






在实际项目中有一个功能点需要用到字符串匹配,之前也有自行实现过这块的功能,但是总觉得不够完善,而且效率也不够高,在网上查询了一番,发现了已经有实现好的很好用的工具模块了,接下来以实际案例为切入点,实际看下效果。
pyahocorasick模块是一个Python库,提供了高效的Aho-Corasick字符串匹配算法。它设计用于同时在给定文本中搜索多个模式,因此在字符串匹配、关键词提取和文本分析等任务中非常强大。
该模块的名称取自两位计算机科学家Alfred Aho和Margaret Corasick,他们于1975年开发了Aho-Corasick算法。这个算法以构建基于一组模式的有限状态机(FSM)为特点,能够快速且可扩展地进行字符串匹配。
以下是使用pyahocorasick模块的一些关键特性和优势:
-
快速模式匹配:pyahocorasick实现的Aho-Corasick算法能够高效地在文本中搜索模式。它可以处理大量模式的匹配,对性能影响较小。
-
多模式匹配:使用pyahocorasick,您可以同时搜索多个模式。当您需要对给定的文本匹配大量模式时,这将非常有用。
-
可定制的操作:该模块支持定义在找到模式时要执行的自定义操作。您可以将不同的操作或回调与单个模式或一组模式关联起来。
-
节省内存:pyahocorasick模块被设计为内存高效。它通过构建模式的紧凑有限状态机表示来优化内存使用。
首先我们来看第一个工具库——pyahocorasick,官方地址在这里,如下所示:
目前已经有将近1k的star量了。
pyahorosick是一个快速且内存高效的库,用于精确或近似的多模式字符串搜索,这意味着可以在某些输入文本中同时找到多个关键字字符串。字符串“index”可以提前构建并保存(作为pickle)到磁盘,以便以后重新加载和重用。该库提供了一个复杂的Python模块,可以将其用作像Trie一样的普通dict,或者将Trie转换为自动机,以实现高效的Aho-Corasick搜索。
pyahocorasick是用C语言实现的,并在Python 3.6及更高版本上进行了测试。它适用于64位Linux、macOS和Windows。
安装命令如下所示:
pip install pyahocorasick简单两句话即可创建一个自动机,如下所示:
import ahocorasick
automaton = ahocorasick.Automaton()简单的实例代码实现如下所示:
import ahocorasick
# 构建模式匹配自动机
patterns = ['an', 'un', 'is']
automaton = ahocorasick.Automaton()
for pattern in patterns:
automaton.add_word(pattern, pattern)
automaton.make_automaton()
# 在文本中查找匹配
text = 'In quiet solitude, peace is found,Where thoughts can wander, unbound.'
matches = []
for end_index, matched_pattern in automaton.iter(text):
start_index = end_index - len(matched_pattern) + 1
matches.append((matched_pattern, start_index, end_index))
print(matches)
结果输出如下所示:
[('is', 25, 26), ('un', 30, 31), ('an', 50, 51), ('an', 54, 55), ('un', 61, 62), ('un', 65, 66)]这里面每个子对象目标都是一个三元组数据,第一个元素就是查找出来的目标对象字符串,后面两个数字表示的就是当前匹配到的字符串在原始字符串文本中的开始索引和结束索引。
接下来我们想要实地测试一下该模块的查询匹配效率,编写测试代码生成随机字符串如下所示:
base_list=['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p',
'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
print(len(base_list))
all_list=[1,10,100,1000,10000,100000]
t_list=[]
for one_all in all_list:
string=""
for i in range(one_all):
string+="".join(random.sample(base_list,10))
print("string_length: ", len(string))随机构建查询目标,查询1000次,如下所示:
for i in range(1000):
one_str="".join(random.sample(base_list, one_num))
one_patterns.append(one_str)构建AC自动机匹配查询,如下所示:
automaton.make_automaton()
matches = []
for end_index, matched_pattern in automaton.iter(string):
start_index = end_index - len(matched_pattern) + 1
matches.append((matched_pattern, start_index, end_index))接下来我们进行实验,在实验中我们还想探索分析查询子串的长度和时间的关系,这里分别进行实验,如下所示:
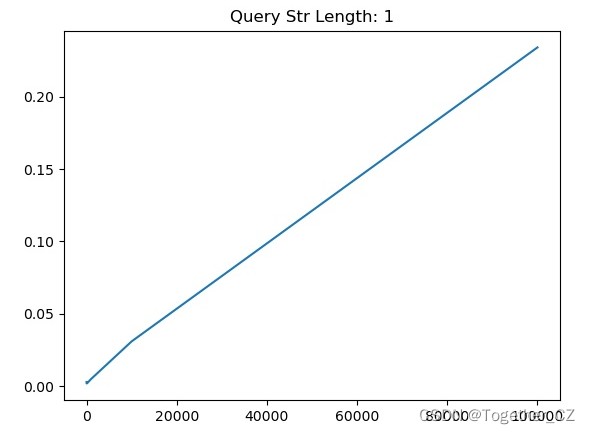
【查询子串长度为1】
【查询子串长度为2】

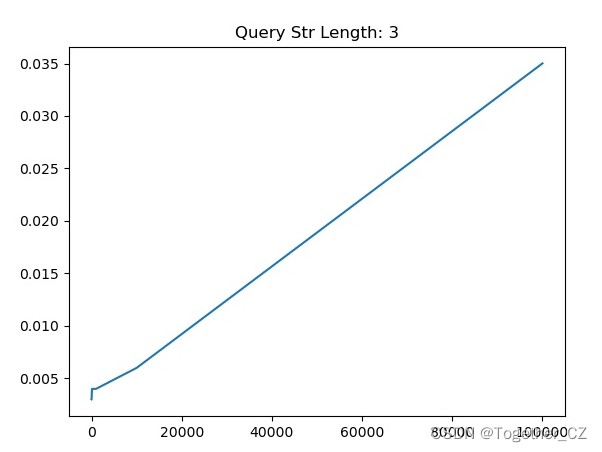
【查询子串长度为3】
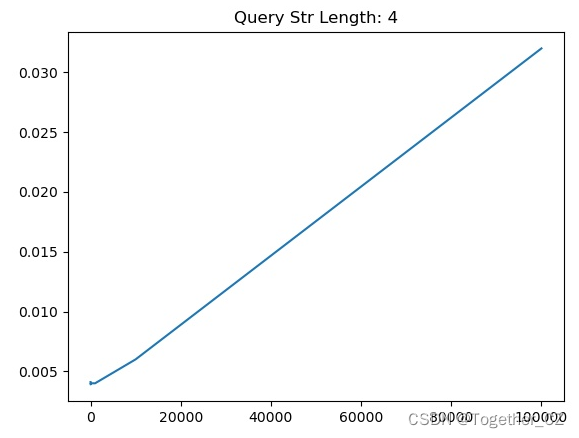
【查询子串长度为4】
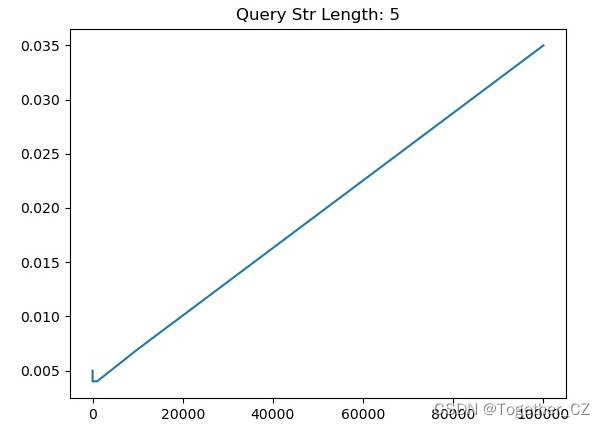
【查询子串长度为5】
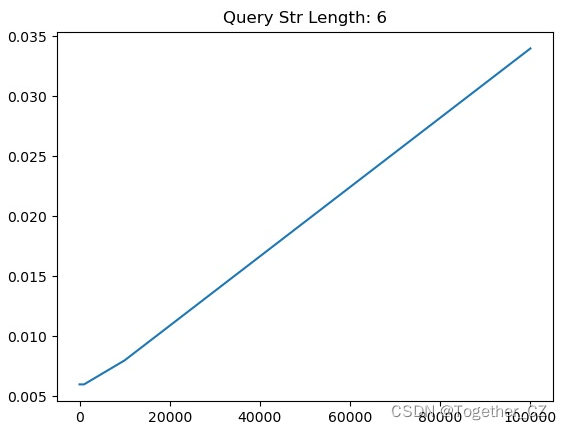
【查询子串长度为6】
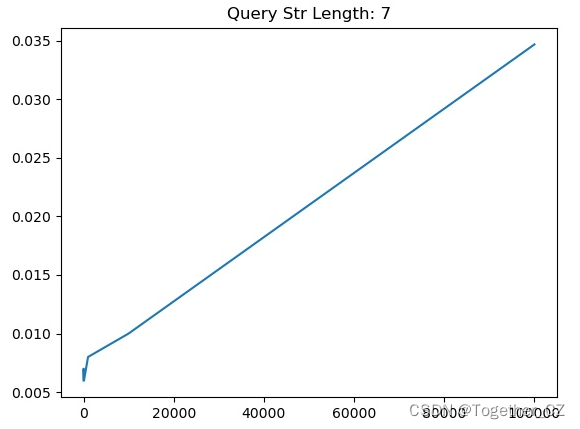
【查询子串长度为7】
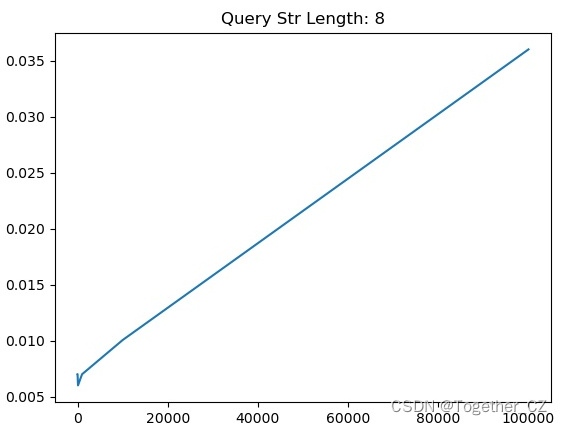
【查询子串长度为8】
【查询子串长度为9】
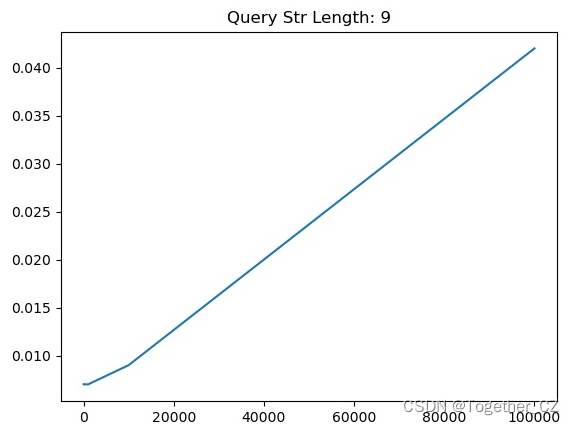
从测试实验结果不难直观看出来:查询子串长度为1的时候查询时耗最长,查询子串长度为2的时候查询时耗次之,当查询子串长度>=3的时候,查询时耗没有发现明显的变化,只是在一定的区间波动。
为了直观对比分析,这里我将其绘制整体对比可视化曲线,如下所示:
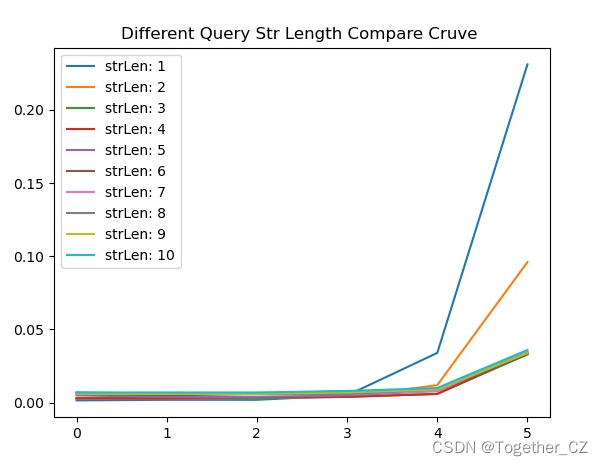
感兴趣的话都可以试试看,相信会发现他的强大。
















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











