








提起唐诗宋词,想必所有人都不会陌生,这些内容陪伴了我们走过了那个曾经的青春岁月啊,最近接触到了一个关于唐诗宋词的分析挖掘问题,自己从不同的角度做了一些尝试,这里简单分享一些,能够做的还有很多,欢迎大家继续尝试。
我用到数据来自于这个项目,感谢作者的努力付出。

可以自行下载项目获取所需的数据集,我的数据集如下:
接下来简单看下对应的数据样例,首先看下唐诗的样例:
接下来是宋词的样例,如下所示:
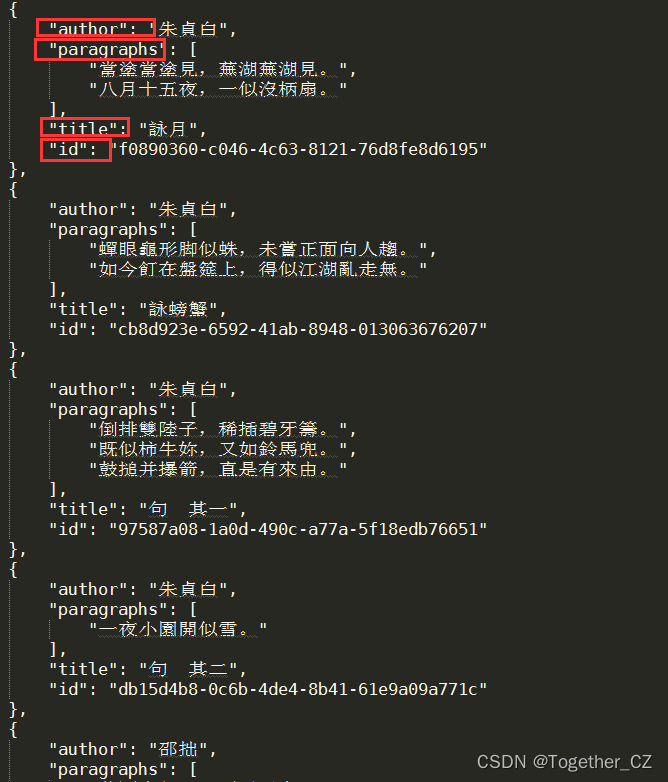
可以看到:对于每个最小粒度的数据字典里面都包含了四个字段,分别是:author、paragraphs、title和id,用于标识不同的内容,方便我们后续提取计算。
为了使用方面,我首先将不同类型的内容进行了相应的提取计算和合并,代码实现如下:
def mergeData(dataDir='json/',flag='tang'):
'''
拆分合并数据集
'''
if not os.path.exists(resDir):
os.makedirs(resDir)
data_list=[]
for one_json in os.listdir(dataDir):
if flag in one_json:
with open(dataDir+one_json,encoding='utf-8') as f:
one_data_list=json.load(f)
print(one_json, len(one_data_list))
for one_dict in one_data_list:
one_author=one_dict["author"]
one_content=str(one_dict["paragraphs"])
one_title=one_dict["title"]
one_con=''.join(re.findall(u'[\u4e00-\u9fff]+', one_content))
data_list.append([one_author,one_title,one_con])
print('data_list_length: ', len(data_list))
for one in data_list[:3]:
print(one)
with open(resDir+flag+'.json','w') as f:
f.write(json.dumps(data_list))接下来,我们对唐诗、宋词里面出现的高频字、词来进行分析计算,代码实现如下所示:
def charFrequency(data='tang.json'):
'''
字频分析
'''
with open(data) as f:
data_list=json.load(f)
char_dict={}
word_dict={}
for one_list in data_list:
one_con_list=list(one_list[-1])
for one_char in one_con_list:
if one_char in char_dict:
char_dict[one_char]+=1
else:
char_dict[one_char]=1
one_cut_list=seg(one_list[-1], [])
for one_word in one_cut_list:
if len(one_word)>=2:
if one_word in word_dict:
word_dict[one_word]+=1
else:
word_dict[one_word]=1
char_sorted=sorted(char_dict.items(),key=lambda e:e[1],reverse=True)
word_sorted=sorted(word_dict.items(),key=lambda e:e[1],reverse=True)
print("==========================Top 10 char==========================")
print(char_sorted[:10])
print("==========================Top 10 word==========================")
print(word_sorted[:10])
print(random.sample(word_sorted,40))
with open(data.split('.')[0]+'_char.json','w') as f:
f.write(json.dumps(char_dict))
with open(data.split('.')[0]+'_word.json','w') as f:
f.write(json.dumps(word_dict))为了更加直观地看到效果,这里对其进行了可视化,如下所示:




这些是将不同朝代作者们混在一起统计分析了,接下来我们按照作者的不同来分别进行分析,这里我只分析了不同朝代里面比较出名的人物,其他人物的分析方法和整体流程跟我这里是一模一样的,效果如下所示:





等等。。。。。
接下来基于字共现和词共现的方法来分析唐诗宋词里面的高频字对和高频词对,我采用的方法是穷举的方法,比较简单暴力,缺点就是对机器的内存要求比较高,粗略估计需要40GB左右。
这里简单看下,唐诗高频共现字对:
不_人,9555
不_無,7510
一_不,7109
人_無,6931
不_風,6604
不_山,6435
一_人,6400
不_有,6245
不_日,6232
人_山,6121
不_何,5964
不_來,5921
人_日,5827
人_風,5730
人_有,5610
有_無,5560
不_時,5554
不_中,5473
山_雲,5428
不_雲,5319
人_何,5310
不_天,5309
一_無,5236
不_知,5223
人_來,5172
日_風,5042
不_自,5034
上_不,5025
不_爲,5007
不_見,4984
山_風,4972
人_天,4909
中_人,4899
人_時,4898
上_人,4893
不_生,4865
一_風,4860
人_雲,4751
一_山,4749
山_日,4739
不_心,4738
不_相,4719
人_春,4712
山_無,4708
日_無,4682
山_水,4675
無_風,4650
不_如,4640
不_水,4598
不_月,4589
一_日,4561
不_花,4558
不_春,4506
雲_風,4475
月_風,4420
人_水,4414
人_爲,4406
不_長,4385
人_見,4353
不_得,4342
不_年,4333
一_有,4283
人_自,4279
不_此,4279
人_月,4277
中_風,4269
春_風,4255
春_花,4248
人_花,4243
人_生,4192
何_無,4171
一_來,4138
日_雲,4130
一_中,4126
來_無,4117
中_無,4110
時_無,4093
人_知,4072
人_此,4057
一_何,4048
中_山,4035
天_風,4022
不_君,4017
人_相,4003
一_天,3998
水_風,3988
山_有,3987
來_山,3985
一_雲,3979
天_日,3975
來_風,3965
不_白,3960
花_風,3936
天_雲,3916
山_月,3882
日_時,3876
天_山,3871
一_時,3864
天_無,3863
有_風,3861
唐诗高频词对:
不_爲,2048
有_爲,1770
在_爲,1651
爲_與,1524
無_爲,1521
我_爲,1372
爲_誰,1320
是_爲,1307
不_有,1287
不_在,1254
有_無,1204
不_無,1160
復_爲,1124
在_有,1124
人_爲,1117
不_與,1116
來_爲,1088
去_爲,1085
月_爲,1068
爲_見,1008
不_復,999
有_與,984
亦_爲,971
在_與,966
不_去,961
在_無,957
我_有,951
不_我,939
上_爲,921
從_爲,906
與_誰,895
我_與,884
在_月,883
不_誰,881
爲_閑,878
不_人,865
無_與,855
爲_長,852
中_爲,837
得_爲,827
不_來,824
有_誰,819
來_去,818
不_月,818
在_誰,806
一_爲,799
不_是,796
已_爲,784
復_無,780
時_爲,779
之_爲,777
來_有,773
去_在,767
我_無,764
是_有,763
在_是,752
復_有,751
月_有,750
來_在,748
去_歸,746
人_有,744
在_我,739
不_亦,736
在_復,728
去_有,724
中_有,721
在_閑,720
多_爲,715
不_閑,713
日_爲,707
人_在,706
中_在,698
是_無,698
上_不,693
在_長,690
爲_雲,689
不_長,687
不_從,684
人_無,684
於_爲,680
是_誰,680
時_有,679
無_誰,677
不_見,676
上_有,671
人_與,669
亦_有,668
更_爲,662
月_與,660
又_爲,660
如_爲,659
有_見,658
來_無,658
去_無,656
欲_爲,655
爲_黃,654
來_從,653
復_與,653
上_月,649
有_閑,647
宋词高频字对:
不_人,42132
一_不,39165
不_無,36217
不_有,33512
不_風,33117
一_人,32623
人_無,30939
不_山,30894
一_無,29668
有_無,29642
不_來,28801
一_風,28704
人_有,28653
不_何,27799
人_風,27344
一_山,26380
人_山,26266
不_天,26001
一_有,25992
不_自,25426
不_如,25290
不_知,24579
不_日,24138
無_風,23887
一_來,23737
不_生,23720
人_何,23435
人_來,23388
山_風,23380
一_天,22627
不_中,22533
不_時,22346
山_無,22206
人_天,22192
不_爲,21954
一_何,21918
有_風,21421
不_此,21194
不_年,20920
山_有,20853
不_得,20705
一_日,20593
不_我,20423
人_自,20394
來_風,20340
不_雲,20219
人_日,20216
來_無,20174
一_生,20065
日_風,20015
何_無,19773
人_如,19741
人_生,19703
來_山,19486
天_風,19370
何_有,19268
一_如,19227
天_無,19198
山_雲,19181
來_有,19111
一_自,19078
不_春,19065
一_中,19064
不_未,18990
春_風,18886
無_自,18788
不_相,18758
中_人,18747
不_可,18610
不_老,18474
日_無,18417
一_年,18407
人_知,18370
一_時,18308
人_時,18175
不_心,18033
不_月,17949
人_此,17825
人_春,17820
天_有,17776
人_爲,17768
不_見,17751
何_風,17651
一_雲,17582
不_水,17560
不_花,17419
無_生,17407
雲_風,17396
山_日,17369
不_今,17338
不_子,17327
有_自,17265
人_年,17262
月_風,17261
天_山,17226
如_無,17223
一_此,17218
不_清,17167
中_風,17072
人_我,17007
宋词高频词对:
不_爲,9312
我_爲,8624
有_爲,8256
爲_與,7544
不_有,7028
爲_誰,6935
我_有,6793
不_與,6755
不_我,6726
我_與,6540
無_爲,6321
有_無,6271
有_與,5985
與_誰,5657
亦_我,5375
不_無,5367
有_誰,5353
復_爲,5184
亦_爲,5176
在_爲,5166
不_復,5139
我_無,5093
來_爲,5078
我_誰,4979
不_誰,4961
無_與,4837
來_我,4764
不_在,4759
亦_有,4704
在_有,4506
不_亦,4385
復_我,4378
復_有,4320
不_來,4270
已_爲,4252
是_爲,4241
復_無,4230
來_有,4229
人_爲,4223
在_我,4146
得_爲,4028
從_爲,4022
爲_豈,4022
去_爲,4014
亦_與,3878
在_與,3868
復_與,3852
欲_爲,3841
我_欲,3816
之_爲,3767
來_與,3754
無_誰,3749
復_誰,3741
更_爲,3694
不_人,3649
從_我,3629
不_去,3602
月_爲,3581
已_我,3543
不_得,3489
更_有,3458
不_從,3443
人_有,3428
去_我,3413
來_從,3372
不_已,3371
在_誰,3370
不_豈,3362
得_我,3361
亦_無,3358
得_有,3357
如_爲,3357
來_無,3355
是_有,3347
從_有,3305
有_豈,3303
不_是,3260
在_無,3258
未_爲,3251
如_我,3234
人_與,3228
去_有,3225
我_豈,3209
亦_復,3206
已_有,3198
不_月,3177
人_我,3169
來_誰,3142
來_去,3140
月_有,3126
不_欲,3120
一_爲,3098
時_有,3066
之_我,3059
不_更,3057
時_爲,3043
我_是,3042
從_與,3035
得_與,3018
不_如,3003
看到这里:细心的可能就会问,为什么明明是高频词对但是结果却跟字对的形式是一模一样的呢?这主要就是分词的问题,会产生很多单字组成的词,两两组合之后就会出现单字词对的频度很高,不信的话自己实现以下,打印最后几个就知道了,说白了就是单个词的长度越大最终共现得到的频率就越低,因为“条件更加苛刻了”。

除了我上面实现的那些还有很多,可以分析的点,时间原因这里就不再继续展开讲解了,古人吟诗作词都会有很多特殊的象征,这里大家可以发挥想象力去挖掘,比如:对不同颜色的挖掘、动植物的挖掘等等,如下:
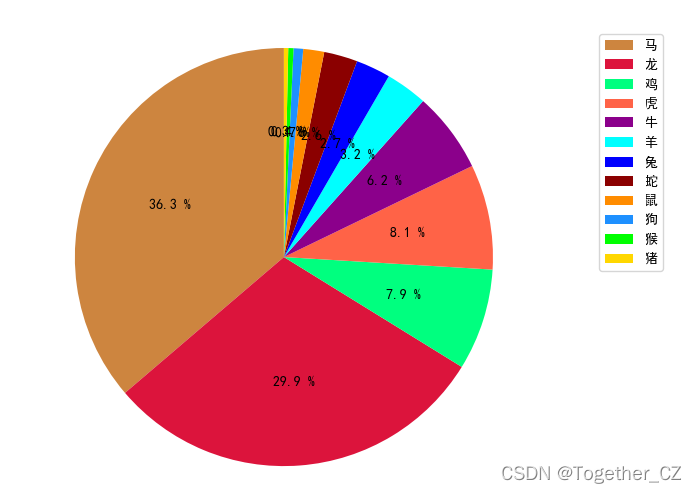
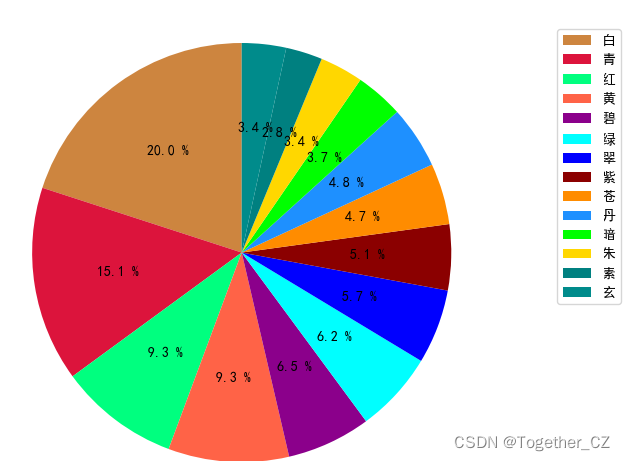
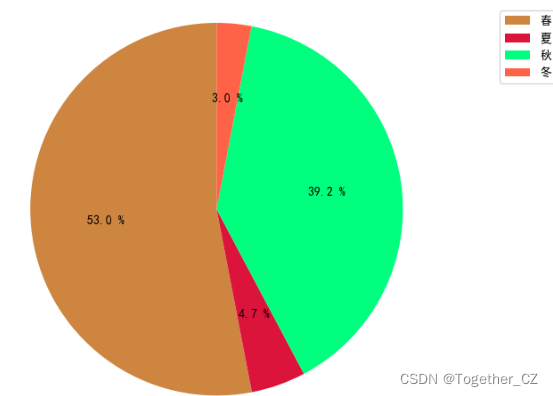
最后我这里还对唐诗宋词基于w2v模型训练词向量,做了分类模型,由于仅仅是简单的尝试了一下,没有进行任何的调参优化,这里就不再放出来了,直接看下结果:
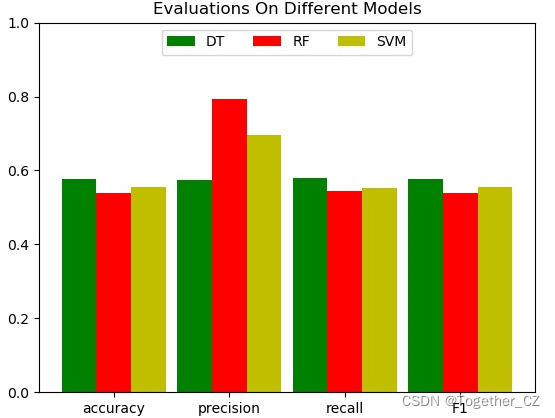
详细的实现在我之前的相关博文里面都有分享过,感兴趣可以查看。我简单贴一些博文,如下:



















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











