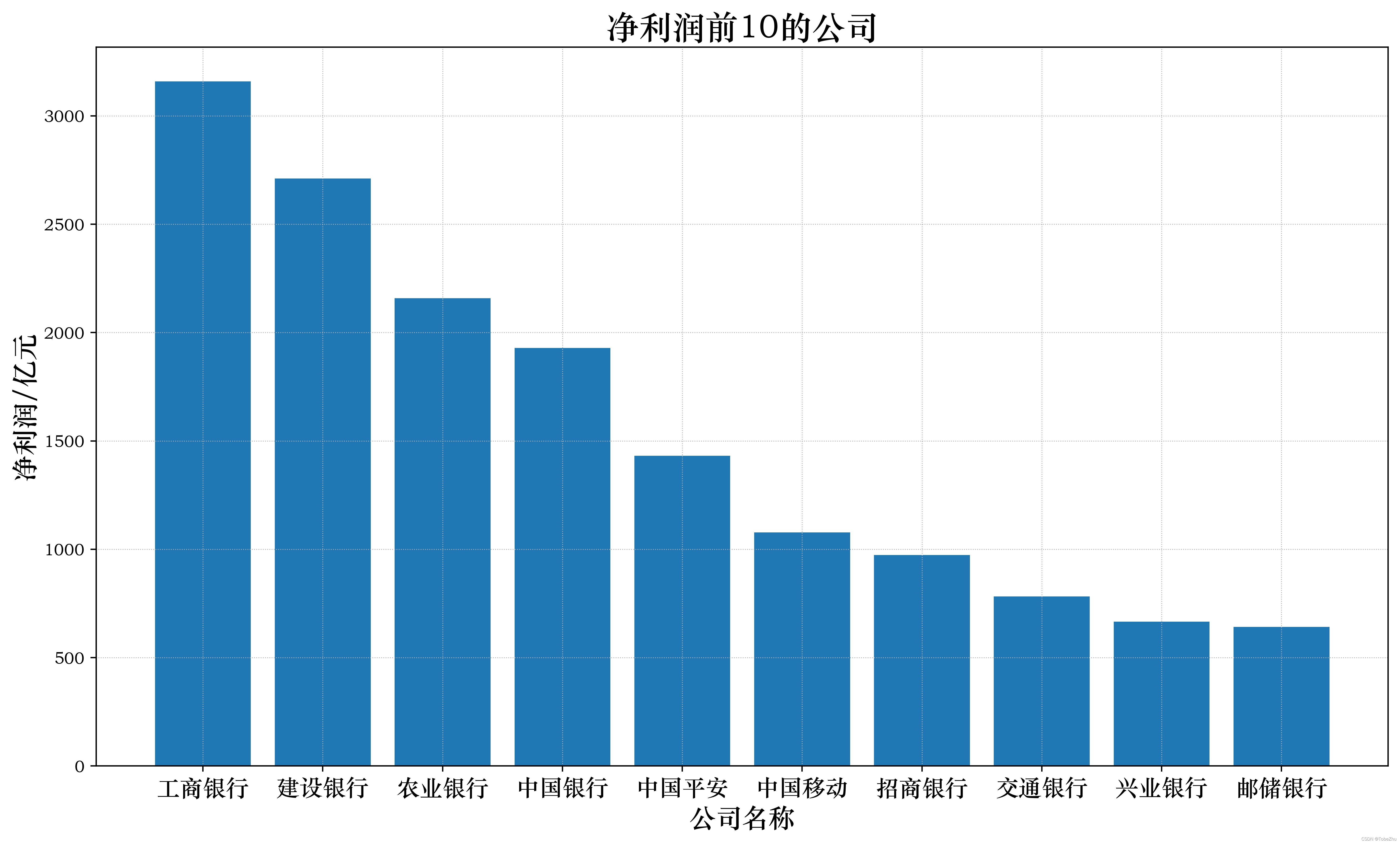
由上图可知,利润前10的公司银行占了8家(垄断的地位确实无可撼动),而且前四名清一色是银行,间接融资为主的金融体系,利润大头还是给银行赚走了。第五名是保险行业的中国平安,还是属于金融机构。应该说只有中国移动一家通信服务的公司挤进了利润前10的地位,排名第6。
下面看一下净利润方面的分布情况,查看净利润前10的公司利润总和占比全A股的利润比例以及利润低于平均值和高于平均值的占比情况。
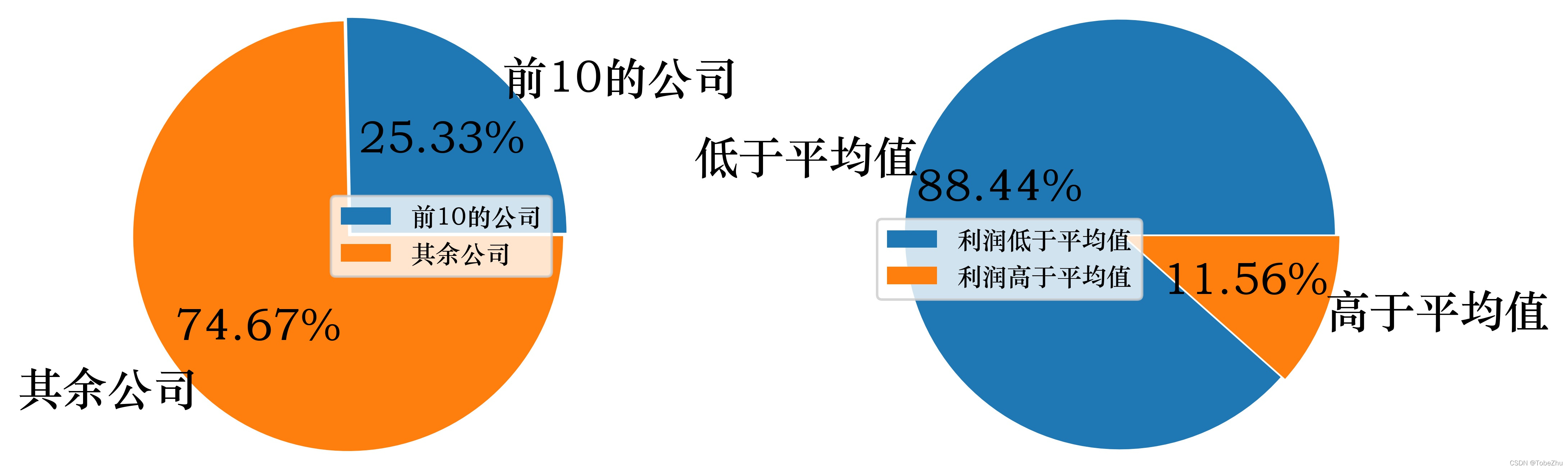
通过上图可以发现,总共有4697家公司,前10家公司(占比0.21%)的利润占比就超过了四分之一(达到了25.33%)。而且有接近九成(88.44%)的公司净利润是低于行业平均值的,这说明了行业利润的集中度是非常高的,即大部分的利润给小部分的公司赚走了。
下面再来看看净利润低于零的公司占比情况:
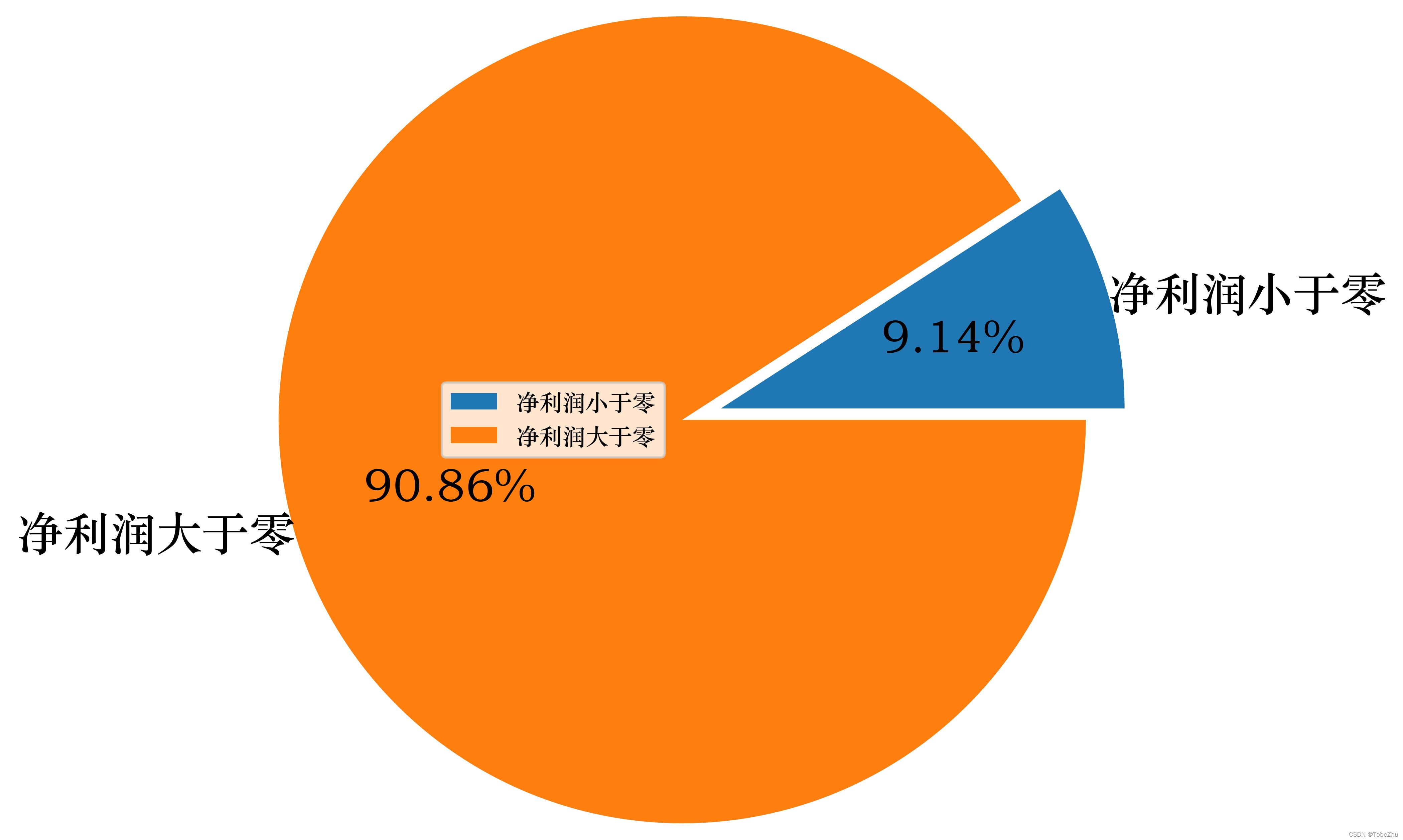
超过9%的公司净利润为负,上市公司一定程度上来说是优秀企业的代表,但优秀的企业辛辛苦苦干一年还是有不少公司净利润是负数。到底是疫情冲击的影响,还是正常现象(没有疫情的时候也存在这么多公司净利润为负)呢?
下面通过绘制词云图,查看净利润小于零的公司所处的行业情况:

词云图的数字大小代表出现的次数,越大表示出现的次数越多,反之亦然。由词云图可以发现,净利润小于零的行业主要集中在文化传媒、互联网服务、旅游酒店和化学制药等行业。对于旅游酒店,很明显是因为疫情的冲击导致的业绩下降。
3.2 A股上市公司营业收入情况分析
查看营收前10的公司:
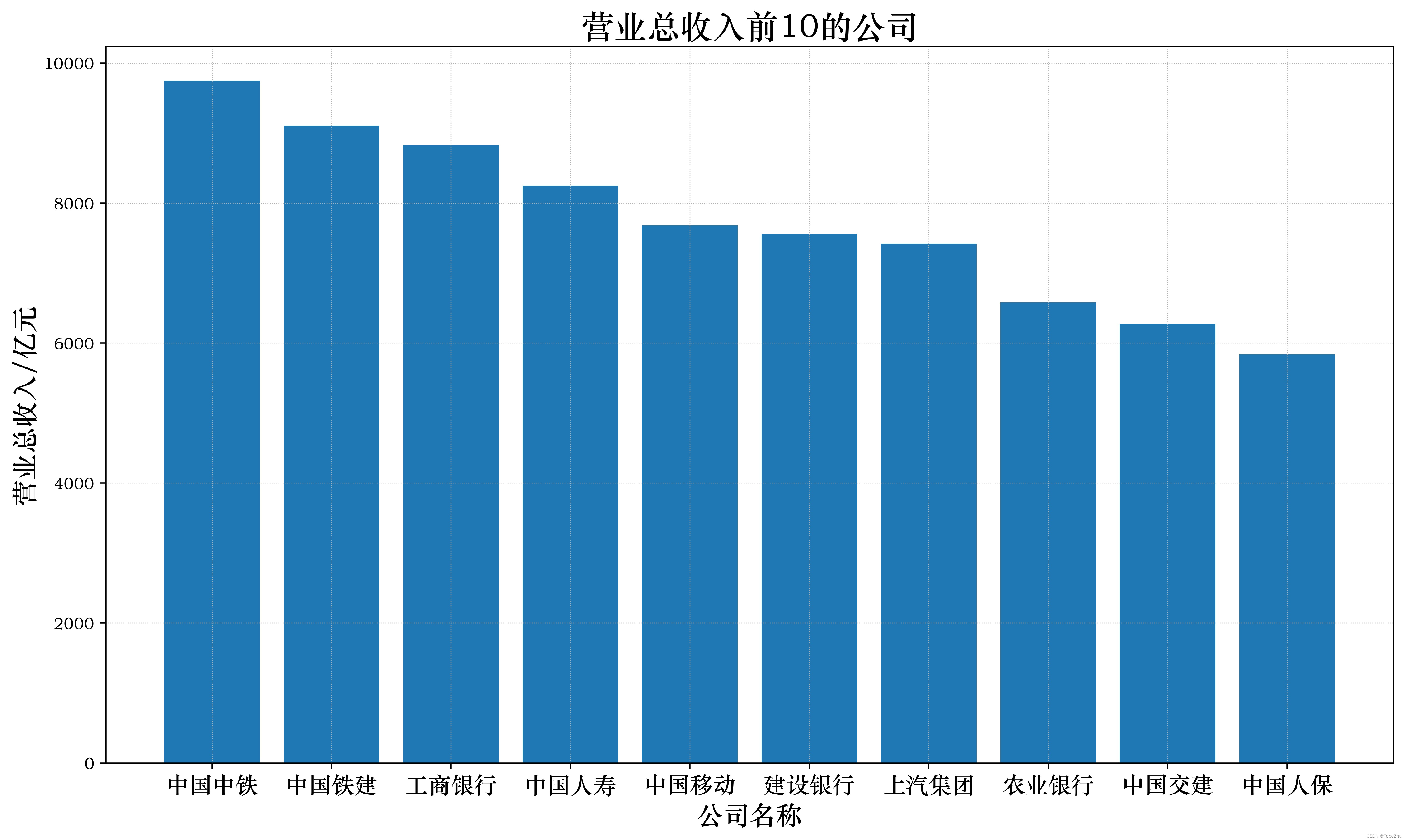
前10名除了银行之外,挤进了中字头的公司,分别是中国中铁和中国铁建,还有汽车行业的上汽集团。
下面查看下营收前10公司营收总额占比以及高于平均值和低于平均值的占比情况:

营业收入前10的公司营业收入总和占比达到了15.86%,营业收入高于平均值的公司却只占比13.75%,可以看得出营业收入的行业集中度也非常大,这说明很少的公司创造了更多的营业收入,而大部分的公司营业收入低于平均值(86.25%低于平均值)。
3.3 A股上市公司分红情况分析
下面统计有分红公司数量和没有分红公司数量占比情况以及相应所处的行业情况:
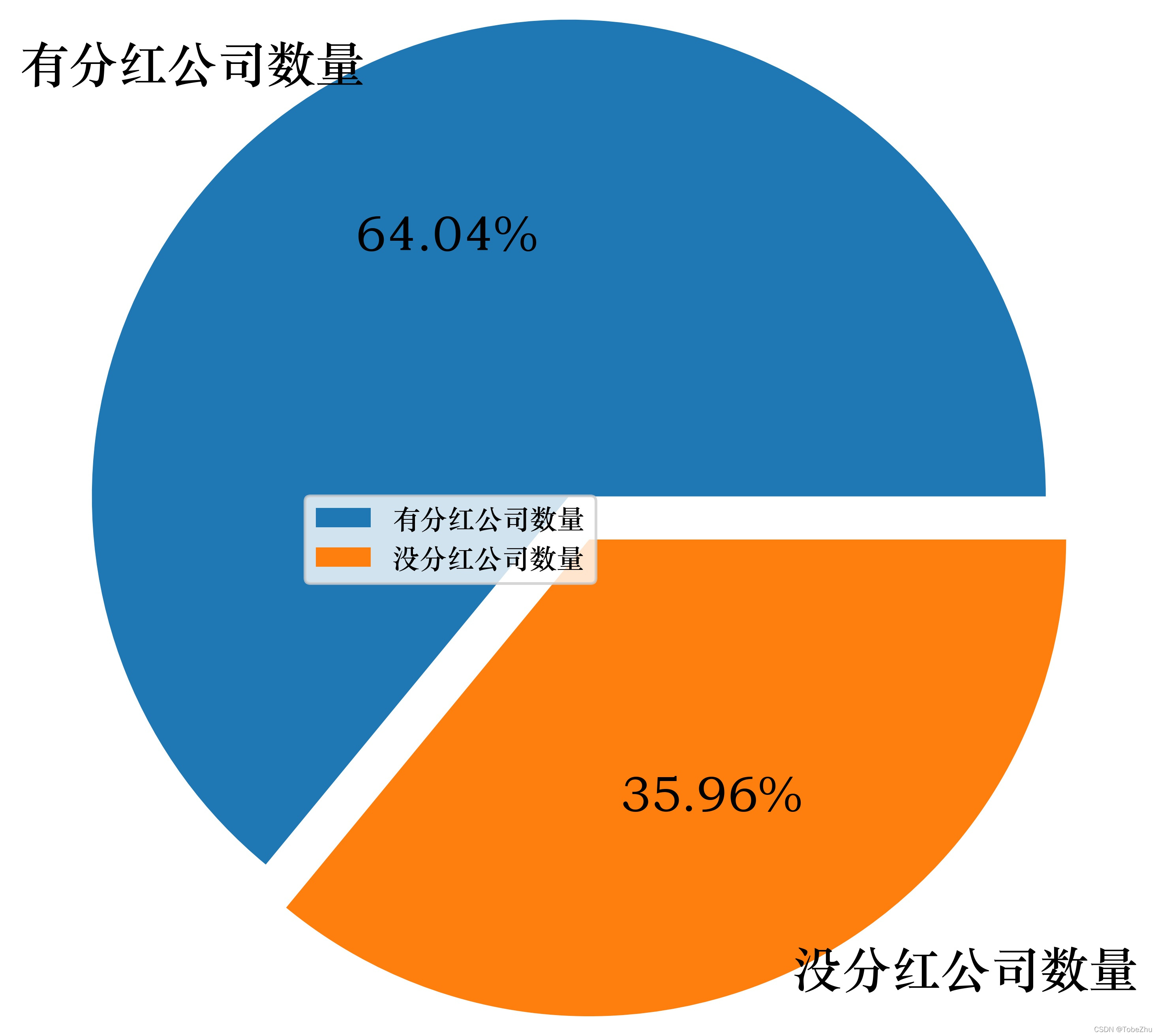
有分红公司数量超过了64%的比例,看来政策效果还是有好转的,但没有分红的公司数量确实也不少,占比接近36%(达到35.96%),也就是说瞎买一只股票的话,正常来说有超过三分之一的概率会买到没有分红的公司。企业有分红,一把情况说明公司经营是比较好的,如果没分红可能是经营不好,也可能是有更好的发展方向,拿去进一步的投资发展了,但是不是真的拿钱去发展了容易成为借口,实打实的有分红作为回报还是能够体现公司经营情况向好的。
下面通过绘制词云图查看分红公司和没有分红的所处行业情况:

(1)没有分红公司所处行业 (2)有分红公司所处行业
由上图可以看到,没有分红的公司所处行业主要有专用设备、汽车零部件、文化传媒、纺织服装和通用设备等。而有分红公司所处行业主要有专用设备、汽车零部件、通用设备、化学制品和软件开发。其中有三个行业存在重叠,即专用设备、汽车零部件和通用设备。
4. 总结
-
4697家上市公司营收最大值9747亿,平均值103.76亿,上四分数为48.23亿。
-
4697家上市公司净利润最大值3159亿,最小值-640亿,平均值8.95亿,上四分数为3.65亿。
-
净利润前10家公司利润总和占比25.33%,88.44%净利润低于平均值。
-
9.14%的公司净利润低于零。
-
营业收入前10家公司营收总和占比15.86%,86.25%净营收低于平均值。
-
超过三分之一(35.96%)的公司没有分红。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









